 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Robust Classification via Learned Smoothed Densities
May 09, 2020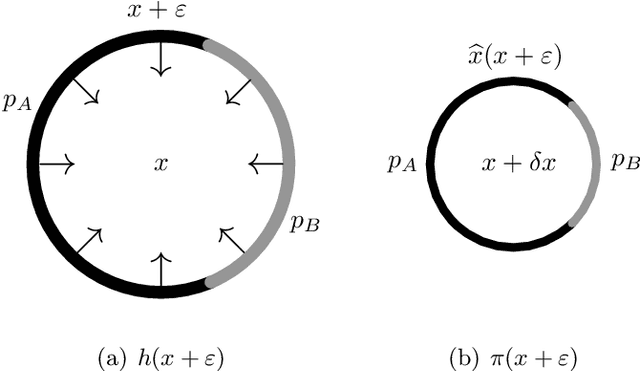

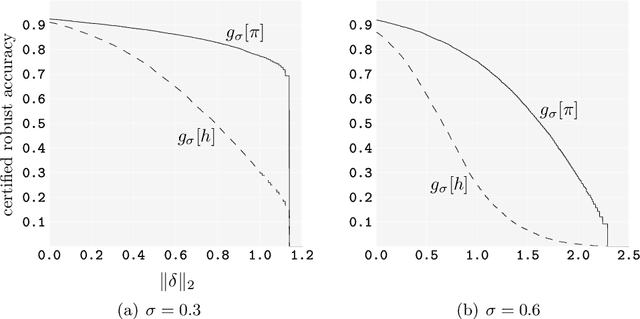

Smoothing classifiers and probability density functions with Gaussian kernels appear unrelated, but in this work, they are unified for the problem of robust classification. The key building block is approximating the $\textit{energy function}$ of the random variable $Y=X+N(0,\sigma^2 I_d)$ with a neural network which we use to formulate the problem of robust classification in terms of $\widehat{x}(Y)$, the $\textit{Bayes estimator}$ of $X$ given the noisy measurements $Y$. We introduce $\textit{empirical Bayes smoothed classifiers}$ within the framework of $\textit{randomized smoothing}$ and study it theoretically for the two-class linear classifier, where we show one can improve their robustness above $\textit{the margin}$. We test the theory on MNIST and we show that with a learned smoothed energy function and a linear classifier we can achieve provable $\ell_2$ robust accuracies that are competitive with empirical defenses. This setup can be significantly improved by $\textit{learning}$ empirical Bayes smoothed classifiers with adversarial training and on MNIST we show that we can achieve provable robust accuracies higher than the state-of-the-art empirical defenses in a range of radii. We discuss some fundamental challenges of randomized smoothing based on a geometric interpretation due to concentration of Gaussians in high dimensions, and we finish the paper with a proposal for using walk-jump sampling, itself based on learned smoothed densities, for robust classification.
Joint Learning of Distributed Representations for Images and Texts
Apr 28, 2015This technical report provides extra details of the deep multimodal similarity model (DMSM) which was proposed in (Fang et al. 2015, arXiv:1411.4952). The model is trained via maximizing global semantic similarity between images and their captions in natural language using the public Microsoft COCO database, which consists of a large set of images and their corresponding captions. The learned representations attempt to capture the combination of various visual concepts and cues.
From Captions to Visual Concepts and Back
Apr 14, 2015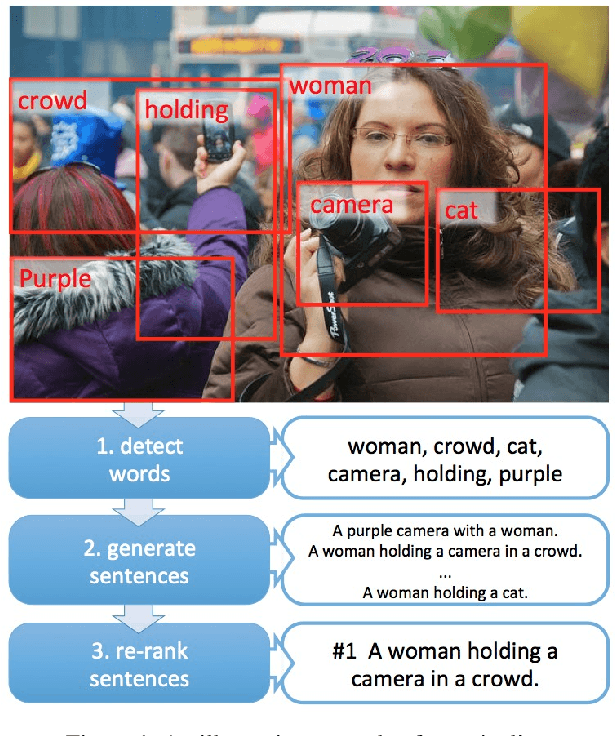

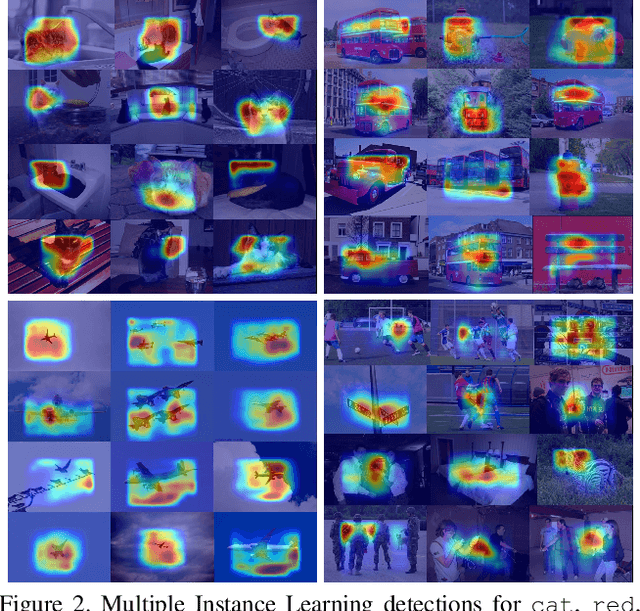

This paper presents a novel approach for automatically generating image descriptions: visual detectors, language models, and multimodal similarity models learnt directly from a dataset of image captions. We use multiple instance learning to train visual detectors for words that commonly occur in captions, including many different parts of speech such as nouns, verbs, and adjectives. The word detector outputs serve as conditional inputs to a maximum-entropy language model. The language model learns from a set of over 400,000 image descriptions to capture the statistics of word usage. We capture global semantics by re-ranking caption candidates using sentence-level features and a deep multimodal similarity model. Our system is state-of-the-art on the official Microsoft COCO benchmark, producing a BLEU-4 score of 29.1%. When human judges compare the system captions to ones written by other people on our held-out test set, the system captions have equal or better quality 34% of the time.