 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Power Inference for On-Device Visual Recognition with a Quantization-Friendly Solution
Mar 12, 2019
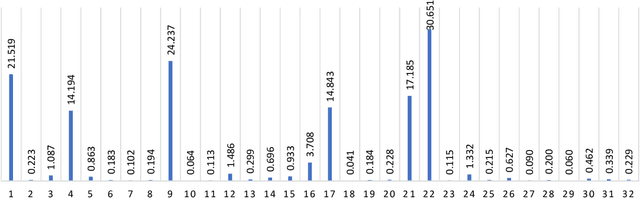
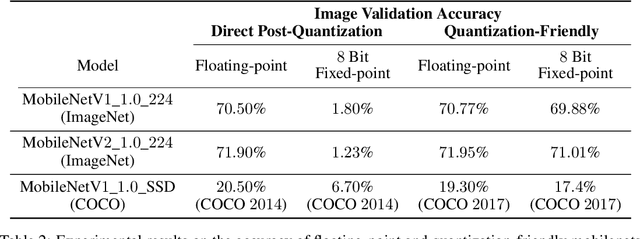
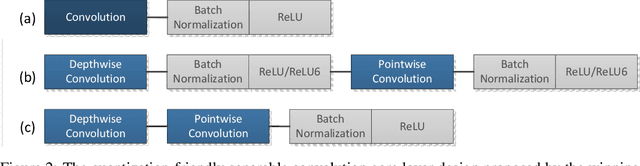
The IEEE Low-Power Image Recognition Challenge (LPIRC) is an annual competition started in 2015 that encourages joint hardware and software solutions for computer vision systems with low latency and power. Track 1 of the competition in 2018 focused on the innovation of software solutions with fixed inference engine and hardware. This decision allows participants to submit models online and not worry about building and bringing custom hardware on-site, which attracted a historically large number of submissions. Among the diverse solutions, the winning solution proposed a quantization-friendly framework for MobileNets that achieves an accuracy of 72.67% on the holdout dataset with an average latency of 27ms on a single CPU core of Google Pixel2 phone, which is superior to the best real-time MobileNet models at the time.
2018 Low-Power Image Recognition Challenge
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.
Radiative Transport Based Flame Volume Reconstruction from Videos
Sep 17, 2018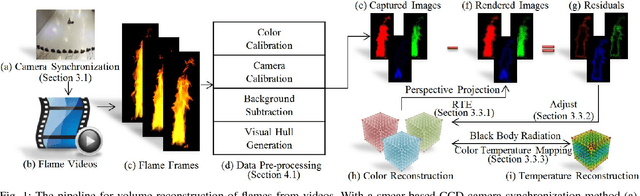
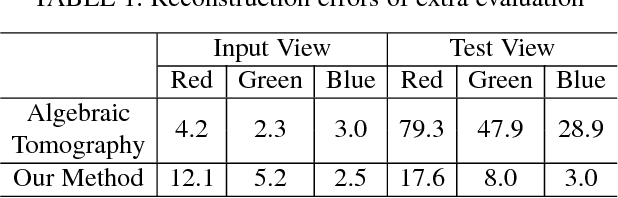
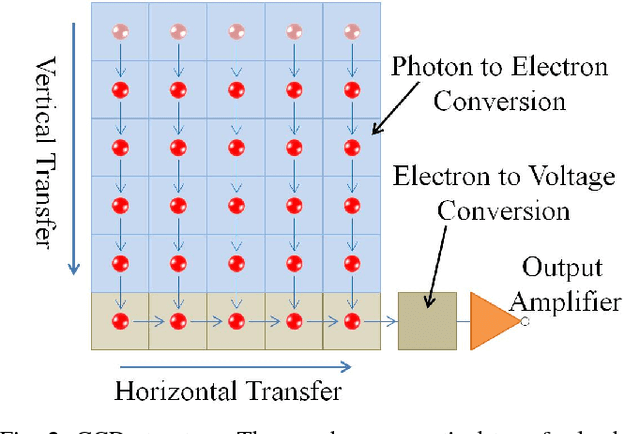

We introduce a novel approach for flame volume reconstruction from videos using inexpensive charge-coupled device (CCD) consumer cameras. The approach includes an economical data capture technique using inexpensive CCD cameras. Leveraging the smear feature of the CCD chip, we present a technique for synchronizing CCD cameras while capturing flame videos from different views. Our reconstruction is based on the radiative transport equation which enables complex phenomena such as emission, extinction, and scattering to be used in the rendering process. Both the color intensity and temperature reconstructions are implemented using the CUDA parallel computing framework, which provides real-time performance and allows visualization of reconstruction results after every iteration. We present the results of our approach using real captured data and physically-based simulated data. Finally, we also compare our approach against the other state-of-the-art flame volume reconstruction methods and demonstrate the efficacy and efficiency of our approach in four different applications: (1) rendering of reconstructed flames in virtual environments, (2) rendering of reconstructed flames in augmented reality, (3) flame stylization, and (4) reconstruction of other semitransparent phenomena.
A Quantization-Friendly Separable Convolution for MobileNets
Mar 22, 2018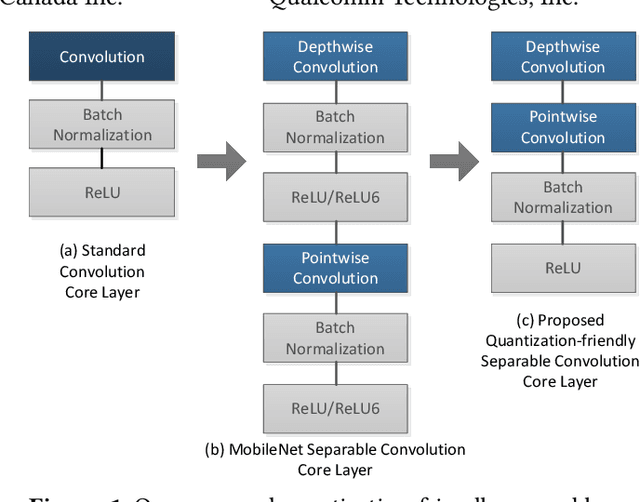

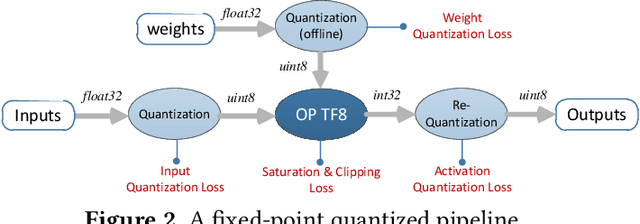
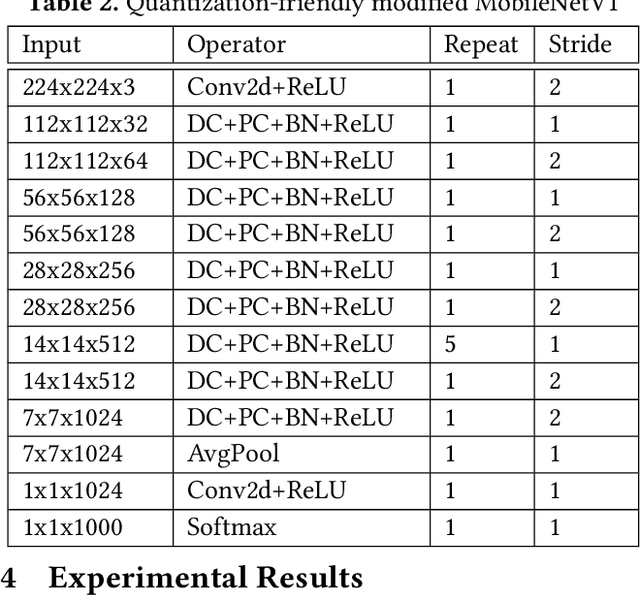
As deep learning (DL) is being rapidly pushed to edge computing, researchers invented various ways to make inference computation more efficient on mobile/IoT devices, such as network pruning, parameter compression, and etc. Quantization, as one of the key approaches, can effectively offload GPU, and make it possible to deploy DL on fixed-point pipeline. Unfortunately, not all existing networks design are friendly to quantization. For example, the popular lightweight MobileNetV1, while it successfully reduces parameter size and computation latency with separable convolution, our experiment shows its quantized models have large accuracy gap against its float point models. To resolve this, we analyzed the root cause of quantization loss and proposed a quantization-friendly separable convolution architecture. By evaluating the image classification task on ImageNet2012 dataset, our modified MobileNetV1 model can archive 8-bit inference top-1 accuracy in 68.03%, almost closed the gap to the float pipeline.
Deep joint rain and haze removal from single images
Jan 21, 2018
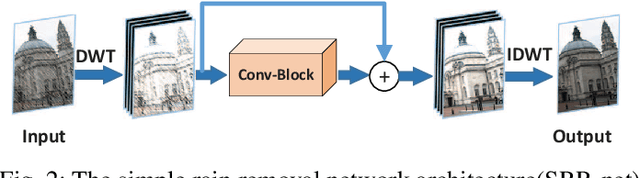
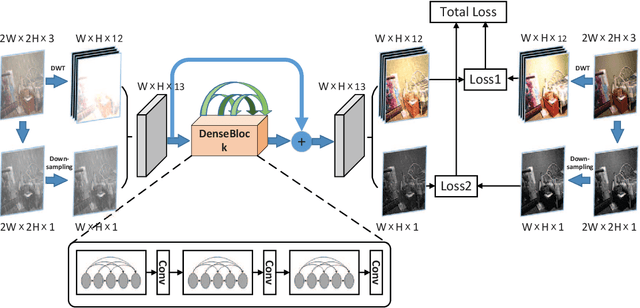

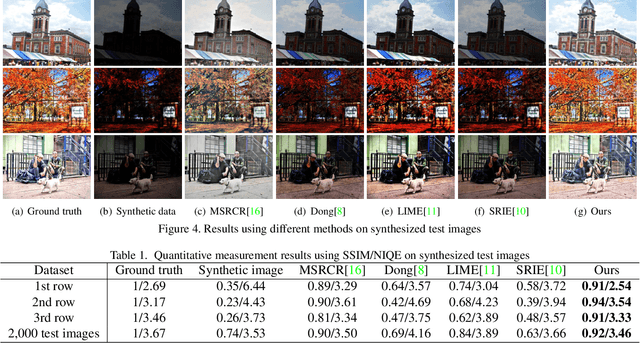
Rain removal from a single image is a challenge which has been studied for a long time. In this paper, a novel convolutional neural network based on wavelet and dark channel is proposed. On one hand, we think that rain streaks correspond to high frequency component of the image. Therefore, haar wavelet transform is a good choice to separate the rain streaks and background to some extent. More specifically, the LL subband of a rain image is more inclined to express the background information, while LH, HL, HH subband tend to represent the rain streaks and the edges. On the other hand, the accumulation of rain streaks from long distance makes the rain image look like haze veil. We extract dark channel of rain image as a feature map in network. By increasing this mapping between the dark channel of input and output images, we achieve haze removal in an indirect way. All of the parameters are optimized by back-propagation. Experiments on both synthetic and real- world datasets reveal that our method outperforms other state-of- the-art methods from a qualitative and quantitative perspective.
MSR-net:Low-light Image Enhancement Using Deep Convolutional Network
Nov 07, 2017
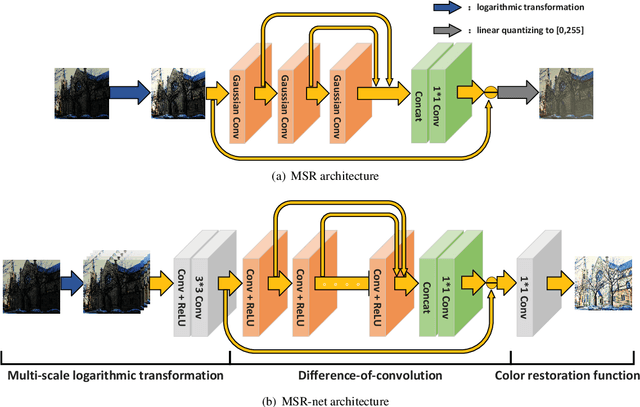

Images captured in low-light conditions usually suffer from very low contrast, which increases the difficulty of subsequent computer vision tasks in a great extent. In this paper, a low-light image enhancement model based on convolutional neural network and Retinex theory is proposed. Firstly, we show that multi-scale Retinex is equivalent to a feedforward convolutional neural network with different Gaussian convolution kernels. Motivated by this fact, we consider a Convolutional Neural Network(MSR-net) that directly learns an end-to-end mapping between dark and bright images. Different fundamentally from existing approaches, low-light image enhancement in this paper is regarded as a machine learning problem. In this model, most of the parameters are optimized by back-propagation, while the parameters of traditional models depend on the artificial setting. Experiments on a number of challenging images reveal the advantages of our method in comparison with other state-of-the-art methods from the qualitative and quantitative perspective.