 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Learn Variational Semantic Memory
Oct 20, 2020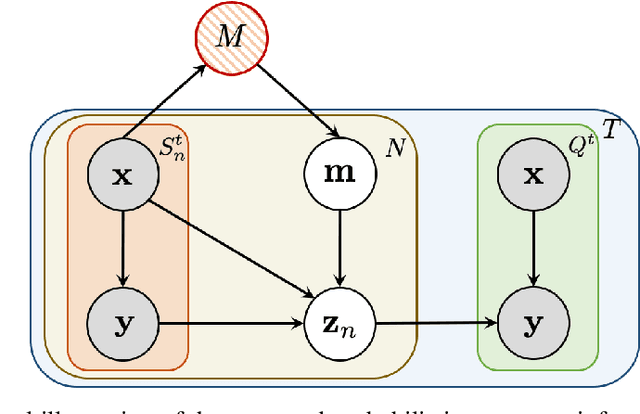

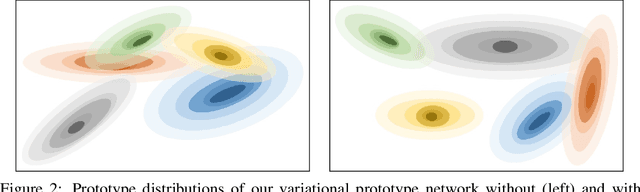

In this paper, we introduce variational semantic memory into meta-learning to acquire long-term knowledge for few-shot learning. The variational semantic memory accrues and stores semantic information for the probabilistic inference of class prototypes in a hierarchical Bayesian framework. The semantic memory is grown from scratch and gradually consolidated by absorbing information from tasks it experiences. By doing so, it is able to accumulate long-term, general knowledge that enables it to learn new concepts of objects. We formulate memory recall as the variational inference of a latent memory variable from addressed contents, which offers a principled way to adapt the knowledge to individual tasks. Our variational semantic memory, as a new long-term memory module, confers principled recall and update mechanisms that enable semantic information to be efficiently accrued and adapted for few-shot learning. Experiments demonstrate that the probabilistic modelling of prototypes achieves a more informative representation of object classes compared to deterministic vectors. The consistent new state-of-the-art performance on four benchmarks shows the benefit of variational semantic memory in boosting few-shot recognition.
Learning Selective Mutual Attention and Contrast for RGB-D Saliency Detection
Oct 12, 2020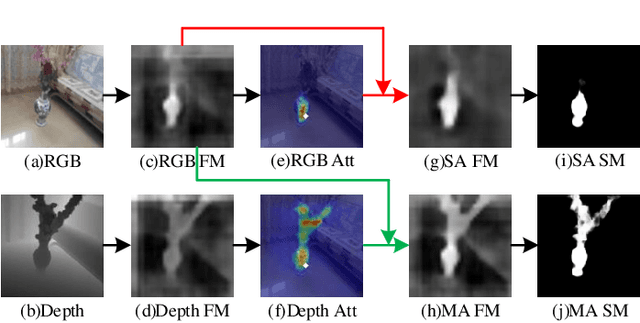
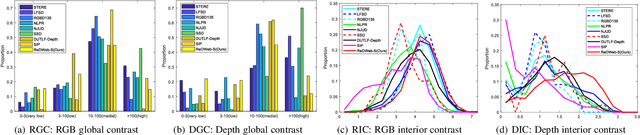
How to effectively fuse cross-modal information is the key problem for RGB-D salient object detection. Early fusion and the result fusion schemes fuse RGB and depth information at the input and output stages, respectively, hence incur the problem of distribution gap or information loss. Many models use the feature fusion strategy but are limited by the low-order point-to-point fusion methods. In this paper, we propose a novel mutual attention model by fusing attention and contexts from different modalities. We use the non-local attention of one modality to propagate long-range contextual dependencies for the other modality, thus leveraging complementary attention cues to perform high-order and trilinear cross-modal interaction. We also propose to induce contrast inference from the mutual attention and obtain a unified model. Considering low-quality depth data may detriment the model performance, we further propose selective attention to reweight the added depth cues. We embed the proposed modules in a two-stream CNN for RGB-D SOD. Experimental results have demonstrated the effectiveness of our proposed model. Moreover, we also construct a new challenging large-scale RGB-D SOD dataset with high-quality, thus can both promote the training and evaluation of deep models.
From Handcrafted to Deep Features for Pedestrian Detection: A Survey
Oct 01, 2020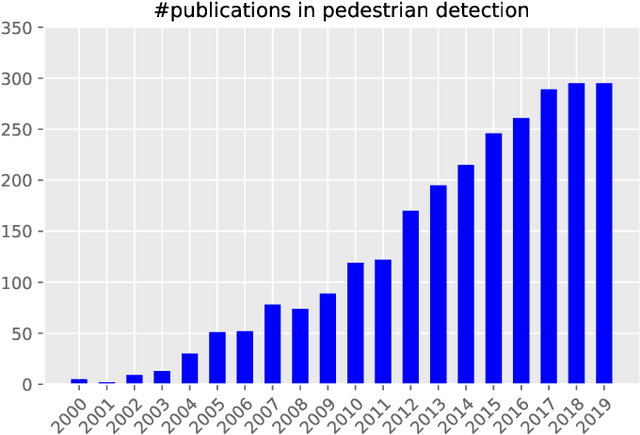
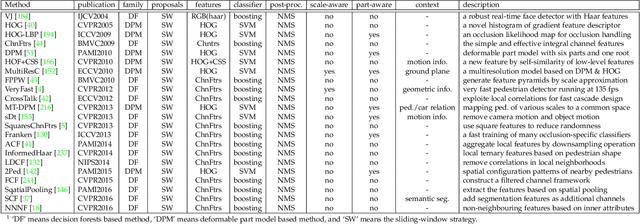
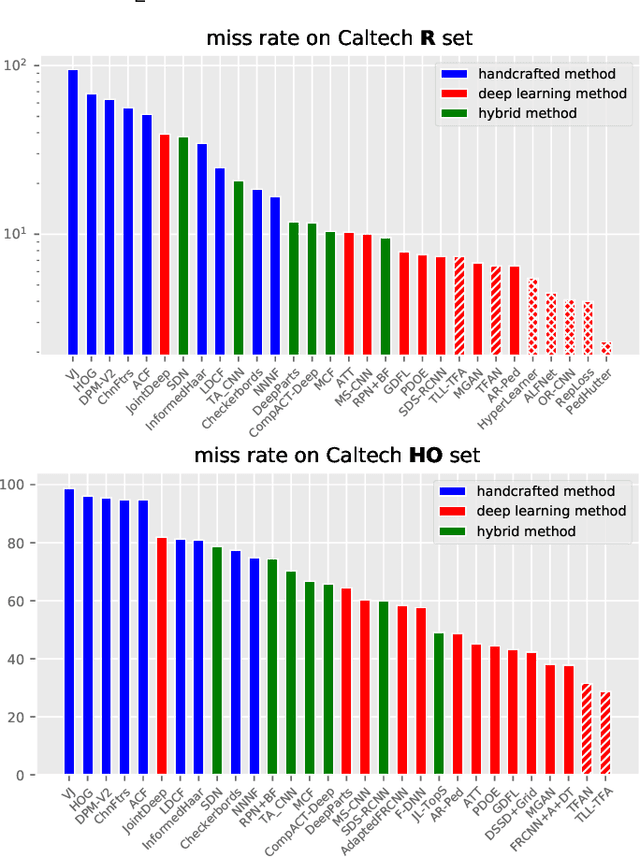
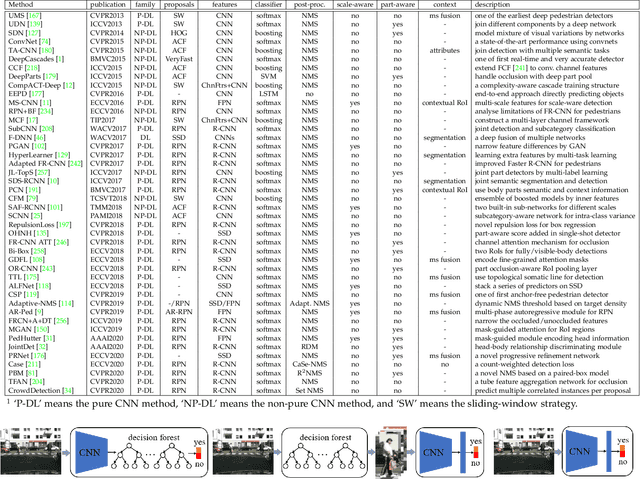
Pedestrian detection is an important but challenging problem in computer vision, especially in human-centric tasks. Over the past decade, significant improvement has been witnessed with the help of handcrafted features and deep features. Here we present a comprehensive survey on recent advances in pedestrian detection. First, we provide a detailed review of single-spectral pedestrian detection that includes handcrafted features based methods and deep features based approaches. For handcrafted features based methods, we present an extensive review of approaches and find that handcrafted features with large freedom degrees in shape and space have better performance. In the case of deep features based approaches, we split them into pure CNN based methods and those employing both handcrafted and CNN based features. We give the statistical analysis and tendency of these methods, where feature enhanced, part-aware, and post-processing methods have attracted main attention. In addition to single-spectral pedestrian detection, we also review multi-spectral pedestrian detection, which provides more robust features for illumination variance. Furthermore, we introduce some related datasets and evaluation metrics, and compare some representative methods. We conclude this survey by emphasizing open problems that need to be addressed and highlighting various future directions. Researchers can track an up-to-date list at https://github.com/JialeCao001/PedSurvey.
Group Whitening: Balancing Learning Efficiency and Representational Capacity
Sep 28, 2020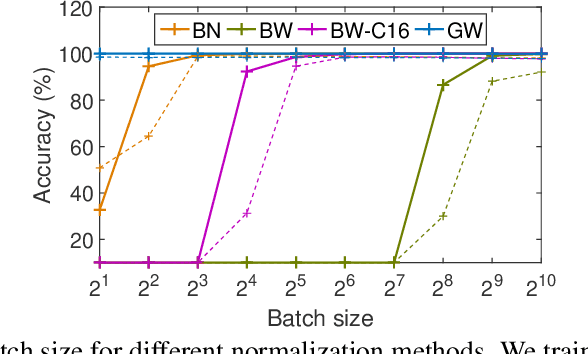
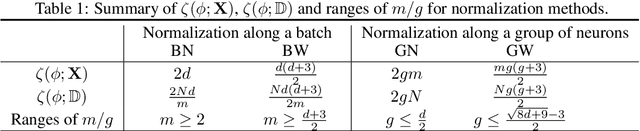
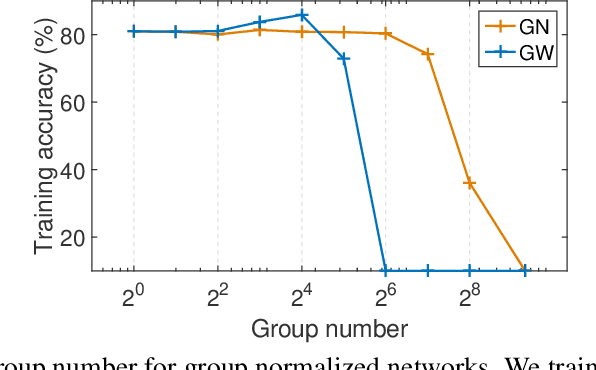

Batch normalization (BN) is an important technique commonly incorporated into deep learning models to perform standardization within mini-batches. The merits of BN in improving model's learning efficiency can be further amplified by applying whitening, while its drawbacks in estimating population statistics for inference can be avoided through group normalization (GN). This paper proposes group whitening (GW), which elaborately exploits the advantages of the whitening operation and avoids the disadvantages of normalization within mini-batches. Specifically, GW divides the neurons of a sample into groups for standardization, like GN, and then further decorrelates the groups. In addition, we quantitatively analyze the constraint imposed by normalization, and show how the batch size (group number) affects the performance of batch (group) normalized networks, from the perspective of model's representational capacity. This analysis provides theoretical guidance for applying GW in practice. Finally, we apply the proposed GW to ResNet and ResNeXt architectures and conduct experiments on the ImageNet and COCO benchmarks. Results show that GW consistently improves the performance of different architectures, with absolute gains of $1.02\%$ $\sim$ $1.49\%$ in top-1 accuracy on ImageNet and $1.82\%$ $\sim$ $3.21\%$ in bounding box AP on COCO.
Normalization Techniques in Training DNNs: Methodology, Analysis and Application
Sep 27, 2020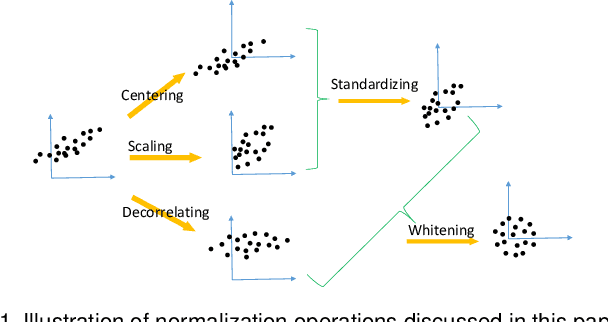
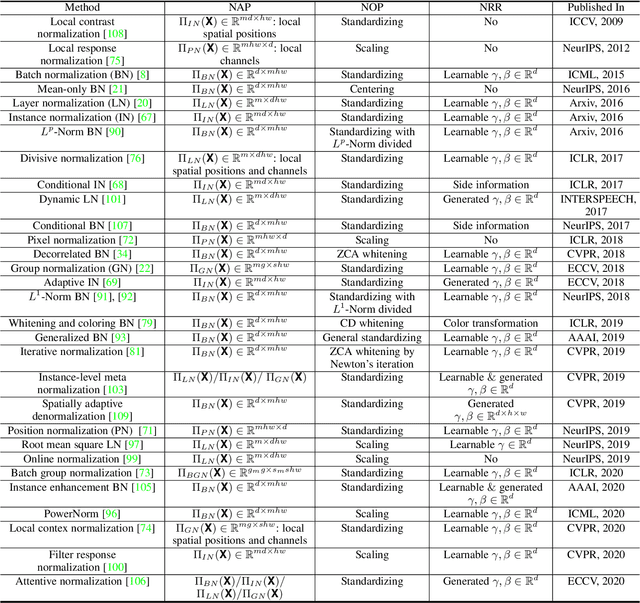
Normalization techniques are essential for accelerating the training and improving the generalization of deep neural networks (DNNs), and have successfully been used in various applications. This paper reviews and comments on the past, present and future of normalization methods in the context of DNN training. We provide a unified picture of the main motivation behind different approaches from the perspective of optimization, and present a taxonomy for understanding the similarities and differences between them. Specifically, we decompose the pipeline of the most representative normalizing activation methods into three components: the normalization area partitioning, normalization operation and normalization representation recovery. In doing so, we provide insight for designing new normalization technique. Finally, we discuss the current progress in understanding normalization methods, and provide a comprehensive review of the applications of normalization for particular tasks, in which it can effectively solve the key issues.
Exploring global diverse attention via pairwise temporal relation for video summarization
Sep 23, 2020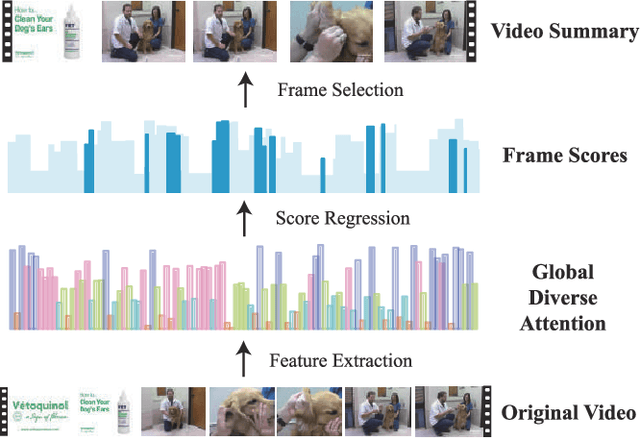
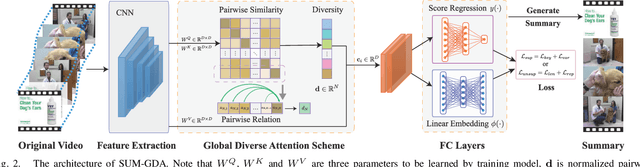
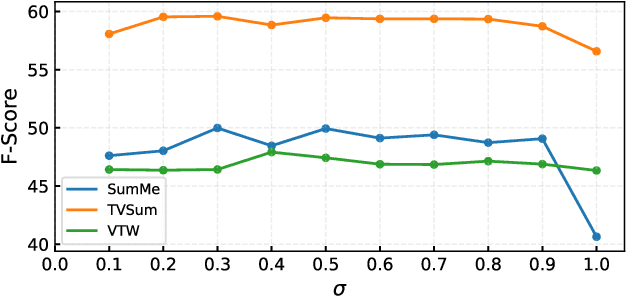
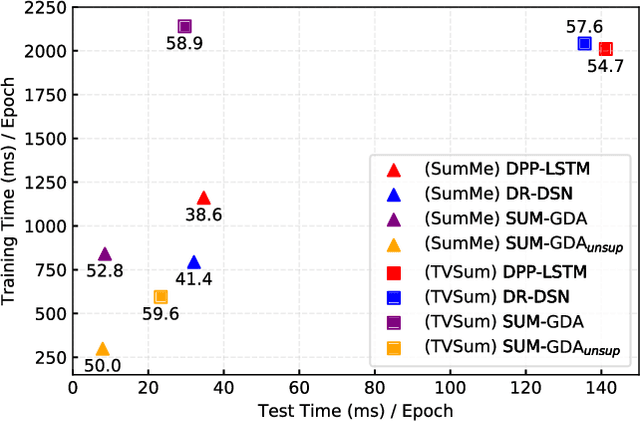
Video summarization is an effective way to facilitate video searching and browsing. Most of existing systems employ encoder-decoder based recurrent neural networks, which fail to explicitly diversify the system-generated summary frames while requiring intensive computations. In this paper, we propose an efficient convolutional neural network architecture for video SUMmarization via Global Diverse Attention called SUM-GDA, which adapts attention mechanism in a global perspective to consider pairwise temporal relations of video frames. Particularly, the GDA module has two advantages: 1) it models the relations within paired frames as well as the relations among all pairs, thus capturing the global attention across all frames of one video; 2) it reflects the importance of each frame to the whole video, leading to diverse attention on these frames. Thus, SUM-GDA is beneficial for generating diverse frames to form satisfactory video summary. Extensive experiments on three data sets, i.e., SumMe, TVSum, and VTW, have demonstrated that SUM-GDA and its extension outperform other competing state-of-the-art methods with remarkable improvements. In addition, the proposed models can be run in parallel with significantly less computational costs, which helps the deployment in highly demanding applications.
* 12 pages, 8 figures
A Benchmark for Studying Diabetic Retinopathy: Segmentation, Grading, and Transferability
Aug 30, 2020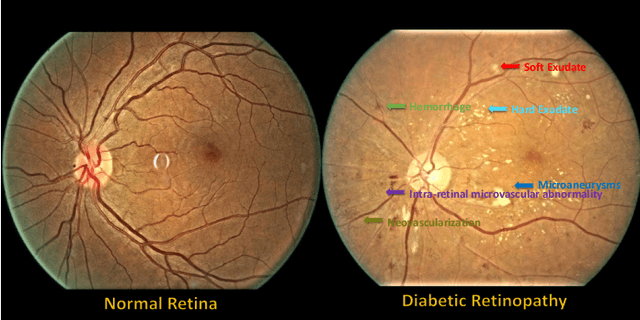
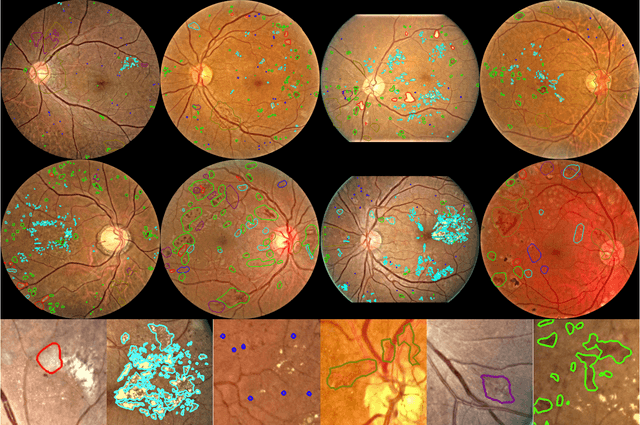
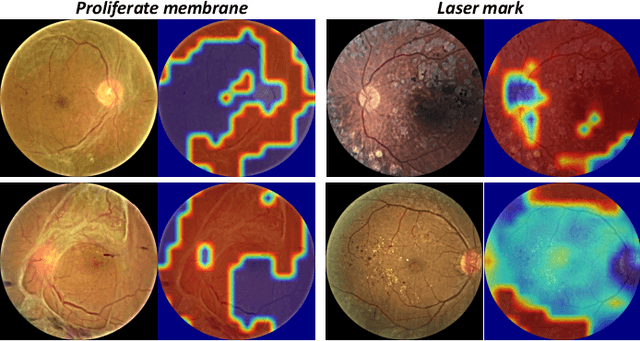
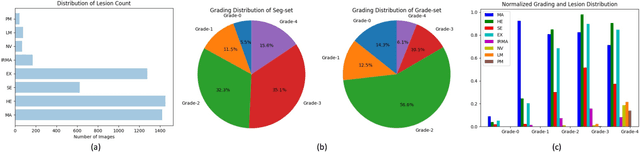
People with diabetes are at risk of developing an eye disease called diabetic retinopathy (DR). This disease occurs when high blood glucose levels cause damage to blood vessels in the retina. Computer-aided DR diagnosis is a promising tool for early detection of DR and severity grading, due to the great success of deep learning. However, most current DR diagnosis systems do not achieve satisfactory performance or interpretability for ophthalmologists, due to the lack of training data with consistent and fine-grained annotations. To address this problem, we construct a large fine-grained annotated DR dataset containing 2,842 images (FGADR). This dataset has 1,842 images with pixel-level DR-related lesion annotations, and 1,000 images with image-level labels graded by six board-certified ophthalmologists with intra-rater consistency. The proposed dataset will enable extensive studies on DR diagnosis. We set up three benchmark tasks for evaluation: 1. DR lesion segmentation; 2. DR grading by joint classification and segmentation; 3. Transfer learning for ocular multi-disease identification. Moreover, a novel inductive transfer learning method is introduced for the third task. Extensive experiments using different state-of-the-art methods are conducted on our FGADR dataset, which can serve as baselines for future research.
Structure Preserving Stain Normalization of Histopathology Images Using Self-Supervised Semantic Guidance
Aug 05, 2020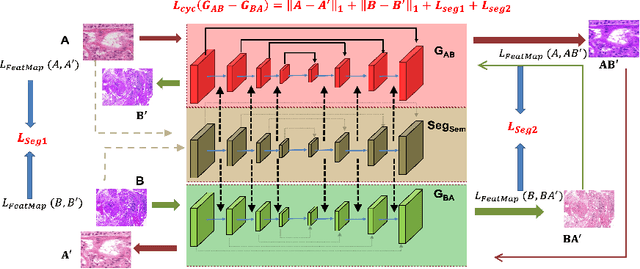
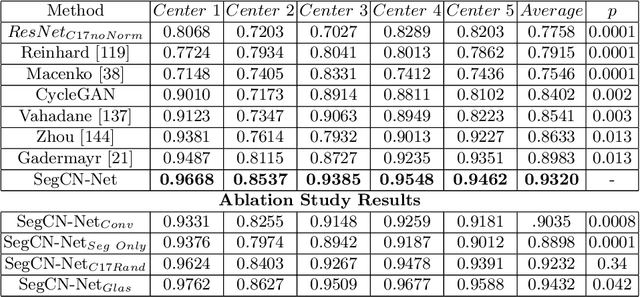
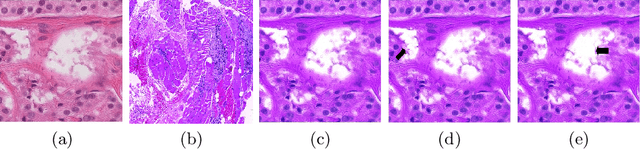
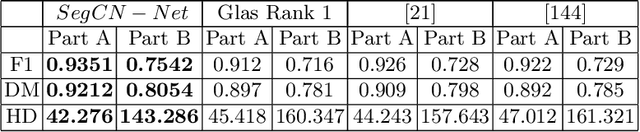
Although generative adversarial network (GAN) based style transfer is state of the art in histopathology color-stain normalization, they do not explicitly integrate structural information of tissues. We propose a self-supervised approach to incorporate semantic guidance into a GAN based stain normalization framework and preserve detailed structural information. Our method does not require manual segmentation maps which is a significant advantage over existing methods. We integrate semantic information at different layers between a pre-trained semantic network and the stain color normalization network. The proposed scheme outperforms other color normalization methods leading to better classification and segmentation performance.
RGB-D Salient Object Detection: A Survey
Aug 01, 2020
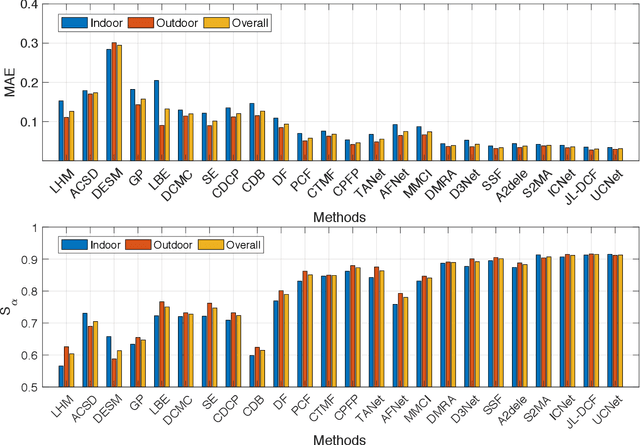


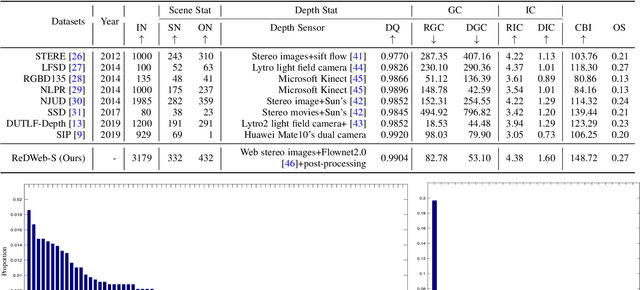
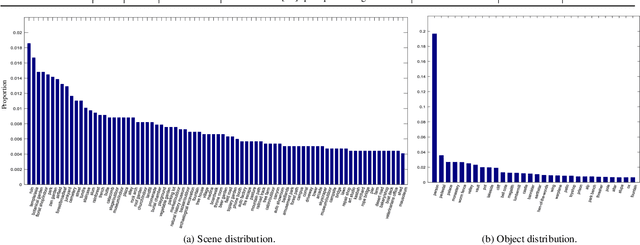
Salient object detection (SOD), which simulates the human visual perception system to locate the most attractive object(s) in a scene, has been widely applied to various computer vision tasks. Now, with the advent of depth sensors, depth maps with affluent spatial information that can be beneficial in boosting the performance of SOD, can easily be captured. Although various RGB-D based SOD models with promising performance have been proposed over the past several years, an in-depth understanding of these models and challenges in this topic remains lacking. In this paper, we provide a comprehensive survey of RGB-D based SOD models from various perspectives, and review related benchmark datasets in detail. Further, considering that the light field can also provide depth maps, we review SOD models and popular benchmark datasets from this domain as well. Moreover, to investigate the SOD ability of existing models, we carry out a comprehensive evaluation, as well as attribute-based evaluation of several representative RGB-D based SOD models. Finally, we discuss several challenges and open directions of RGB-D based SOD for future research. All collected models, benchmark datasets, source code links, datasets constructed for attribute-based evaluation, and codes for evaluation will be made publicly available at https://github.com/taozh2017/RGBDSODsurvey
SipMask: Spatial Information Preservation for Fast Image and Video Instance Segmentation
Jul 29, 2020
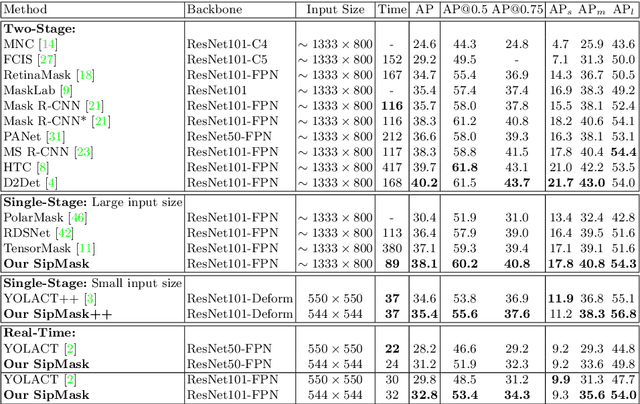
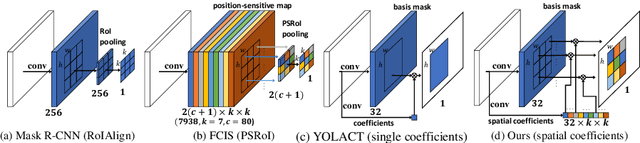
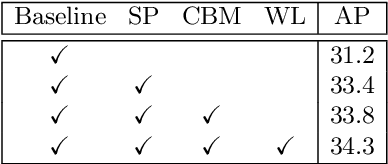
Single-stage instance segmentation approaches have recently gained popularity due to their speed and simplicity, but are still lagging behind in accuracy, compared to two-stage methods. We propose a fast single-stage instance segmentation method, called SipMask, that preserves instance-specific spatial information by separating mask prediction of an instance to different sub-regions of a detected bounding-box. Our main contribution is a novel light-weight spatial preservation (SP) module that generates a separate set of spatial coefficients for each sub-region within a bounding-box, leading to improved mask predictions. It also enables accurate delineation of spatially adjacent instances. Further, we introduce a mask alignment weighting loss and a feature alignment scheme to better correlate mask prediction with object detection. On COCO test-dev, our SipMask outperforms the existing single-stage methods. Compared to the state-of-the-art single-stage TensorMask, SipMask obtains an absolute gain of 1.0% (mask AP), while providing a four-fold speedup. In terms of real-time capabilities, SipMask outperforms YOLACT with an absolute gain of 3.0% (mask AP) under similar settings, while operating at comparable speed on a Titan Xp. We also evaluate our SipMask for real-time video instance segmentation, achieving promising results on YouTube-VIS dataset. The source code is available at https://github.com/JialeCao001/SipMask.