 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistortion-aware Transformer in 360° Salient Object Detection
Aug 07, 2023With the emergence of VR and AR, 360{\deg} data attracts increasing attention from the computer vision and multimedia communities. Typically, 360{\deg} data is projected into 2D ERP (equirectangular projection) images for feature extraction. However, existing methods cannot handle the distortions that result from the projection, hindering the development of 360-data-based tasks. Therefore, in this paper, we propose a Transformer-based model called DATFormer to address the distortion problem. We tackle this issue from two perspectives. Firstly, we introduce two distortion-adaptive modules. The first is a Distortion Mapping Module, which guides the model to pre-adapt to distorted features globally. The second module is a Distortion-Adaptive Attention Block that reduces local distortions on multi-scale features. Secondly, to exploit the unique characteristics of 360{\deg} data, we present a learnable relation matrix and use it as part of the positional embedding to further improve performance. Extensive experiments are conducted on three public datasets, and the results show that our model outperforms existing 2D SOD (salient object detection) and 360 SOD methods.
VL-SAT: Visual-Linguistic Semantics Assisted Training for 3D Semantic Scene Graph Prediction in Point Cloud
Mar 25, 2023



The task of 3D semantic scene graph (3DSSG) prediction in the point cloud is challenging since (1) the 3D point cloud only captures geometric structures with limited semantics compared to 2D images, and (2) long-tailed relation distribution inherently hinders the learning of unbiased prediction. Since 2D images provide rich semantics and scene graphs are in nature coped with languages, in this study, we propose Visual-Linguistic Semantics Assisted Training (VL-SAT) scheme that can significantly empower 3DSSG prediction models with discrimination about long-tailed and ambiguous semantic relations. The key idea is to train a powerful multi-modal oracle model to assist the 3D model. This oracle learns reliable structural representations based on semantics from vision, language, and 3D geometry, and its benefits can be heterogeneously passed to the 3D model during the training stage. By effectively utilizing visual-linguistic semantics in training, our VL-SAT can significantly boost common 3DSSG prediction models, such as SGFN and SGGpoint, only with 3D inputs in the inference stage, especially when dealing with tail relation triplets. Comprehensive evaluations and ablation studies on the 3DSSG dataset have validated the effectiveness of the proposed scheme. Code is available at https://github.com/wz7in/CVPR2023-VLSAT.
Towards Explainable 3D Grounded Visual Question Answering: A New Benchmark and Strong Baseline
Sep 24, 2022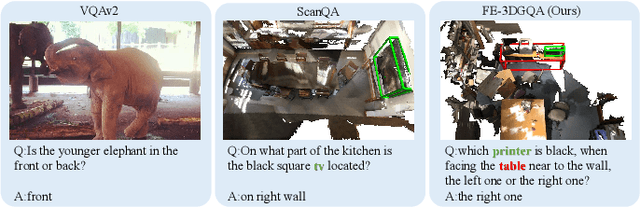
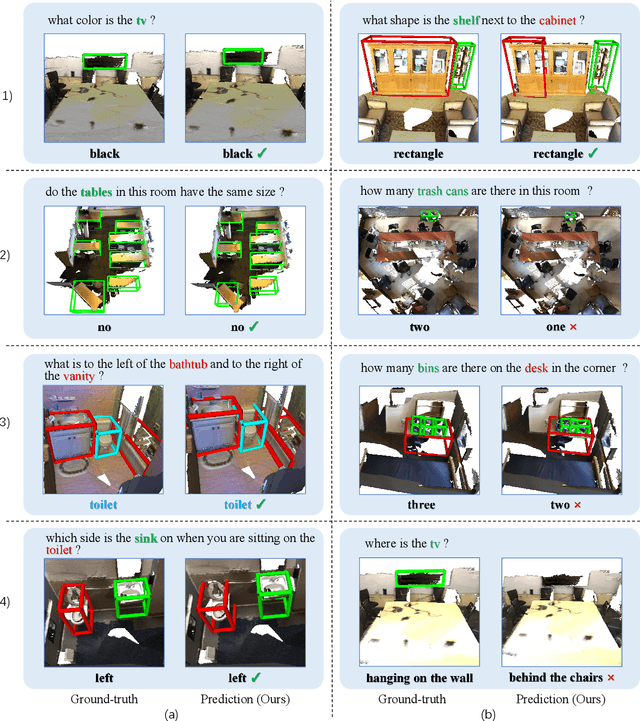
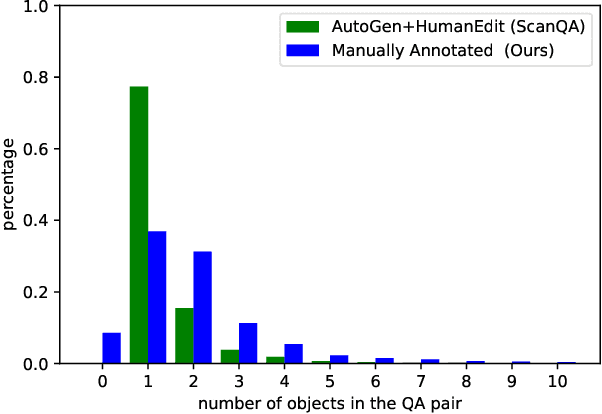

Recently, 3D vision-and-language tasks have attracted increasing research interest. Compared to other vision-and-language tasks, the 3D visual question answering (VQA) task is less exploited and is more susceptible to language priors and co-reference ambiguity. Meanwhile, a couple of recently proposed 3D VQA datasets do not well support 3D VQA task due to their limited scale and annotation methods. In this work, we formally define and address a 3D grounded VQA task by collecting a new 3D VQA dataset, referred to as FE-3DGQA, with diverse and relatively free-form question-answer pairs, as well as dense and completely grounded bounding box annotations. To achieve more explainable answers, we labelled the objects appeared in the complex QA pairs with different semantic types, including answer-grounded objects (both appeared and not appeared in the questions), and contextual objects for answer-grounded objects. We also propose a new 3D VQA framework to effectively predict the completely visually grounded and explainable answer. Extensive experiments verify that our newly collected benchmark datasets can be effectively used to evaluate various 3D VQA methods from different aspects and our newly proposed framework also achieves state-of-the-art performance on the new benchmark dataset. Both the newly collected dataset and our codes will be publicly available at http://github.com/zlccccc/3DGQA.
Democratizing Contrastive Language-Image Pre-training: A CLIP Benchmark of Data, Model, and Supervision
Mar 11, 2022
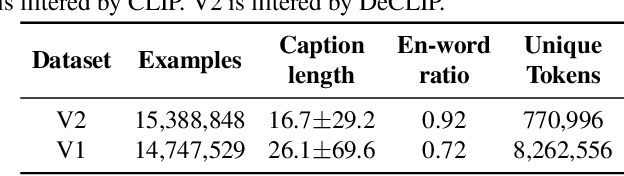

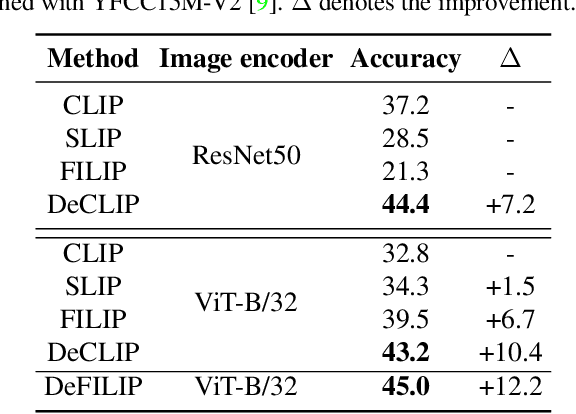
Contrastive Language-Image Pretraining (CLIP) has emerged as a novel paradigm to learn visual models from language supervision. While researchers continue to push the frontier of CLIP, reproducing these works remains challenging. This is because researchers do not choose consistent training recipes and even use different data, hampering the fair comparison between different methods. In this work, we propose CLIP-benchmark, a first attempt to evaluate, analyze, and benchmark CLIP and its variants. We conduct a comprehensive analysis of three key factors: data, supervision, and model architecture. We find considerable intuitive or counter-intuitive insights: (1). Data quality has a significant impact on performance. (2). Certain supervision has different effects for Convolutional Networks (ConvNets) and Vision Transformers (ViT). Applying more proper supervision can effectively improve the performance of CLIP. (3). Curtailing the text encoder reduces the training cost but not much affect the final performance. Moreover, we further combine DeCLIP with FILIP, bringing us the strongest variant DeFILIP. The CLIP-benchmark would be released at: https://github.com/Sense-GVT/DeCLIP for future CLIP research.
Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm
Oct 11, 2021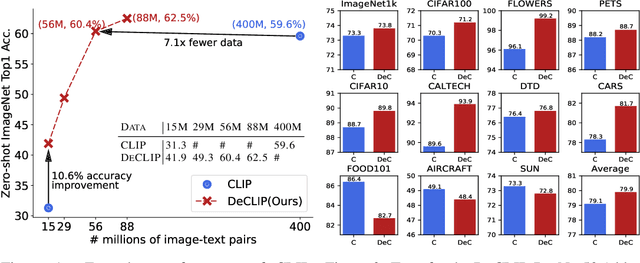
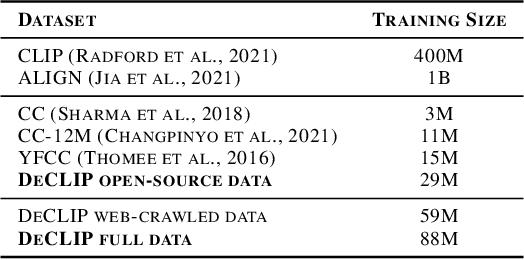
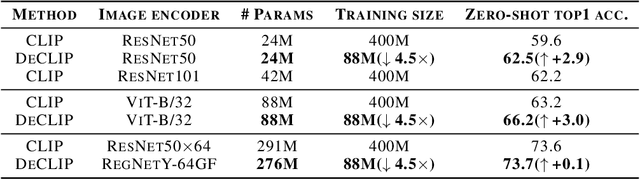
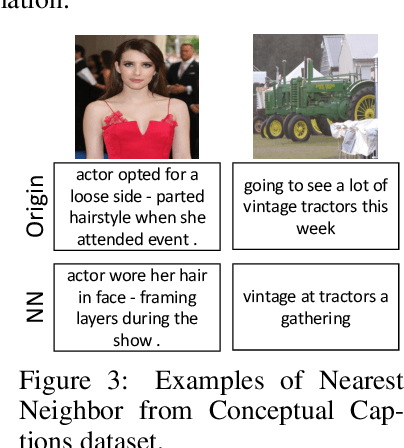
Recently, large-scale Contrastive Language-Image Pre-training (CLIP) has attracted unprecedented attention for its impressive zero-shot recognition ability and excellent transferability to downstream tasks. However, CLIP is quite data-hungry and requires 400M image-text pairs for pre-training, thereby restricting its adoption. This work proposes a novel training paradigm, Data efficient CLIP (DeCLIP), to alleviate this limitation. We demonstrate that by carefully utilizing the widespread supervision among the image-text pairs, our De-CLIP can learn generic visual features more efficiently. Instead of using the single image-text contrastive supervision, we fully exploit data potential through the use of (1) self-supervision within each modality; (2) multi-view supervision across modalities; (3) nearest-neighbor supervision from other similar pairs. Benefiting from intrinsic supervision, our DeCLIP-ResNet50 can achieve 60.4% zero-shot top1 accuracy on ImageNet, which is 0.8% above the CLIP-ResNet50 while using 7.1 x fewer data. Our DeCLIP-ResNet50 outperforms its counterpart in 8 out of 11 visual datasets when transferred to downstream tasks. Moreover, Scaling up the model and computing also works well in our framework.Our code, dataset and models are released at: https://github.com/Sense-GVT/DeCLIP