 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Robust AIGI Detection with LoRA-based Pairwise Training
Apr 14, 2026The proliferation of highly realistic AI-Generated Image (AIGI) has necessitated the development of practical detection methods. While current AIGI detectors perform admirably on clean datasets, their detection performance frequently decreases when deployed "in the wild", where images are subjected to unpredictable, complex distortions. To resolve the critical vulnerability, we propose a novel LoRA-based Pairwise Training (LPT) strategy designed specifically to achieve robust detection for AIGI under severe distortions. The core of our strategy involves the targeted finetuning of a visual foundation model, the deliberate simulation of data distribution during the training phase, and a unique pairwise training process. Specifically, we introduce distortion and size simulations to better fit the distribution from the validation and test sets. Based on the strong visual representation capability of the visual foundation model, we finetune the model to achieve AIGI detection. The pairwise training is utilized to improve the detection via decoupling the generalization and robustness optimization. Experiments show that our approach secured the 3th placement in the NTIRE Robust AI-Generated Image Detection in the Wild challenge
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
Ontology Based Global and Collective Motion Patterns for Event Classification in Basketball Videos
Mar 19, 2019
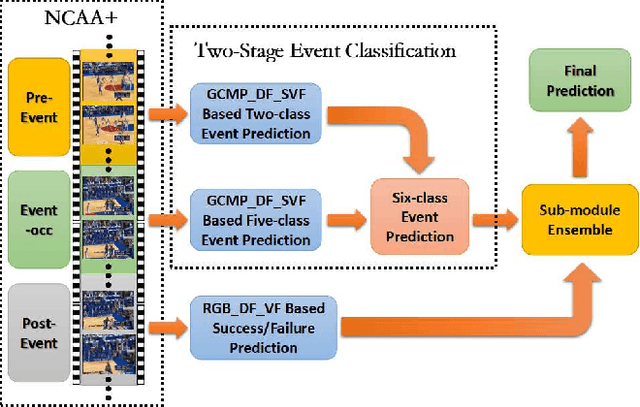

In multi-person videos, especially team sport videos, a semantic event is usually represented as a confrontation between two teams of players, which can be represented as collective motion. In broadcast basketball videos, specific camera motions are used to present specific events. Therefore, a semantic event in broadcast basketball videos is closely related to both the global motion (camera motion) and the collective motion. A semantic event in basketball videos can be generally divided into three stages: pre-event, event occurrence (event-occ), and post-event. In this paper, we propose an ontology-based global and collective motion pattern (On_GCMP) algorithm for basketball event classification. First, a two-stage GCMP based event classification scheme is proposed. The GCMP is extracted using optical flow. The two-stage scheme progressively combines a five-class event classification algorithm on event-occs and a two-class event classification algorithm on pre-events. Both algorithms utilize sequential convolutional neural networks (CNNs) and long short-term memory (LSTM) networks to extract the spatial and temporal features of GCMP for event classification. Second, we utilize post-event segments to predict success/failure using deep features of images in the video frames (RGB_DF_VF) based algorithms. Finally the event classification results and success/failure classification results are integrated to obtain the final results. To evaluate the proposed scheme, we collected a new dataset called NCAA+, which is automatically obtained from the NCAA dataset by extending the fixed length of video clips forward and backward of the corresponding semantic events. The experimental results demonstrate that the proposed scheme achieves the mean average precision of 58.10% on NCAA+. It is higher by 6.50% than state-of-the-art on NCAA.