 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEKD: Self-Evolving Keypoint Detection and Description
Jun 09, 2020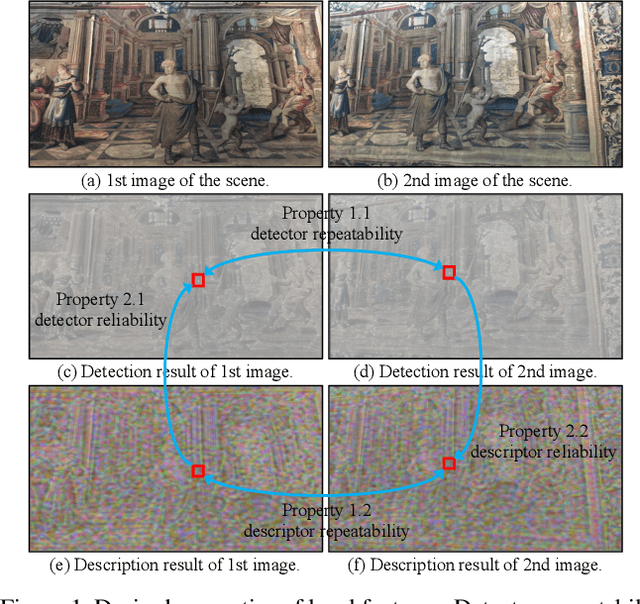
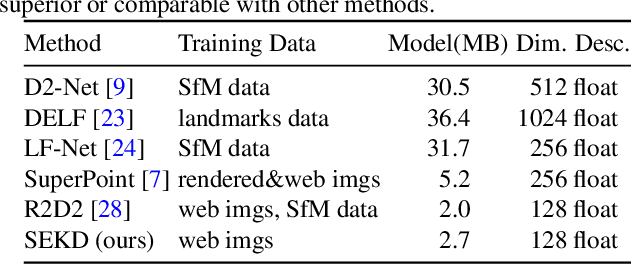
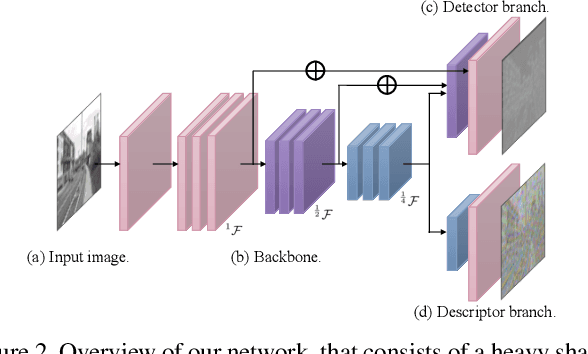
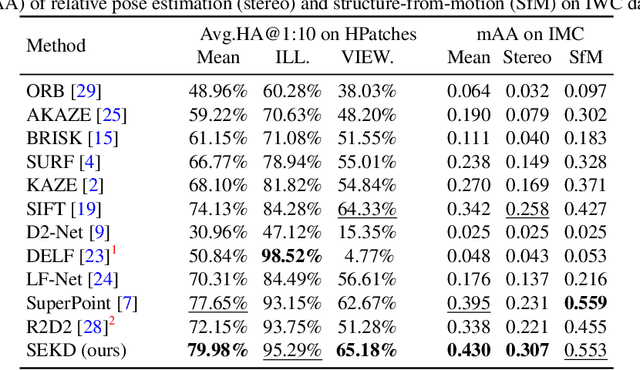
Researchers have attempted utilizing deep neural network (DNN) to learn novel local features from images inspired by its recent successes on a variety of vision tasks. However, existing DNN-based algorithms have not achieved such remarkable progress that could be partly attributed to insufficient utilization of the interactive characters between local feature detector and descriptor. To alleviate these difficulties, we emphasize two desired properties, i.e., repeatability and reliability, to simultaneously summarize the inherent and interactive characters of local feature detector and descriptor. Guided by these properties, a self-supervised framework, namely self-evolving keypoint detection and description (SEKD), is proposed to learn an advanced local feature model from unlabeled natural images. Additionally, to have performance guarantees, novel training strategies have also been dedicatedly designed to minimize the gap between the learned feature and its properties. We benchmark the proposed method on homography estimation, relative pose estimation, and structure-from-motion tasks. Extensive experimental results demonstrate that the proposed method outperforms popular hand-crafted and DNN-based methods by remarkable margins. Ablation studies also verify the effectiveness of each critical training strategy. We will release our code along with the trained model publicly.
Accelerating Neural Network Inference by Overflow Aware Quantization
May 27, 2020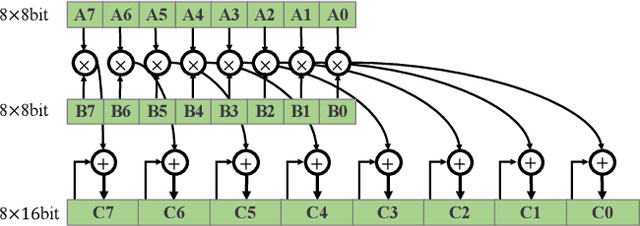
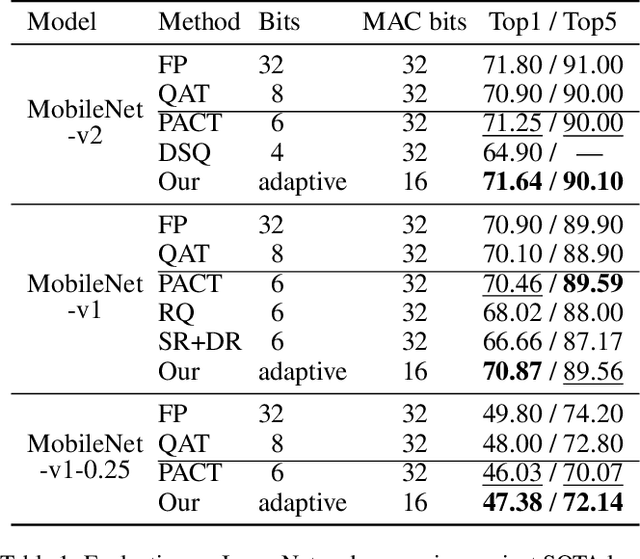
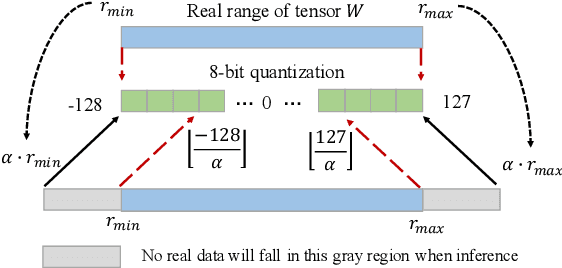
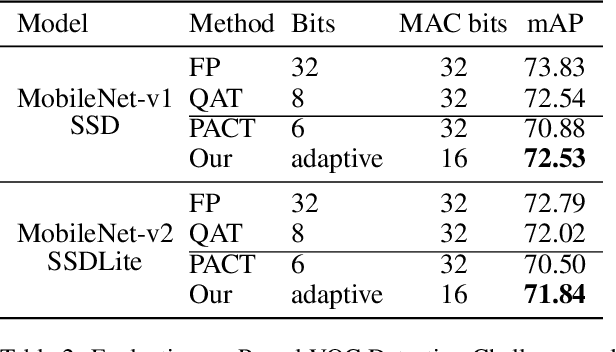
The inherent heavy computation of deep neural networks prevents their widespread applications. A widely used method for accelerating model inference is quantization, by replacing the input operands of a network using fixed-point values. Then the majority of computation costs focus on the integer matrix multiplication accumulation. In fact, high-bit accumulator leads to partially wasted computation and low-bit one typically suffers from numerical overflow. To address this problem, we propose an overflow aware quantization method by designing trainable adaptive fixed-point representation, to optimize the number of bits for each input tensor while prohibiting numeric overflow during the computation. With the proposed method, we are able to fully utilize the computing power to minimize the quantization loss and obtain optimized inference performance. To verify the effectiveness of our method, we conduct image classification, object detection, and semantic segmentation tasks on ImageNet, Pascal VOC, and COCO datasets, respectively. Experimental results demonstrate that the proposed method can achieve comparable performance with state-of-the-art quantization methods while accelerating the inference process by about 2 times.
SE-KGE: A Location-Aware Knowledge Graph Embedding Model for Geographic Question Answering and Spatial Semantic Lifting
Apr 25, 2020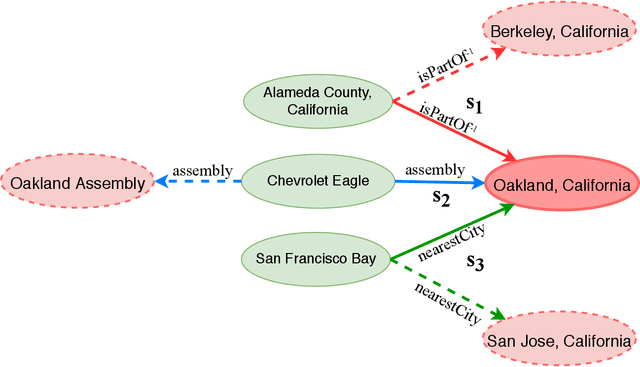


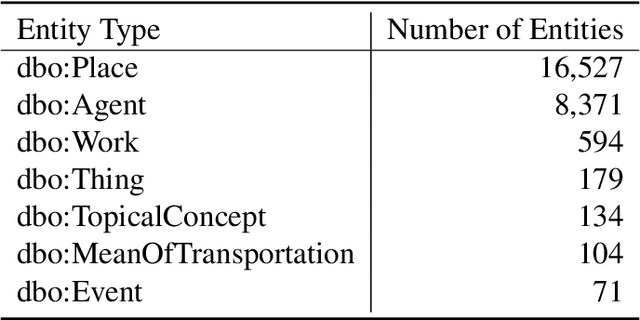
Learning knowledge graph (KG) embeddings is an emerging technique for a variety of downstream tasks such as summarization, link prediction, information retrieval, and question answering. However, most existing KG embedding models neglect space and, therefore, do not perform well when applied to (geo)spatial data and tasks. For those models that consider space, most of them primarily rely on some notions of distance. These models suffer from higher computational complexity during training while still losing information beyond the relative distance between entities. In this work, we propose a location-aware KG embedding model called SE-KGE. It directly encodes spatial information such as point coordinates or bounding boxes of geographic entities into the KG embedding space. The resulting model is capable of handling different types of spatial reasoning. We also construct a geographic knowledge graph as well as a set of geographic query-answer pairs called DBGeo to evaluate the performance of SE-KGE in comparison to multiple baselines. Evaluation results show that SE-KGE outperforms these baselines on the DBGeo dataset for geographic logic query answering task. This demonstrates the effectiveness of our spatially-explicit model and the importance of considering the scale of different geographic entities. Finally, we introduce a novel downstream task called spatial semantic lifting which links an arbitrary location in the study area to entities in the KG via some relations. Evaluation on DBGeo shows that our model outperforms the baseline by a substantial margin.
* Accepted to Transactions in GIS
Semantically-Enriched Search Engine for Geoportals: A Case Study with ArcGIS Online
Mar 14, 2020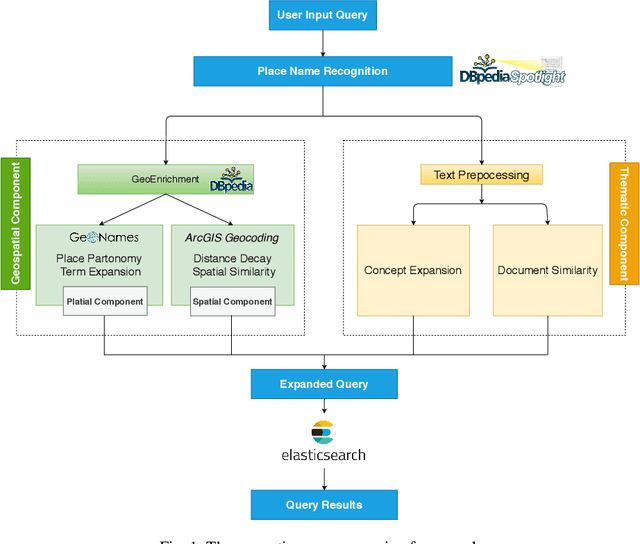
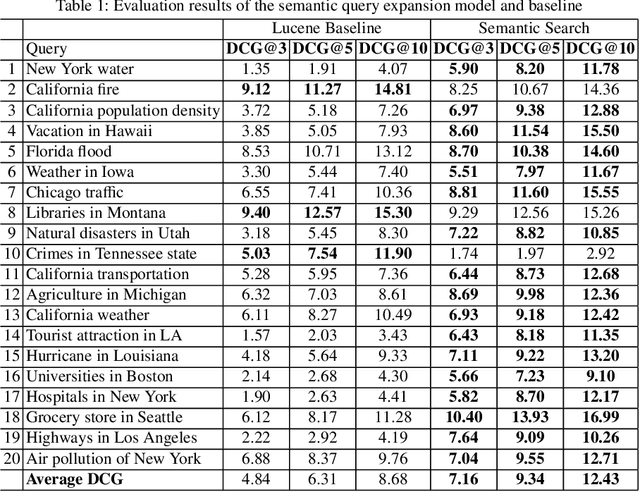

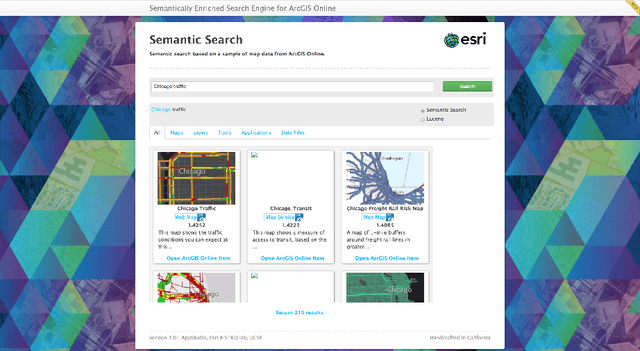
Many geoportals such as ArcGIS Online are established with the goal of improving geospatial data reusability and achieving intelligent knowledge discovery. However, according to previous research, most of the existing geoportals adopt Lucene-based techniques to achieve their core search functionality, which has a limited ability to capture the user's search intentions. To better understand a user's search intention, query expansion can be used to enrich the user's query by adding semantically similar terms. In the context of geoportals and geographic information retrieval, we advocate the idea of semantically enriching a user's query from both geospatial and thematic perspectives. In the geospatial aspect, we propose to enrich a query by using both place partonomy and distance decay. In terms of the thematic aspect, concept expansion and embedding-based document similarity are used to infer the implicit information hidden in a user's query. This semantic query expansion 1 2 G. Mai et al. framework is implemented as a semantically-enriched search engine using ArcGIS Online as a case study. A benchmark dataset is constructed to evaluate the proposed framework. Our evaluation results show that the proposed semantic query expansion framework is very effective in capturing a user's search intention and significantly outperforms a well-established baseline-Lucene's practical scoring function-with more than 3.0 increments in DCG@K (K=3,5,10).
* 18 pages; Accepted to AGILE 2020 as a full paper GitHub Code Repository: https://github.com/gengchenmai/arcgis-online-search-engine
Multi-Scale Representation Learning for Spatial Feature Distributions using Grid Cells
Feb 16, 2020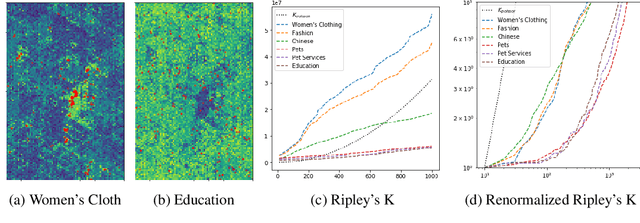
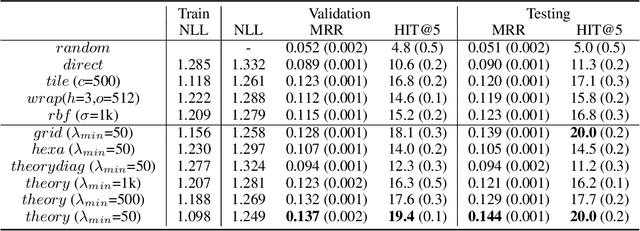

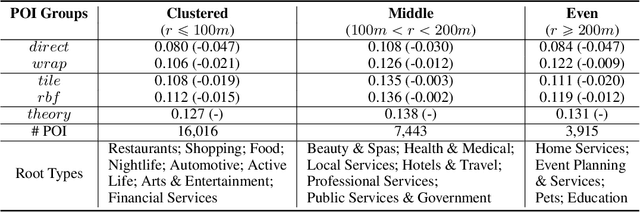
Unsupervised text encoding models have recently fueled substantial progress in NLP. The key idea is to use neural networks to convert words in texts to vector space representations based on word positions in a sentence and their contexts, which are suitable for end-to-end training of downstream tasks. We see a strikingly similar situation in spatial analysis, which focuses on incorporating both absolute positions and spatial contexts of geographic objects such as POIs into models. A general-purpose representation model for space is valuable for a multitude of tasks. However, no such general model exists to date beyond simply applying discretization or feed-forward nets to coordinates, and little effort has been put into jointly modeling distributions with vastly different characteristics, which commonly emerges from GIS data. Meanwhile, Nobel Prize-winning Neuroscience research shows that grid cells in mammals provide a multi-scale periodic representation that functions as a metric for location encoding and is critical for recognizing places and for path-integration. Therefore, we propose a representation learning model called Space2Vec to encode the absolute positions and spatial relationships of places. We conduct experiments on two real-world geographic data for two different tasks: 1) predicting types of POIs given their positions and context, 2) image classification leveraging their geo-locations. Results show that because of its multi-scale representations, Space2Vec outperforms well-established ML approaches such as RBF kernels, multi-layer feed-forward nets, and tile embedding approaches for location modeling and image classification tasks. Detailed analysis shows that all baselines can at most well handle distribution at one scale but show poor performances in other scales. In contrast, Space2Vec's multi-scale representation can handle distributions at different scales.
* 15 pages; Accepted to ICLR 2020 as a spotlight paper
TransGCN:Coupling Transformation Assumptions with Graph Convolutional Networks for Link Prediction
Oct 01, 2019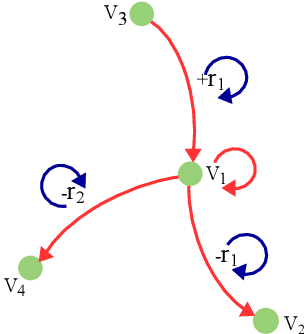
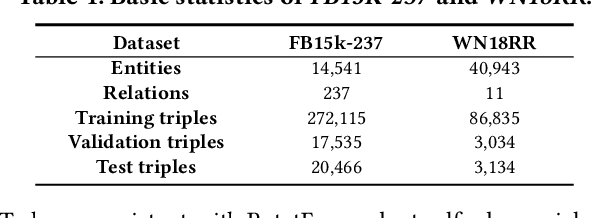
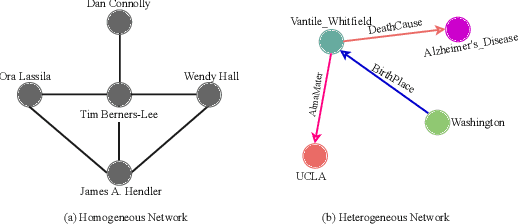
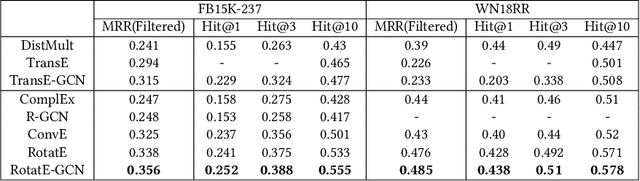
Link prediction is an important and frequently studied task that contributes to an understanding of the structure of knowledge graphs (KGs) in statistical relational learning. Inspired by the success of graph convolutional networks (GCN) in modeling graph data, we propose a unified GCN framework, named TransGCN, to address this task, in which relation and entity embeddings are learned simultaneously. To handle heterogeneous relations in KGs, we introduce a novel way of representing heterogeneous neighborhood by introducing transformation assumptions on the relationship between the subject, the relation, and the object of a triple. Specifically, a relation is treated as a transformation operator transforming a head entity to a tail entity. Both translation assumption in TransE and rotation assumption in RotatE are explored in our framework. Additionally, instead of only learning entity embeddings in the convolution-based encoder while learning relation embeddings in the decoder as done by the state-of-art models, e.g., R-GCN, the TransGCN framework trains relation embeddings and entity embeddings simultaneously during the graph convolution operation, thus having fewer parameters compared with R-GCN. Experiments show that our models outperform the-state-of-arts methods on both FB15K-237 and WN18RR.
Contextual Graph Attention for Answering Logical Queries over Incomplete Knowledge Graphs
Sep 30, 2019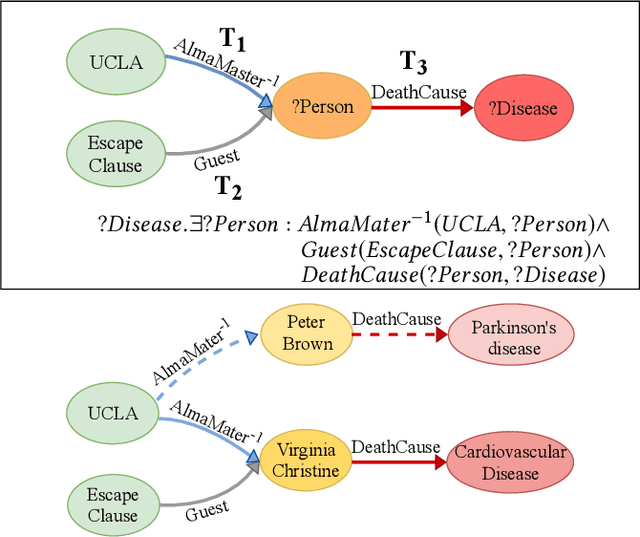

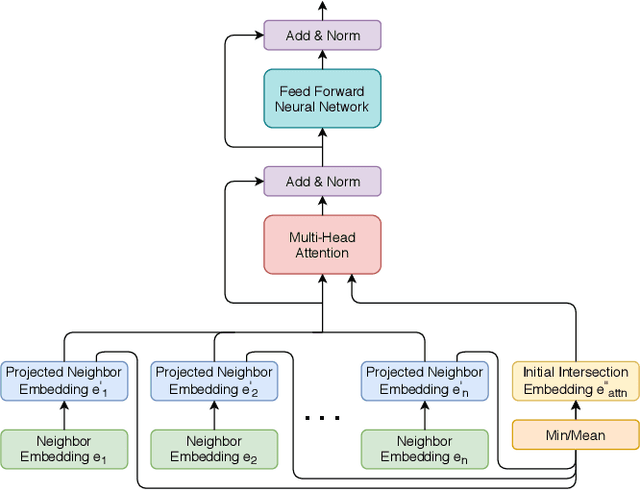
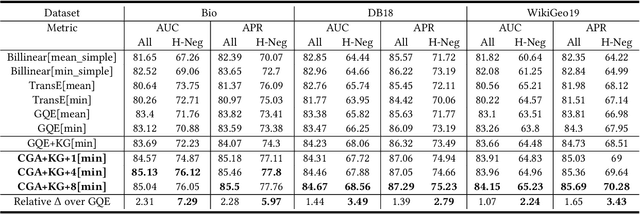
Recently, several studies have explored methods for using KG embedding to answer logical queries. These approaches either treat embedding learning and query answering as two separated learning tasks, or fail to deal with the variability of contributions from different query paths. We proposed to leverage a graph attention mechanism to handle the unequal contribution of different query paths. However, commonly used graph attention assumes that the center node embedding is provided, which is unavailable in this task since the center node is to be predicted. To solve this problem we propose a multi-head attention-based end-to-end logical query answering model, called Contextual Graph Attention model(CGA), which uses an initial neighborhood aggregation layer to generate the center embedding, and the whole model is trained jointly on the original KG structure as well as the sampled query-answer pairs. We also introduce two new datasets, DB18 and WikiGeo19, which are rather large in size compared to the existing datasets and contain many more relation types, and use them to evaluate the performance of the proposed model. Our result shows that the proposed CGA with fewer learnable parameters consistently outperforms the baseline models on both datasets as well as Bio dataset.
* 8 pages, 3 figures, camera ready version of article accepted to K-CAP 2019, Marina del Rey, California, United States
M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network
Nov 13, 2018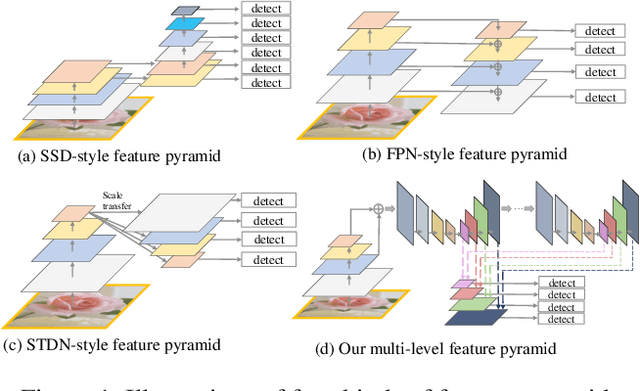

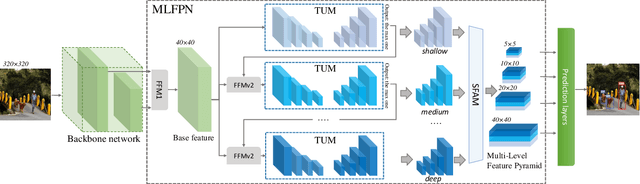
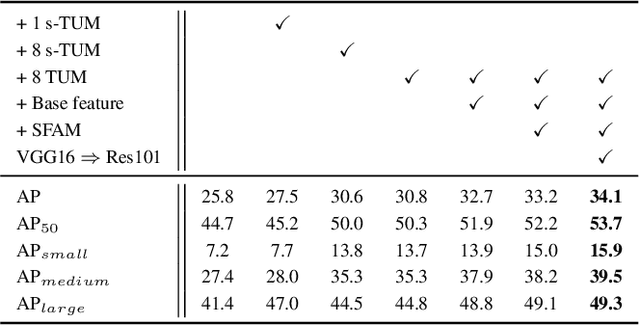
Feature pyramids are widely exploited by both the state-of-the-art one-stage object detectors (e.g., DSSD, RetinaNet, RefineDet) and the two-stage object detectors (e.g., Mask R-CNN, DetNet) to alleviate the problem arising from scale variation across object instances. Although these object detectors with feature pyramids achieve encouraging results, they have some limitations due to that they only simply construct the feature pyramid according to the inherent multi-scale, pyramidal architecture of the backbones which are actually designed for object classification task. Newly, in this work, we present a method called Multi-Level Feature Pyramid Network (MLFPN) to construct more effective feature pyramids for detecting objects of different scales. First, we fuse multi-level features (i.e. multiple layers) extracted by backbone as the base feature. Second, we feed the base feature into a block of alternating joint Thinned U-shape Modules and Feature Fusion Modules and exploit the decoder layers of each u-shape module as the features for detecting objects. Finally, we gather up the decoder layers with equivalent scales (sizes) to develop a feature pyramid for object detection, in which every feature map consists of the layers (features) from multiple levels. To evaluate the effectiveness of the proposed MLFPN, we design and train a powerful end-to-end one-stage object detector we call M2Det by integrating it into the architecture of SSD, which gets better detection performance than state-of-the-art one-stage detectors. Specifically, on MS-COCO benchmark, M2Det achieves AP of 41.0 at speed of 11.8 FPS with single-scale inference strategy and AP of 44.2 with multi-scale inference strategy, which is the new state-of-the-art results among one-stage detectors. The code will be made available on \url{https://github.com/qijiezhao/M2Det.
CFENet: An Accurate and Efficient Single-Shot Object Detector for Autonomous Driving
Oct 10, 2018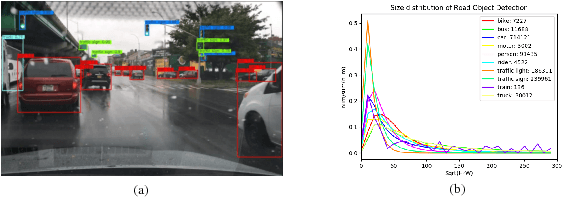
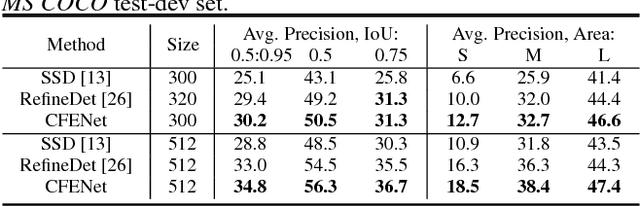
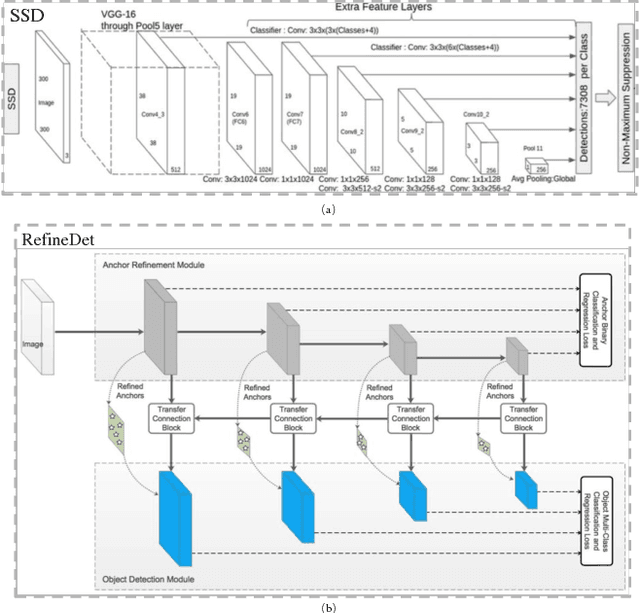

The ability to detect small objects and the speed of the object detector are very important for the application of autonomous driving, and in this paper, we propose an effective yet efficient one-stage detector, which gained the second place in the Road Object Detection competition of CVPR2018 workshop - Workshop of Autonomous Driving(WAD). The proposed detector inherits the architecture of SSD and introduces a novel Comprehensive Feature Enhancement(CFE) module into it. Experimental results on this competition dataset as well as the MSCOCO dataset demonstrate that the proposed detector (named CFENet) performs much better than the original SSD and the state-of-the-art method RefineDet especially for small objects, while keeping high efficiency close to the original SSD. Specifically, the single scale version of the proposed detector can run at the speed of 21 fps, while the multi-scale version with larger input size achieves the mAP 29.69, ranking second on the leaderboard