 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLingfei Wu
Bridging the Gap between Spatial and Spectral Domains: A Theoretical Framework for Graph Neural Networks
Jul 21, 2021
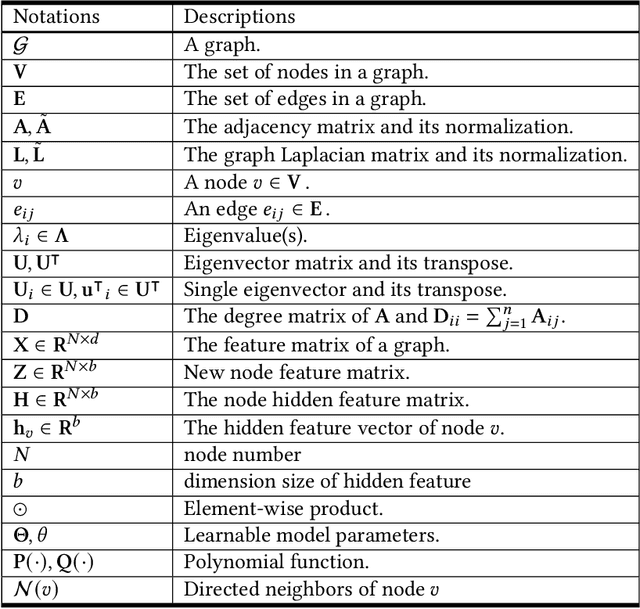

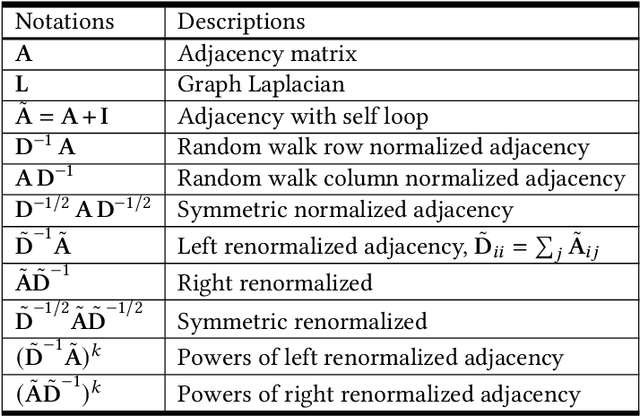
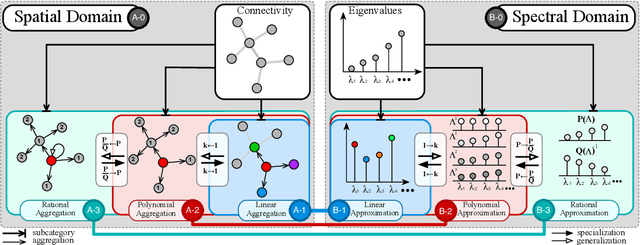
During the past decade, deep learning's performance has been widely recognized in a variety of machine learning tasks, ranging from image classification, speech recognition to natural language understanding. Graph neural networks (GNN) are a type of deep learning that is designed to handle non-Euclidean issues using graph-structured data that are difficult to solve with traditional deep learning techniques. The majority of GNNs were created using a variety of processes, including random walk, PageRank, graph convolution, and heat diffusion, making direct comparisons impossible. Previous studies have primarily focused on classifying current models into distinct categories, with little investigation of their internal relationships. This research proposes a unified theoretical framework and a novel perspective that can methodologically integrate existing GNN into our framework. We survey and categorize existing GNN models into spatial and spectral domains, as well as show linkages between subcategories within each domain. Further investigation reveals a strong relationship between the spatial, spectral, and subgroups of these domains.
Heterogeneous Global Graph Neural Networks for Personalized Session-based Recommendation
Jul 08, 2021
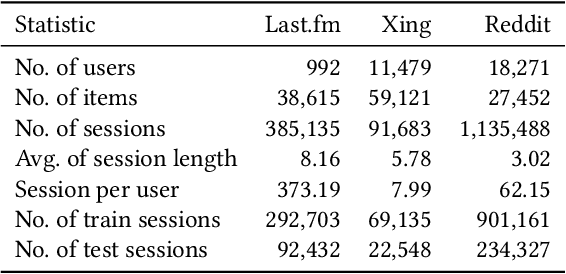
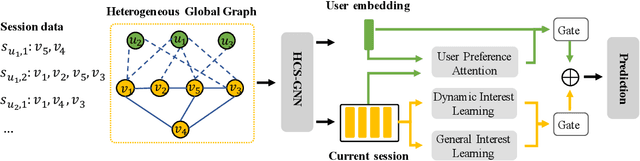
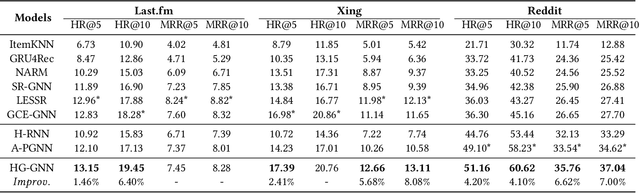
Predicting the next interaction of a short-term interaction session is a challenging task in session-based recommendation. Almost all existing works rely on item transition patterns, and neglect the impact of user historical sessions while modeling user preference, which often leads to non-personalized recommendation. Additionally, existing personalized session-based recommenders capture user preference only based on the sessions of the current user, but ignore the useful item-transition patterns from other user's historical sessions. To address these issues, we propose a novel Heterogeneous Global Graph Neural Networks (HG-GNN) to exploit the item transitions over all sessions in a subtle manner for better inferring user preference from the current and historical sessions. To effectively exploit the item transitions over all sessions from users, we propose a novel heterogeneous global graph that contains item transitions of sessions, user-item interactions and global co-occurrence items. Moreover, to capture user preference from sessions comprehensively, we propose to learn two levels of user representations from the global graph via two graph augmented preference encoders. Specifically, we design a novel heterogeneous graph neural network (HGNN) on the heterogeneous global graph to learn the long-term user preference and item representations with rich semantics. Based on the HGNN, we propose the Current Preference Encoder and the Historical Preference Encoder to capture the different levels of user preference from the current and historical sessions, respectively. To achieve personalized recommendation, we integrate the representations of the user current preference and historical interests to generate the final user preference representation. Extensive experimental results on three real-world datasets show that our model outperforms other state-of-the-art methods.
Graph Neural Networks for Natural Language Processing: A Survey
Jun 10, 2021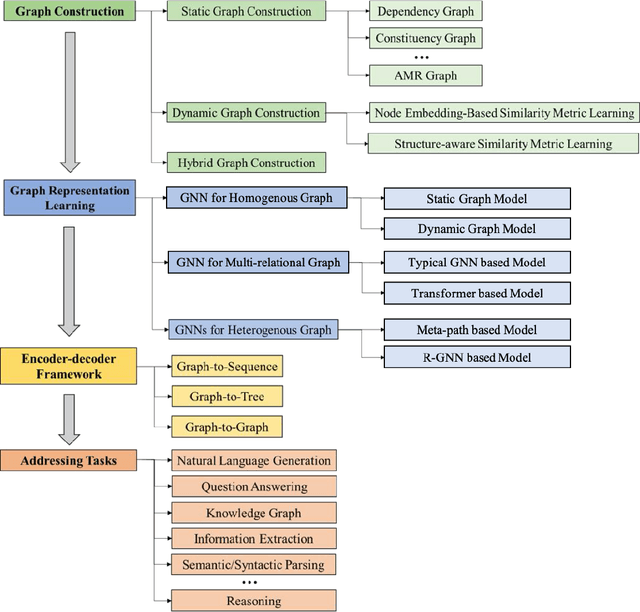
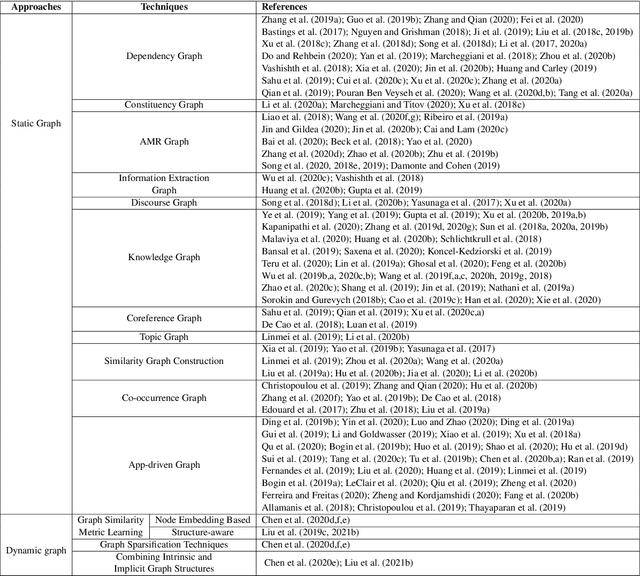
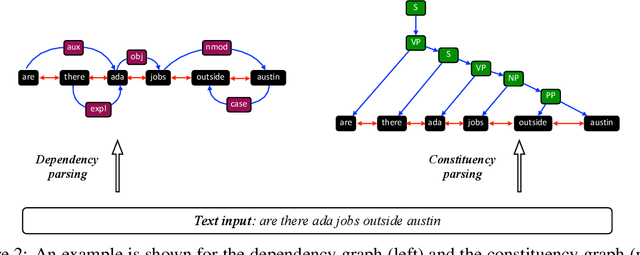
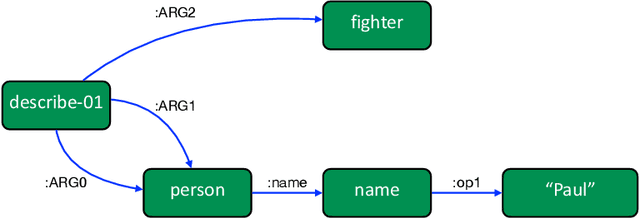
Deep learning has become the dominant approach in coping with various tasks in Natural LanguageProcessing (NLP). Although text inputs are typically represented as a sequence of tokens, there isa rich variety of NLP problems that can be best expressed with a graph structure. As a result, thereis a surge of interests in developing new deep learning techniques on graphs for a large numberof NLP tasks. In this survey, we present a comprehensive overview onGraph Neural Networks(GNNs) for Natural Language Processing. We propose a new taxonomy of GNNs for NLP, whichsystematically organizes existing research of GNNs for NLP along three axes: graph construction,graph representation learning, and graph based encoder-decoder models. We further introducea large number of NLP applications that are exploiting the power of GNNs and summarize thecorresponding benchmark datasets, evaluation metrics, and open-source codes. Finally, we discussvarious outstanding challenges for making the full use of GNNs for NLP as well as future researchdirections. To the best of our knowledge, this is the first comprehensive overview of Graph NeuralNetworks for Natural Language Processing.
Constructing Contrastive samples via Summarization for Text Classification with limited annotations
Apr 11, 2021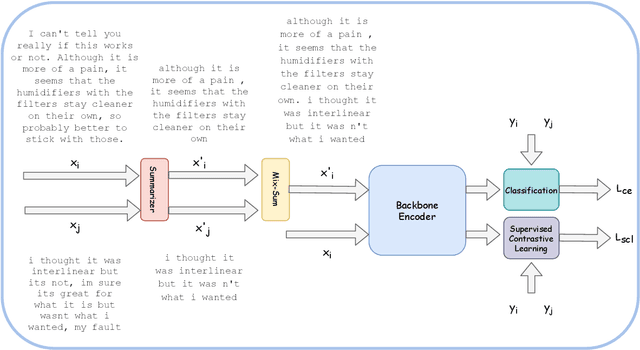
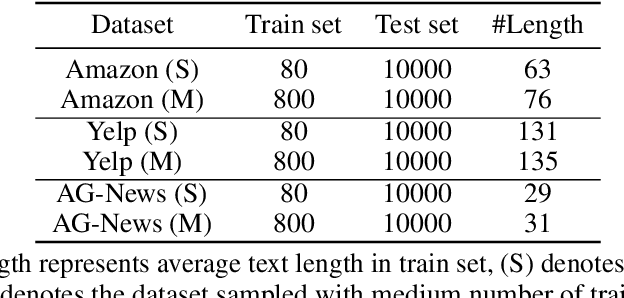
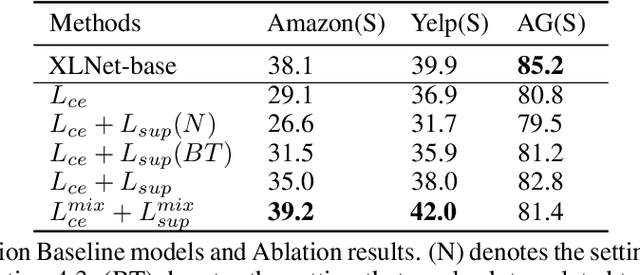
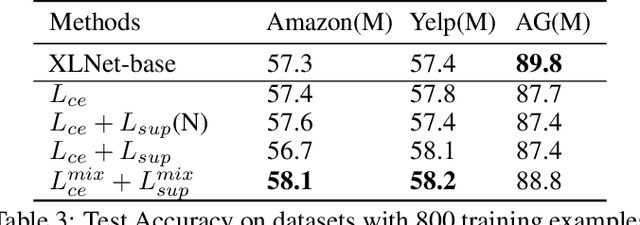
Contrastive Learning has emerged as a powerful representation learning method and facilitates various downstream tasks especially when supervised data is limited. How to construct efficient contrastive samples through data augmentation is key to its success. Unlike vision tasks, the data augmentation method for contrastive learning has not been investigated sufficiently in language tasks. In this paper, we propose a novel approach to constructing contrastive samples for language tasks using text summarization. We use these samples for supervised contrastive learning to gain better text representations which greatly benefit text classification tasks with limited annotations. To further improve the method, we mix up samples from different classes and add an extra regularization, named mix-sum regularization, in addition to the cross-entropy-loss. Experiments on real-world text classification datasets (Amazon-5, Yelp-5, AG News) demonstrate the effectiveness of the proposed contrastive learning framework with summarization-based data augmentation and mix-sum regularization.
HAConvGNN: Hierarchical Attention Based Convolutional Graph Neural Network for Code Documentation Generation in Jupyter Notebooks
Mar 31, 2021

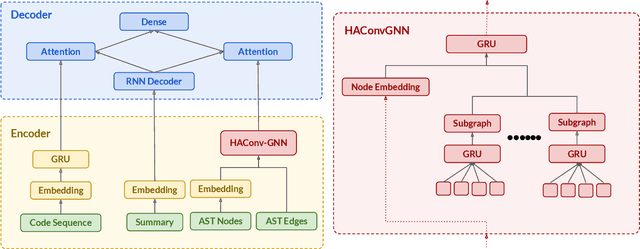
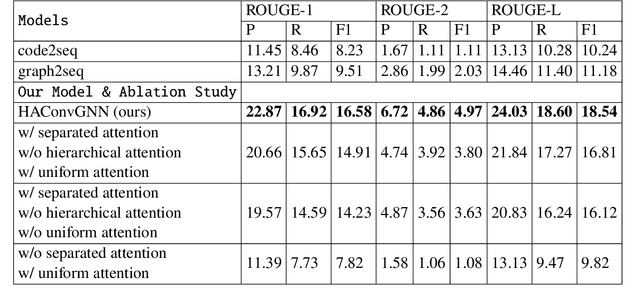
Many data scientists use Jupyter notebook to experiment code, visualize results, and document rationales or interpretations. The code documentation generation CDG task in notebooks is related but different from the code summarization task in software engineering, as one documentation (markdown cell) may consist of a text (informative summary or indicative rationale) for multiple code cells. Our work aims to solve the CDG task by encoding the multiple code cells as separated AST graph structures, for which we propose a hierarchical attention-based ConvGNN component to augment the Seq2Seq network. We build a dataset with publicly available Kaggle notebooks and evaluate our model (HAConvGNN) against baseline models (e.g., Code2Seq or Graph2Seq).
Relation-aware Graph Attention Model With Adaptive Self-adversarial Training
Feb 14, 2021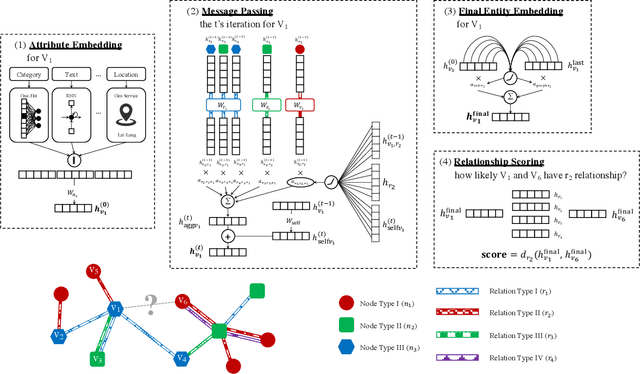

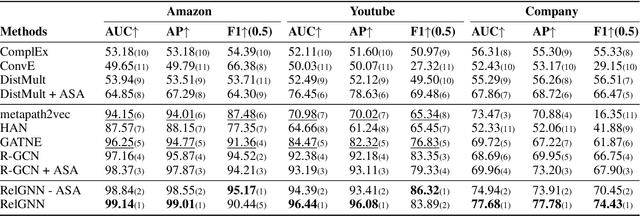
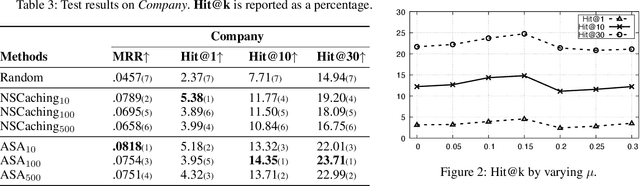
This paper describes an end-to-end solution for the relationship prediction task in heterogeneous, multi-relational graphs. We particularly address two building blocks in the pipeline, namely heterogeneous graph representation learning and negative sampling. Existing message passing-based graph neural networks use edges either for graph traversal and/or selection of message encoding functions. Ignoring the edge semantics could have severe repercussions on the quality of embeddings, especially when dealing with two nodes having multiple relations. Furthermore, the expressivity of the learned representation depends on the quality of negative samples used during training. Although existing hard negative sampling techniques can identify challenging negative relationships for optimization, new techniques are required to control false negatives during training as false negatives could corrupt the learning process. To address these issues, first, we propose RelGNN -- a message passing-based heterogeneous graph attention model. In particular, RelGNN generates the states of different relations and leverages them along with the node states to weigh the messages. RelGNN also adopts a self-attention mechanism to balance the importance of attribute features and topological features for generating the final entity embeddings. Second, we introduce a parameter-free negative sampling technique -- adaptive self-adversarial (ASA) negative sampling. ASA reduces the false-negative rate by leveraging positive relationships to effectively guide the identification of true negative samples. Our experimental evaluation demonstrates that RelGNN optimized by ASA for relationship prediction improves state-of-the-art performance across established benchmarks as well as on a real industrial dataset.
Low-skilled Occupations Face the Highest Re-skilling Pressure
Jan 27, 2021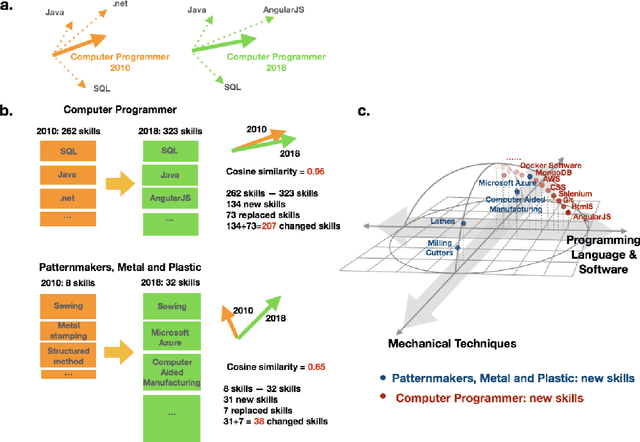
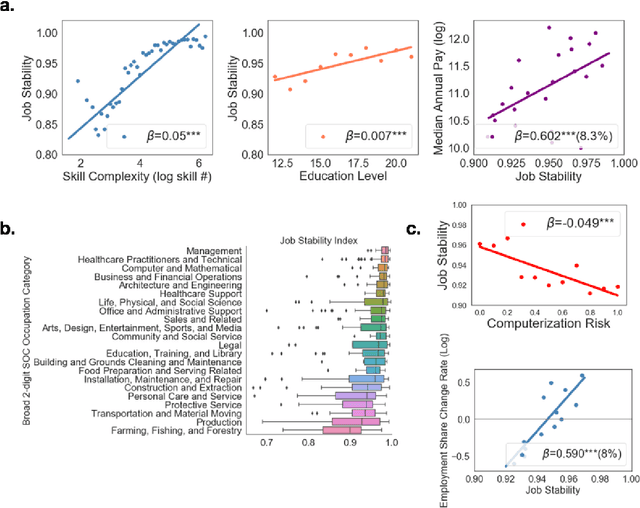
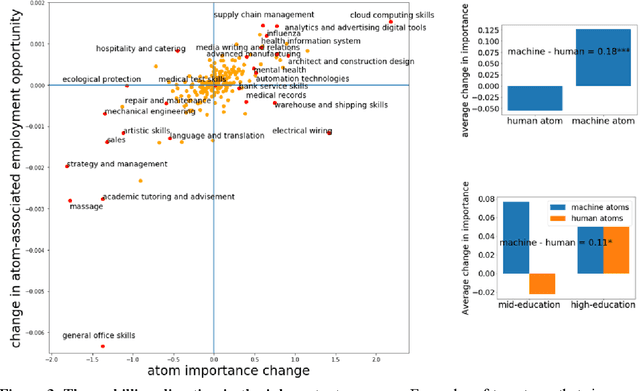
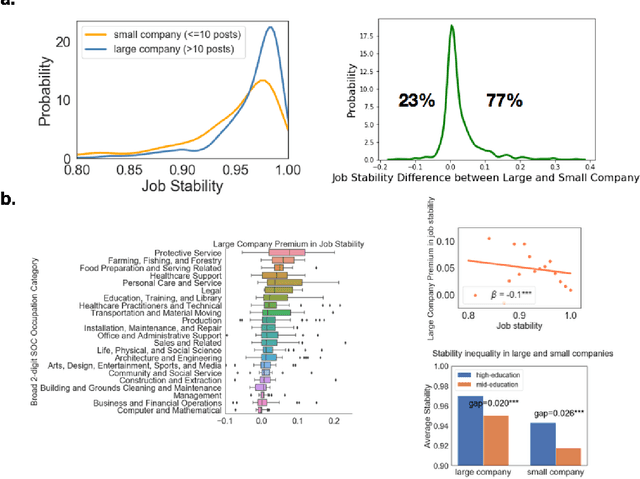
While substantial scholarship has focused on estimating the susceptibility of jobs to automation, little has examined how job contents evolve in the information age despite the fact that new technologies typically substitute for specific job tasks, shifting job skills rather than eliminating whole jobs. Here we explore the process and consequences of changes in occupational skill contents and characterize occupations subject to the most re-skilling pressure. Recent research suggests that high-skilled STEM and technology-intensive business occupations have experienced the highest rates of skill content change. Using a dataset covering the near universe of U.S. online job postings between 2010 and 2018, we find that when the number and similarity of skills within a job are taken into account, the re-skilling pressure is much higher for workers in low complexity, low education and low compensation occupations. We use high-dimensional embeddings of skills estimated across all jobs to precisely assess skill similarity, and characterize occupational skill transformations, demonstrating that skills requiring machine-operation and interface rise sharply in importance in the past decade, much more than human interface skills in low and mid-education occupations. We establish that large organizations buffer jobs from skill instability and obsolescence, especially low-skilled jobs with unstable skill requirements. Finally, the gap in re-skilling pressure between low/mid-education and high-education occupations is smaller in large organizations, suggesting that by controlling the surrounding skill environment, such organizations reduce the rate of required re-skilling and sustain short-term productivity for those occupations.
A Neural Question Answering System for Basic Questions about Subroutines
Jan 11, 2021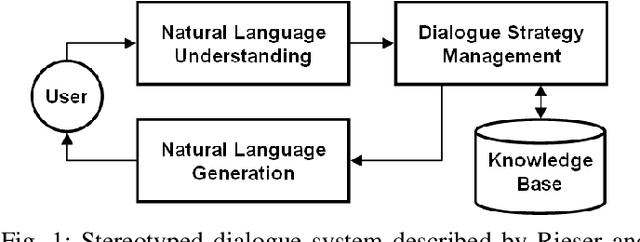
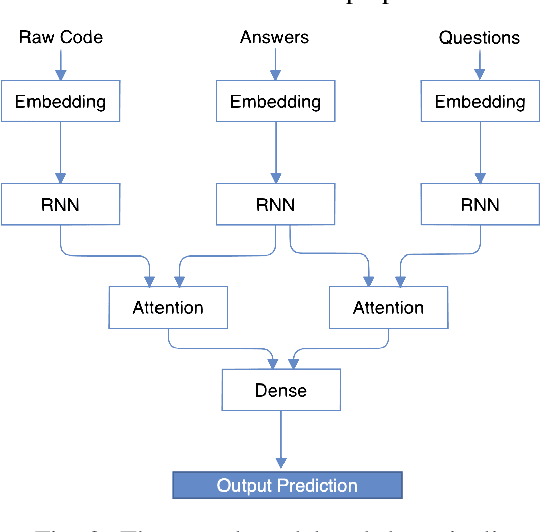
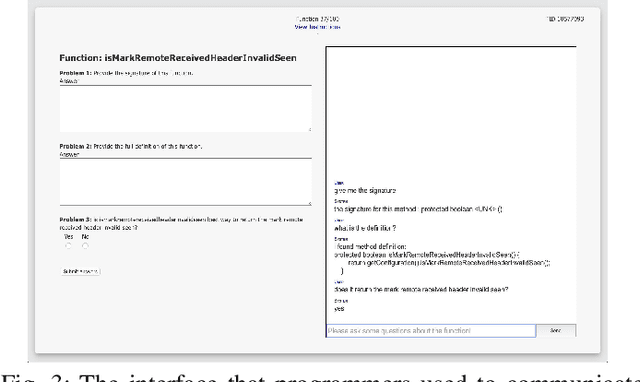
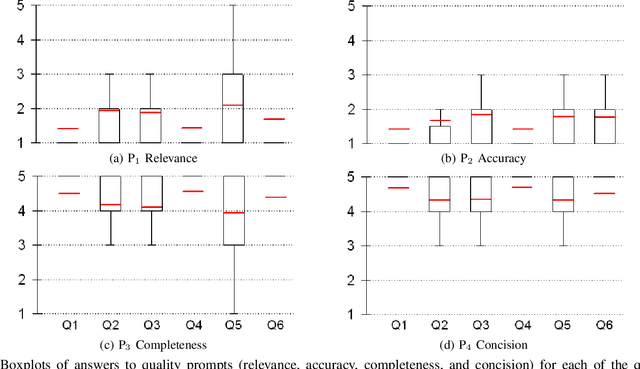
A question answering (QA) system is a type of conversational AI that generates natural language answers to questions posed by human users. QA systems often form the backbone of interactive dialogue systems, and have been studied extensively for a wide variety of tasks ranging from restaurant recommendations to medical diagnostics. Dramatic progress has been made in recent years, especially from the use of encoder-decoder neural architectures trained with big data input. In this paper, we take initial steps to bringing state-of-the-art neural QA technologies to Software Engineering applications by designing a context-based QA system for basic questions about subroutines. We curate a training dataset of 10.9 million question/context/answer tuples based on rules we extract from recent empirical studies. Then, we train a custom neural QA model with this dataset and evaluate the model in a study with professional programmers. We demonstrate the strengths and weaknesses of the system, and lay the groundwork for its use in eventual dialogue systems for software engineering.
Exploiting Heterogeneous Graph Neural Networks with Latent Worker/Task Correlation Information for Label Aggregation in Crowdsourcing
Oct 25, 2020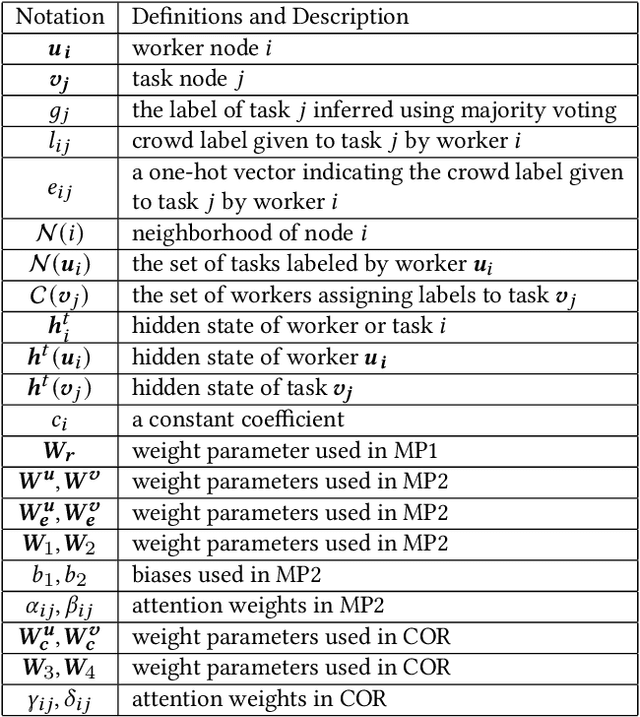

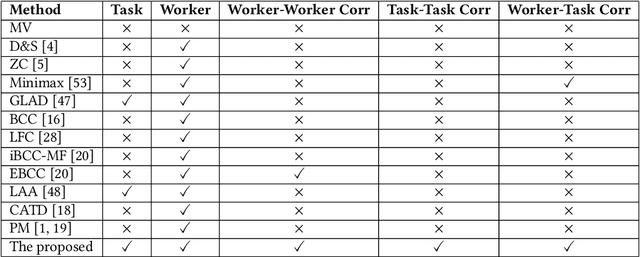
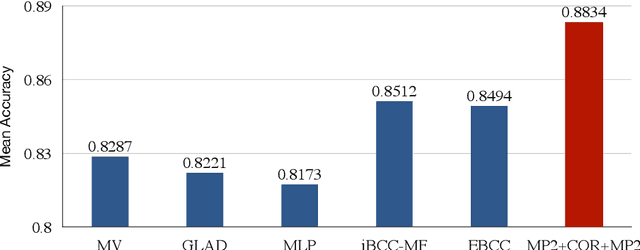
Crowdsourcing has attracted much attention for its convenience to collect labels from non-expert workers instead of experts. However, due to the high level of noise from the non-experts, an aggregation model that learns the true label by incorporating the source credibility is required. In this paper, we propose a novel framework based on graph neural networks for aggregating crowd labels. We construct a heterogeneous graph between workers and tasks and derive a new graph neural network to learn the representations of nodes and the true labels. Besides, we exploit the unknown latent interaction between the same type of nodes (workers or tasks) by adding a homogeneous attention layer in the graph neural networks. Experimental results on 13 real-world datasets show superior performance over state-of-the-art models.
Deep Graph Matching and Searching for Semantic Code Retrieval
Oct 24, 2020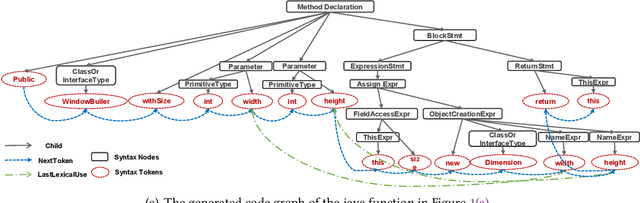

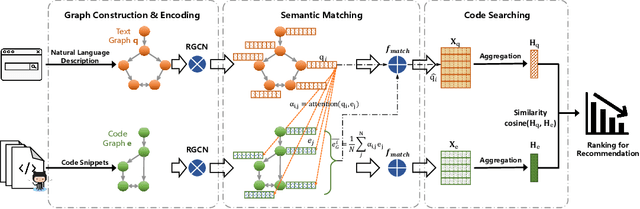

Code retrieval is to find the code snippet from a large corpus of source code repositories that highly matches the query of natural language description. Recent work mainly uses natural language processing techniques to process both query texts (i.e., human natural language) and code snippets (i.e., machine programming language), however neglecting the deep structured features of natural language query texts and source codes, both of which contain rich semantic information. In this paper, we propose an end-to-end deep graph matching and searching (DGMS) model based on graph neural networks for semantic code retrieval. To this end, we first represent both natural language query texts and programming language codes with the unified graph-structured data, and then use the proposed graph matching and searching model to retrieve the best matching code snippet. In particular, DGMS not only captures more structural information for individual query texts or code snippets but also learns the fine-grained similarity between them by a cross-attention based semantic matching operation. We evaluate the proposed DGMS model on two public code retrieval datasets from two representative programming languages (i.e., Java and Python). The experiment results demonstrate that DGMS significantly outperforms state-of-the-art baseline models by a large margin on both datasets. Moreover, our extensive ablation studies systematically investigate and illustrate the impact of each part of DGMS.