 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Neural Gauge Fields
May 05, 2023The recent advance of neural fields, such as neural radiance fields, has significantly pushed the boundary of scene representation learning. Aiming to boost the computation efficiency and rendering quality of 3D scenes, a popular line of research maps the 3D coordinate system to another measuring system, e.g., 2D manifolds and hash tables, for modeling neural fields. The conversion of coordinate systems can be typically dubbed as gauge transformation, which is usually a pre-defined mapping function, e.g., orthogonal projection or spatial hash function. This begs a question: can we directly learn a desired gauge transformation along with the neural field in an end-to-end manner? In this work, we extend this problem to a general paradigm with a taxonomy of discrete & continuous cases, and develop an end-to-end learning framework to jointly optimize the gauge transformation and neural fields. To counter the problem that the learning of gauge transformations can collapse easily, we derive a general regularization mechanism from the principle of information conservation during the gauge transformation. To circumvent the high computation cost in gauge learning with regularization, we directly derive an information-invariant gauge transformation which allows to preserve scene information inherently and yield superior performance.
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction
Apr 17, 2023



3D-aware image synthesis encompasses a variety of tasks, such as scene generation and novel view synthesis from images. Despite numerous task-specific methods, developing a comprehensive model remains challenging. In this paper, we present SSDNeRF, a unified approach that employs an expressive diffusion model to learn a generalizable prior of neural radiance fields (NeRF) from multi-view images of diverse objects. Previous studies have used two-stage approaches that rely on pretrained NeRFs as real data to train diffusion models. In contrast, we propose a new single-stage training paradigm with an end-to-end objective that jointly optimizes a NeRF auto-decoder and a latent diffusion model, enabling simultaneous 3D reconstruction and prior learning, even from sparsely available views. At test time, we can directly sample the diffusion prior for unconditional generation, or combine it with arbitrary observations of unseen objects for NeRF reconstruction. SSDNeRF demonstrates robust results comparable to or better than leading task-specific methods in unconditional generation and single/sparse-view 3D reconstruction.
Learning Controllable 3D Diffusion Models from Single-view Images
Apr 13, 2023



Diffusion models have recently become the de-facto approach for generative modeling in the 2D domain. However, extending diffusion models to 3D is challenging due to the difficulties in acquiring 3D ground truth data for training. On the other hand, 3D GANs that integrate implicit 3D representations into GANs have shown remarkable 3D-aware generation when trained only on single-view image datasets. However, 3D GANs do not provide straightforward ways to precisely control image synthesis. To address these challenges, We present Control3Diff, a 3D diffusion model that combines the strengths of diffusion models and 3D GANs for versatile, controllable 3D-aware image synthesis for single-view datasets. Control3Diff explicitly models the underlying latent distribution (optionally conditioned on external inputs), thus enabling direct control during the diffusion process. Moreover, our approach is general and applicable to any type of controlling input, allowing us to train it with the same diffusion objective without any auxiliary supervision. We validate the efficacy of Control3Diff on standard image generation benchmarks, including FFHQ, AFHQ, and ShapeNet, using various conditioning inputs such as images, sketches, and text prompts. Please see the project website (\url{https://jiataogu.me/control3diff}) for video comparisons.
F$^{2}$-NeRF: Fast Neural Radiance Field Training with Free Camera Trajectories
Mar 28, 2023This paper presents a novel grid-based NeRF called F2-NeRF (Fast-Free-NeRF) for novel view synthesis, which enables arbitrary input camera trajectories and only costs a few minutes for training. Existing fast grid-based NeRF training frameworks, like Instant-NGP, Plenoxels, DVGO, or TensoRF, are mainly designed for bounded scenes and rely on space warping to handle unbounded scenes. Existing two widely-used space-warping methods are only designed for the forward-facing trajectory or the 360-degree object-centric trajectory but cannot process arbitrary trajectories. In this paper, we delve deep into the mechanism of space warping to handle unbounded scenes. Based on our analysis, we further propose a novel space-warping method called perspective warping, which allows us to handle arbitrary trajectories in the grid-based NeRF framework. Extensive experiments demonstrate that F2-NeRF is able to use the same perspective warping to render high-quality images on two standard datasets and a new free trajectory dataset collected by us. Project page: https://totoro97.github.io/projects/f2-nerf.
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
Feb 20, 2023
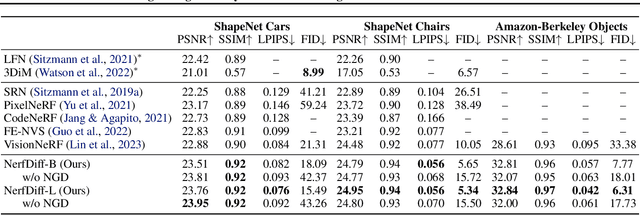
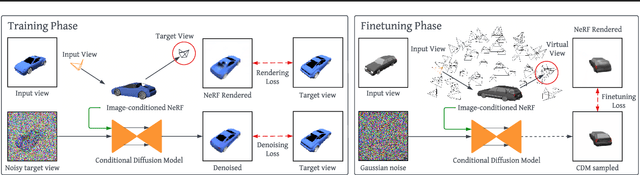
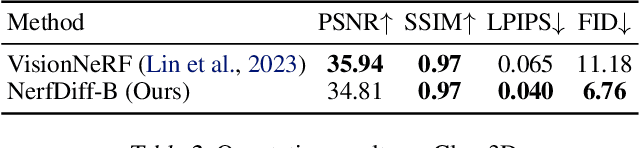
Novel view synthesis from a single image requires inferring occluded regions of objects and scenes whilst simultaneously maintaining semantic and physical consistency with the input. Existing approaches condition neural radiance fields (NeRF) on local image features, projecting points to the input image plane, and aggregating 2D features to perform volume rendering. However, under severe occlusion, this projection fails to resolve uncertainty, resulting in blurry renderings that lack details. In this work, we propose NerfDiff, which addresses this issue by distilling the knowledge of a 3D-aware conditional diffusion model (CDM) into NeRF through synthesizing and refining a set of virtual views at test time. We further propose a novel NeRF-guided distillation algorithm that simultaneously generates 3D consistent virtual views from the CDM samples, and finetunes the NeRF based on the improved virtual views. Our approach significantly outperforms existing NeRF-based and geometry-free approaches on challenging datasets, including ShapeNet, ABO, and Clevr3D.
Scene-aware Egocentric 3D Human Pose Estimation
Dec 20, 2022



Egocentric 3D human pose estimation with a single head-mounted fisheye camera has recently attracted attention due to its numerous applications in virtual and augmented reality. Existing methods still struggle in challenging poses where the human body is highly occluded or is closely interacting with the scene. To address this issue, we propose a scene-aware egocentric pose estimation method that guides the prediction of the egocentric pose with scene constraints. To this end, we propose an egocentric depth estimation network to predict the scene depth map from a wide-view egocentric fisheye camera while mitigating the occlusion of the human body with a depth-inpainting network. Next, we propose a scene-aware pose estimation network that projects the 2D image features and estimated depth map of the scene into a voxel space and regresses the 3D pose with a V2V network. The voxel-based feature representation provides the direct geometric connection between 2D image features and scene geometry, and further facilitates the V2V network to constrain the predicted pose based on the estimated scene geometry. To enable the training of the aforementioned networks, we also generated a synthetic dataset, called EgoGTA, and an in-the-wild dataset based on EgoPW, called EgoPW-Scene. The experimental results of our new evaluation sequences show that the predicted 3D egocentric poses are accurate and physically plausible in terms of human-scene interaction, demonstrating that our method outperforms the state-of-the-art methods both quantitatively and qualitatively.
NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction
Dec 10, 2022



Recent methods for neural surface representation and rendering, for example NeuS, have demonstrated remarkably high-quality reconstruction of static scenes. However, the training of NeuS takes an extremely long time (8 hours), which makes it almost impossible to apply them to dynamic scenes with thousands of frames. We propose a fast neural surface reconstruction approach, called NeuS2, which achieves two orders of magnitude improvement in terms of acceleration without compromising reconstruction quality. To accelerate the training process, we integrate multi-resolution hash encodings into a neural surface representation and implement our whole algorithm in CUDA. We also present a lightweight calculation of second-order derivatives tailored to our networks (i.e., ReLU-based MLPs), which achieves a factor two speed up. To further stabilize training, a progressive learning strategy is proposed to optimize multi-resolution hash encodings from coarse to fine. In addition, we extend our method for reconstructing dynamic scenes with an incremental training strategy. Our experiments on various datasets demonstrate that NeuS2 significantly outperforms the state-of-the-arts in both surface reconstruction accuracy and training speed. The video is available at https://vcai.mpi-inf.mpg.de/projects/NeuS2/ .
NeuralUDF: Learning Unsigned Distance Fields for Multi-view Reconstruction of Surfaces with Arbitrary Topologies
Nov 25, 2022We present a novel method, called NeuralUDF, for reconstructing surfaces with arbitrary topologies from 2D images via volume rendering. Recent advances in neural rendering based reconstruction have achieved compelling results. However, these methods are limited to objects with closed surfaces since they adopt Signed Distance Function (SDF) as surface representation which requires the target shape to be divided into inside and outside. In this paper, we propose to represent surfaces as the Unsigned Distance Function (UDF) and develop a new volume rendering scheme to learn the neural UDF representation. Specifically, a new density function that correlates the property of UDF with the volume rendering scheme is introduced for robust optimization of the UDF fields. Experiments on the DTU and DeepFashion3D datasets show that our method not only enables high-quality reconstruction of non-closed shapes with complex typologies, but also achieves comparable performance to the SDF based methods on the reconstruction of closed surfaces.
Neural Novel Actor: Learning a Generalized Animatable Neural Representation for Human Actors
Aug 25, 2022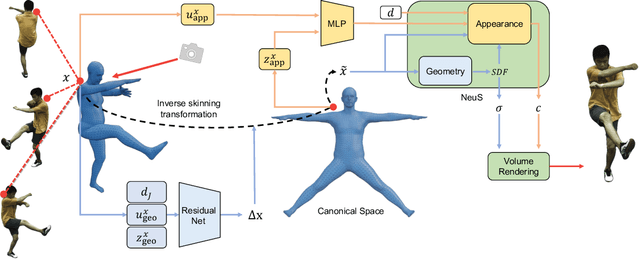

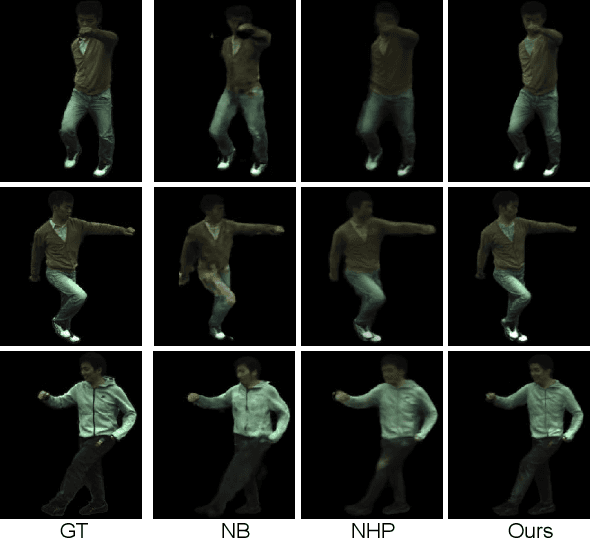

We propose a new method for learning a generalized animatable neural human representation from a sparse set of multi-view imagery of multiple persons. The learned representation can be used to synthesize novel view images of an arbitrary person from a sparse set of cameras, and further animate them with the user's pose control. While existing methods can either generalize to new persons or synthesize animations with user control, none of them can achieve both at the same time. We attribute this accomplishment to the employment of a 3D proxy for a shared multi-person human model, and further the warping of the spaces of different poses to a shared canonical pose space, in which we learn a neural field and predict the person- and pose-dependent deformations, as well as appearance with the features extracted from input images. To cope with the complexity of the large variations in body shapes, poses, and clothing deformations, we design our neural human model with disentangled geometry and appearance. Furthermore, we utilize the image features both at the spatial point and on the surface points of the 3D proxy for predicting person- and pose-dependent properties. Experiments show that our method significantly outperforms the state-of-the-arts on both tasks. The video and code are available at https://talegqz.github.io/neural_novel_actor.
Progressively-connected Light Field Network for Efficient View Synthesis
Jul 10, 2022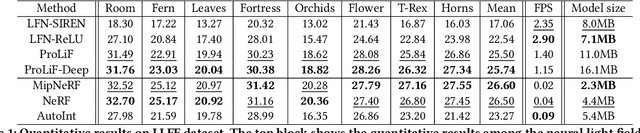


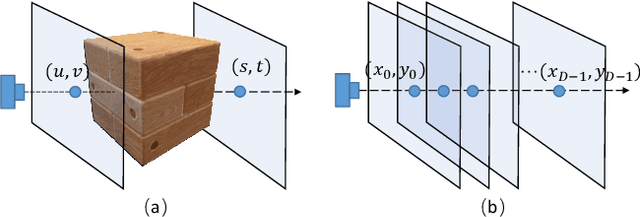
This paper presents a Progressively-connected Light Field network (ProLiF), for the novel view synthesis of complex forward-facing scenes. ProLiF encodes a 4D light field, which allows rendering a large batch of rays in one training step for image- or patch-level losses. Directly learning a neural light field from images has difficulty in rendering multi-view consistent images due to its unawareness of the underlying 3D geometry. To address this problem, we propose a progressive training scheme and regularization losses to infer the underlying geometry during training, both of which enforce the multi-view consistency and thus greatly improves the rendering quality. Experiments demonstrate that our method is able to achieve significantly better rendering quality than the vanilla neural light fields and comparable results to NeRF-like rendering methods on the challenging LLFF dataset and Shiny Object dataset. Moreover, we demonstrate better compatibility with LPIPS loss to achieve robustness to varying light conditions and CLIP loss to control the rendering style of the scene. Project page: https://totoro97.github.io/projects/prolif.