 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlayer-Centric Multimodal Prompt Generation for Large Language Model Based Identity-Aware Basketball Video Captioning
Jul 27, 2025Existing sports video captioning methods often focus on the action yet overlook player identities, limiting their applicability. Although some methods integrate extra information to generate identity-aware descriptions, the player identities are sometimes incorrect because the extra information is independent of the video content. This paper proposes a player-centric multimodal prompt generation network for identity-aware sports video captioning (LLM-IAVC), which focuses on recognizing player identities from a visual perspective. Specifically, an identity-related information extraction module (IRIEM) is designed to extract player-related multimodal embeddings. IRIEM includes a player identification network (PIN) for extracting visual features and player names, and a bidirectional semantic interaction module (BSIM) to link player features with video content for mutual enhancement. Additionally, a visual context learning module (VCLM) is designed to capture the key video context information. Finally, by integrating the outputs of the above modules as the multimodal prompt for the large language model (LLM), it facilitates the generation of descriptions with player identities. To support this work, we construct a new benchmark called NBA-Identity, a large identity-aware basketball video captioning dataset with 9,726 videos covering 9 major event types. The experimental results on NBA-Identity and VC-NBA-2022 demonstrate that our proposed model achieves advanced performance. Code and dataset are publicly available at https://github.com/Zeyu1226-mt/LLM-IAVC.
Modified Supervised Contrastive Learning for Detecting Anomalous Driving Behaviours
Sep 09, 2021


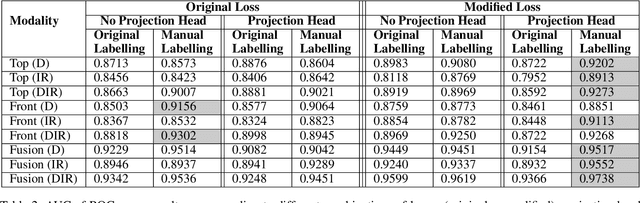
Detecting distracted driving behaviours is important to reduce millions of deaths and injuries occurring worldwide. Distracted or anomalous driving behaviours are deviations from the 'normal' driving that need to be identified correctly to alert the driver. However, these driving behaviours do not comprise of one specific type of driving style and their distribution can be different during training and testing phases of a classifier. We formulate this problem as a supervised contrastive learning approach to learn a visual representation to detect normal, and seen and unseen anomalous driving behaviours. We made a change to the standard contrastive loss function to adjust the similarity of negative pairs to aid the optimization. Normally, the (self) supervised contrastive framework contains an encoder followed by a projection head, which is omitted during testing phase as the encoding layers are considered to contain general visual representative information. However, we assert that for supervised contrastive learning task, including projection head will be beneficial. We showed our results on a Driver Anomaly Detection dataset that contains 783 minutes of video recordings of normal and anomalous driving behaviours of 31 drivers from various from top and front cameras (both depth and infrared). We also performed an extra step of fine tuning the labels in this dataset. Out of 9 video modalities combinations, our modified contrastive approach improved the ROC AUC on 7 in comparison to the baseline models (from 3.12% to 8.91% for different modalities); the remaining two models also had manual labelling. We performed statistical tests that showed evidence that our modifications perform better than the baseline contrastive models. Finally, the results showed that the fusion of depth and infrared modalities from top and front view achieved the best AUC ROC of 0.9738 and AUC PR of 0.9772.