 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning in Vector Space: An Exploratory Study of Question Answering
Feb 26, 2016

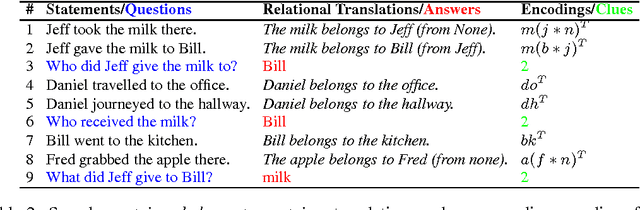

Question answering tasks have shown remarkable progress with distributed vector representation. In this paper, we investigate the recently proposed Facebook bAbI tasks which consist of twenty different categories of questions that require complex reasoning. Because the previous work on bAbI are all end-to-end models, errors could come from either an imperfect understanding of semantics or in certain steps of the reasoning. For clearer analysis, we propose two vector space models inspired by Tensor Product Representation (TPR) to perform knowledge encoding and logical reasoning based on common-sense inference. They together achieve near-perfect accuracy on all categories including positional reasoning and path finding that have proved difficult for most of the previous approaches. We hypothesize that the difficulties in these categories are due to the multi-relations in contrast to uni-relational characteristic of other categories. Our exploration sheds light on designing more sophisticated dataset and moving one step toward integrating transparent and interpretable formalism of TPR into existing learning paradigms.
Stacked Attention Networks for Image Question Answering
Jan 26, 2016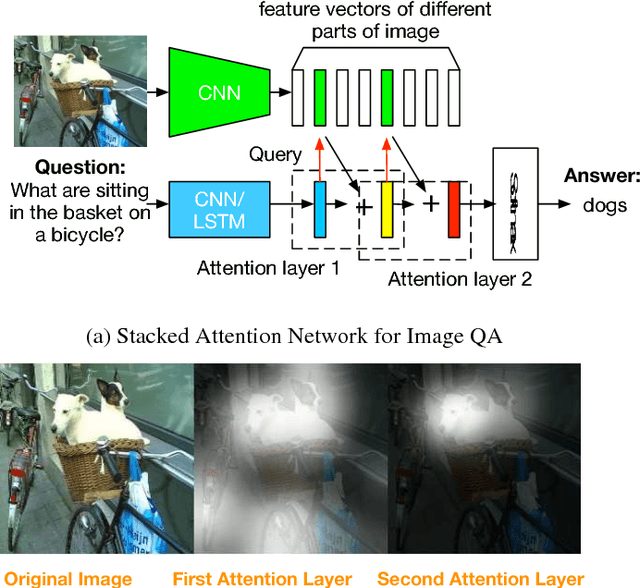
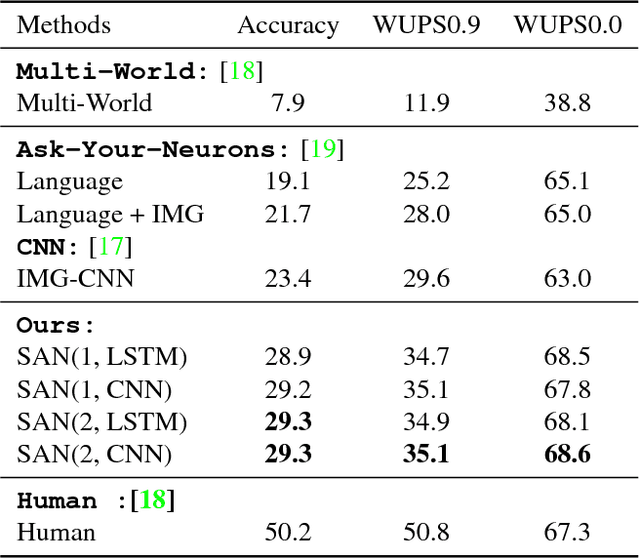
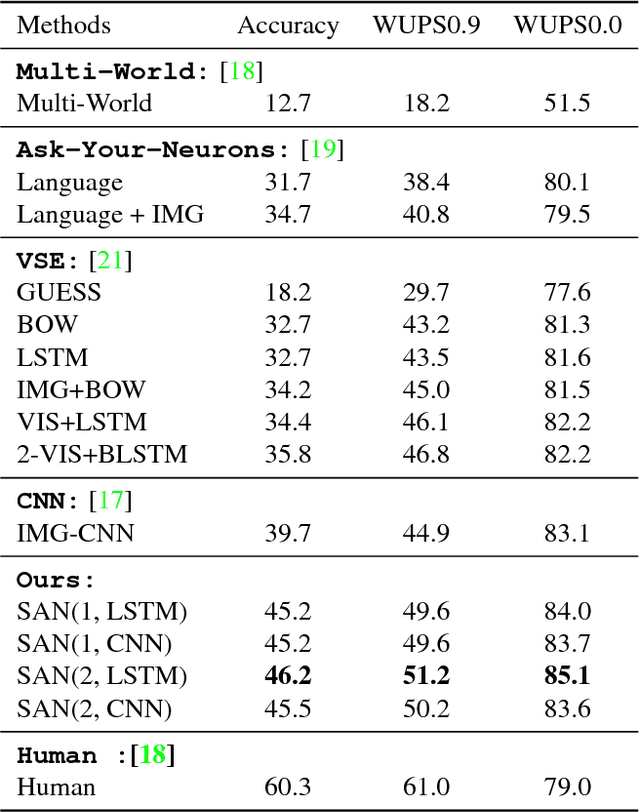
This paper presents stacked attention networks (SANs) that learn to answer natural language questions from images. SANs use semantic representation of a question as query to search for the regions in an image that are related to the answer. We argue that image question answering (QA) often requires multiple steps of reasoning. Thus, we develop a multiple-layer SAN in which we query an image multiple times to infer the answer progressively. Experiments conducted on four image QA data sets demonstrate that the proposed SANs significantly outperform previous state-of-the-art approaches. The visualization of the attention layers illustrates the progress that the SAN locates the relevant visual clues that lead to the answer of the question layer-by-layer.
Deep Sentence Embedding Using Long Short-Term Memory Networks: Analysis and Application to Information Retrieval
Jan 16, 2016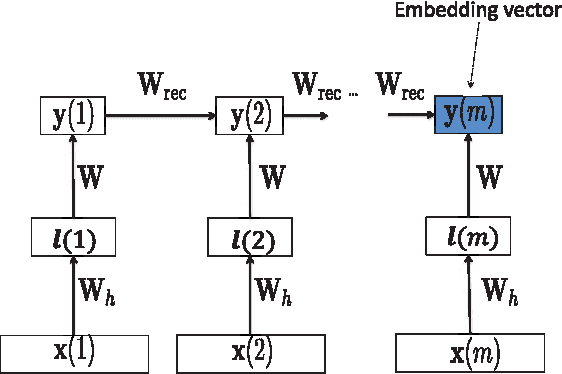
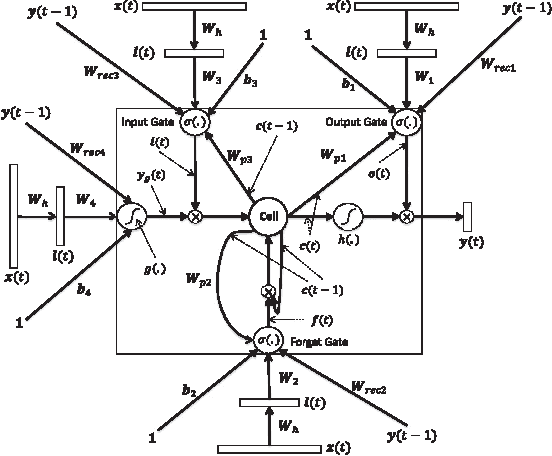
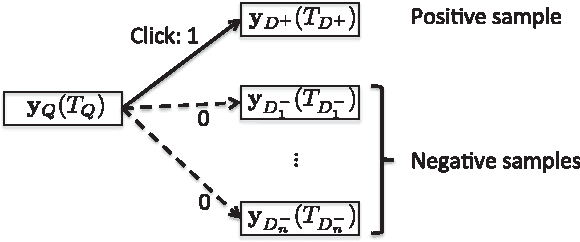
This paper develops a model that addresses sentence embedding, a hot topic in current natural language processing research, using recurrent neural networks with Long Short-Term Memory (LSTM) cells. Due to its ability to capture long term memory, the LSTM-RNN accumulates increasingly richer information as it goes through the sentence, and when it reaches the last word, the hidden layer of the network provides a semantic representation of the whole sentence. In this paper, the LSTM-RNN is trained in a weakly supervised manner on user click-through data logged by a commercial web search engine. Visualization and analysis are performed to understand how the embedding process works. The model is found to automatically attenuate the unimportant words and detects the salient keywords in the sentence. Furthermore, these detected keywords are found to automatically activate different cells of the LSTM-RNN, where words belonging to a similar topic activate the same cell. As a semantic representation of the sentence, the embedding vector can be used in many different applications. These automatic keyword detection and topic allocation abilities enabled by the LSTM-RNN allow the network to perform document retrieval, a difficult language processing task, where the similarity between the query and documents can be measured by the distance between their corresponding sentence embedding vectors computed by the LSTM-RNN. On a web search task, the LSTM-RNN embedding is shown to significantly outperform several existing state of the art methods. We emphasize that the proposed model generates sentence embedding vectors that are specially useful for web document retrieval tasks. A comparison with a well known general sentence embedding method, the Paragraph Vector, is performed. The results show that the proposed method in this paper significantly outperforms it for web document retrieval task.
Basic Reasoning with Tensor Product Representations
Jan 12, 2016In this paper we present the initial development of a general theory for mapping inference in predicate logic to computation over Tensor Product Representations (TPRs; Smolensky (1990), Smolensky & Legendre (2006)). After an initial brief synopsis of TPRs (Section 0), we begin with particular examples of inference with TPRs in the 'bAbI' question-answering task of Weston et al. (2015) (Section 1). We then present a simplification of the general analysis that suffices for the bAbI task (Section 2). Finally, we lay out the general treatment of inference over TPRs (Section 3). We also show the simplification in Section 2 derives the inference methods described in Lee et al. (2016); this shows how the simple methods of Lee et al. (2016) can be formally extended to more general reasoning tasks.
Recurrent Reinforcement Learning: A Hybrid Approach
Nov 19, 2015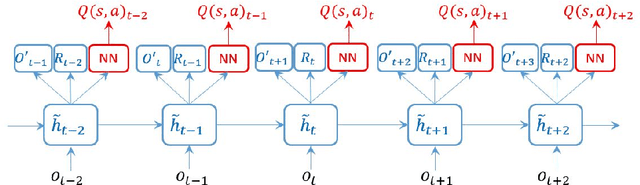
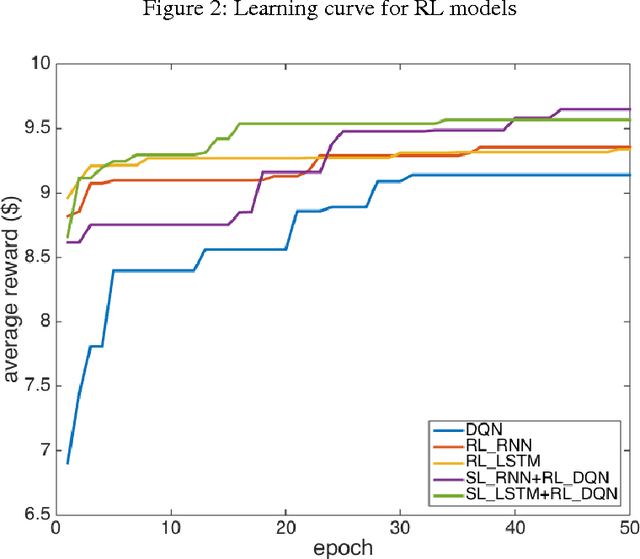
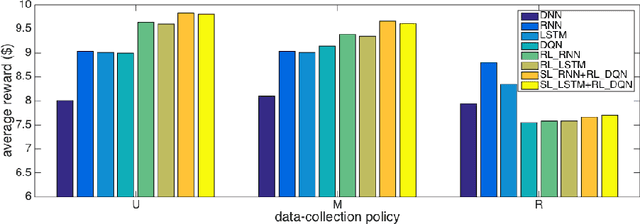
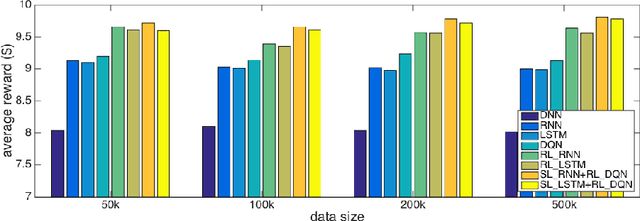
Successful applications of reinforcement learning in real-world problems often require dealing with partially observable states. It is in general very challenging to construct and infer hidden states as they often depend on the agent's entire interaction history and may require substantial domain knowledge. In this work, we investigate a deep-learning approach to learning the representation of states in partially observable tasks, with minimal prior knowledge of the domain. In particular, we propose a new family of hybrid models that combines the strength of both supervised learning (SL) and reinforcement learning (RL), trained in a joint fashion: The SL component can be a recurrent neural networks (RNN) or its long short-term memory (LSTM) version, which is equipped with the desired property of being able to capture long-term dependency on history, thus providing an effective way of learning the representation of hidden states. The RL component is a deep Q-network (DQN) that learns to optimize the control for maximizing long-term rewards. Extensive experiments in a direct mailing campaign problem demonstrate the effectiveness and advantages of the proposed approach, which performs the best among a set of previous state-of-the-art methods.
End-to-end Learning of LDA by Mirror-Descent Back Propagation over a Deep Architecture
Nov 01, 2015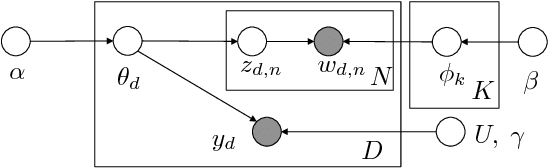
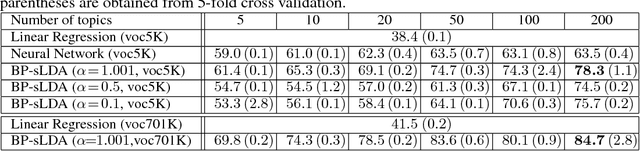

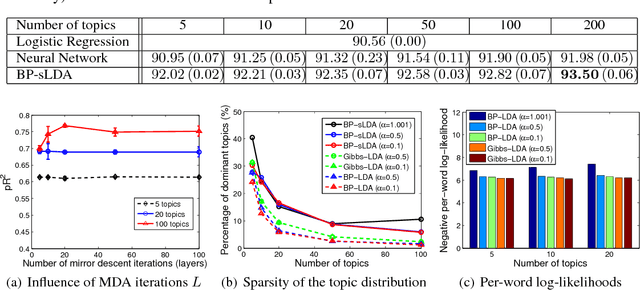
We develop a fully discriminative learning approach for supervised Latent Dirichlet Allocation (LDA) model using Back Propagation (i.e., BP-sLDA), which maximizes the posterior probability of the prediction variable given the input document. Different from traditional variational learning or Gibbs sampling approaches, the proposed learning method applies (i) the mirror descent algorithm for maximum a posterior inference and (ii) back propagation over a deep architecture together with stochastic gradient/mirror descent for model parameter estimation, leading to scalable and end-to-end discriminative learning of the model. As a byproduct, we also apply this technique to develop a new learning method for the traditional unsupervised LDA model (i.e., BP-LDA). Experimental results on three real-world regression and classification tasks show that the proposed methods significantly outperform the previous supervised topic models, neural networks, and is on par with deep neural networks.
Language Models for Image Captioning: The Quirks and What Works
Oct 14, 2015
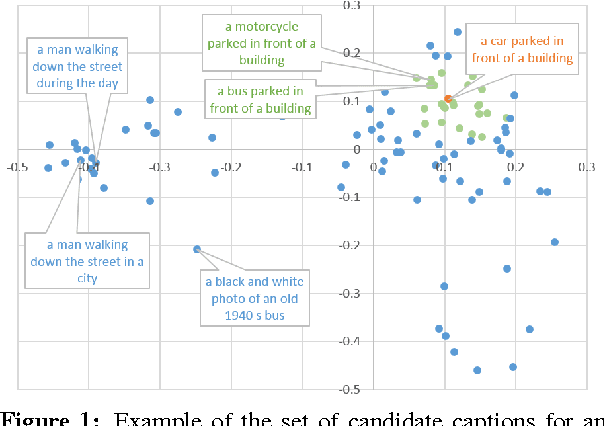
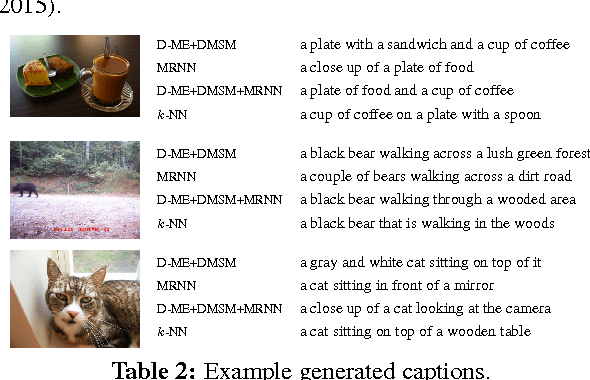

Two recent approaches have achieved state-of-the-art results in image captioning. The first uses a pipelined process where a set of candidate words is generated by a convolutional neural network (CNN) trained on images, and then a maximum entropy (ME) language model is used to arrange these words into a coherent sentence. The second uses the penultimate activation layer of the CNN as input to a recurrent neural network (RNN) that then generates the caption sequence. In this paper, we compare the merits of these different language modeling approaches for the first time by using the same state-of-the-art CNN as input. We examine issues in the different approaches, including linguistic irregularities, caption repetition, and data set overlap. By combining key aspects of the ME and RNN methods, we achieve a new record performance over previously published results on the benchmark COCO dataset. However, the gains we see in BLEU do not translate to human judgments.
Embedding Entities and Relations for Learning and Inference in Knowledge Bases
Aug 29, 2015
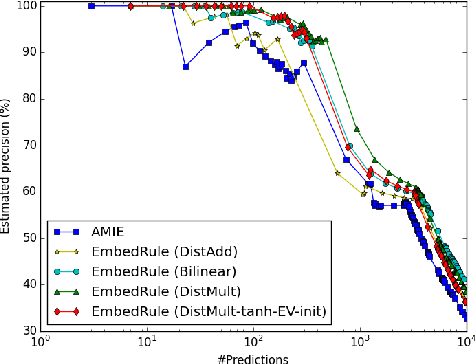
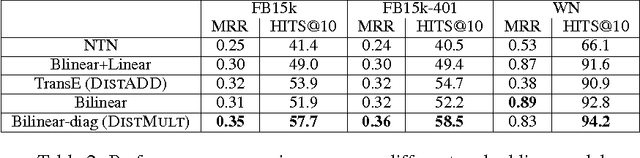
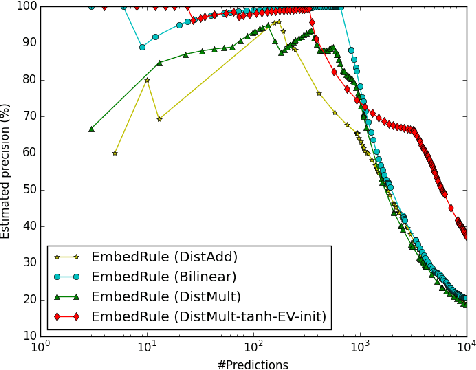
We consider learning representations of entities and relations in KBs using the neural-embedding approach. We show that most existing models, including NTN (Socher et al., 2013) and TransE (Bordes et al., 2013b), can be generalized under a unified learning framework, where entities are low-dimensional vectors learned from a neural network and relations are bilinear and/or linear mapping functions. Under this framework, we compare a variety of embedding models on the link prediction task. We show that a simple bilinear formulation achieves new state-of-the-art results for the task (achieving a top-10 accuracy of 73.2% vs. 54.7% by TransE on Freebase). Furthermore, we introduce a novel approach that utilizes the learned relation embeddings to mine logical rules such as "BornInCity(a,b) and CityInCountry(b,c) => Nationality(a,c)". We find that embeddings learned from the bilinear objective are particularly good at capturing relational semantics and that the composition of relations is characterized by matrix multiplication. More interestingly, we demonstrate that our embedding-based rule extraction approach successfully outperforms a state-of-the-art confidence-based rule mining approach in mining Horn rules that involve compositional reasoning.
A Deep Embedding Model for Co-occurrence Learning
Jun 04, 2015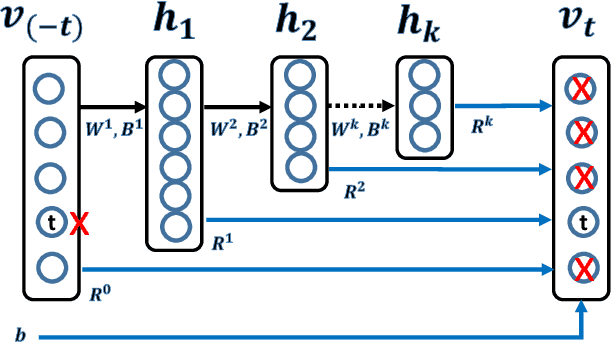
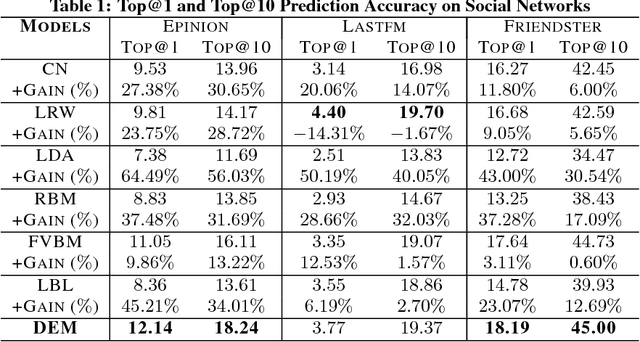
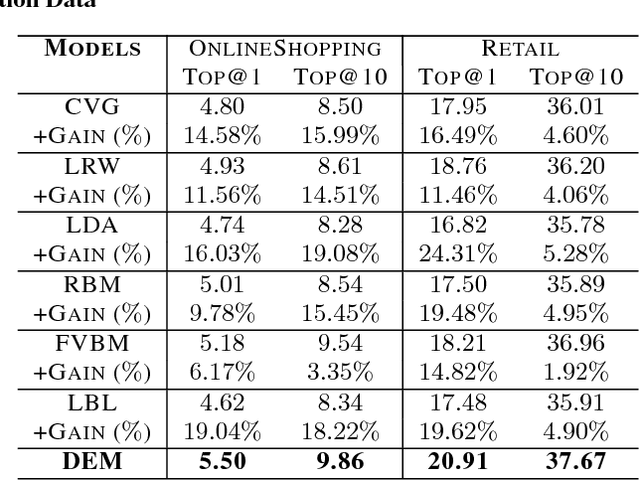
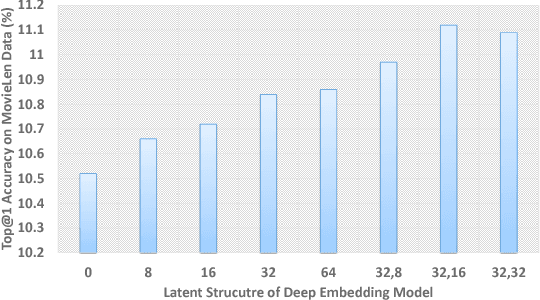
Co-occurrence Data is a common and important information source in many areas, such as the word co-occurrence in the sentences, friends co-occurrence in social networks and products co-occurrence in commercial transaction data, etc, which contains rich correlation and clustering information about the items. In this paper, we study co-occurrence data using a general energy-based probabilistic model, and we analyze three different categories of energy-based model, namely, the $L_1$, $L_2$ and $L_k$ models, which are able to capture different levels of dependency in the co-occurrence data. We also discuss how several typical existing models are related to these three types of energy models, including the Fully Visible Boltzmann Machine (FVBM) ($L_2$), Matrix Factorization ($L_2$), Log-BiLinear (LBL) models ($L_2$), and the Restricted Boltzmann Machine (RBM) model ($L_k$). Then, we propose a Deep Embedding Model (DEM) (an $L_k$ model) from the energy model in a \emph{principled} manner. Furthermore, motivated by the observation that the partition function in the energy model is intractable and the fact that the major objective of modeling the co-occurrence data is to predict using the conditional probability, we apply the \emph{maximum pseudo-likelihood} method to learn DEM. In consequence, the developed model and its learning method naturally avoid the above difficulties and can be easily used to compute the conditional probability in prediction. Interestingly, our method is equivalent to learning a special structured deep neural network using back-propagation and a special sampling strategy, which makes it scalable on large-scale datasets. Finally, in the experiments, we show that the DEM can achieve comparable or better results than state-of-the-art methods on datasets across several application domains.
Joint Learning of Distributed Representations for Images and Texts
Apr 28, 2015This technical report provides extra details of the deep multimodal similarity model (DMSM) which was proposed in (Fang et al. 2015, arXiv:1411.4952). The model is trained via maximizing global semantic similarity between images and their captions in natural language using the public Microsoft COCO database, which consists of a large set of images and their corresponding captions. The learned representations attempt to capture the combination of various visual concepts and cues.