 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceive, Route and Modulate: Dynamic Pattern Recalibration for Time Series Forecasting
May 07, 2026Local temporal patterns in real-world time series continuously shift, rendering globally shared transformations suboptimal. Current deep forecasting models, despite their scale and complexity, rely on fixed weight matrices applied uniformly to all temporal tokens. This creates a static pattern response: models settle into a compromised average, unable to adapt to changing local dynamics. We introduce Dynamic Pattern Recalibration (DPR), a backbone-agnostic mechanism that resolves this via token-level recalibration. Through a lightweight "Perceive-Route-Modulate" pipeline, DPR computes a soft-routing distribution over a learned basis of adaptive response patterns, generating a time-aware modulation vector that recalibrates hidden states via a residual Hadamard product. As a backbone-agnostic adapter, DPR enhances forecasting across diverse architectures with minimal overhead, confirming it addresses a general bottleneck. As a minimalist standalone model, DPRNet achieves competitive performance across 12 benchmarks, validating dynamic recalibration against macroscopic parameter scaling.
LoRA Done RITE: Robust Invariant Transformation Equilibration for LoRA Optimization
Oct 27, 2024Low-rank adaption (LoRA) is a widely used parameter-efficient finetuning method for LLM that reduces memory requirements. However, current LoRA optimizers lack transformation invariance, meaning the actual updates to the weights depends on how the two LoRA factors are scaled or rotated. This deficiency leads to inefficient learning and sub-optimal solutions in practice. This paper introduces LoRA-RITE, a novel adaptive matrix preconditioning method for LoRA optimization, which can achieve transformation invariance and remain computationally efficient. We provide theoretical analysis to demonstrate the benefit of our method and conduct experiments on various LLM tasks with different models including Gemma 2B, 7B, and mT5-XXL. The results demonstrate consistent improvements against existing optimizers. For example, replacing Adam with LoRA-RITE during LoRA fine-tuning of Gemma-2B yielded 4.6\% accuracy gain on Super-Natural Instructions and 3.5\% accuracy gain across other four LLM benchmarks (HellaSwag, ArcChallenge, GSM8K, OpenBookQA).
Assessing Adversarial Robustness of Large Language Models: An Empirical Study
May 04, 2024Large Language Models (LLMs) have revolutionized natural language processing, but their robustness against adversarial attacks remains a critical concern. We presents a novel white-box style attack approach that exposes vulnerabilities in leading open-source LLMs, including Llama, OPT, and T5. We assess the impact of model size, structure, and fine-tuning strategies on their resistance to adversarial perturbations. Our comprehensive evaluation across five diverse text classification tasks establishes a new benchmark for LLM robustness. The findings of this study have far-reaching implications for the reliable deployment of LLMs in real-world applications and contribute to the advancement of trustworthy AI systems.
Beyond prompting: Making Pre-trained Language Models Better Zero-shot Learners by Clustering Representations
Oct 29, 2022



Recent work has demonstrated that pre-trained language models (PLMs) are zero-shot learners. However, most existing zero-shot methods involve heavy human engineering or complicated self-training pipelines, hindering their application to new situations. In this work, we show that zero-shot text classification can be improved simply by clustering texts in the embedding spaces of PLMs. Specifically, we fit the unlabeled texts with a Bayesian Gaussian Mixture Model after initializing cluster positions and shapes using class names. Despite its simplicity, this approach achieves superior or comparable performance on both topic and sentiment classification datasets and outperforms prior works significantly on unbalanced datasets. We further explore the applicability of our clustering approach by evaluating it on 14 datasets with more diverse topics, text lengths, and numbers of classes. Our approach achieves an average of 20% absolute improvement over prompt-based zero-shot learning. Finally, we compare different PLM embedding spaces and find that texts are well-clustered by topics even if the PLM is not explicitly pre-trained to generate meaningful sentence embeddings. This work indicates that PLM embeddings can categorize texts without task-specific fine-tuning, thus providing a new way to analyze and utilize their knowledge and zero-shot learning ability.
Forecasting Question Answering over Temporal Knowledge Graphs
Aug 12, 2022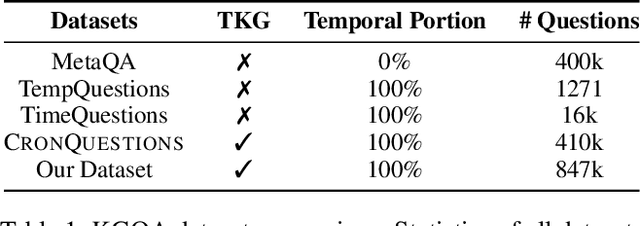

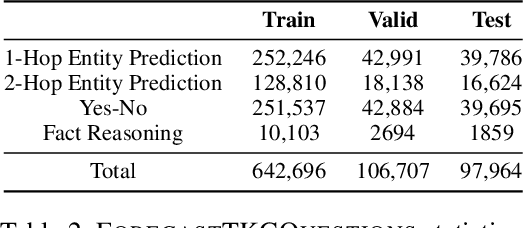
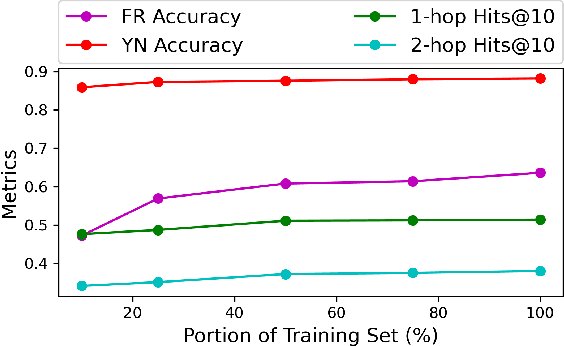
Question answering over temporal knowledge graphs (TKGQA) has recently found increasing interest. TKGQA requires temporal reasoning techniques to extract the relevant information from temporal knowledge bases. The only existing TKGQA dataset, i.e., CronQuestions, consists of temporal questions based on the facts from a fixed time period, where a temporal knowledge graph (TKG) spanning the same period can be fully used for answer inference, allowing the TKGQA models to use even the future knowledge to answer the questions based on the past facts. In real-world scenarios, however, it is also common that given the knowledge until now, we wish the TKGQA systems to answer the questions asking about the future. As humans constantly seek plans for the future, building TKGQA systems for answering such forecasting questions is important. Nevertheless, this has still been unexplored in previous research. In this paper, we propose a novel task: forecasting question answering over temporal knowledge graphs. We also propose a large-scale TKGQA benchmark dataset, i.e., ForecastTKGQuestions, for this task. It includes three types of questions, i.e., entity prediction, yes-no, and fact reasoning questions. For every forecasting question in our dataset, QA models can only have access to the TKG information before the timestamp annotated in the given question for answer inference. We find that the state-of-the-art TKGQA methods perform poorly on forecasting questions, and they are unable to answer yes-no questions and fact reasoning questions. To this end, we propose ForecastTKGQA, a TKGQA model that employs a TKG forecasting module for future inference, to answer all three types of questions. Experimental results show that ForecastTKGQA outperforms recent TKGQA methods on the entity prediction questions, and it also shows great effectiveness in answering the other two types of questions.
3D-RETR: End-to-End Single and Multi-View 3D Reconstruction with Transformers
Oct 17, 2021
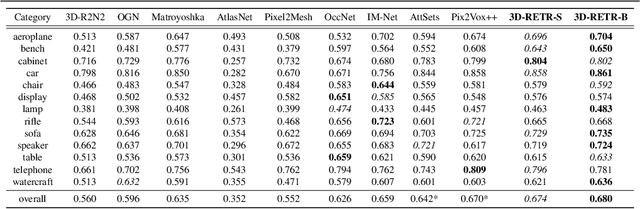
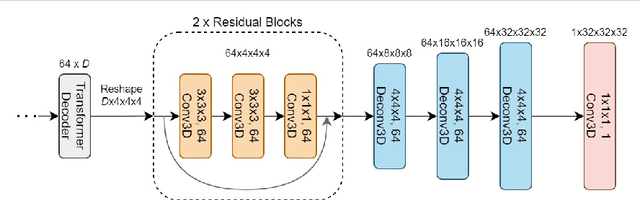
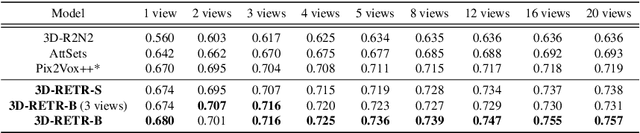
3D reconstruction aims to reconstruct 3D objects from 2D views. Previous works for 3D reconstruction mainly focus on feature matching between views or using CNNs as backbones. Recently, Transformers have been shown effective in multiple applications of computer vision. However, whether or not Transformers can be used for 3D reconstruction is still unclear. In this paper, we fill this gap by proposing 3D-RETR, which is able to perform end-to-end 3D REconstruction with TRansformers. 3D-RETR first uses a pretrained Transformer to extract visual features from 2D input images. 3D-RETR then uses another Transformer Decoder to obtain the voxel features. A CNN Decoder then takes as input the voxel features to obtain the reconstructed objects. 3D-RETR is capable of 3D reconstruction from a single view or multiple views. Experimental results on two datasets show that 3DRETR reaches state-of-the-art performance on 3D reconstruction. Additional ablation study also demonstrates that 3D-DETR benefits from using Transformers.
BERT is Robust! A Case Against Synonym-Based Adversarial Examples in Text Classification
Sep 15, 2021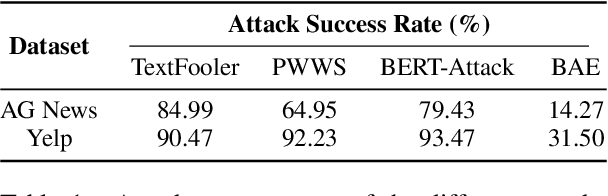
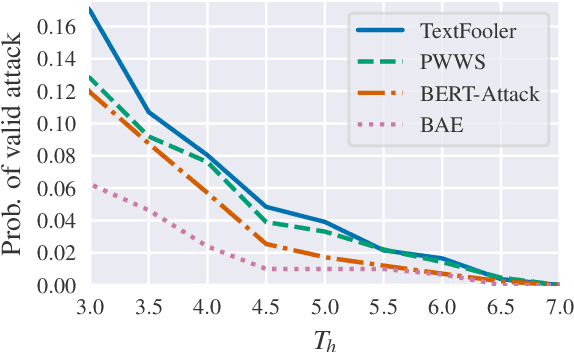

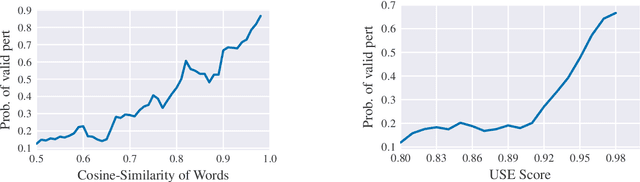
Deep Neural Networks have taken Natural Language Processing by storm. While this led to incredible improvements across many tasks, it also initiated a new research field, questioning the robustness of these neural networks by attacking them. In this paper, we investigate four word substitution-based attacks on BERT. We combine a human evaluation of individual word substitutions and a probabilistic analysis to show that between 96% and 99% of the analyzed attacks do not preserve semantics, indicating that their success is mainly based on feeding poor data to the model. To further confirm that, we introduce an efficient data augmentation procedure and show that many adversarial examples can be prevented by including data similar to the attacks during training. An additional post-processing step reduces the success rates of state-of-the-art attacks below 5%. Finally, by looking at more reasonable thresholds on constraints for word substitutions, we conclude that BERT is a lot more robust than research on attacks suggests.
Self-Supervised Contrastive Learning with Adversarial Perturbations for Robust Pretrained Language Models
Jul 15, 2021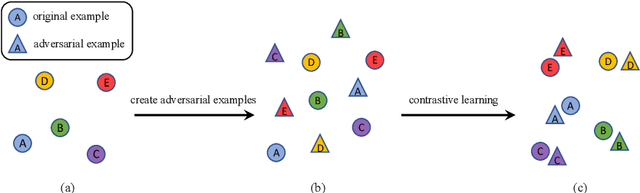
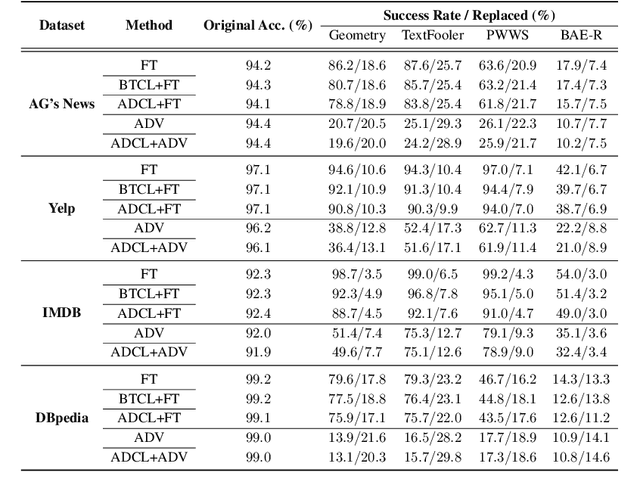
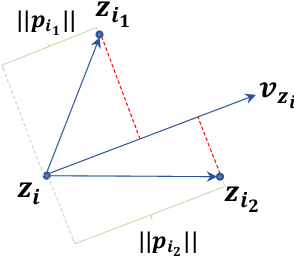
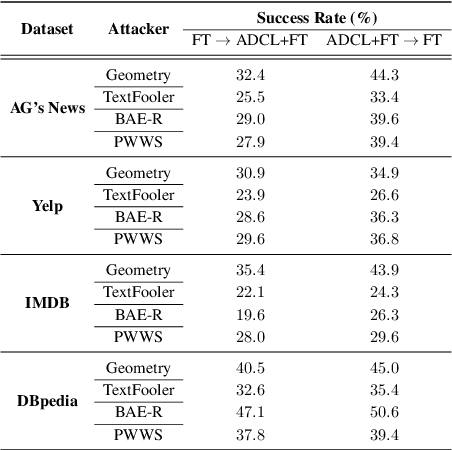
This paper improves the robustness of the pretrained language model BERT against word substitution-based adversarial attacks by leveraging self-supervised contrastive learning with adversarial perturbations. One advantage of our method compared to previous works is that it is capable of improving model robustness without using any labels. Additionally, we also create an adversarial attack for word-level adversarial training on BERT. The attack is efficient, allowing adversarial training for BERT on adversarial examples generated on the fly during training. Experimental results on four datasets show that our method improves the robustness of BERT against four different word substitution-based adversarial attacks. Furthermore, to understand why our method can improve the model robustness against adversarial attacks, we study vector representations of clean examples and their corresponding adversarial examples before and after applying our method. As our method improves model robustness with unlabeled raw data, it opens up the possibility of using large text datasets to train robust language models.
Towards Robust Graph Contrastive Learning
Feb 25, 2021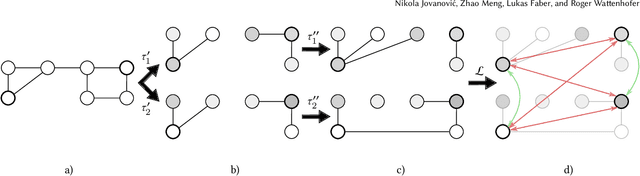
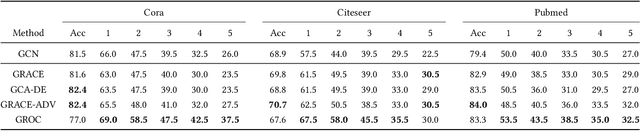
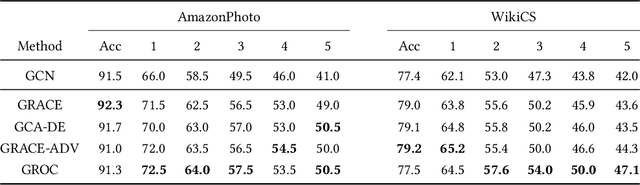
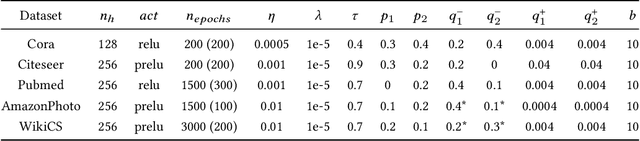
We study the problem of adversarially robust self-supervised learning on graphs. In the contrastive learning framework, we introduce a new method that increases the adversarial robustness of the learned representations through i) adversarial transformations and ii) transformations that not only remove but also insert edges. We evaluate the learned representations in a preliminary set of experiments, obtaining promising results. We believe this work takes an important step towards incorporating robustness as a viable auxiliary task in graph contrastive learning.
KM-BART: Knowledge Enhanced Multimodal BART for Visual Commonsense Generation
Jan 02, 2021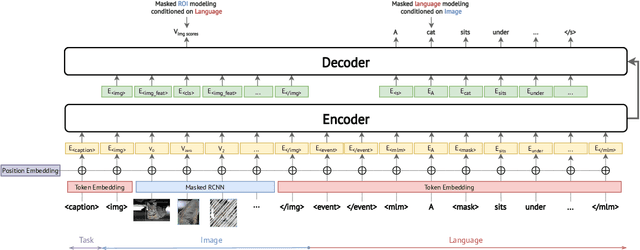
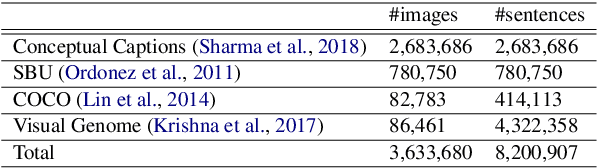
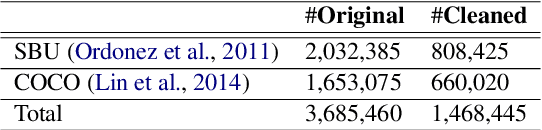
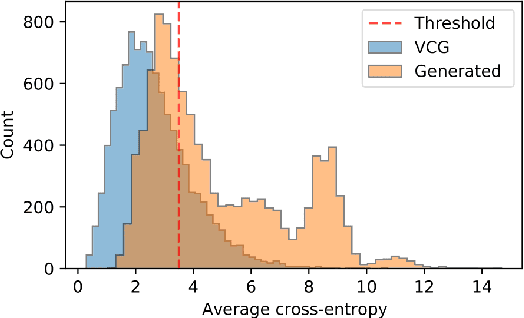
We present Knowledge Enhanced Multimodal BART (KM-BART), which is a Transformer-based sequence-to-sequence model capable of reasoning about commonsense knowledge from multimodal inputs of images and texts. We extend the popular BART architecture to a multi-modal model. We design a new pretraining task to improve the model performance on Visual Commonsense Generation task. Our pretraining task improves the Visual Commonsense Generation performance by leveraging knowledge from a large language model pretrained on an external knowledge graph. To the best of our knowledge, we are the first to propose a dedicated task for improving model performance on Visual Commonsense Generation. Experimental results show that by pretraining, our model reaches state-of-the-art performance on the Visual Commonsense Generation task.