 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-to-CAD: Agentic Synthesis of Interpretable CAD Programs at Million-Scale Without Real Data
Apr 27, 2026Computer-Aided Design (CAD) models are defined by their construction history: a parametric recipe that encodes design intent. However, existing large-scale 3D datasets predominantly consist of boundary representations (B-Reps) or meshes, stripping away this critical procedural information. To address this scarcity, we introduce Zero-to-CAD, a scalable framework for synthesizing executable CAD construction sequences. We frame synthesis as an agentic search problem: by embedding a large language model (LLM) within a feedback-driven CAD environment, our system iteratively generates, executes, and validates code using tools and documentation lookup to promote geometric validity and operation diversity. This agentic approach enables the synthesis of approximately one million executable, readable, editable CAD sequences, covering a rich vocabulary of operations beyond sketch-and-extrude workflows. We also release a curated subset of 100,000 high-quality models selected for geometric diversity. To demonstrate the dataset's utility, we fine-tune a vision-language model on our synthetic data to reconstruct editable CAD programs from multi-view images, outperforming strong baselines, including GPT-5.2, and effectively bootstrapping sequence generation capabilities without real construction-history training data. Zero-to-CAD bridges the gap between geometric scale and parametric interpretability, offering a vital resource for the next generation of CAD AI.
Wavelet Latent Diffusion (Wala): Billion-Parameter 3D Generative Model with Compact Wavelet Encodings
Nov 12, 2024



Large-scale 3D generative models require substantial computational resources yet often fall short in capturing fine details and complex geometries at high resolutions. We attribute this limitation to the inefficiency of current representations, which lack the compactness required to model the generative models effectively. To address this, we introduce a novel approach called Wavelet Latent Diffusion, or WaLa, that encodes 3D shapes into wavelet-based, compact latent encodings. Specifically, we compress a $256^3$ signed distance field into a $12^3 \times 4$ latent grid, achieving an impressive 2427x compression ratio with minimal loss of detail. This high level of compression allows our method to efficiently train large-scale generative networks without increasing the inference time. Our models, both conditional and unconditional, contain approximately one billion parameters and successfully generate high-quality 3D shapes at $256^3$ resolution. Moreover, WaLa offers rapid inference, producing shapes within two to four seconds depending on the condition, despite the model's scale. We demonstrate state-of-the-art performance across multiple datasets, with significant improvements in generation quality, diversity, and computational efficiency. We open-source our code and, to the best of our knowledge, release the largest pretrained 3D generative models across different modalities.
Make-A-Shape: a Ten-Million-scale 3D Shape Model
Jan 20, 2024



Significant progress has been made in training large generative models for natural language and images. Yet, the advancement of 3D generative models is hindered by their substantial resource demands for training, along with inefficient, non-compact, and less expressive representations. This paper introduces Make-A-Shape, a new 3D generative model designed for efficient training on a vast scale, capable of utilizing 10 millions publicly-available shapes. Technical-wise, we first innovate a wavelet-tree representation to compactly encode shapes by formulating the subband coefficient filtering scheme to efficiently exploit coefficient relations. We then make the representation generatable by a diffusion model by devising the subband coefficients packing scheme to layout the representation in a low-resolution grid. Further, we derive the subband adaptive training strategy to train our model to effectively learn to generate coarse and detail wavelet coefficients. Last, we extend our framework to be controlled by additional input conditions to enable it to generate shapes from assorted modalities, e.g., single/multi-view images, point clouds, and low-resolution voxels. In our extensive set of experiments, we demonstrate various applications, such as unconditional generation, shape completion, and conditional generation on a wide range of modalities. Our approach not only surpasses the state of the art in delivering high-quality results but also efficiently generates shapes within a few seconds, often achieving this in just 2 seconds for most conditions.
Generalizable Pose Estimation Using Implicit Scene Representations
May 26, 2023



6-DoF pose estimation is an essential component of robotic manipulation pipelines. However, it usually suffers from a lack of generalization to new instances and object types. Most widely used methods learn to infer the object pose in a discriminative setup where the model filters useful information to infer the exact pose of the object. While such methods offer accurate poses, the model does not store enough information to generalize to new objects. In this work, we address the generalization capability of pose estimation using models that contain enough information about the object to render it in different poses. We follow the line of work that inverts neural renderers to infer the pose. We propose i-$\sigma$SRN to maximize the information flowing from the input pose to the rendered scene and invert them to infer the pose given an input image. Specifically, we extend Scene Representation Networks (SRNs) by incorporating a separate network for density estimation and introduce a new way of obtaining a weighted scene representation. We investigate several ways of initial pose estimates and losses for the neural renderer. Our final evaluation shows a significant improvement in inference performance and speed compared to existing approaches.
Reconstructing editable prismatic CAD from rounded voxel models
Sep 02, 2022
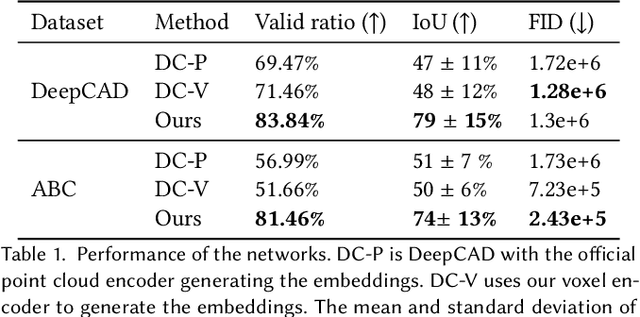
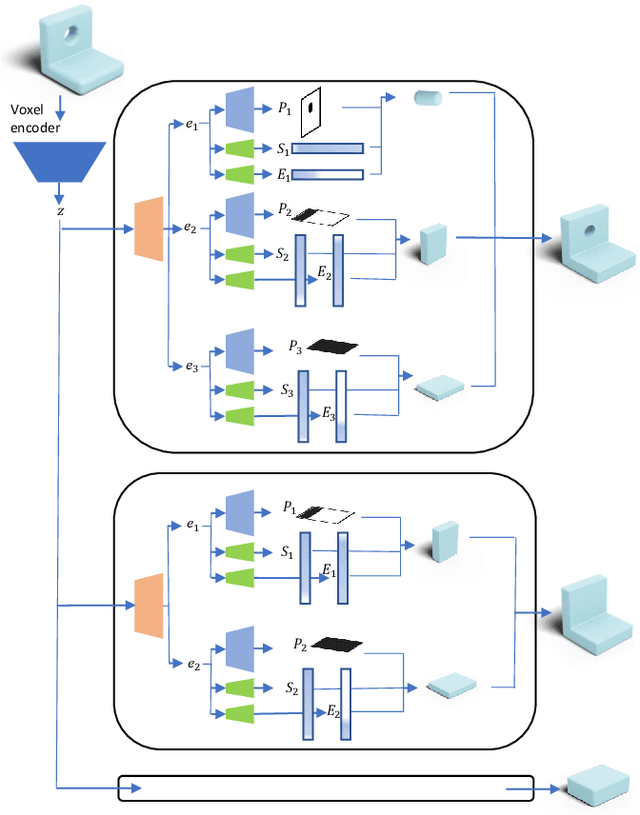
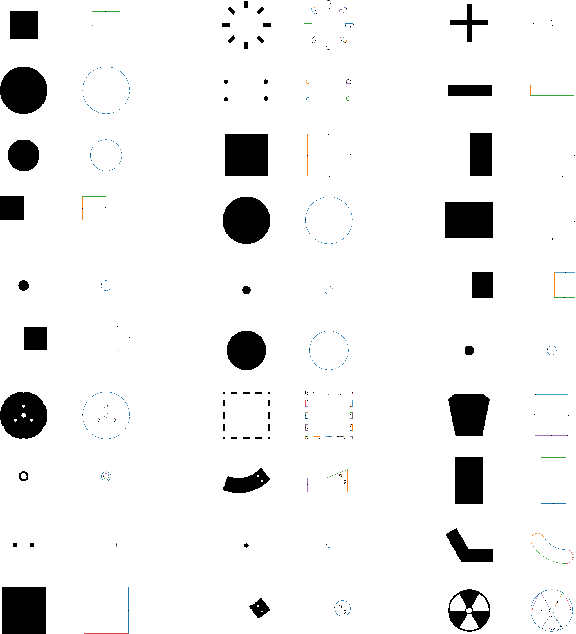
Reverse Engineering a CAD shape from other representations is an important geometric processing step for many downstream applications. In this work, we introduce a novel neural network architecture to solve this challenging task and approximate a smoothed signed distance function with an editable, constrained, prismatic CAD model. During training, our method reconstructs the input geometry in the voxel space by decomposing the shape into a series of 2D profile images and 1D envelope functions. These can then be recombined in a differentiable way allowing a geometric loss function to be defined. During inference, we obtain the CAD data by first searching a database of 2D constrained sketches to find curves which approximate the profile images, then extrude them and use Boolean operations to build the final CAD model. Our method approximates the target shape more closely than other methods and outputs highly editable constrained parametric sketches which are compatible with existing CAD software.