 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Task-Specific Knowledge from BERT into Simple Neural Networks
Mar 28, 2019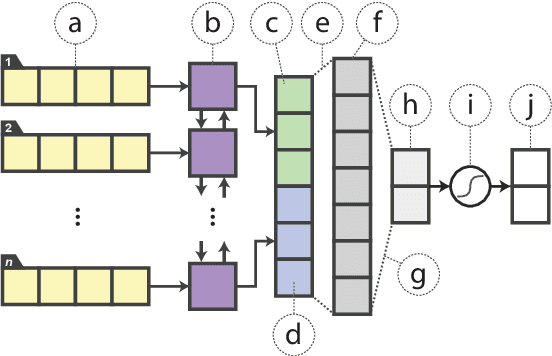
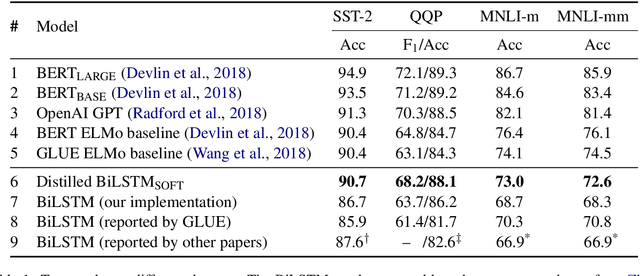
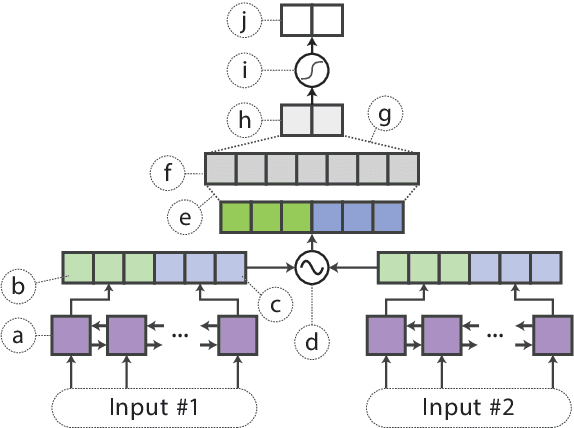
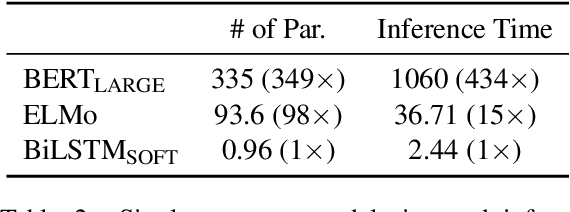
In the natural language processing literature, neural networks are becoming increasingly deeper and complex. The recent poster child of this trend is the deep language representation model, which includes BERT, ELMo, and GPT. These developments have led to the conviction that previous-generation, shallower neural networks for language understanding are obsolete. In this paper, however, we demonstrate that rudimentary, lightweight neural networks can still be made competitive without architecture changes, external training data, or additional input features. We propose to distill knowledge from BERT, a state-of-the-art language representation model, into a single-layer BiLSTM, as well as its siamese counterpart for sentence-pair tasks. Across multiple datasets in paraphrasing, natural language inference, and sentiment classification, we achieve comparable results with ELMo, while using roughly 100 times fewer parameters and 15 times less inference time.
CGMH: Constrained Sentence Generation by Metropolis-Hastings Sampling
Nov 14, 2018
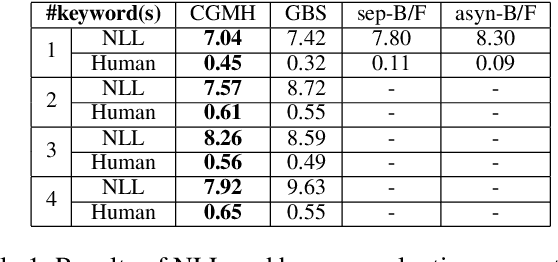
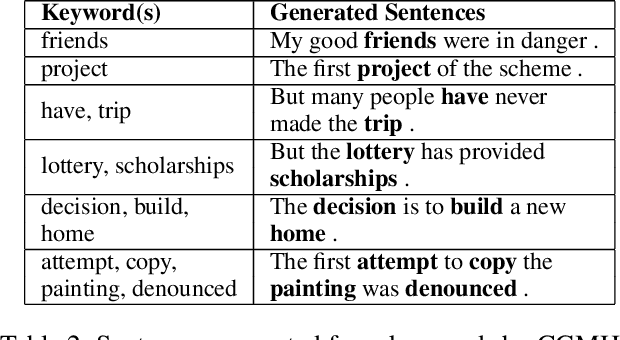
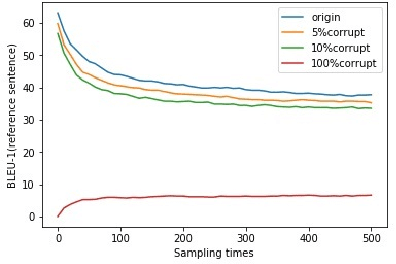
In real-world applications of natural language generation, there are often constraints on the target sentences in addition to fluency and naturalness requirements. Existing language generation techniques are usually based on recurrent neural networks (RNNs). However, it is non-trivial to impose constraints on RNNs while maintaining generation quality, since RNNs generate sentences sequentially (or with beam search) from the first word to the last. In this paper, we propose CGMH, a novel approach using Metropolis-Hastings sampling for constrained sentence generation. CGMH allows complicated constraints such as the occurrence of multiple keywords in the target sentences, which cannot be handled in traditional RNN-based approaches. Moreover, CGMH works in the inference stage, and does not require parallel corpora for training. We evaluate our method on a variety of tasks, including keywords-to-sentence generation, unsupervised sentence paraphrasing, and unsupervised sentence error correction. CGMH achieves high performance compared with previous supervised methods for sentence generation. Our code is released at https://github.com/NingMiao/CGMH
A Grammar-Based Structural CNN Decoder for Code Generation
Nov 14, 2018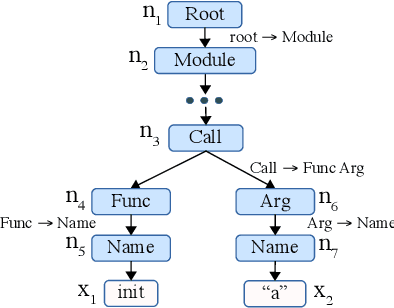

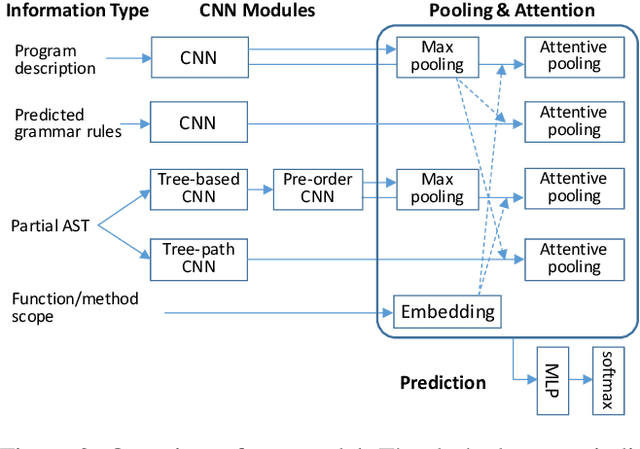
Code generation maps a program description to executable source code in a programming language. Existing approaches mainly rely on a recurrent neural network (RNN) as the decoder. However, we find that a program contains significantly more tokens than a natural language sentence, and thus it may be inappropriate for RNN to capture such a long sequence. In this paper, we propose a grammar-based structural convolutional neural network (CNN) for code generation. Our model generates a program by predicting the grammar rules of the programming language; we design several CNN modules, including the tree-based convolution and pre-order convolution, whose information is further aggregated by dedicated attentive pooling layers. Experimental results on the HearthStone benchmark dataset show that our CNN code generator significantly outperforms the previous state-of-the-art method by 5 percentage points; additional experiments on several semantic parsing tasks demonstrate the robustness of our model. We also conduct in-depth ablation test to better understand each component of our model.
Progressive Memory Banks for Incremental Domain Adaptation
Nov 01, 2018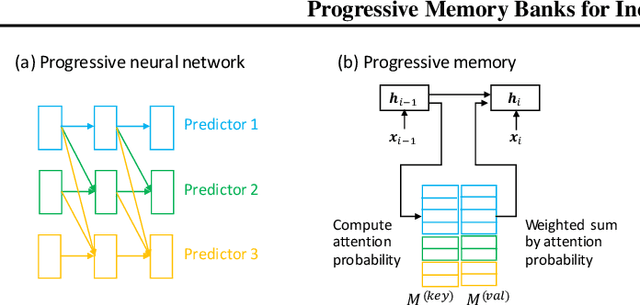
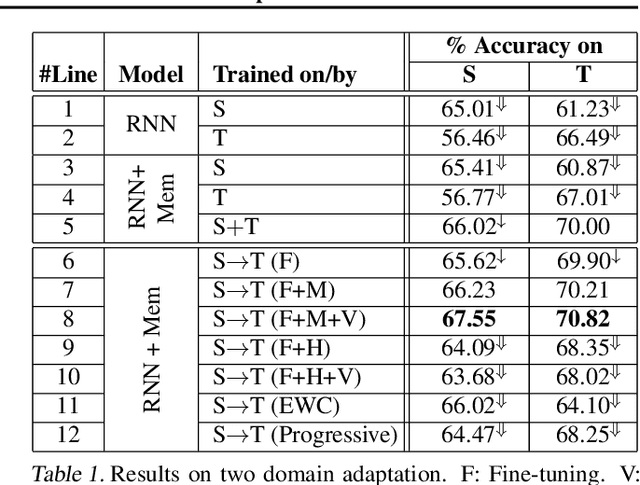
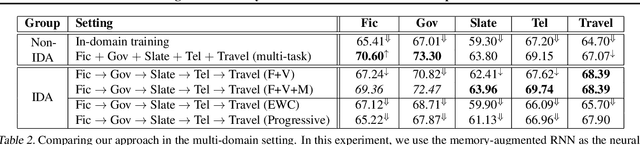
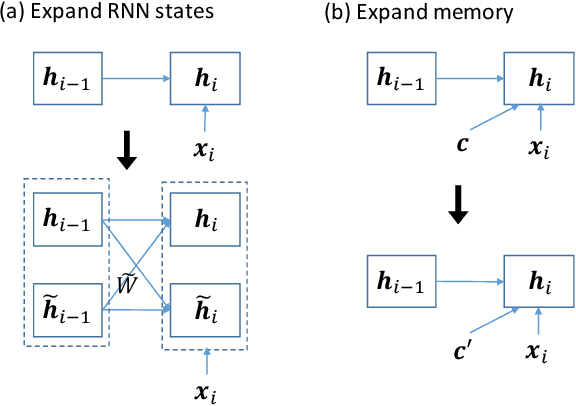
This paper addresses the problem of incremental domain adaptation (IDA). We assume each domain comes one after another, and that we could only access data in the current domain. The goal of IDA is to build a unified model performing well on all the domains that we have encountered. We propose to augment a recurrent neural network (RNN) with a directly parameterized memory bank, which is retrieved by an attention mechanism at each step of RNN transition. The memory bank provides a natural way of IDA: when adapting our model to a new domain, we progressively add new slots to the memory bank, which increases the number of parameters, and thus the model capacity. We learn the new memory slots and fine-tune existing parameters by back-propagation. Experimental results show that our approach achieves significantly better performance than fine-tuning alone, which suffers from the catastrophic forgetting problem. Compared with expanding hidden states, our approach is more robust for old domains, shown by both empirical and theoretical results. Our model also outperforms previous work of IDA including elastic weight consolidation (EWC) and the progressive neural network.
Hierarchical RNN with Static Sentence-Level Attention for Text-Based Speaker Change Detection
Sep 28, 2018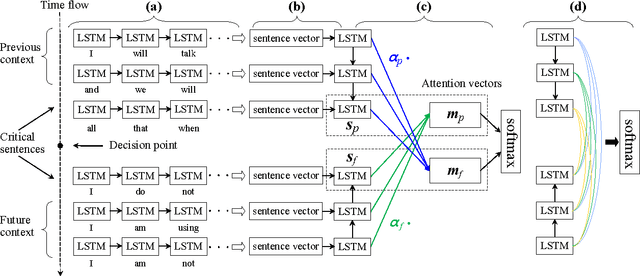
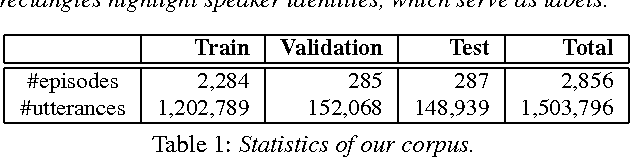
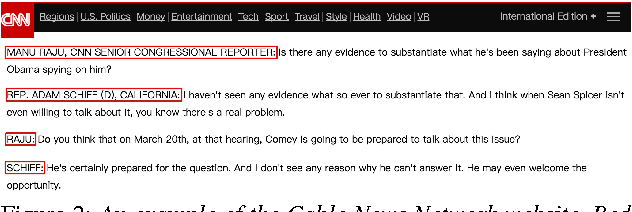
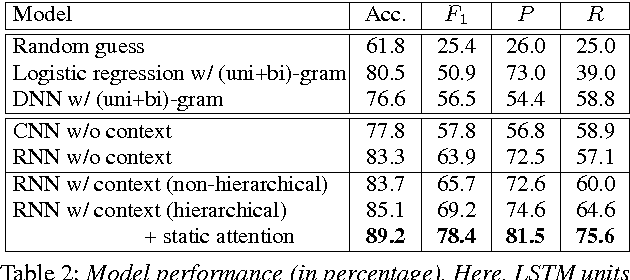
Speaker change detection (SCD) is an important task in dialog modeling. Our paper addresses the problem of text-based SCD, which differs from existing audio-based studies and is useful in various scenarios, for example, processing dialog transcripts where speaker identities are missing (e.g., OpenSubtitle), and enhancing audio SCD with textual information. We formulate text-based SCD as a matching problem of utterances before and after a certain decision point; we propose a hierarchical recurrent neural network (RNN) with static sentence-level attention. Experimental results show that neural networks consistently achieve better performance than feature-based approaches, and that our attention-based model significantly outperforms non-attention neural networks.
Towards Neural Speaker Modeling in Multi-Party Conversation: The Task, Dataset, and Models
Sep 28, 2018
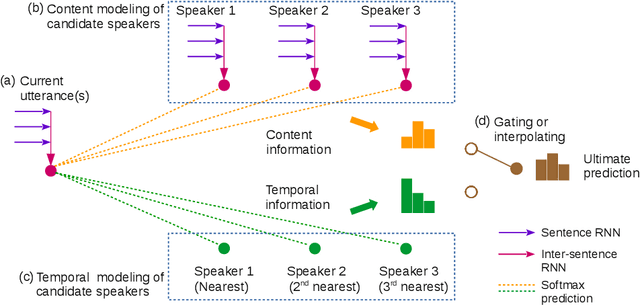
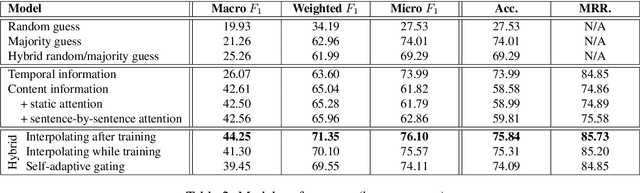
Neural network-based dialog systems are attracting increasing attention in both academia and industry. Recently, researchers have begun to realize the importance of speaker modeling in neural dialog systems, but there lacks established tasks and datasets. In this paper, we propose speaker classification as a surrogate task for general speaker modeling, and collect massive data to facilitate research in this direction. We further investigate temporal-based and content-based models of speakers, and propose several hybrids of them. Experiments show that speaker classification is feasible, and that hybrid models outperform each single component.
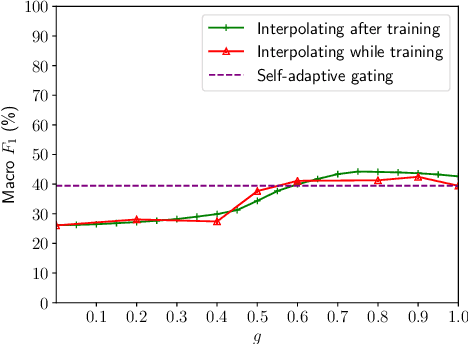
Disentangled Representation Learning for Non-Parallel Text Style Transfer
Sep 11, 2018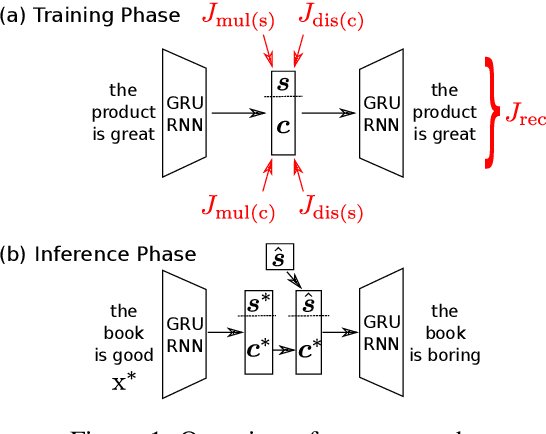
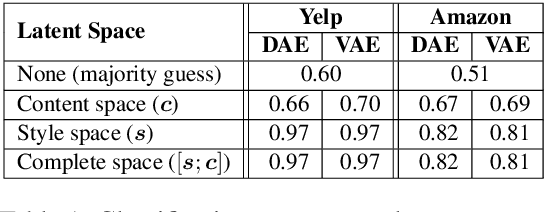
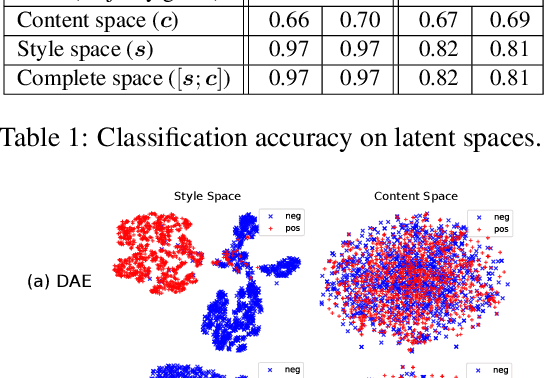
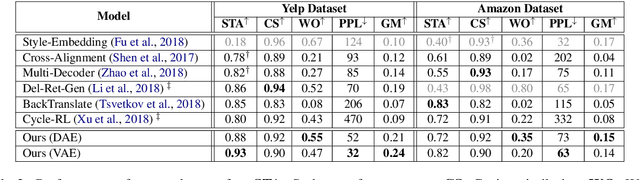
This paper tackles the problem of disentangling the latent variables of style and content in language models. We propose a simple yet effective approach, which incorporates auxiliary multi-task and adversarial objectives, for label prediction and bag-of-words prediction, respectively. We show, both qualitatively and quantitatively, that the style and content are indeed disentangled in the latent space. This disentangled latent representation learning method is applied to style transfer on non-parallel corpora. We achieve substantially better results in terms of transfer accuracy, content preservation and language fluency, in comparison to previous state-of-the-art approaches.
JUMPER: Learning When to Make Classification Decisions in Reading
Jul 06, 2018
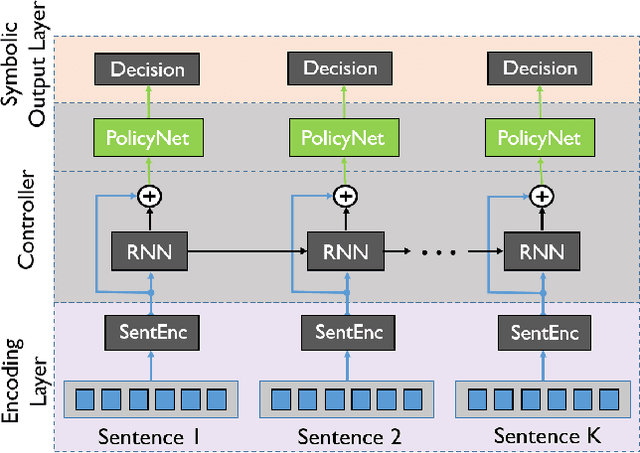
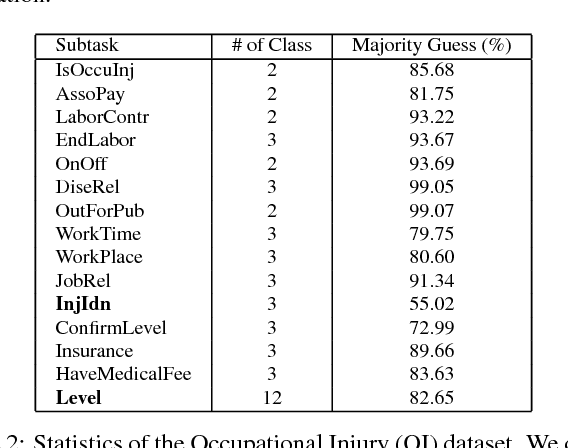
In early years, text classification is typically accomplished by feature-based machine learning models; recently, deep neural networks, as a powerful learning machine, make it possible to work with raw input as the text stands. However, exiting end-to-end neural networks lack explicit interpretation of the prediction. In this paper, we propose a novel framework, JUMPER, inspired by the cognitive process of text reading, that models text classification as a sequential decision process. Basically, JUMPER is a neural system that scans a piece of text sequentially and makes classification decisions at the time it wishes. Both the classification result and when to make the classification are part of the decision process, which is controlled by a policy network and trained with reinforcement learning. Experimental results show that a properly trained JUMPER has the following properties: (1) It can make decisions whenever the evidence is enough, therefore reducing total text reading by 30-40% and often finding the key rationale of prediction. (2) It achieves classification accuracy better than or comparable to state-of-the-art models in several benchmark and industrial datasets.
Probabilistic Natural Language Generation with Wasserstein Autoencoders
Jun 22, 2018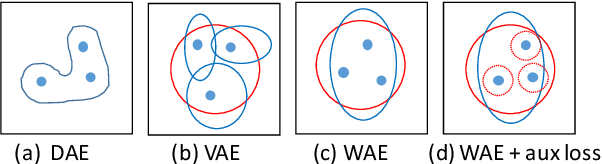
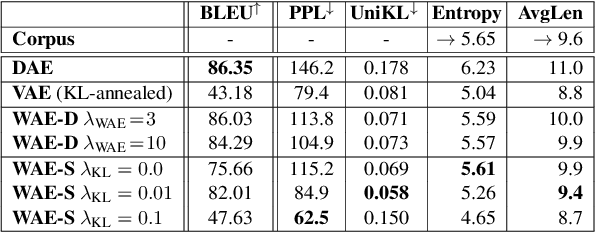
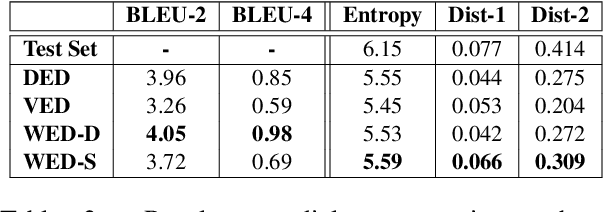
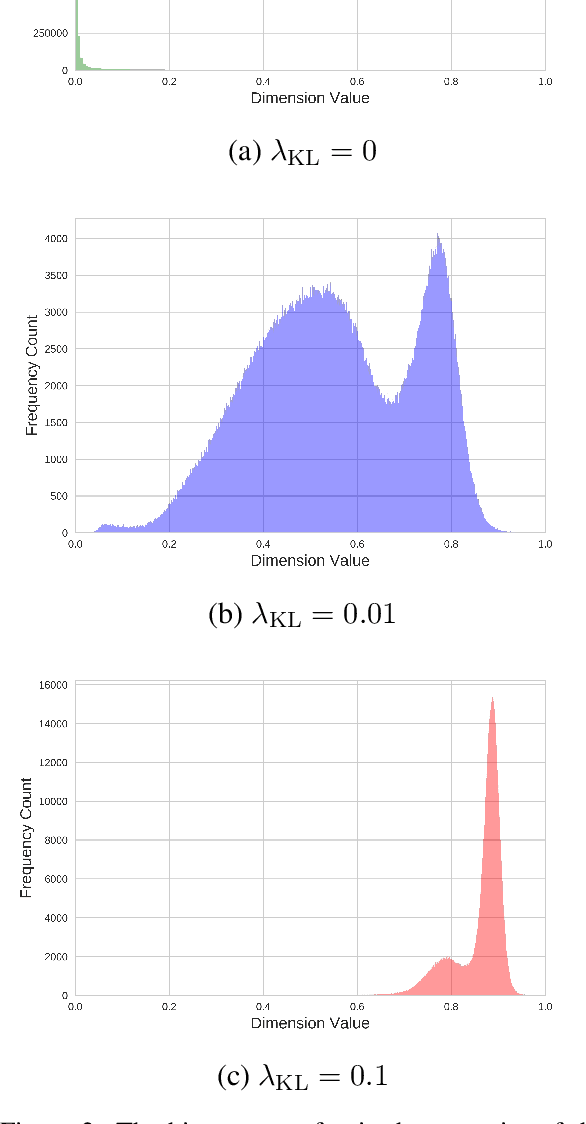
Probabilistic generation of natural language sentences is an important task in NLP. Existing models such as variational autoencoders (VAE) for sequence generation are extremely difficult to train due to the issues associated with the Kullback-Leibler (KL) loss collapsing to zero. One has to implement various heuristics such as KL weight annealing and word dropout in a carefully engineered manner to successfully train a text VAE. In this paper, we propose the use of Wasserstein autoencoders (WAE) for probabilistic natural language sentence generation. We show that sequence-to-sequence WAEs are more robust towards hyperparameters and can be trained in a straightforward manner without the need for any weight annealing. Empirical evidence shows that the latent space learned by WAEs exhibits properties of continuity and smoothness as in VAEs, while simultaneously achieving much higher BLEU scores for sentence reconstruction.
Variational Attention for Sequence-to-Sequence Models
Jun 21, 2018

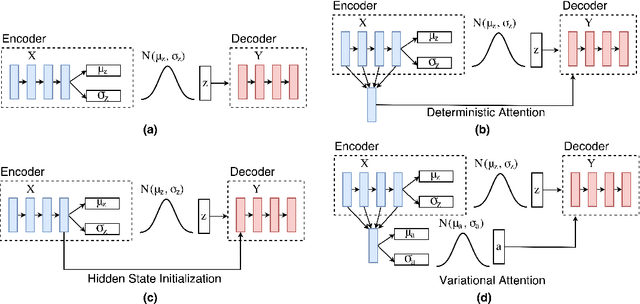
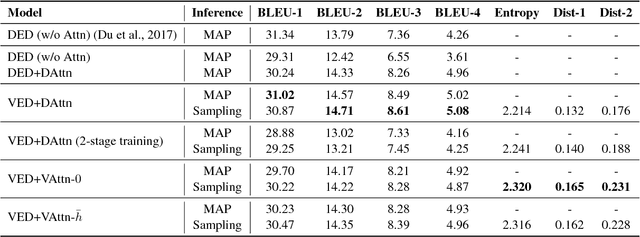
The variational encoder-decoder (VED) encodes source information as a set of random variables using a neural network, which in turn is decoded into target data using another neural network. In natural language processing, sequence-to-sequence (Seq2Seq) models typically serve as encoder-decoder networks. When combined with a traditional (deterministic) attention mechanism, the variational latent space may be bypassed by the attention model, and thus becomes ineffective. In this paper, we propose a variational attention mechanism for VED, where the attention vector is also modeled as Gaussian distributed random variables. Results on two experiments show that, without loss of quality, our proposed method alleviates the bypassing phenomenon as it increases the diversity of generated sentences.