 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoMask: Generative Masked Modeling of 3D Human Motions
Nov 29, 2023



We introduce MoMask, a novel masked modeling framework for text-driven 3D human motion generation. In MoMask, a hierarchical quantization scheme is employed to represent human motion as multi-layer discrete motion tokens with high-fidelity details. Starting at the base layer, with a sequence of motion tokens obtained by vector quantization, the residual tokens of increasing orders are derived and stored at the subsequent layers of the hierarchy. This is consequently followed by two distinct bidirectional transformers. For the base-layer motion tokens, a Masked Transformer is designated to predict randomly masked motion tokens conditioned on text input at training stage. During generation (i.e. inference) stage, starting from an empty sequence, our Masked Transformer iteratively fills up the missing tokens; Subsequently, a Residual Transformer learns to progressively predict the next-layer tokens based on the results from current layer. Extensive experiments demonstrate that MoMask outperforms the state-of-art methods on the text-to-motion generation task, with an FID of 0.045 (vs e.g. 0.141 of T2M-GPT) on the HumanML3D dataset, and 0.228 (vs 0.514) on KIT-ML, respectively. MoMask can also be seamlessly applied in related tasks without further model fine-tuning, such as text-guided temporal inpainting.
DRIFu: Differentiable Rendering and Implicit Function-based Single-View 3D Reconstruction
Nov 23, 2023



The Differentiable Rendering and Implicit Function-based model (DRIFu) draws its roots from the Pixel-aligned Implicit Function (PIFU), a pioneering 3D digitization technique initially designed for clothed human bodies. PIFU excels in capturing nuanced body shape variations within a low-dimensional space and has been extensively trained on human 3D scans. However, the application of PIFU to live animals poses significant challenges, primarily due to the inherent difficulty in obtaining the cooperation of animals for 3D scanning. In response to this challenge, we introduce the DRIFu model, specifically tailored for animal digitization. To train DRIFu, we employ a curated set of synthetic 3D animal models, encompassing diverse shapes, sizes, and even accounting for variations such as baby birds. Our innovative alignment tools play a pivotal role in mapping these diverse synthetic animal models onto a unified template, facilitating precise predictions of animal shape and texture. Crucially, our template alignment strategy establishes a shared shape space, allowing for the seamless sampling of new animal shapes, posing them realistically, animating them, and aligning them with real-world data. This groundbreaking approach revolutionizes our capacity to comprehensively understand and represent avian forms. For further details and access to the project, the project website can be found at https://github.com/kuangzijian/drifu-for-animals
Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
Apr 13, 2023Recently, Meta AI Research approaches a general, promptable Segment Anything Model (SAM) pre-trained on an unprecedentedly large segmentation dataset (SA-1B). Without a doubt, the emergence of SAM will yield significant benefits for a wide array of practical image segmentation applications. In this study, we conduct a series of intriguing investigations into the performance of SAM across various applications, particularly in the fields of natural images, agriculture, manufacturing, remote sensing, and healthcare. We analyze and discuss the benefits and limitations of SAM and provide an outlook on future development of segmentation tasks. Note that our work does not intend to propose new algorithms or theories, but rather provide a comprehensive view of SAM in practice. This work is expected to provide insights that facilitate future research activities toward generic segmentation.
Event-based Human Pose Tracking by Spiking Spatiotemporal Transformer
Mar 31, 2023



Event camera, as an emerging biologically-inspired vision sensor for capturing motion dynamics, presents new potential for 3D human pose tracking, or video-based 3D human pose estimation. However, existing works in pose tracking either require the presence of additional gray-scale images to establish a solid starting pose, or ignore the temporal dependencies all together by collapsing segments of event streams to form static event frames. Meanwhile, although the effectiveness of Artificial Neural Networks (ANNs, a.k.a. dense deep learning) has been showcased in many event-based tasks, the use of ANNs tends to neglect the fact that compared to the dense frame-based image sequences, the occurrence of events from an event camera is spatiotemporally much sparser. Motivated by the above mentioned issues, we present in this paper a dedicated end-to-end sparse deep learning approach for event-based pose tracking: 1) to our knowledge this is the first time that 3D human pose tracking is obtained from events only, thus eliminating the need of accessing to any frame-based images as part of input; 2) our approach is based entirely upon the framework of Spiking Neural Networks (SNNs), which consists of Spike-Element-Wise (SEW) ResNet and a novel Spiking Spatiotemporal Transformer; 3) a large-scale synthetic dataset is constructed that features a broad and diverse set of annotated 3D human motions, as well as longer hours of event stream data, named SynEventHPD. Empirical experiments demonstrate that, with superior performance over the state-of-the-art (SOTA) ANNs counterparts, our approach also achieves a significant computation reduction of 80% in FLOPS. Furthermore, our proposed method also outperforms SOTA SNNs in the regression task of human pose tracking. Our implementation is available at https://github.com/JimmyZou/HumanPoseTracking_SNN and dataset will be released upon paper acceptance.
Snipper: A Spatiotemporal Transformer for Simultaneous Multi-Person 3D Pose Estimation Tracking and Forecasting on a Video Snippet
Jul 13, 2022
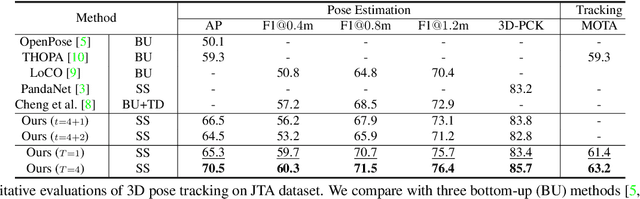
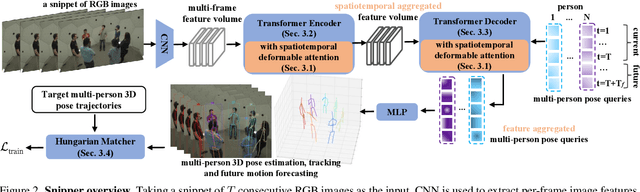
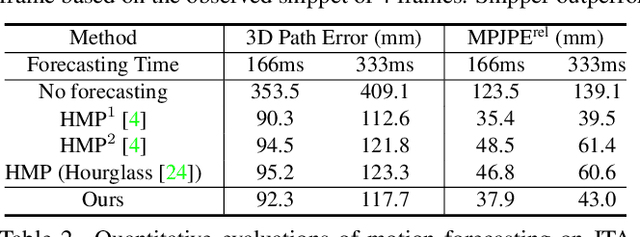
Multi-person pose understanding from RGB videos includes three complex tasks: pose estimation, tracking and motion forecasting. Among these three tasks, pose estimation and tracking are correlated, and tracking is crucial to motion forecasting. Most existing works either focus on a single task or employ cascaded methods to solve each individual task separately. In this paper, we propose Snipper, a framework to perform multi-person 3D pose estimation, tracking and motion forecasting simultaneously in a single inference. Specifically, we first propose a deformable attention mechanism to aggregate spatiotemporal information from video snippets. Building upon this deformable attention, a visual transformer is learned to encode the spatiotemporal features from multi-frame images and to decode informative pose features to update multi-person pose queries. Last, these queries are regressed to predict multi-person pose trajectories and future motions in one forward pass. In the experiments, we show the effectiveness of Snipper on three challenging public datasets where a generic model rivals specialized state-of-art baselines for pose estimation, tracking, and forecasting. Code is available at https://github.com/JimmyZou/Snipper
TM2T: Stochastic and Tokenized Modeling for the Reciprocal Generation of 3D Human Motions and Texts
Jul 04, 2022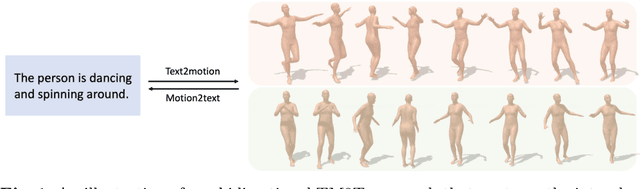
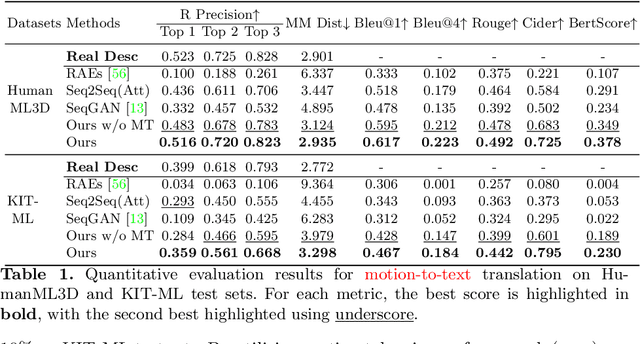
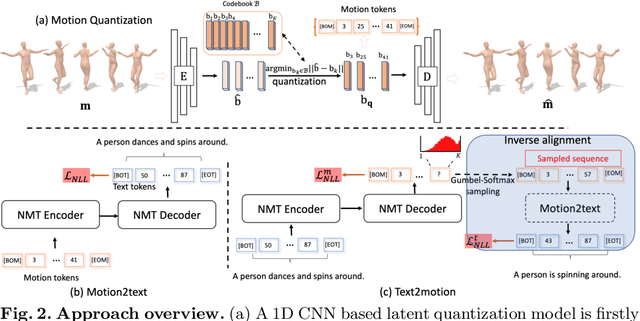
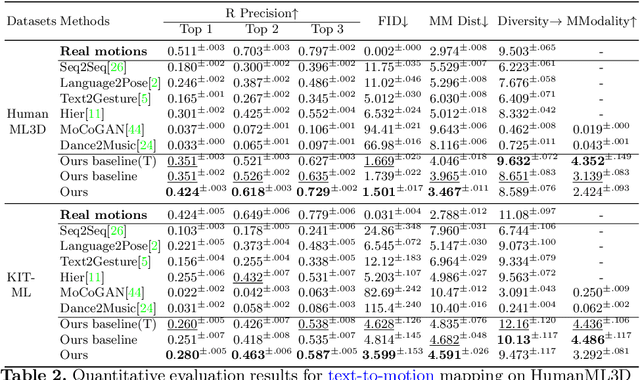
Inspired by the strong ties between vision and language, the two intimate human sensing and communication modalities, our paper aims to explore the generation of 3D human full-body motions from texts, as well as its reciprocal task, shorthanded for text2motion and motion2text, respectively. To tackle the existing challenges, especially to enable the generation of multiple distinct motions from the same text, and to avoid the undesirable production of trivial motionless pose sequences, we propose the use of motion token, a discrete and compact motion representation. This provides one level playing ground when considering both motions and text signals, as the motion and text tokens, respectively. Moreover, our motion2text module is integrated into the inverse alignment process of our text2motion training pipeline, where a significant deviation of synthesized text from the input text would be penalized by a large training loss; empirically this is shown to effectively improve performance. Finally, the mappings in-between the two modalities of motions and texts are facilitated by adapting the neural model for machine translation (NMT) to our context. This autoregressive modeling of the distribution over discrete motion tokens further enables non-deterministic production of pose sequences, of variable lengths, from an input text. Our approach is flexible, could be used for both text2motion and motion2text tasks. Empirical evaluations on two benchmark datasets demonstrate the superior performance of our approach on both tasks over a variety of state-of-the-art methods. Project page: https://ericguo5513.github.io/TM2T/
Promoting Saliency From Depth: Deep Unsupervised RGB-D Saliency Detection
May 15, 2022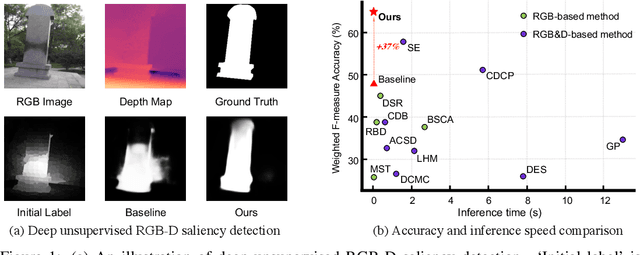
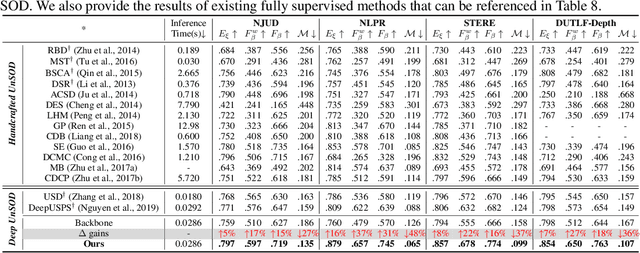
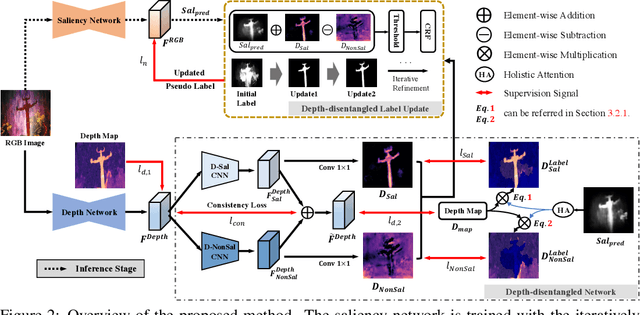
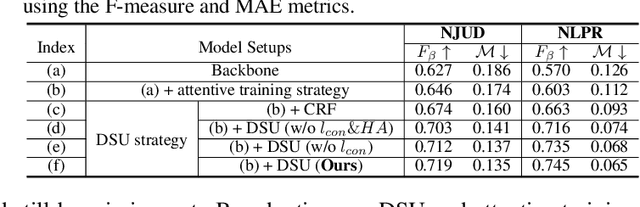
Growing interests in RGB-D salient object detection (RGB-D SOD) have been witnessed in recent years, owing partly to the popularity of depth sensors and the rapid progress of deep learning techniques. Unfortunately, existing RGB-D SOD methods typically demand large quantity of training images being thoroughly annotated at pixel-level. The laborious and time-consuming manual annotation has become a real bottleneck in various practical scenarios. On the other hand, current unsupervised RGB-D SOD methods still heavily rely on handcrafted feature representations. This inspires us to propose in this paper a deep unsupervised RGB-D saliency detection approach, which requires no manual pixel-level annotation during training. It is realized by two key ingredients in our training pipeline. First, a depth-disentangled saliency update (DSU) framework is designed to automatically produce pseudo-labels with iterative follow-up refinements, which provides more trustworthy supervision signals for training the saliency network. Second, an attentive training strategy is introduced to tackle the issue of noisy pseudo-labels, by properly re-weighting to highlight the more reliable pseudo-labels. Extensive experiments demonstrate the superior efficiency and effectiveness of our approach in tackling the challenging unsupervised RGB-D SOD scenarios. Moreover, our approach can also be adapted to work in fully-supervised situation. Empirical studies show the incorporation of our approach gives rise to notably performance improvement in existing supervised RGB-D SOD models.
Dual Learning Music Composition and Dance Choreography
Jan 28, 2022
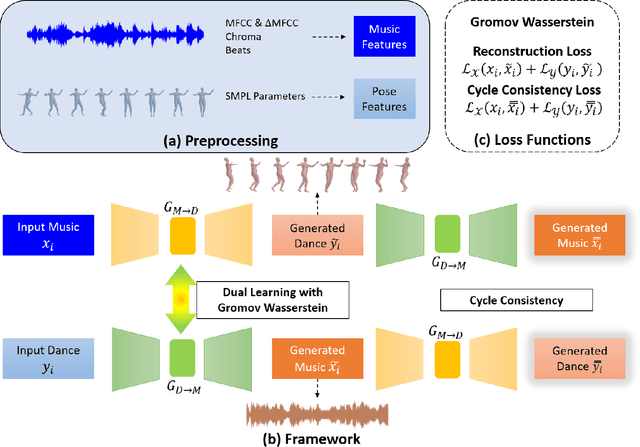
Music and dance have always co-existed as pillars of human activities, contributing immensely to the cultural, social, and entertainment functions in virtually all societies. Notwithstanding the gradual systematization of music and dance into two independent disciplines, their intimate connection is undeniable and one art-form often appears incomplete without the other. Recent research works have studied generative models for dance sequences conditioned on music. The dual task of composing music for given dances, however, has been largely overlooked. In this paper, we propose a novel extension, where we jointly model both tasks in a dual learning approach. To leverage the duality of the two modalities, we introduce an optimal transport objective to align feature embeddings, as well as a cycle consistency loss to foster overall consistency. Experimental results demonstrate that our dual learning framework improves individual task performance, delivering generated music compositions and dance choreographs that are realistic and faithful to the conditioned inputs.
Investigating Pose Representations and Motion Contexts Modeling for 3D Motion Prediction
Dec 30, 2021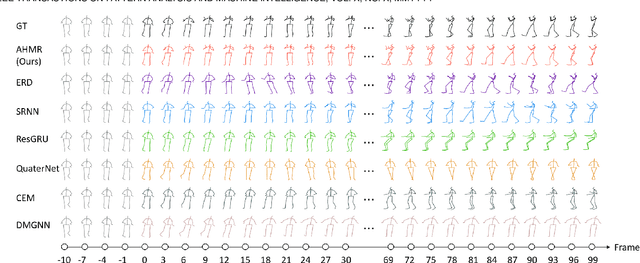
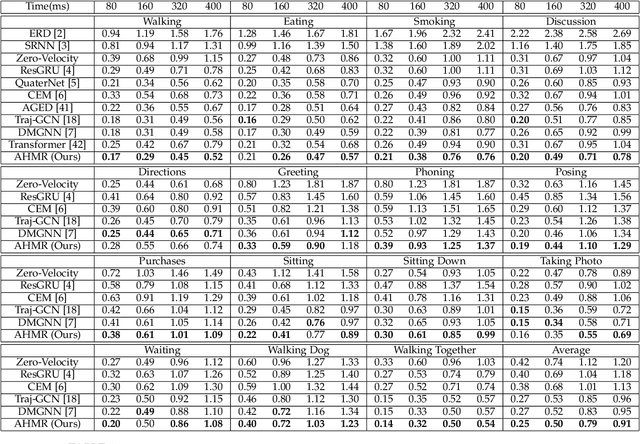

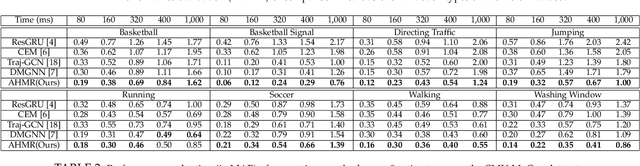
Predicting human motion from historical pose sequence is crucial for a machine to succeed in intelligent interactions with humans. One aspect that has been obviated so far, is the fact that how we represent the skeletal pose has a critical impact on the prediction results. Yet there is no effort that investigates across different pose representation schemes. We conduct an indepth study on various pose representations with a focus on their effects on the motion prediction task. Moreover, recent approaches build upon off-the-shelf RNN units for motion prediction. These approaches process input pose sequence sequentially and inherently have difficulties in capturing long-term dependencies. In this paper, we propose a novel RNN architecture termed AHMR (Attentive Hierarchical Motion Recurrent network) for motion prediction which simultaneously models local motion contexts and a global context. We further explore a geodesic loss and a forward kinematics loss for the motion prediction task, which have more geometric significance than the widely employed L2 loss. Interestingly, we applied our method to a range of articulate objects including human, fish, and mouse. Empirical results show that our approach outperforms the state-of-the-art methods in short-term prediction and achieves much enhanced long-term prediction proficiency, such as retaining natural human-like motions over 50 seconds predictions. Our codes are released.
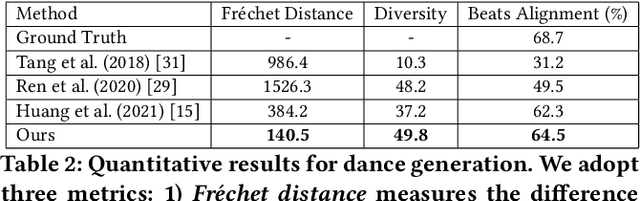
Music-to-Dance Generation with Optimal Transport
Dec 03, 2021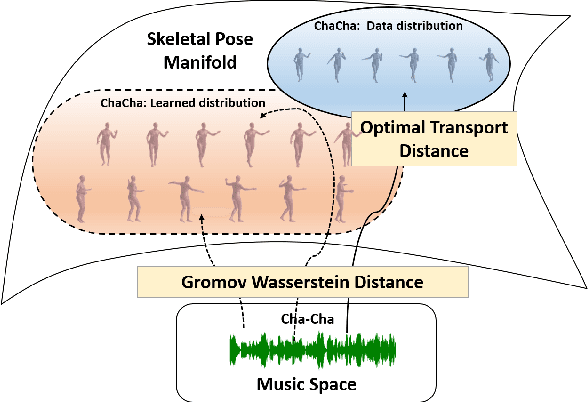
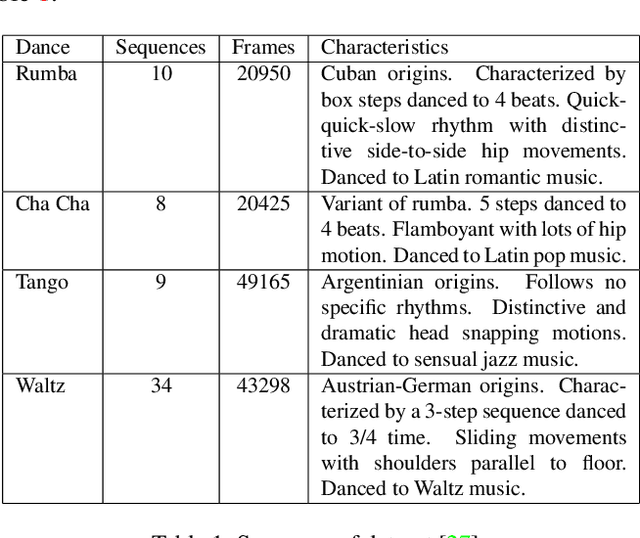
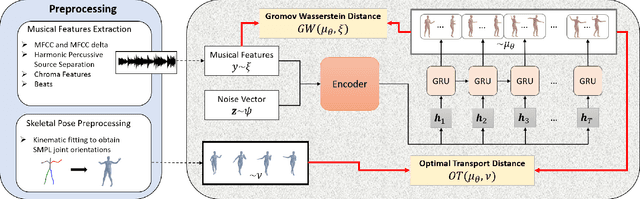
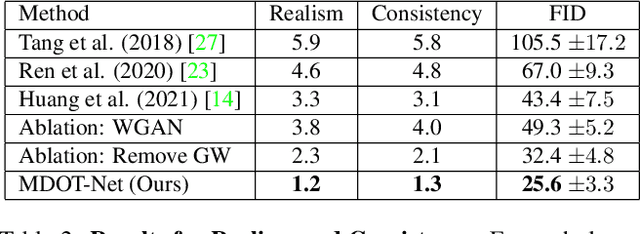
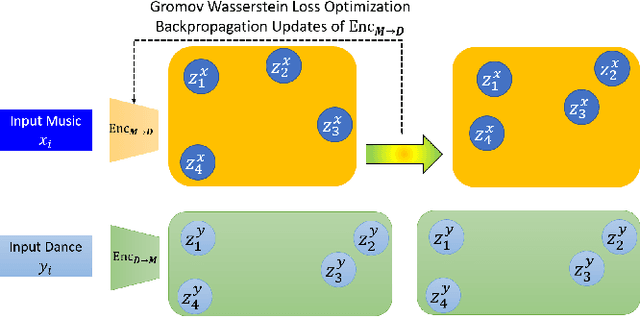
Dance choreography for a piece of music is a challenging task, having to be creative in presenting distinctive stylistic dance elements while taking into account the musical theme and rhythm. It has been tackled by different approaches such as similarity retrieval, sequence-to-sequence modeling and generative adversarial networks, but their generated dance sequences are often short of motion realism, diversity and music consistency. In this paper, we propose a Music-to-Dance with Optimal Transport Network (MDOT-Net) for learning to generate 3D dance choreographs from music. We introduce an optimal transport distance for evaluating the authenticity of the generated dance distribution and a Gromov-Wasserstein distance to measure the correspondence between the dance distribution and the input music. This gives a well defined and non-divergent training objective that mitigates the limitation of standard GAN training which is frequently plagued with instability and divergent generator loss issues. Extensive experiments demonstrate that our MDOT-Net can synthesize realistic and diverse dances which achieve an organic unity with the input music, reflecting the shared intentionality and matching the rhythmic articulation.