 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Global Model via Data-Free Knowledge Distillation for Non-IID Federated Learning
Mar 17, 2022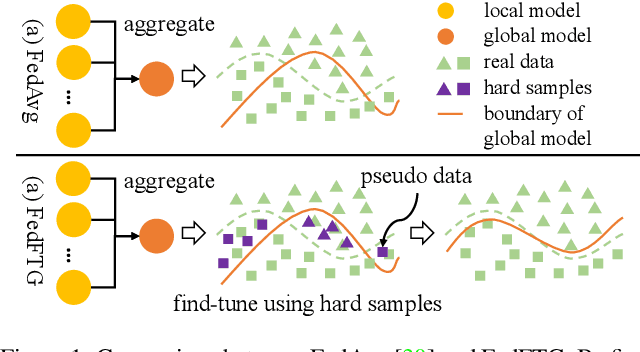
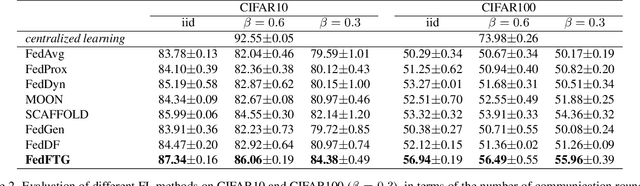
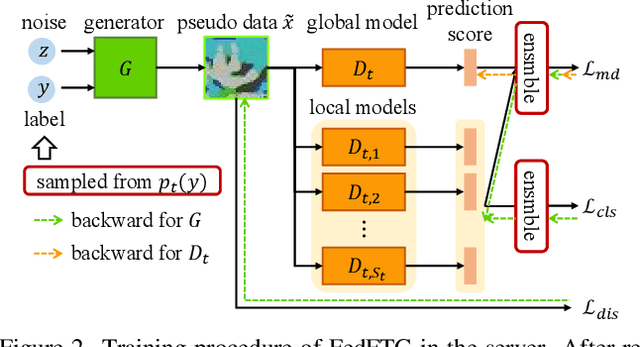
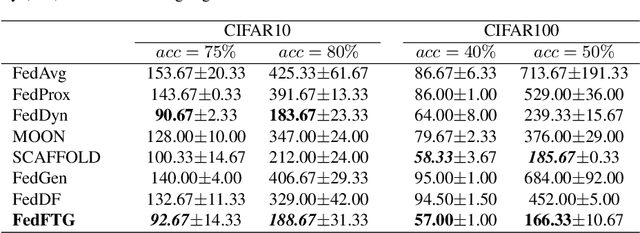
Federated Learning (FL) is an emerging distributed learning paradigm under privacy constraint. Data heterogeneity is one of the main challenges in FL, which results in slow convergence and degraded performance. Most existing approaches only tackle the heterogeneity challenge by restricting the local model update in client, ignoring the performance drop caused by direct global model aggregation. Instead, we propose a data-free knowledge distillation method to fine-tune the global model in the server (FedFTG), which relieves the issue of direct model aggregation. Concretely, FedFTG explores the input space of local models through a generator, and uses it to transfer the knowledge from local models to the global model. Besides, we propose a hard sample mining scheme to achieve effective knowledge distillation throughout the training. In addition, we develop customized label sampling and class-level ensemble to derive maximum utilization of knowledge, which implicitly mitigates the distribution discrepancy across clients. Extensive experiments show that our FedFTG significantly outperforms the state-of-the-art (SOTA) FL algorithms and can serve as a strong plugin for enhancing FedAvg, FedProx, FedDyn, and SCAFFOLD.
Bridging the Source-to-target Gap for Cross-domain Person Re-Identification with Intermediate Domains
Mar 03, 2022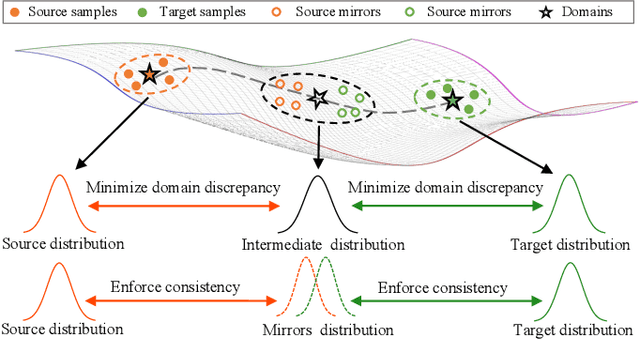
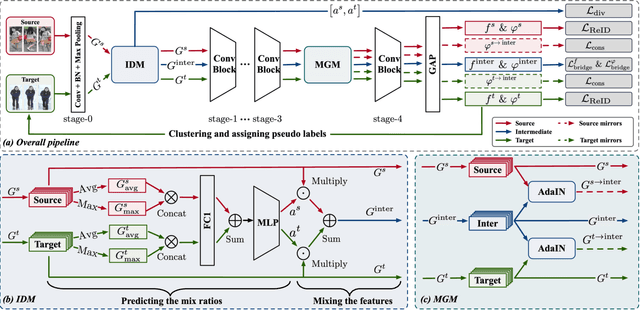
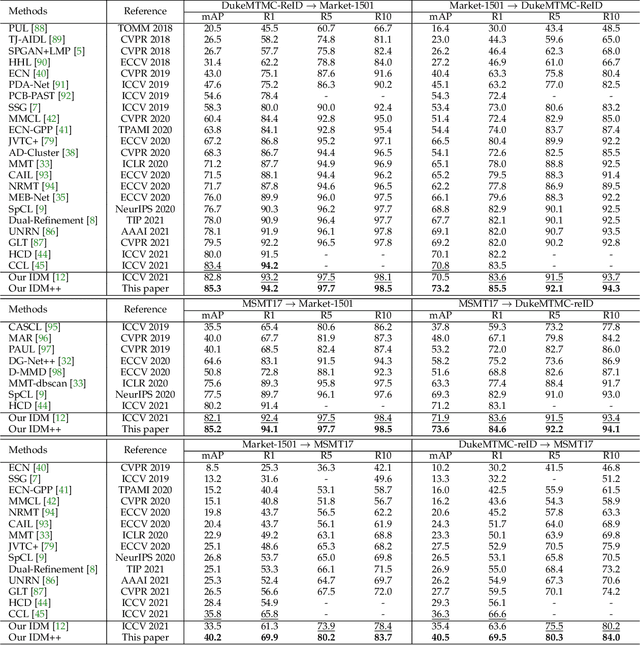
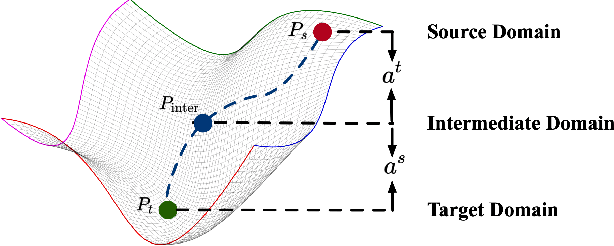
Cross-domain person re-identification (re-ID), such as unsupervised domain adaptive (UDA) re-ID, aims to transfer the identity-discriminative knowledge from the source to the target domain. Existing methods commonly consider the source and target domains are isolated from each other, i.e., no intermediate status is modeled between both domains. Directly transferring the knowledge between two isolated domains can be very difficult, especially when the domain gap is large. From a novel perspective, we assume these two domains are not completely isolated, but can be connected through intermediate domains. Instead of directly aligning the source and target domains against each other, we propose to align the source and target domains against their intermediate domains for a smooth knowledge transfer. To discover and utilize these intermediate domains, we propose an Intermediate Domain Module (IDM) and a Mirrors Generation Module (MGM). IDM has two functions: 1) it generates multiple intermediate domains by mixing the hidden-layer features from source and target domains and 2) it dynamically reduces the domain gap between the source / target domain features and the intermediate domain features. While IDM achieves good domain alignment, it introduces a side effect, i.e., the mix-up operation may mix the identities into a new identity and lose the original identities. To compensate this, MGM is introduced by mapping the features into the IDM-generated intermediate domains without changing their original identity. It allows to focus on minimizing domain variations to promote the alignment between the source / target domain and intermediate domains, which reinforces IDM into IDM++. We extensively evaluate our method under both the UDA and domain generalization (DG) scenarios and observe that IDM++ yields consistent performance improvement for cross-domain re-ID, achieving new state of the art.
Uncertainty Modeling for Out-of-Distribution Generalization
Feb 08, 2022
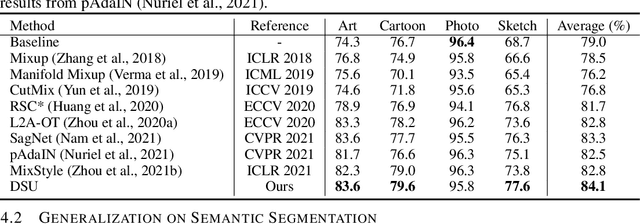
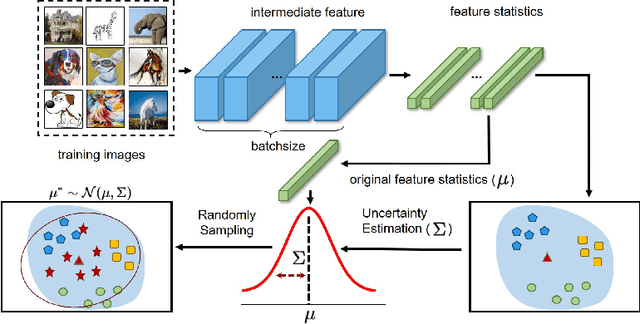

Though remarkable progress has been achieved in various vision tasks, deep neural networks still suffer obvious performance degradation when tested in out-of-distribution scenarios. We argue that the feature statistics (mean and standard deviation), which carry the domain characteristics of the training data, can be properly manipulated to improve the generalization ability of deep learning models. Common methods often consider the feature statistics as deterministic values measured from the learned features and do not explicitly consider the uncertain statistics discrepancy caused by potential domain shifts during testing. In this paper, we improve the network generalization ability by modeling the uncertainty of domain shifts with synthesized feature statistics during training. Specifically, we hypothesize that the feature statistic, after considering the potential uncertainties, follows a multivariate Gaussian distribution. Hence, each feature statistic is no longer a deterministic value, but a probabilistic point with diverse distribution possibilities. With the uncertain feature statistics, the models can be trained to alleviate the domain perturbations and achieve better robustness against potential domain shifts. Our method can be readily integrated into networks without additional parameters. Extensive experiments demonstrate that our proposed method consistently improves the network generalization ability on multiple vision tasks, including image classification, semantic segmentation, and instance retrieval. The code will be released soon at https://github.com/lixiaotong97/DSU.
Towards Low Light Enhancement with RAW Images
Dec 28, 2021



In this paper, we make the first benchmark effort to elaborate on the superiority of using RAW images in the low light enhancement and develop a novel alternative route to utilize RAW images in a more flexible and practical way. Inspired by a full consideration on the typical image processing pipeline, we are inspired to develop a new evaluation framework, Factorized Enhancement Model (FEM), which decomposes the properties of RAW images into measurable factors and provides a tool for exploring how properties of RAW images affect the enhancement performance empirically. The empirical benchmark results show that the Linearity of data and Exposure Time recorded in meta-data play the most critical role, which brings distinct performance gains in various measures over the approaches taking the sRGB images as input. With the insights obtained from the benchmark results in mind, a RAW-guiding Exposure Enhancement Network (REENet) is developed, which makes trade-offs between the advantages and inaccessibility of RAW images in real applications in a way of using RAW images only in the training phase. REENet projects sRGB images into linear RAW domains to apply constraints with corresponding RAW images to reduce the difficulty of modeling training. After that, in the testing phase, our REENet does not rely on RAW images. Experimental results demonstrate not only the superiority of REENet to state-of-the-art sRGB-based methods and but also the effectiveness of the RAW guidance and all components.
Video Coding for Machine: Compact Visual Representation Compression for Intelligent Collaborative Analytics
Oct 18, 2021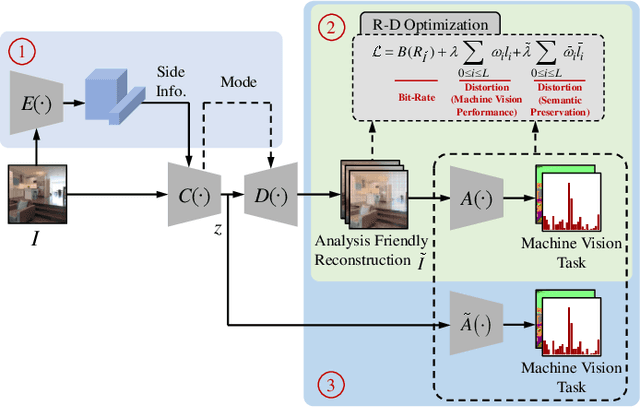
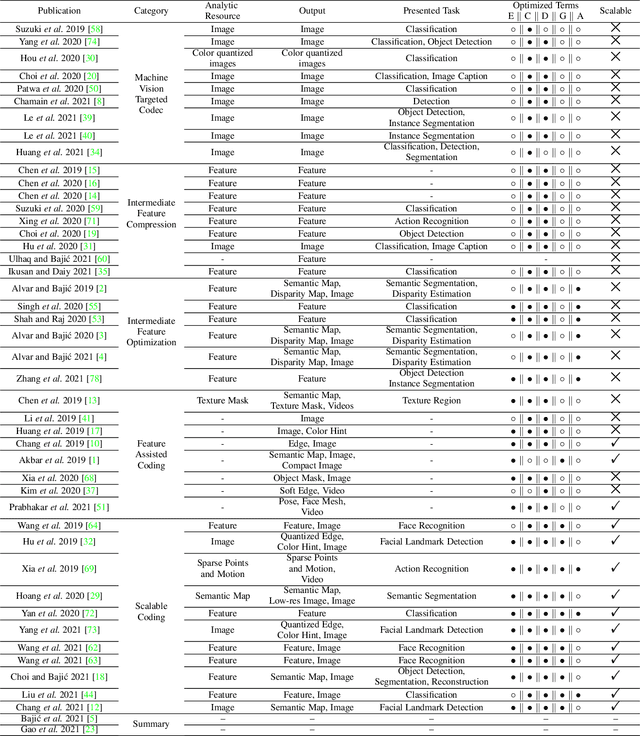
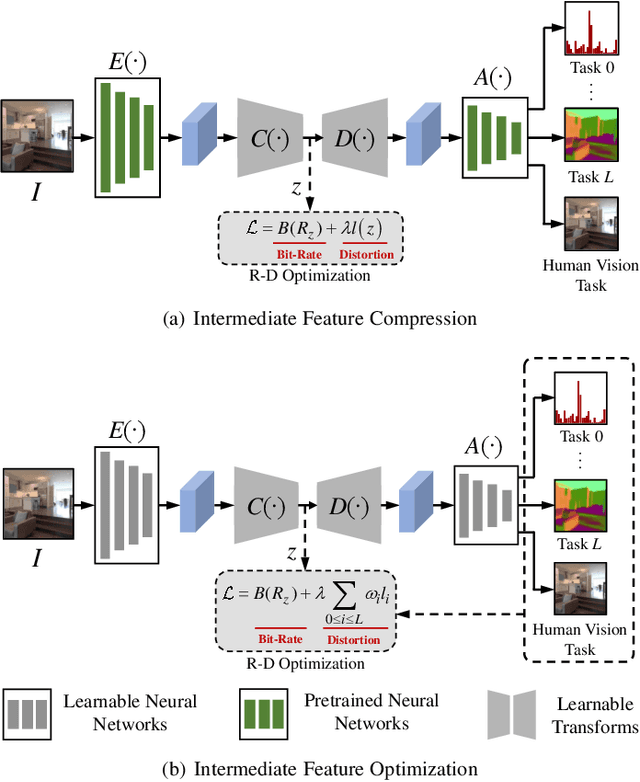
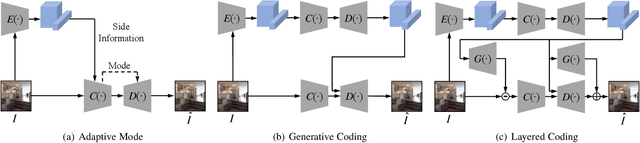
Video Coding for Machines (VCM) is committed to bridging to an extent separate research tracks of video/image compression and feature compression, and attempts to optimize compactness and efficiency jointly from a unified perspective of high accuracy machine vision and full fidelity human vision. In this paper, we summarize VCM methodology and philosophy based on existing academia and industrial efforts. The development of VCM follows a general rate-distortion optimization, and the categorization of key modules or techniques is established. From previous works, it is demonstrated that, although existing works attempt to reveal the nature of scalable representation in bits when dealing with machine and human vision tasks, there remains a rare study in the generality of low bit rate representation, and accordingly how to support a variety of visual analytic tasks. Therefore, we investigate a novel visual information compression for the analytics taxonomy problem to strengthen the capability of compact visual representations extracted from multiple tasks for visual analytics. A new perspective of task relationships versus compression is revisited. By keeping in mind the transferability among different machine vision tasks (e.g. high-level semantic and mid-level geometry-related), we aim to support multiple tasks jointly at low bit rates. In particular, to narrow the dimensionality gap between neural network generated features extracted from pixels and a variety of machine vision features/labels (e.g. scene class, segmentation labels), a codebook hyperprior is designed to compress the neural network-generated features. As demonstrated in our experiments, this new hyperprior model is expected to improve feature compression efficiency by estimating the signal entropy more accurately, which enables further investigation of the granularity of abstracting compact features among different tasks.
Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning
Aug 06, 2021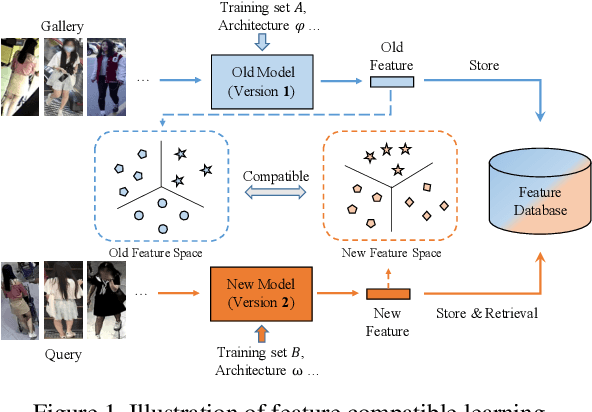
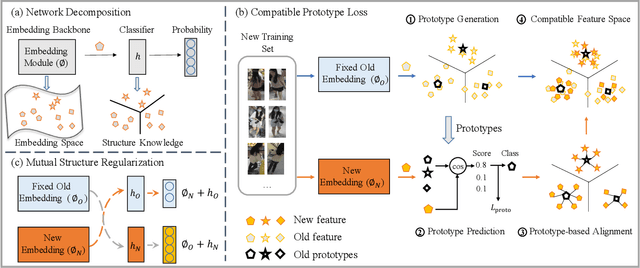
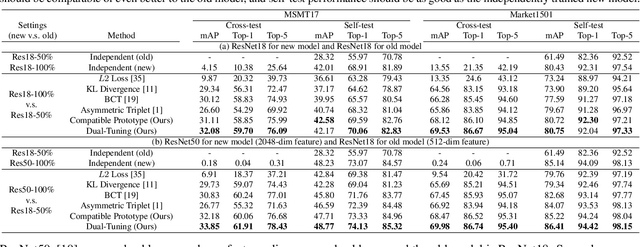
Visual retrieval system faces frequent model update and deployment. It is a heavy workload to re-extract features of the whole database every time.Feature compatibility enables the learned new visual features to be directly compared with the old features stored in the database. In this way, when updating the deployed model, we can bypass the inflexible and time-consuming feature re-extraction process. However, the old feature space that needs to be compatible is not ideal and faces the distribution discrepancy problem with the new space caused by different supervision losses. In this work, we propose a global optimization Dual-Tuning method to obtain feature compatibility against different networks and losses. A feature-level prototype loss is proposed to explicitly align two types of embedding features, by transferring global prototype information. Furthermore, we design a component-level mutual structural regularization to implicitly optimize the feature intrinsic structure. Experimental results on million-scale datasets demonstrate that our Dual-Tuning is able to obtain feature compatibility without sacrificing performance. (Our code will be avaliable at https://github.com/yanbai1993/Dual-Tuning)
IDM: An Intermediate Domain Module for Domain Adaptive Person Re-ID
Aug 05, 2021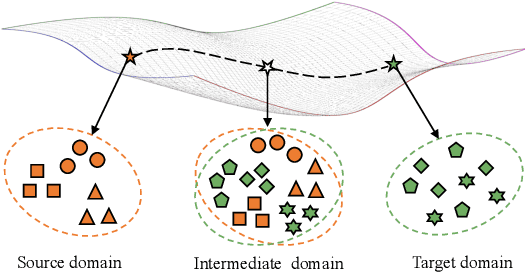
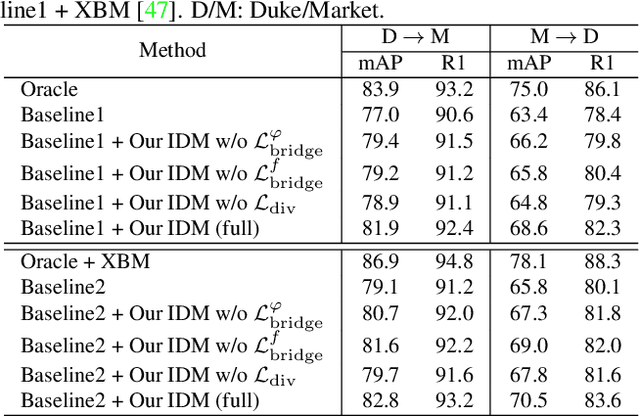
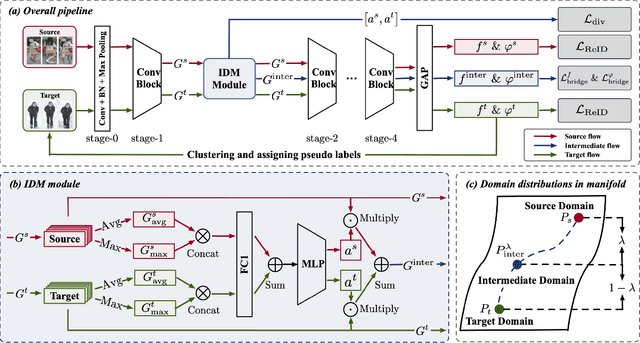
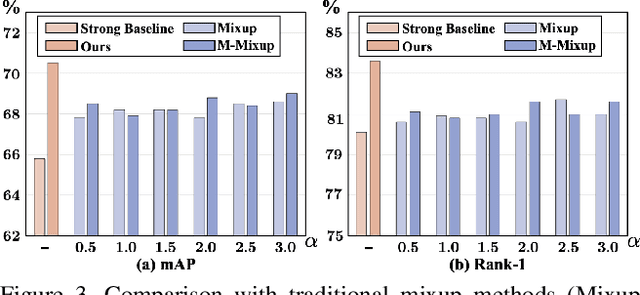
Unsupervised domain adaptive person re-identification (UDA re-ID) aims at transferring the labeled source domain's knowledge to improve the model's discriminability on the unlabeled target domain. From a novel perspective, we argue that the bridging between the source and target domains can be utilized to tackle the UDA re-ID task, and we focus on explicitly modeling appropriate intermediate domains to characterize this bridging. Specifically, we propose an Intermediate Domain Module (IDM) to generate intermediate domains' representations on-the-fly by mixing the source and target domains' hidden representations using two domain factors. Based on the "shortest geodesic path" definition, i.e., the intermediate domains along the shortest geodesic path between the two extreme domains can play a better bridging role, we propose two properties that these intermediate domains should satisfy. To ensure these two properties to better characterize appropriate intermediate domains, we enforce the bridge losses on intermediate domains' prediction space and feature space, and enforce a diversity loss on the two domain factors. The bridge losses aim at guiding the distribution of appropriate intermediate domains to keep the right distance to the source and target domains. The diversity loss serves as a regularization to prevent the generated intermediate domains from being over-fitting to either of the source and target domains. Our proposed method outperforms the state-of-the-arts by a large margin in all the common UDA re-ID tasks, and the mAP gain is up to 7.7% on the challenging MSMT17 benchmark. Code is available at https://github.com/SikaStar/IDM.
Generalizable Person Re-identification with Relevance-aware Mixture of Experts
May 19, 2021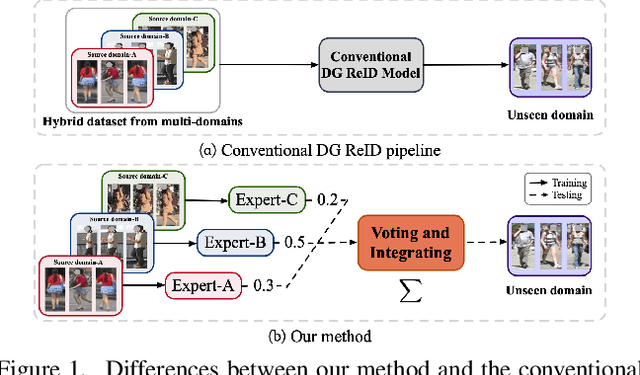
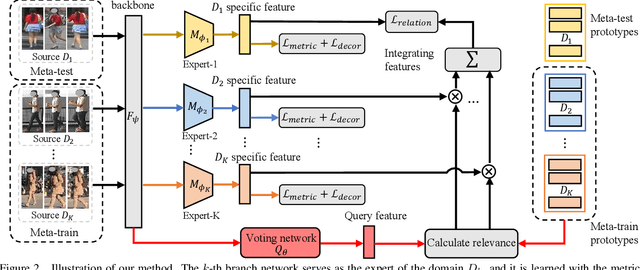
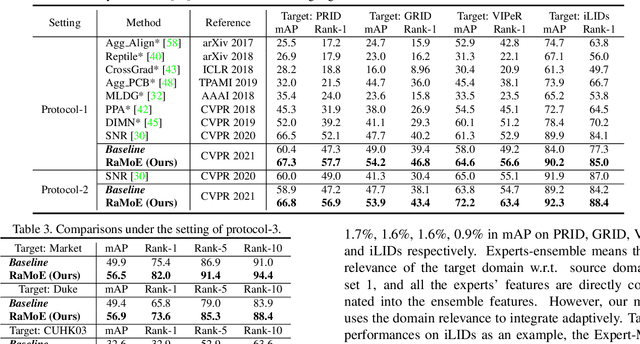
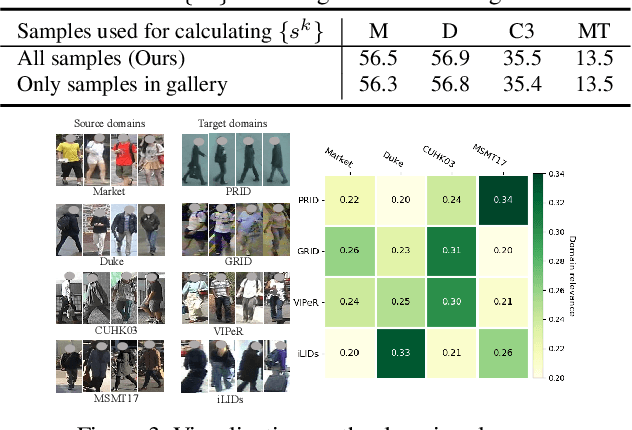
Domain generalizable (DG) person re-identification (ReID) is a challenging problem because we cannot access any unseen target domain data during training. Almost all the existing DG ReID methods follow the same pipeline where they use a hybrid dataset from multiple source domains for training, and then directly apply the trained model to the unseen target domains for testing. These methods often neglect individual source domains' discriminative characteristics and their relevances w.r.t. the unseen target domains, though both of which can be leveraged to help the model's generalization. To handle the above two issues, we propose a novel method called the relevance-aware mixture of experts (RaMoE), using an effective voting-based mixture mechanism to dynamically leverage source domains' diverse characteristics to improve the model's generalization. Specifically, we propose a decorrelation loss to make the source domain networks (experts) keep the diversity and discriminability of individual domains' characteristics. Besides, we design a voting network to adaptively integrate all the experts' features into the more generalizable aggregated features with domain relevance. Considering the target domains' invisibility during training, we propose a novel learning-to-learn algorithm combined with our relation alignment loss to update the voting network. Extensive experiments demonstrate that our proposed RaMoE outperforms the state-of-the-art methods.
Dual-Refinement: Joint Label and Feature Refinement for Unsupervised Domain Adaptive Person Re-Identification
Jan 17, 2021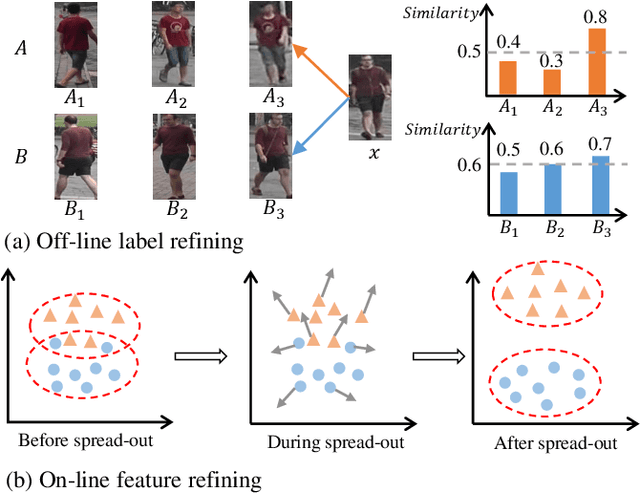
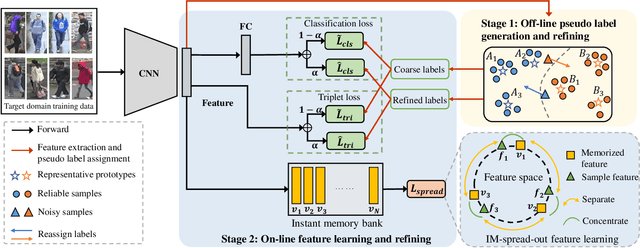
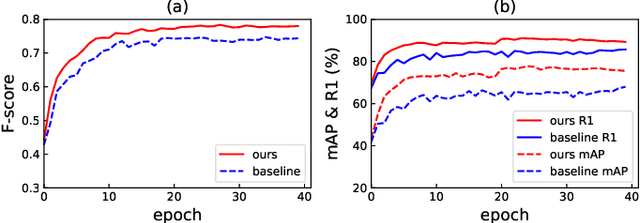
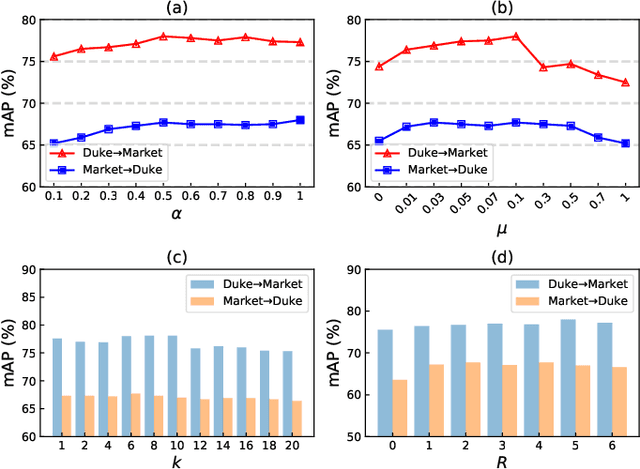
Unsupervised domain adaptive (UDA) person re-identification (re-ID) is a challenging task due to the missing of labels for the target domain data. To handle this problem, some recent works adopt clustering algorithms to off-line generate pseudo labels, which can then be used as the supervision signal for on-line feature learning in the target domain. However, the off-line generated labels often contain lots of noise that significantly hinders the discriminability of the on-line learned features, and thus limits the final UDA re-ID performance. To this end, we propose a novel approach, called Dual-Refinement, that jointly refines pseudo labels at the off-line clustering phase and features at the on-line training phase, to alternatively boost the label purity and feature discriminability in the target domain for more reliable re-ID. Specifically, at the off-line phase, a new hierarchical clustering scheme is proposed, which selects representative prototypes for every coarse cluster. Thus, labels can be effectively refined by using the inherent hierarchical information of person images. Besides, at the on-line phase, we propose an instant memory spread-out (IM-spread-out) regularization, that takes advantage of the proposed instant memory bank to store sample features of the entire dataset and enable spread-out feature learning over the entire training data instantly. Our Dual-Refinement method reduces the influence of noisy labels and refines the learned features within the alternative training process. Experiments demonstrate that our method outperforms the state-of-the-art methods by a large margin.
Video Coding for Machines: A Paradigm of Collaborative Compression and Intelligent Analytics
Jan 13, 2020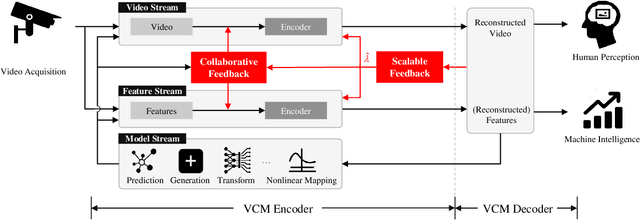
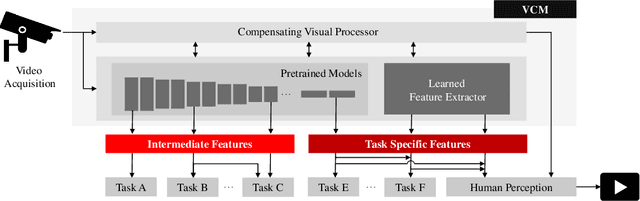
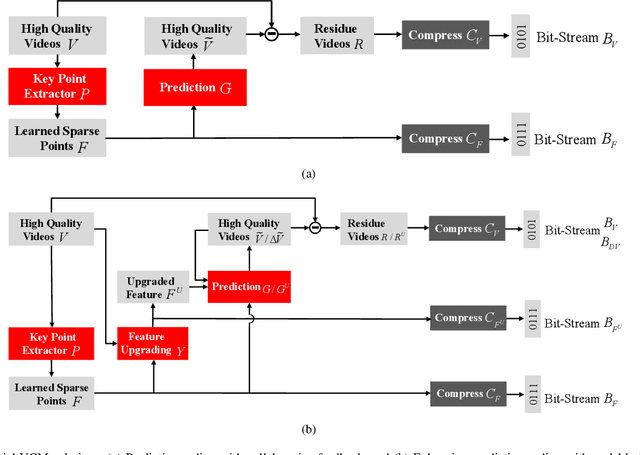

Video coding, which targets to compress and reconstruct the whole frame, and feature compression, which only preserves and transmits the most critical information, stand at two ends of the scale. That is, one is with compactness and efficiency to serve for machine vision, and the other is with full fidelity, bowing to human perception. The recent endeavors in imminent trends of video compression, e.g. deep learning based coding tools and end-to-end image/video coding, and MPEG-7 compact feature descriptor standards, i.e. Compact Descriptors for Visual Search and Compact Descriptors for Video Analysis, promote the sustainable and fast development in their own directions, respectively. In this paper, thanks to booming AI technology, e.g. prediction and generation models, we carry out exploration in the new area, Video Coding for Machines (VCM), arising from the emerging MPEG standardization efforts1. Towards collaborative compression and intelligent analytics, VCM attempts to bridge the gap between feature coding for machine vision and video coding for human vision. Aligning with the rising Analyze then Compress instance Digital Retina, the definition, formulation, and paradigm of VCM are given first. Meanwhile, we systematically review state-of-the-art techniques in video compression and feature compression from the unique perspective of MPEG standardization, which provides the academic and industrial evidence to realize the collaborative compression of video and feature streams in a broad range of AI applications. Finally, we come up with potential VCM solutions, and the preliminary results have demonstrated the performance and efficiency gains. Further direction is discussed as well.