 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale temporal-frequency attention for music source separation
Sep 02, 2022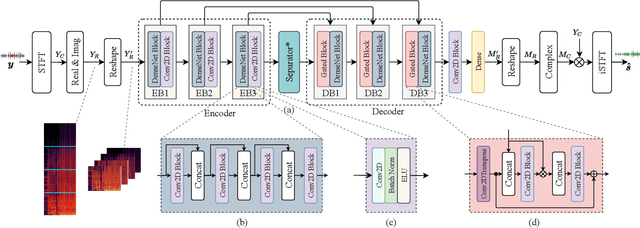
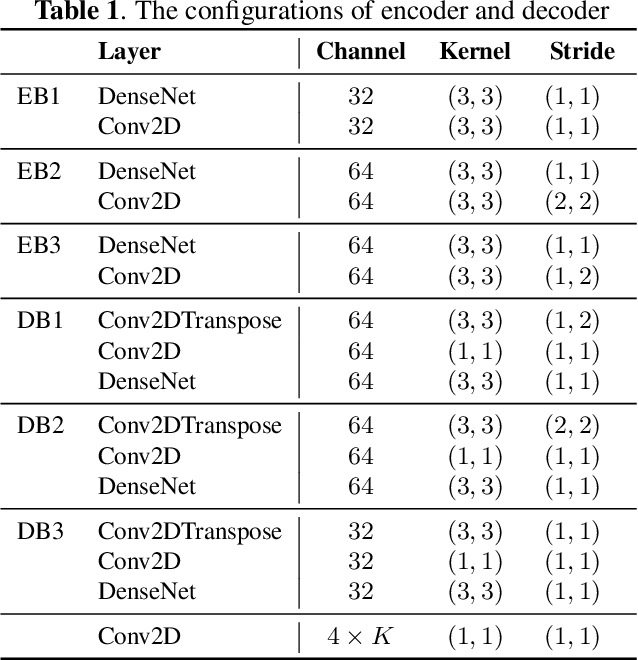
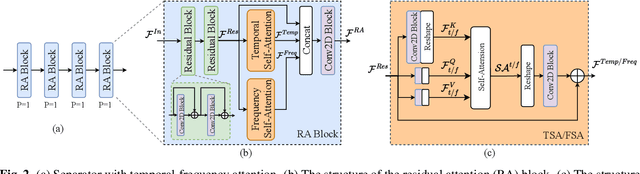
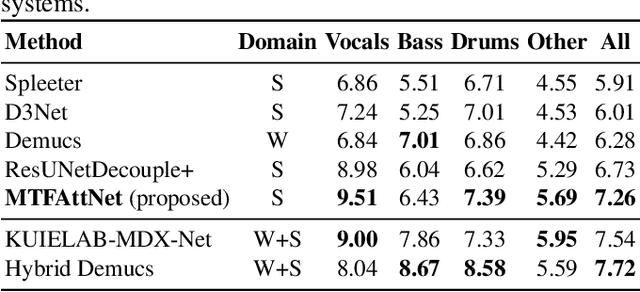
In recent years, deep neural networks (DNNs) based approaches have achieved the start-of-the-art performance for music source separation (MSS). Although previous methods have addressed the large receptive field modeling using various methods, the temporal and frequency correlations of the music spectrogram with repeated patterns have not been explicitly explored for the MSS task. In this paper, a temporal-frequency attention module is proposed to model the spectrogram correlations along both temporal and frequency dimensions. Moreover, a multi-scale attention is proposed to effectively capture the correlations for music signal. The experimental results on MUSDB18 dataset show that the proposed method outperforms the existing state-of-the-art systems with 9.51 dB signal-to-distortion ratio (SDR) on separating the vocal stems, which is the primary practical application of MSS.
A two-step backward compatible fullband speech enhancement system
Jan 28, 2022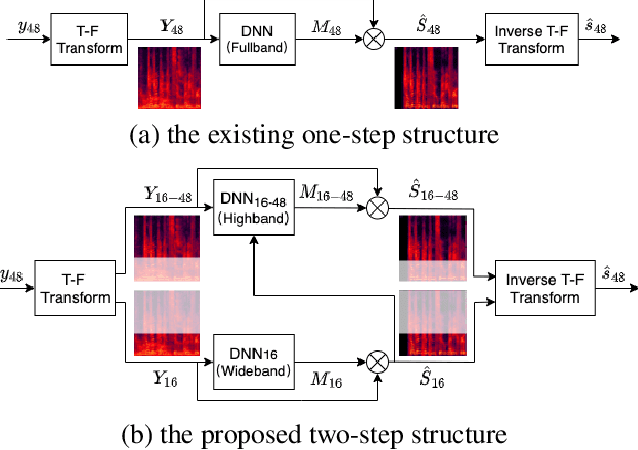
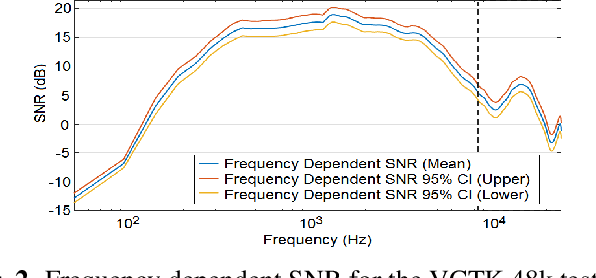
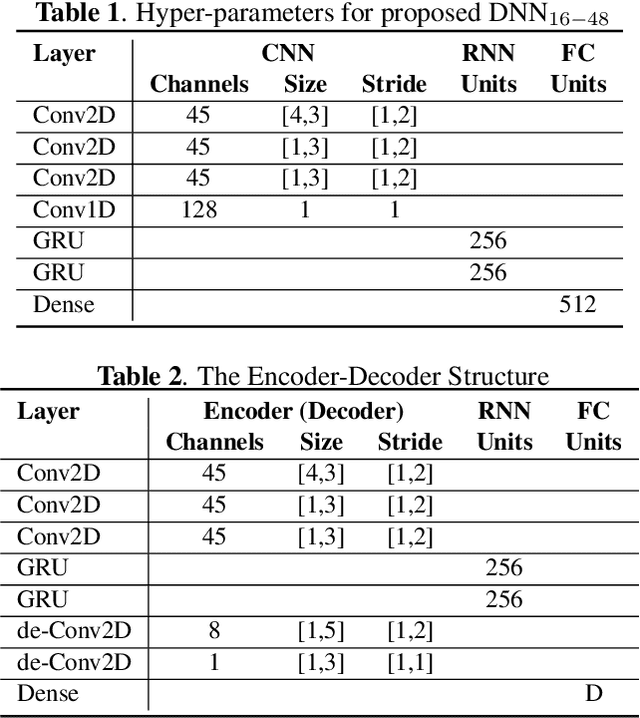
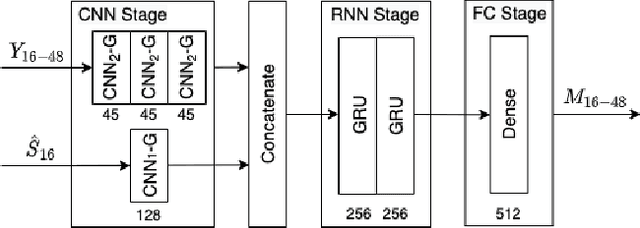
Speech enhancement methods based on deep learning have surpassed traditional methods. While many of these new approaches are operating on the wideband (16kHz) sample rate, a new fullband (48kHz) speech enhancement system is proposed in this paper. Compared to the existing fullband systems that utilizes perceptually motivated features to train the fullband speech enhancement using a single network structure, the proposed system is a two-step system ensuring good fullband speech enhancement quality while backward compatible to the existing wideband systems.
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021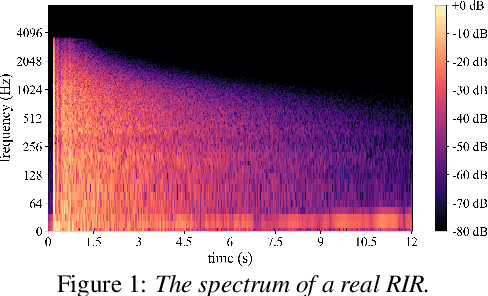
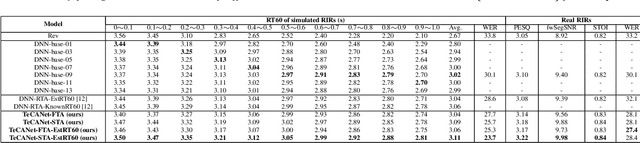
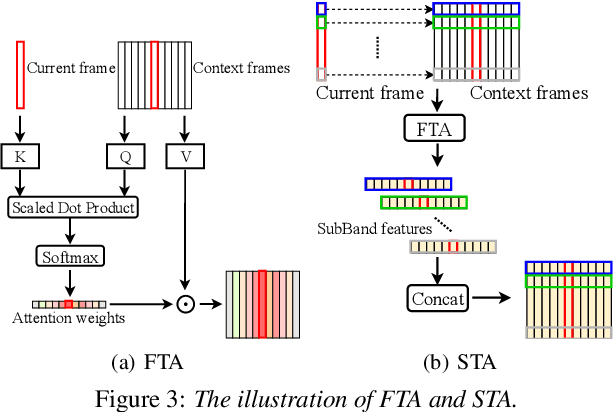
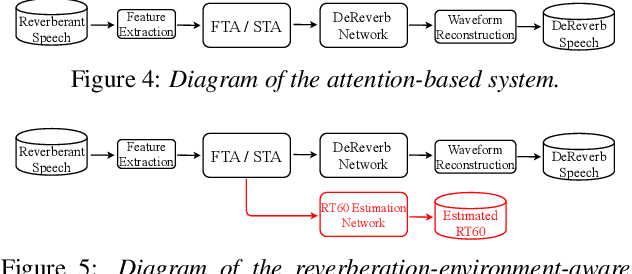
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Generalized RNN beamformer for target speech separation
Jan 04, 2021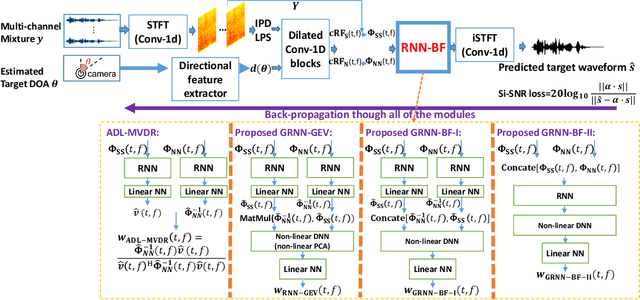
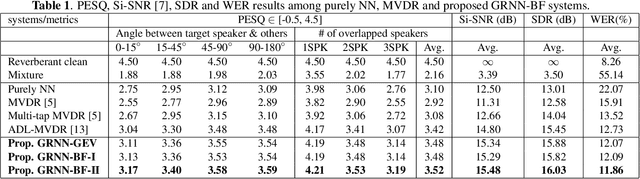
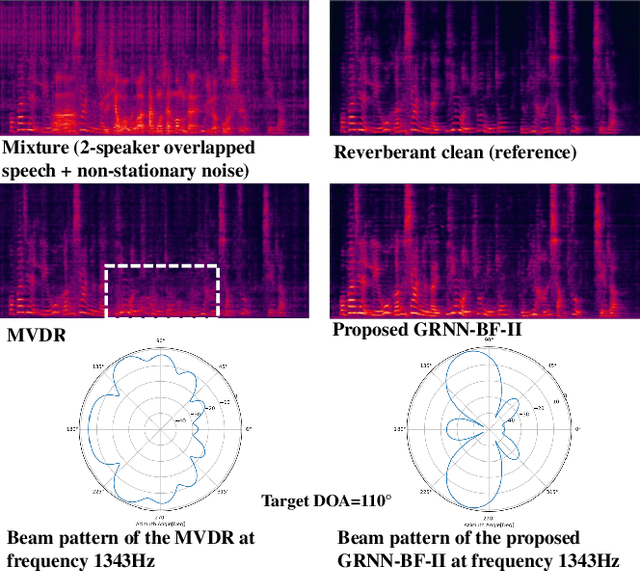
Recently we proposed an all-deep-learning minimum variance distortionless response (ADL-MVDR) method where the unstable matrix inverse and principal component analysis (PCA) operations in the MVDR were replaced by recurrent neural networks (RNNs). However, it is not clear whether the success of the ADL-MVDR is owed to the calculated covariance matrices or following the MVDR formula. In this work, we demonstrate the importance of the calculated covariance matrices and propose three types of generalized RNN beamformers (GRNN-BFs) where the beamforming solution is beyond the MVDR and optimal. The GRNN-BFs could predict the frame-wise beamforming weights by leveraging on the temporal modeling capability of RNNs. The proposed GRNN-BF method obtains better performance than the state-of-the-art ADL-MVDR and the traditional mask-based MVDR methods in terms of speech quality (PESQ), speech-to-noise ratio (SNR), and word error rate (WER).
Multi-channel Multi-frame ADL-MVDR for Target Speech Separation
Dec 24, 2020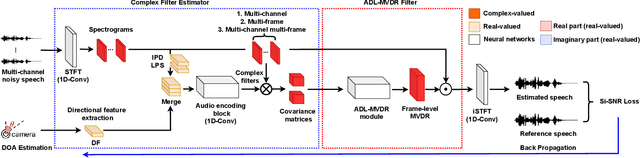
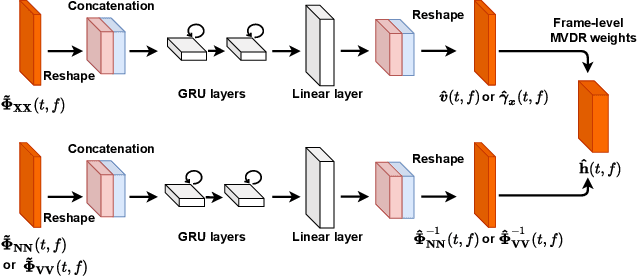
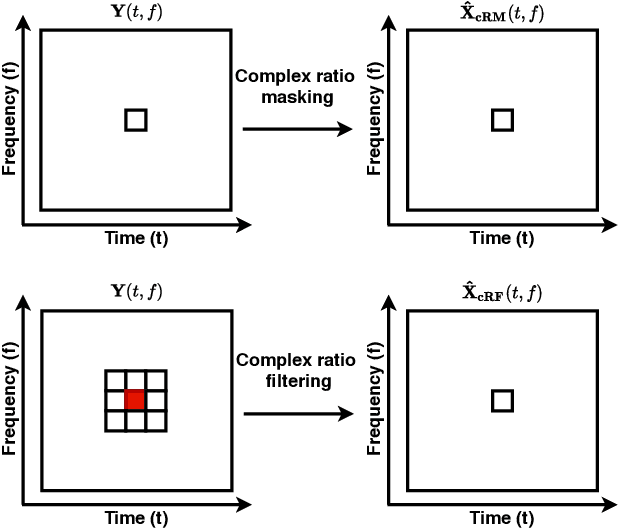
Many purely neural network based speech separation approaches have been proposed that greatly improve objective assessment scores, but they often introduce nonlinear distortions that are harmful to automatic speech recognition (ASR). Minimum variance distortionless response (MVDR) filters strive to remove nonlinear distortions, however, these approaches either are not optimal for removing residual (linear) noise, or they are unstable when used jointly with neural networks. In this study, we propose a multi-channel multi-frame (MCMF) all deep learning (ADL)-MVDR approach for target speech separation, which extends our preliminary multi-channel ADL-MVDR approach. The MCMF ADL-MVDR handles different numbers of microphone channels in one framework, where it addresses linear and nonlinear distortions. Spatio-temporal cross correlations are also fully utilized in the proposed approach. The proposed system is evaluated using a Mandarin audio-visual corpora and is compared with several state-of-the-art approaches. Experimental results demonstrate the superiority of our proposed framework under different scenarios and across several objective evaluation metrics, including ASR performance.
Improving Reverberant Speech Training Using Diffuse Acoustic Simulation
Jul 09, 2019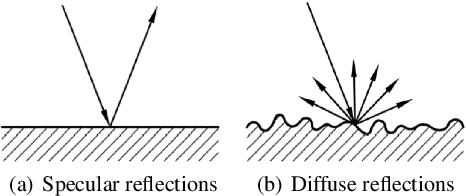


We present an efficient and realistic geometric sound simulation approach for generating and augmenting training data in speech-related machine learning tasks. Our physically based acoustic simulation method is capable of modeling occlusion, specular and diffuse reflections of sound in complicated acoustic environments, whereas the classical image method can only model specular reflections in simple room settings. We show that by using our synthetic training data, the same models gain significant performance improvement on real test sets in both speech recognition and keyword spotting tasks, without fine tuning using any real data.
End-to-End Multi-Channel Speech Separation
May 28, 2019
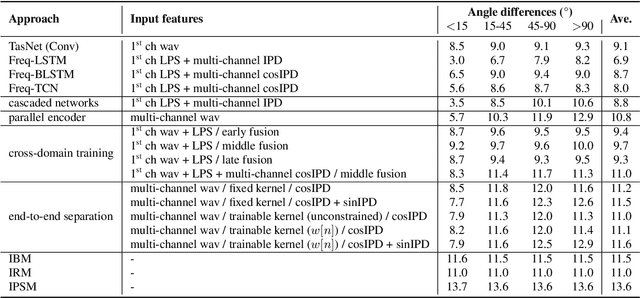
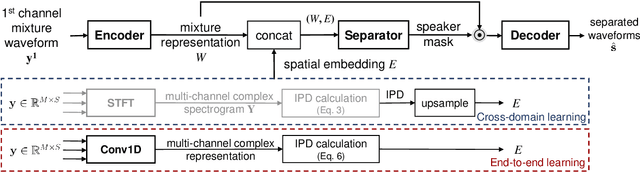

The end-to-end approach for single-channel speech separation has been studied recently and shown promising results. This paper extended the previous approach and proposed a new end-to-end model for multi-channel speech separation. The primary contributions of this work include 1) an integrated waveform-in waveform-out separation system in a single neural network architecture. 2) We reformulate the traditional short time Fourier transform (STFT) and inter-channel phase difference (IPD) as a function of time-domain convolution with a special kernel. 3) We further relaxed those fixed kernels to be learnable, so that the entire architecture becomes purely data-driven and can be trained from end-to-end. We demonstrate on the WSJ0 far-field speech separation task that, with the benefit of learnable spatial features, our proposed end-to-end multi-channel model significantly improved the performance of previous end-to-end single-channel method and traditional multi-channel methods.