 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispensed Transformer Network for Unsupervised Domain Adaptation
Oct 28, 2021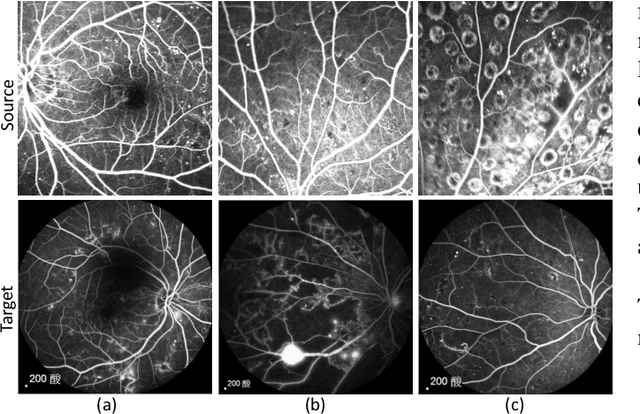
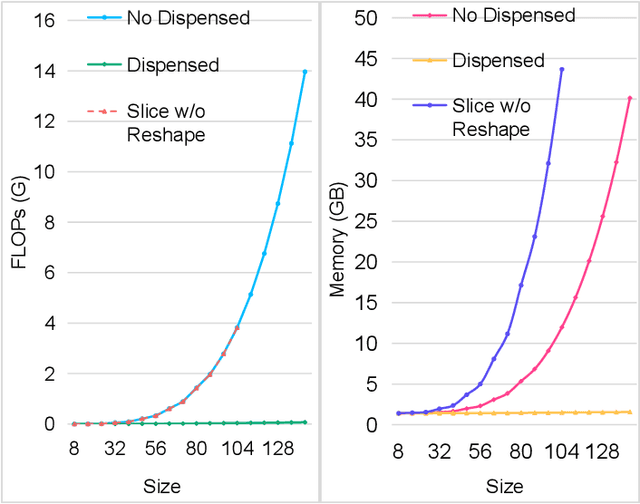
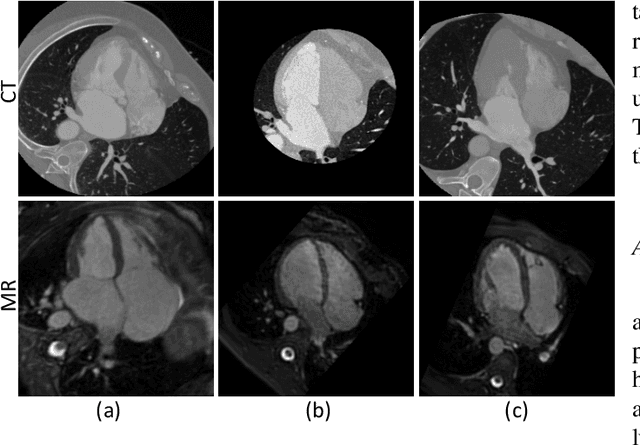
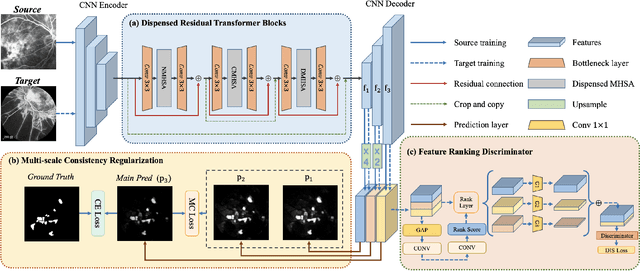
Accurate segmentation is a crucial step in medical image analysis and applying supervised machine learning to segment the organs or lesions has been substantiated effective. However, it is costly to perform data annotation that provides ground truth labels for training the supervised algorithms, and the high variance of data that comes from different domains tends to severely degrade system performance over cross-site or cross-modality datasets. To mitigate this problem, a novel unsupervised domain adaptation (UDA) method named dispensed Transformer network (DTNet) is introduced in this paper. Our novel DTNet contains three modules. First, a dispensed residual transformer block is designed, which realizes global attention by dispensed interleaving operation and deals with the excessive computational cost and GPU memory usage of the Transformer. Second, a multi-scale consistency regularization is proposed to alleviate the loss of details in the low-resolution output for better feature alignment. Finally, a feature ranking discriminator is introduced to automatically assign different weights to domain-gap features to lessen the feature distribution distance, reducing the performance shift of two domains. The proposed method is evaluated on large fluorescein angiography (FA) retinal nonperfusion (RNP) cross-site dataset with 676 images and a wide used cross-modality dataset from the MM-WHS challenge. Extensive results demonstrate that our proposed network achieves the best performance in comparison with several state-of-the-art techniques.
Joint Model and Data Driven Receiver Design for Data-Dependent Superimposed Training Scheme with Imperfect Hardware
Oct 26, 2021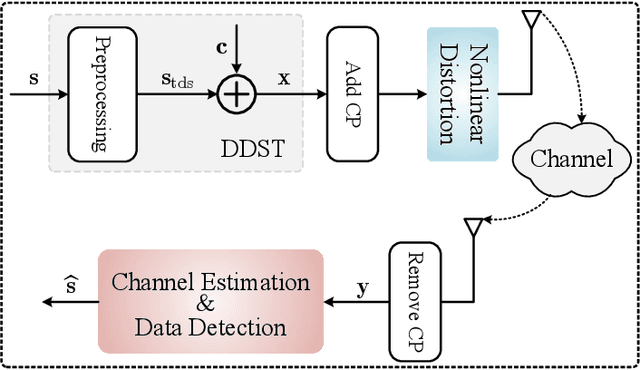
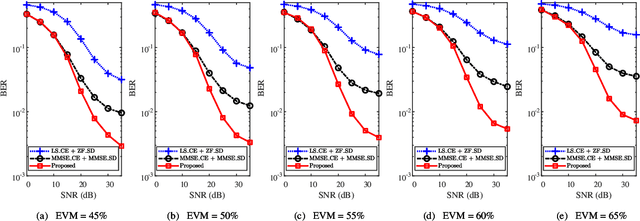
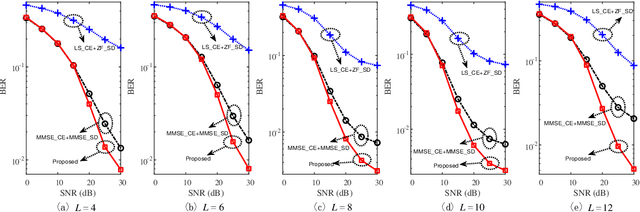
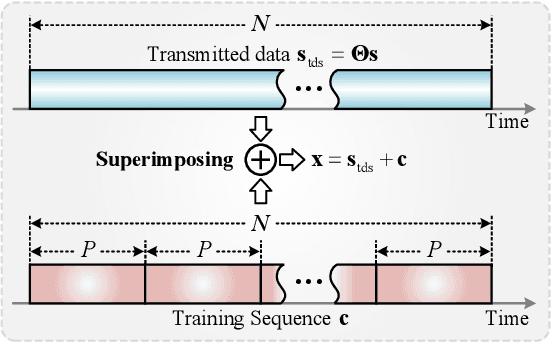
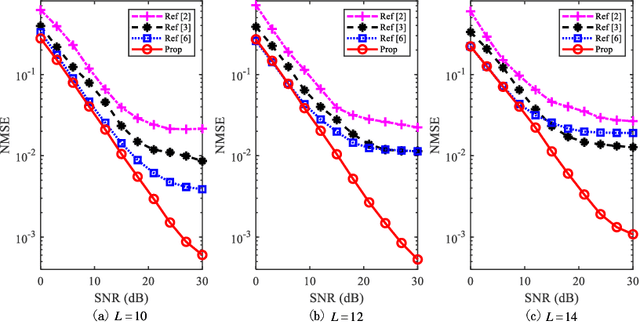
Data-dependent superimposed training (DDST) scheme has shown the potential to achieve high bandwidth efficiency, while encounters symbol misidentification caused by hardware imperfection. To tackle these challenges, a joint model and data driven receiver scheme is proposed in this paper. Specifically, based on the conventional linear receiver model, the least squares (LS) estimation and zero forcing (ZF) equalization are first employed to extract the initial features for channel estimation and data detection. Then, shallow neural networks, named CE-Net and SD-Net, are developed to refine the channel estimation and data detection, where the imperfect hardware is modeled as a nonlinear function and data is utilized to train these neural networks to approximate it. Simulation results show that compared with the conventional minimum mean square error (MMSE) equalization scheme, the proposed one effectively suppresses the symbol misidentification and achieves similar or better bit error rate (BER) performance without the second-order statistics about the channel and noise.
Enhanced ELM Based Channel Estimation for RIS-Assisted OFDM systems with Insufficient CP and Imperfect Hardware
Oct 26, 2021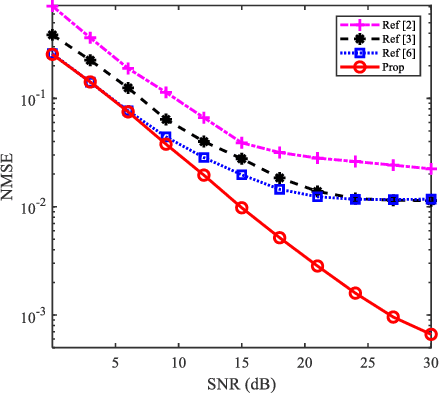

Reconfigurable intelligent surface (RIS)-assisted orthogonal frequency division multiplexing (OFDM) systems have aroused extensive research interests due to the controllable communication environment and the performance of combating multi-path interference. However, as the premise of RIS-assisted OFDM systems, the accuracy of channel estimation is severely degraded by the increased possibility of insufficient cyclic prefix (CP) produced by extra cascaded channels of RIS and the nonlinear distortion lead by imperfect hardware. To address these issues, an enhanced extreme learning machine (ELM)- based channel estimation (eELM-CE) is proposed in this letter to facilitate accurate channel estimation. Based on the model-driven mode, least square (LS) estimation is employed to highlight the initial linear features for channel estimation. Then, according to the obtained initial features, an enhanced ELM network is constructed to refine the channel estimation. In particular, we start from the perspective of guiding it to recognize the feature, and normalize the data after the network activation function to enhance the ability of identifying non-linear factors. Experiment results show that, compared with existing methods, the proposed method achieves a much lower normalized mean square error (NMSE) given insufficient CP and imperfect hardware. In addition, the simulation results indicate that the proposed method possesses robustness against the parameter variations.
Wav2vec-S: Semi-Supervised Pre-Training for Speech Recognition
Oct 09, 2021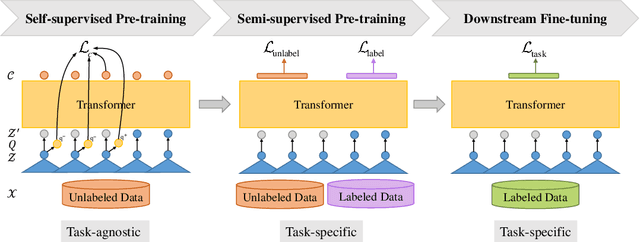
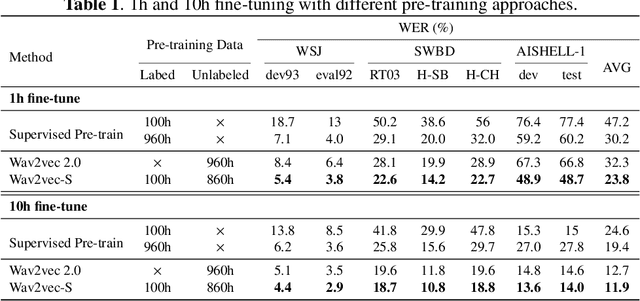
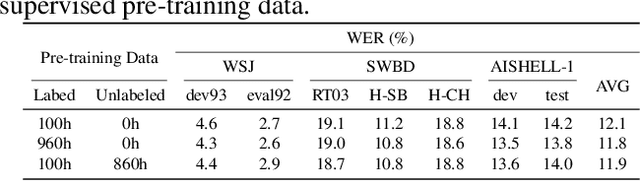
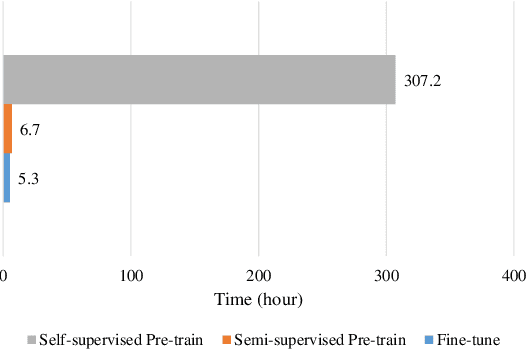
Self-supervised pre-training has dramatically improved the performance of automatic speech recognition (ASR). However, most existing self-supervised pre-training approaches are task-agnostic, i.e., could be applied to various downstream tasks. And there is a gap between the task-agnostic pre-training and the task-specific downstream fine-tuning, which may degrade the downstream performance. In this work, we propose a novel pre-training paradigm called wav2vec-S, where we use task-specific semi-supervised pre-training to bridge this gap. Specifically, the semi-supervised pre-training is conducted on the basis of self-supervised pre-training such as wav2vec 2.0. Experiments on ASR show that compared to wav2vec 2.0, wav2vec-S only requires marginal increment of pre-training time but could significantly improve ASR performance on in-domain, cross-domain and cross-lingual datasets. The average relative WER reductions are 26.3% and 6.3% for 1h and 10h fine-tuning, respectively.
Two-Stage Mesh Deep Learning for Automated Tooth Segmentation and Landmark Localization on 3D Intraoral Scans
Sep 24, 2021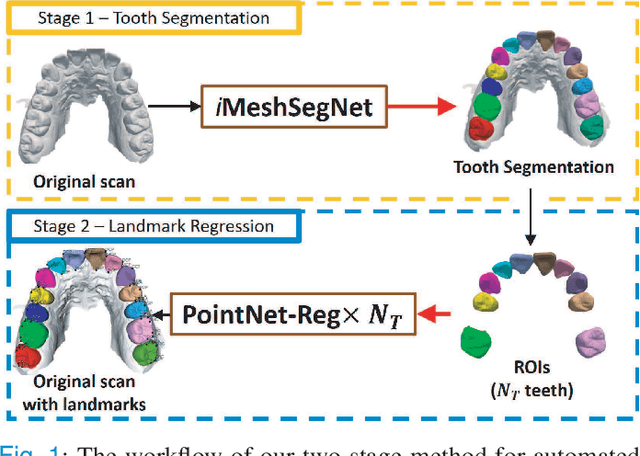
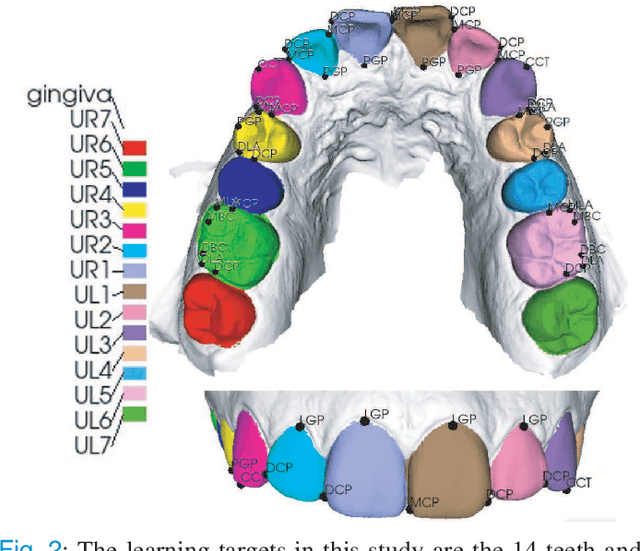
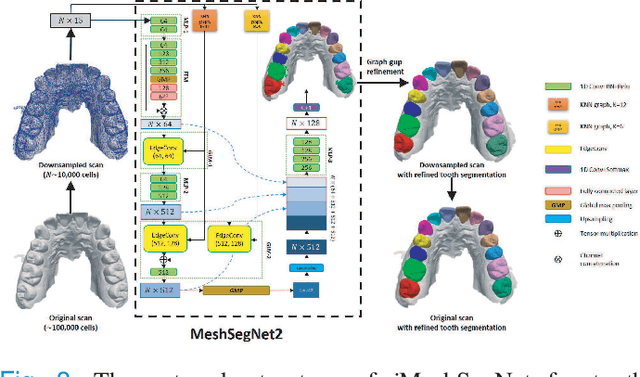
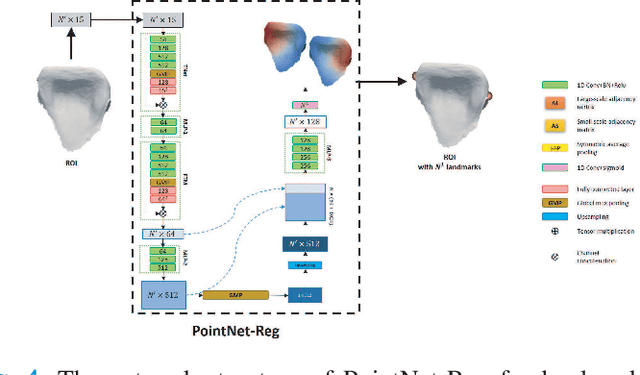
Accurately segmenting teeth and identifying the corresponding anatomical landmarks on dental mesh models are essential in computer-aided orthodontic treatment. Manually performing these two tasks is time-consuming, tedious, and, more importantly, highly dependent on orthodontists' experiences due to the abnormality and large-scale variance of patients' teeth. Some machine learning-based methods have been designed and applied in the orthodontic field to automatically segment dental meshes (e.g., intraoral scans). In contrast, the number of studies on tooth landmark localization is still limited. This paper proposes a two-stage framework based on mesh deep learning (called TS-MDL) for joint tooth labeling and landmark identification on raw intraoral scans. Our TS-MDL first adopts an end-to-end \emph{i}MeshSegNet method (i.e., a variant of the existing MeshSegNet with both improved accuracy and efficiency) to label each tooth on the downsampled scan. Guided by the segmentation outputs, our TS-MDL further selects each tooth's region of interest (ROI) on the original mesh to construct a light-weight variant of the pioneering PointNet (i.e., PointNet-Reg) for regressing the corresponding landmark heatmaps. Our TS-MDL was evaluated on a real-clinical dataset, showing promising segmentation and localization performance. Specifically, \emph{i}MeshSegNet in the first stage of TS-MDL reached an averaged Dice similarity coefficient (DSC) at $0.953\pm0.076$, significantly outperforming the original MeshSegNet. In the second stage, PointNet-Reg achieved a mean absolute error (MAE) of $0.623\pm0.718 \, mm$ in distances between the prediction and ground truth for $44$ landmarks, which is superior compared with other networks for landmark detection. All these results suggest the potential usage of our TS-MDL in clinical practices.
Structure-Enhanced Pop Music Generation via Harmony-Aware Learning
Sep 14, 2021
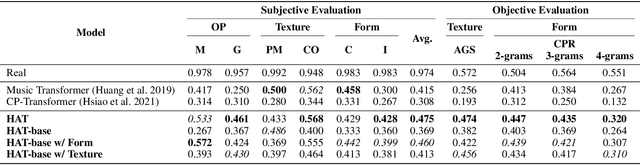
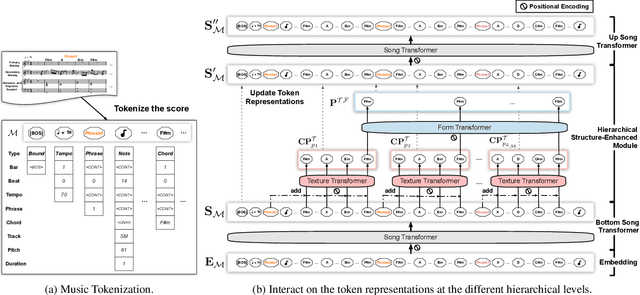
Automatically composing pop music with a satisfactory structure is an attractive but challenging topic. Although the musical structure is easy to be perceived by human, it is difficult to be described clearly and defined accurately. And it is still far from being solved that how we should model the structure in pop music generation. In this paper, we propose to leverage harmony-aware learning for structure-enhanced pop music generation. On the one hand, one of the participants of harmony, chord, represents the harmonic set of multiple notes, which is integrated closely with the spatial structure of music, texture. On the other hand, the other participant of harmony, chord progression, usually accompanies with the development of the music, which promotes the temporal structure of music, form. Besides, when chords evolve into chord progression, the texture and the form can be bridged by the harmony naturally, which contributes to the joint learning of the two structures. Furthermore, we propose the Harmony-Aware Hierarchical Music Transformer (HAT), which can exploit the structure adaptively from the music, and interact on the music tokens at multiple levels to enhance the signals of the structure in various musical elements. Results of subjective and objective evaluations demonstrate that HAT significantly improves the quality of generated music, especially in the structureness.
HyAR: Addressing Discrete-Continuous Action Reinforcement Learning via Hybrid Action Representation
Sep 12, 2021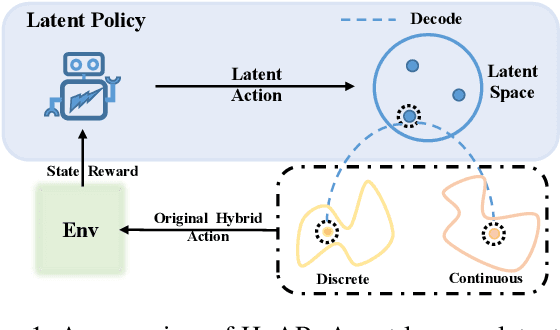
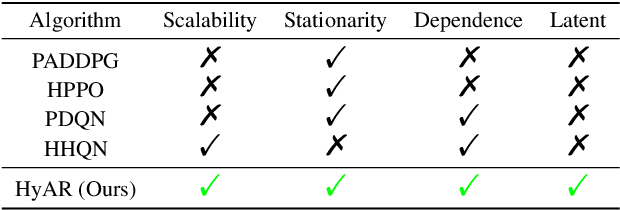
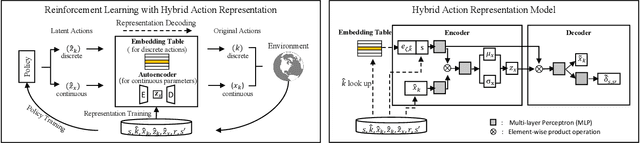
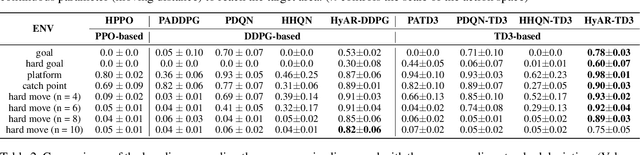
Discrete-continuous hybrid action space is a natural setting in many practical problems, such as robot control and game AI. However, most previous Reinforcement Learning (RL) works only demonstrate the success in controlling with either discrete or continuous action space, while seldom take into account the hybrid action space. One naive way to address hybrid action RL is to convert the hybrid action space into a unified homogeneous action space by discretization or continualization, so that conventional RL algorithms can be applied. However, this ignores the underlying structure of hybrid action space and also induces the scalability issue and additional approximation difficulties, thus leading to degenerated results. In this paper, we propose Hybrid Action Representation (HyAR) to learn a compact and decodable latent representation space for the original hybrid action space. HyAR constructs the latent space and embeds the dependence between discrete action and continuous parameter via an embedding table and conditional Variantional Auto-Encoder (VAE). To further improve the effectiveness, the action representation is trained to be semantically smooth through unsupervised environmental dynamics prediction. Finally, the agent then learns its policy with conventional DRL algorithms in the learned representation space and interacts with the environment by decoding the hybrid action embeddings to the original action space. We evaluate HyAR in a variety of environments with discrete-continuous action space. The results demonstrate the superiority of HyAR when compared with previous baselines, especially for high-dimensional action spaces.
Progressive Coordinate Transforms for Monocular 3D Object Detection
Aug 13, 2021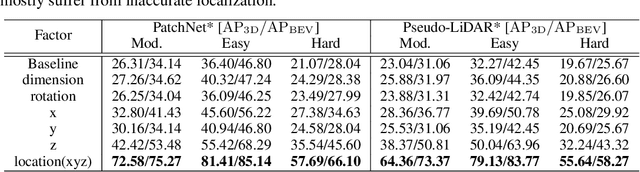

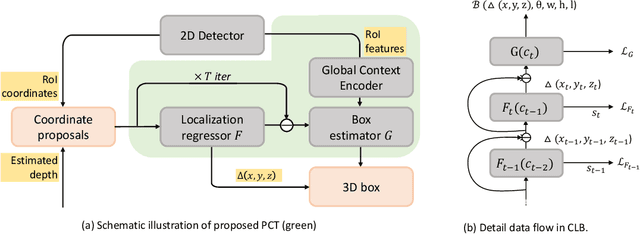
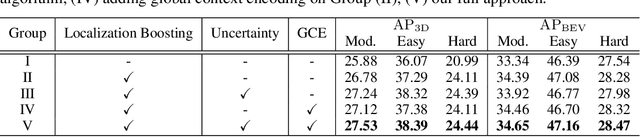
Recognizing and localizing objects in the 3D space is a crucial ability for an AI agent to perceive its surrounding environment. While significant progress has been achieved with expensive LiDAR point clouds, it poses a great challenge for 3D object detection given only a monocular image. While there exist different alternatives for tackling this problem, it is found that they are either equipped with heavy networks to fuse RGB and depth information or empirically ineffective to process millions of pseudo-LiDAR points. With in-depth examination, we realize that these limitations are rooted in inaccurate object localization. In this paper, we propose a novel and lightweight approach, dubbed {\em Progressive Coordinate Transforms} (PCT) to facilitate learning coordinate representations. Specifically, a localization boosting mechanism with confidence-aware loss is introduced to progressively refine the localization prediction. In addition, semantic image representation is also exploited to compensate for the usage of patch proposals. Despite being lightweight and simple, our strategy leads to superior improvements on the KITTI and Waymo Open Dataset monocular 3D detection benchmarks. At the same time, our proposed PCT shows great generalization to most coordinate-based 3D detection frameworks. The code is available at: https://github.com/amazon-research/progressive-coordinate-transforms .
Text Anchor Based Metric Learning for Small-footprint Keyword Spotting
Aug 12, 2021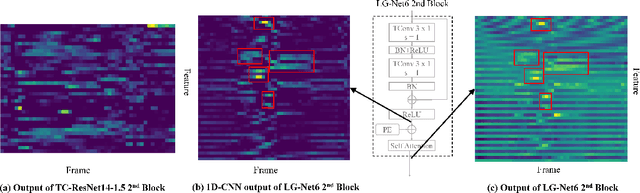

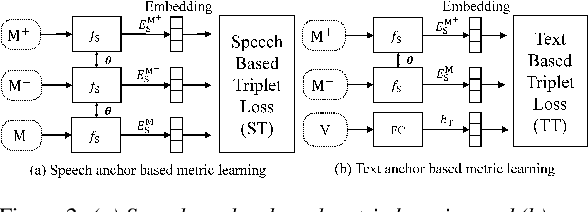
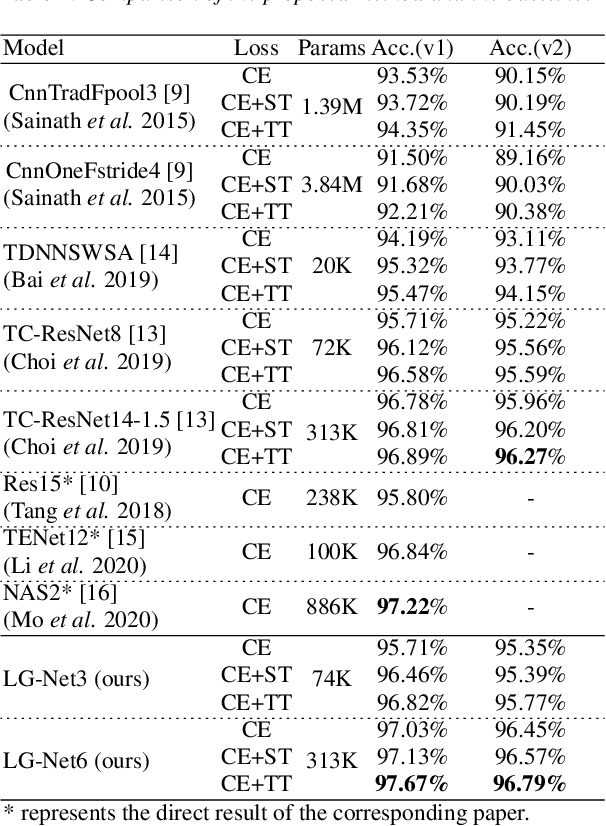
Keyword Spotting (KWS) remains challenging to achieve the trade-off between small footprint and high accuracy. Recently proposed metric learning approaches improved the generalizability of models for the KWS task, and 1D-CNN based KWS models have achieved the state-of-the-arts (SOTA) in terms of model size. However, for metric learning, due to data limitations, the speech anchor is highly susceptible to the acoustic environment and speakers. Also, we note that the 1D-CNN models have limited capability to capture long-term temporal acoustic features. To address the above problems, we propose to utilize text anchors to improve the stability of anchors. Furthermore, a new type of model (LG-Net) is exquisitely designed to promote long-short term acoustic feature modeling based on 1D-CNN and self-attention. Experiments are conducted on Google Speech Commands Dataset version 1 (GSCDv1) and 2 (GSCDv2). The results demonstrate that the proposed text anchor based metric learning method shows consistent improvements over speech anchor on representative CNN-based models. Moreover, our LG-Net model achieves SOTA accuracy of 97.67% and 96.79% on two datasets, respectively. It is encouraged to see that our lighter LG-Net with only 74k parameters obtains 96.82% KWS accuracy on the GSCDv1 and 95.77% KWS accuracy on the GSCDv2.
Privacy Threats Analysis to Secure Federated Learning
Jun 24, 2021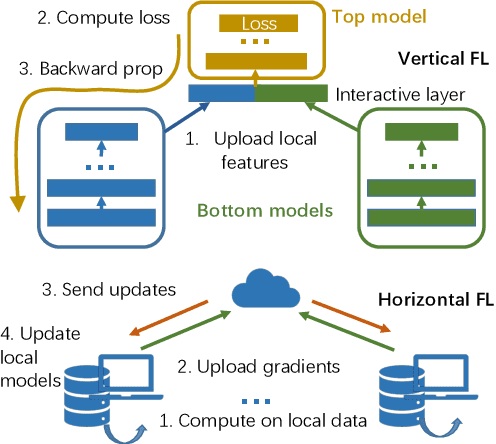
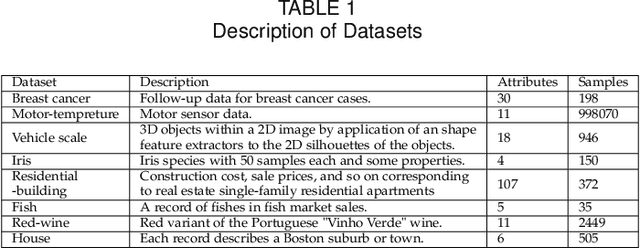
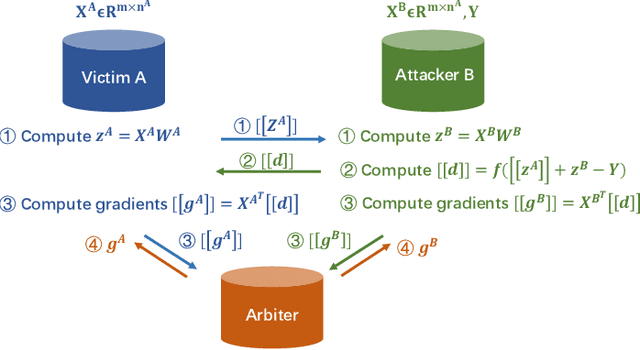
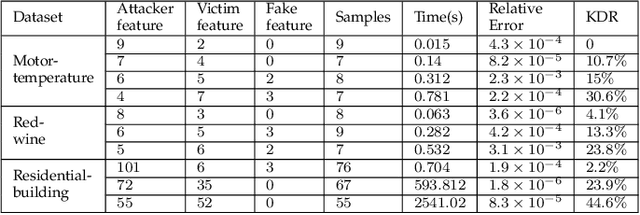
Federated learning is emerging as a machine learning technique that trains a model across multiple decentralized parties. It is renowned for preserving privacy as the data never leaves the computational devices, and recent approaches further enhance its privacy by hiding messages transferred in encryption. However, we found that despite the efforts, federated learning remains privacy-threatening, due to its interactive nature across different parties. In this paper, we analyze the privacy threats in industrial-level federated learning frameworks with secure computation, and reveal such threats widely exist in typical machine learning models such as linear regression, logistic regression and decision tree. For the linear and logistic regression, we show through theoretical analysis that it is possible for the attacker to invert the entire private input of the victim, given very few information. For the decision tree model, we launch an attack to infer the range of victim's private inputs. All attacks are evaluated on popular federated learning frameworks and real-world datasets.