 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning swimming via deep reinforcement learning
Sep 22, 2022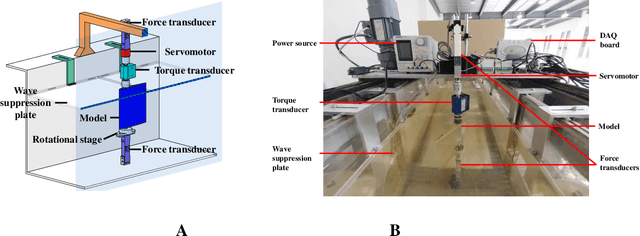
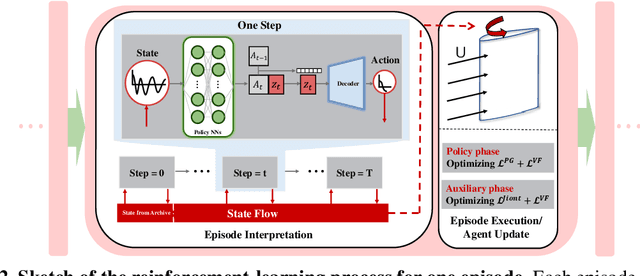
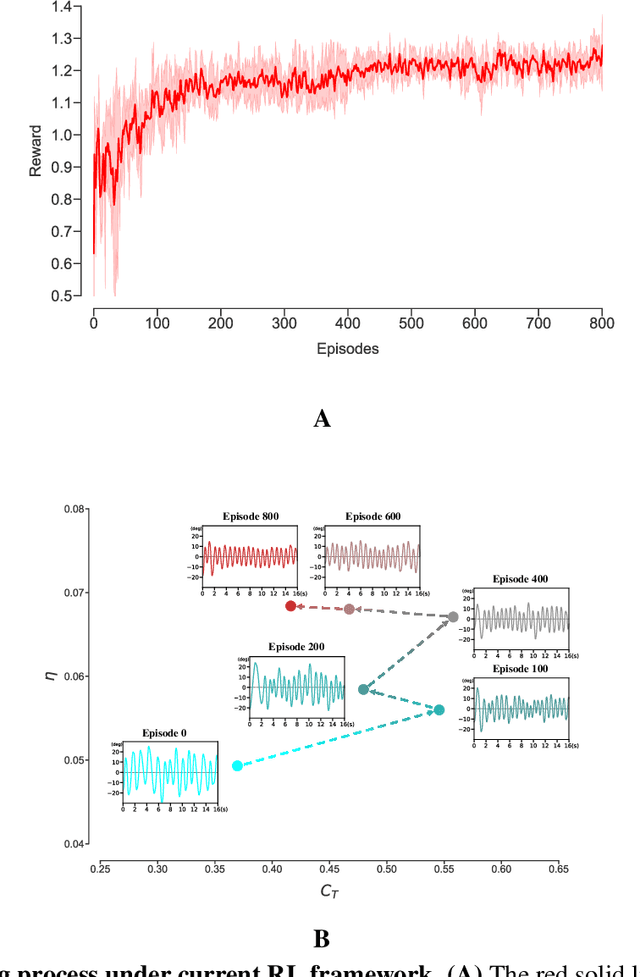
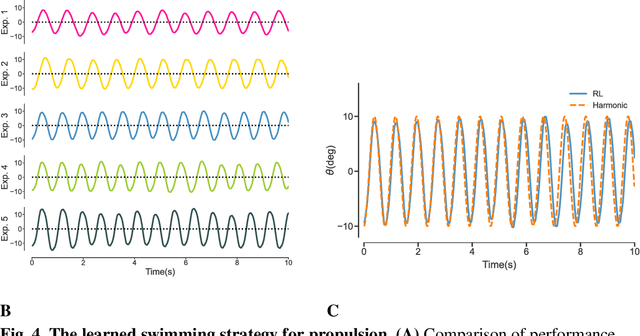
For decades, people have been seeking for fishlike flapping motions that can realize underwater propulsion with low energy cost. Complexity of the nonstationary flow field around the flapping body makes this problem very difficult. In earlier studies, motion patterns are usually prescribed as certain periodic functions which constrains the following optimization process in a small subdomain of the whole motion space. In this work, to avoid this motion constraint, a variational autoencoder (VAE) is designed to compress various flapping motions into a simple action vector. Then we let a flapping airfoil continuously interact with water tunnel environment and adjust its action accordingly through a reinforcement learning (RL) framework. By this automatic close-looped experiment, we obtain several motion patterns that can result in high hydrodynamic efficiency comparing to pure harmonic motions with the same thrust level. And we find that, after numerous trials and errors, RL trainings in current experiment always converge to motion patterns that are close to harmonic motions. In other words, current work proves that harmonic motion with appropriate amplitude and frequency is always an optimal choice for efficient underwater propulsion. Furthermore, the RL framework proposed here can be also extended to the study of other complex swimming problems, which might pave the way for the creation of a robotic fish that can swim like a real fish.
ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
Aug 30, 2022
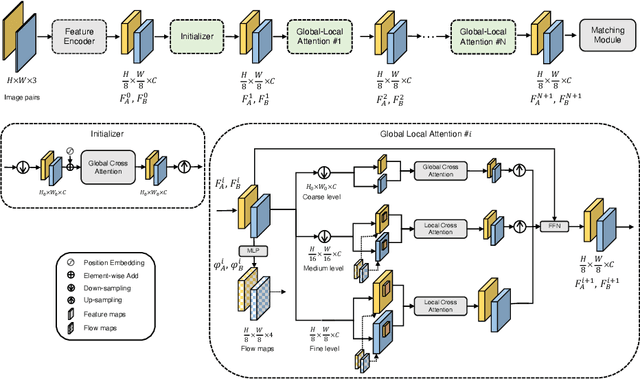
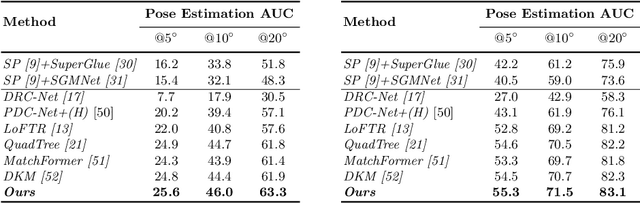

Generating robust and reliable correspondences across images is a fundamental task for a diversity of applications. To capture context at both global and local granularity, we propose ASpanFormer, a Transformer-based detector-free matcher that is built on hierarchical attention structure, adopting a novel attention operation which is capable of adjusting attention span in a self-adaptive manner. To achieve this goal, first, flow maps are regressed in each cross attention phase to locate the center of search region. Next, a sampling grid is generated around the center, whose size, instead of being empirically configured as fixed, is adaptively computed from a pixel uncertainty estimated along with the flow map. Finally, attention is computed across two images within derived regions, referred to as attention span. By these means, we are able to not only maintain long-range dependencies, but also enable fine-grained attention among pixels of high relevance that compensates essential locality and piece-wise smoothness in matching tasks. State-of-the-art accuracy on a wide range of evaluation benchmarks validates the strong matching capability of our method.
Learning Prototype via Placeholder for Zero-shot Recognition
Jul 29, 2022Zero-shot learning (ZSL) aims to recognize unseen classes by exploiting semantic descriptions shared between seen classes and unseen classes. Current methods show that it is effective to learn visual-semantic alignment by projecting semantic embeddings into the visual space as class prototypes. However, such a projection function is only concerned with seen classes. When applied to unseen classes, the prototypes often perform suboptimally due to domain shift. In this paper, we propose to learn prototypes via placeholders, termed LPL, to eliminate the domain shift between seen and unseen classes. Specifically, we combine seen classes to hallucinate new classes which play as placeholders of the unseen classes in the visual and semantic space. Placed between seen classes, the placeholders encourage prototypes of seen classes to be highly dispersed. And more space is spared for the insertion of well-separated unseen ones. Empirically, well-separated prototypes help counteract visual-semantic misalignment caused by domain shift. Furthermore, we exploit a novel semantic-oriented fine-tuning to guarantee the semantic reliability of placeholders. Extensive experiments on five benchmark datasets demonstrate the significant performance gain of LPL over the state-of-the-art methods. Code is available at https://github.com/zaiquanyang/LPL.
Economical Precise Manipulation and Auto Eye-Hand Coordination with Binocular Visual Reinforcement Learning
May 12, 2022
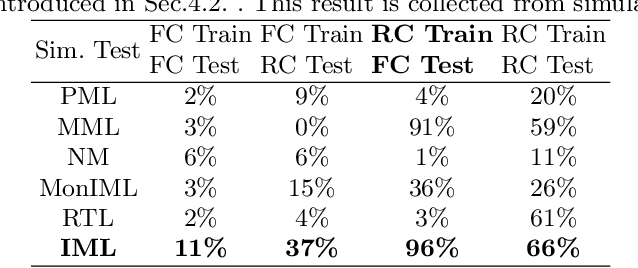
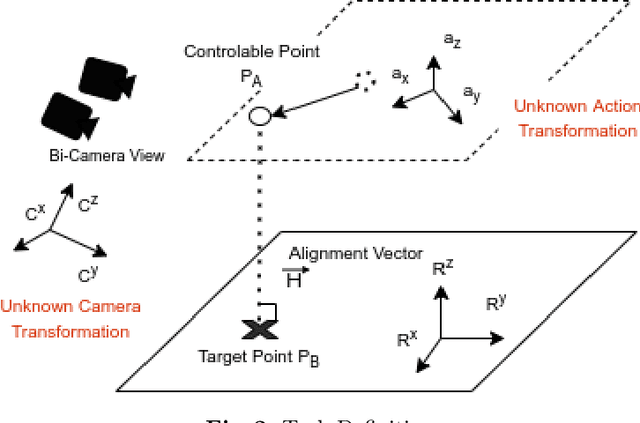

Precision robotic manipulation tasks (insertion, screwing, precisely pick, precisely place) are required in many scenarios. Previous methods achieved good performance on such manipulation tasks. However, such methods typically require tedious calibration or expensive sensors. 3D/RGB-D cameras and torque/force sensors add to the cost of the robotic application and may not always be economical. In this work, we aim to solve these but using only weak-calibrated and low-cost webcams. We propose Binocular Alignment Learning (BAL), which could automatically learn the eye-hand coordination and points alignment capabilities to solve the four tasks. Our work focuses on working with unknown eye-hand coordination and proposes different ways of performing eye-in-hand camera calibration automatically. The algorithm was trained in simulation and used a practical pipeline to achieve sim2real and test it on the real robot. Our method achieves a competitively good result with minimal cost on the four tasks.
PEGG-Net: Background Agnostic Pixel-Wise Efficient Grasp Generation Under Closed-Loop Conditions
Mar 30, 2022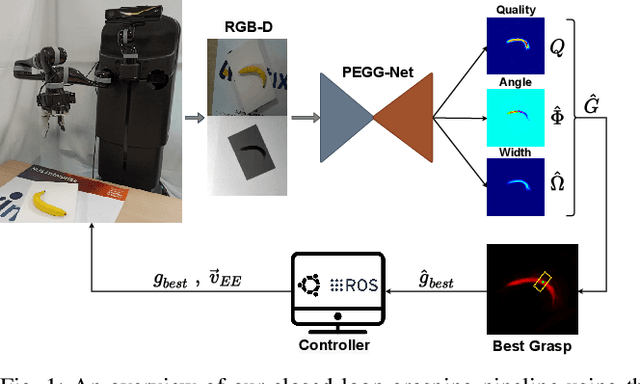
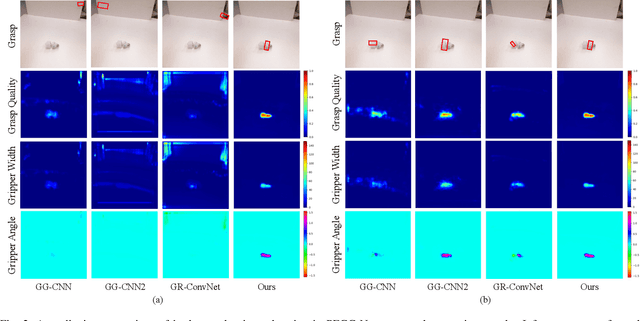
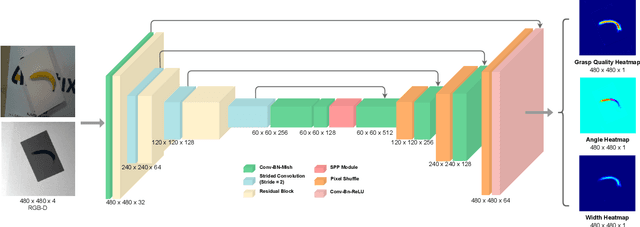

Performing closed-loop grasping at close proximity to an object requires a large field of view. However, such images will inevitably bring large amounts of unnecessary background information, especially when the camera is far away from the target object at the initial stage, resulting in performance degradation of the grasping network. To address this problem, we design a novel PEGG-Net, a real-time, pixel-wise, robotic grasp generation network. The proposed lightweight network is inherently able to learn to remove background noise that can reduce grasping accuracy. Our proposed PEGG-Net achieves improved state-of-the-art performance on both Cornell dataset (98.9%) and Jacquard dataset (93.8%). In the real-world tests, PEGG-Net can support closed-loop grasping at up to 50Hz using an image size of 480x480 in dynamic environments. The trained model also generalizes to previously unseen objects with complex geometrical shapes, household objects and workshop tools and achieved an overall grasp success rate of 91.2% in our real-world grasping experiments.
Self Pre-training with Masked Autoencoders for Medical Image Analysis
Mar 10, 2022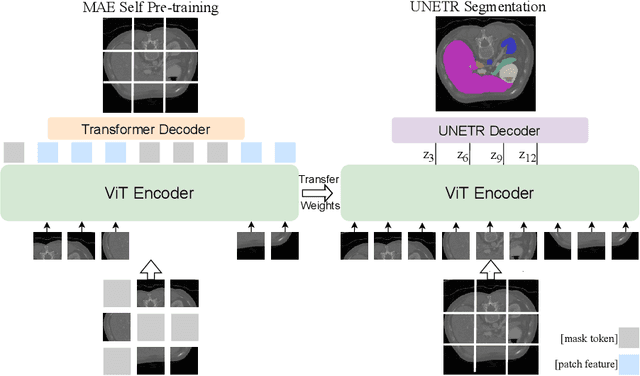
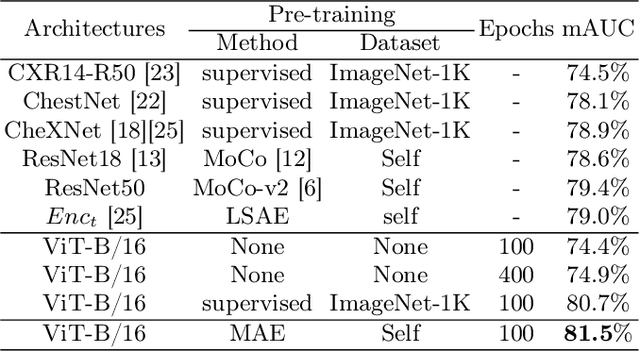
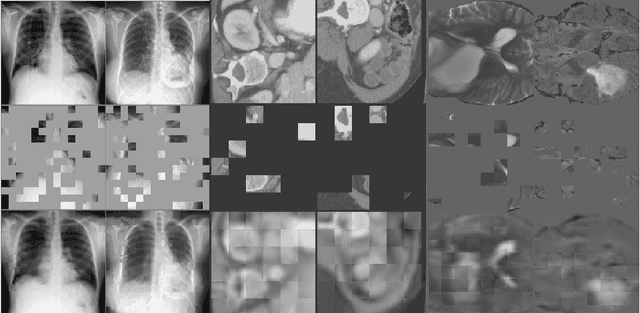
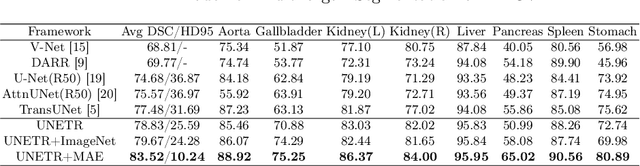
Masked Autoencoder (MAE) has recently been shown to be effective in pre-training Vision Transformers (ViT) for natural image analysis. By performing the pretext task of reconstructing the original image from only partial observations, the encoder, which is a ViT, is encouraged to aggregate contextual information to infer content in masked image regions. We believe that this context aggregation ability is also essential to the medical image domain where each anatomical structure is functionally and mechanically connected to other structures and regions. However, there is no ImageNet-scale medical image dataset for pre-training. Thus, in this paper, we investigate a self pre-training paradigm with MAE for medical images, i.e., models are pre-trained on the same target dataset. To validate the MAE self pre-training, we consider three diverse medical image tasks including chest X-ray disease classification, CT abdomen multi-organ segmentation and MRI brain tumor segmentation. It turns out MAE self pre-training benefits all the tasks markedly. Specifically, the mAUC on lung disease classification is increased by 9.4%. The average DSC on brain tumor segmentation is improved from 77.4% to 78.9%. Most interestingly, on the small-scale multi-organ segmentation dataset (N=30), the average DSC improves from 78.8% to 83.5% and the HD95 is reduced by 60%, indicating its effectiveness in limited data scenarios. The segmentation and classification results reveal the promising potential of MAE self pre-training for medical image analysis.
Lung Swapping Autoencoder: Learning a Disentangled Structure-texture Representation of Chest Radiographs
Jan 18, 2022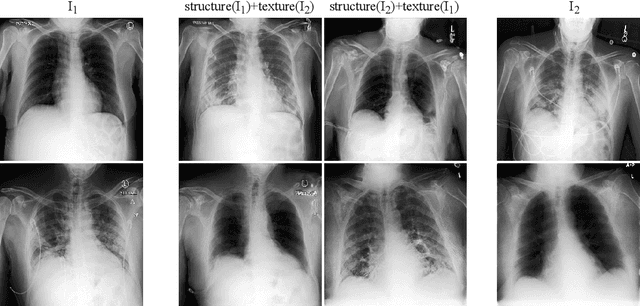

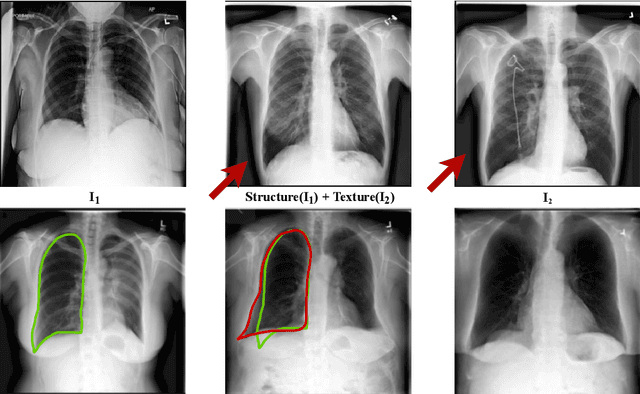
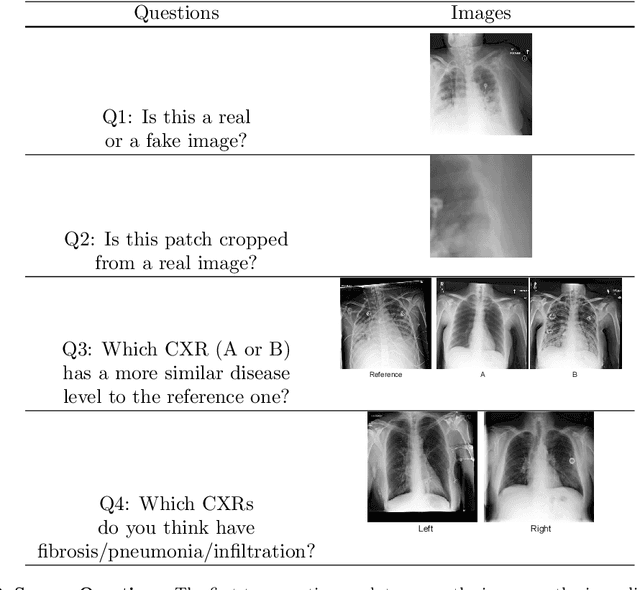
Well-labeled datasets of chest radiographs (CXRs) are difficult to acquire due to the high cost of annotation. Thus, it is desirable to learn a robust and transferable representation in an unsupervised manner to benefit tasks that lack labeled data. Unlike natural images, medical images have their own domain prior; e.g., we observe that many pulmonary diseases, such as the COVID-19, manifest as changes in the lung tissue texture rather than the anatomical structure. Therefore, we hypothesize that studying only the texture without the influence of structure variations would be advantageous for downstream prognostic and predictive modeling tasks. In this paper, we propose a generative framework, the Lung Swapping Autoencoder (LSAE), that learns factorized representations of a CXR to disentangle the texture factor from the structure factor. Specifically, by adversarial training, the LSAE is optimized to generate a hybrid image that preserves the lung shape in one image but inherits the lung texture of another. To demonstrate the effectiveness of the disentangled texture representation, we evaluate the texture encoder $Enc^t$ in LSAE on ChestX-ray14 (N=112,120), and our own multi-institutional COVID-19 outcome prediction dataset, COVOC (N=340 (Subset-1) + 53 (Subset-2)). On both datasets, we reach or surpass the state-of-the-art by finetuning $Enc^t$ in LSAE that is 77% smaller than a baseline Inception v3. Additionally, in semi-and-self supervised settings with a similar model budget, $Enc^t$ in LSAE is also competitive with the state-of-the-art MoCo. By "re-mixing" the texture and shape factors, we generate meaningful hybrid images that can augment the training set. This data augmentation method can further improve COVOC prediction performance. The improvement is consistent even when we directly evaluate the Subset-1 trained model on Subset-2 without any fine-tuning.
Half a Dozen Real-World Applications of Evolutionary Multitasking and More
Sep 29, 2021
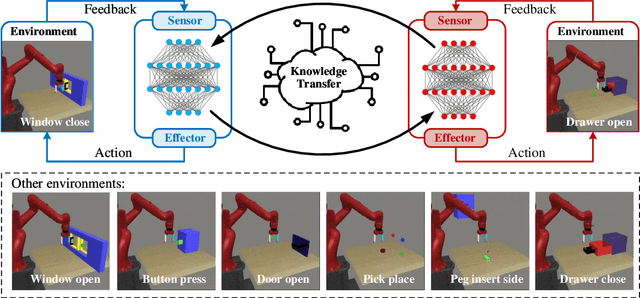
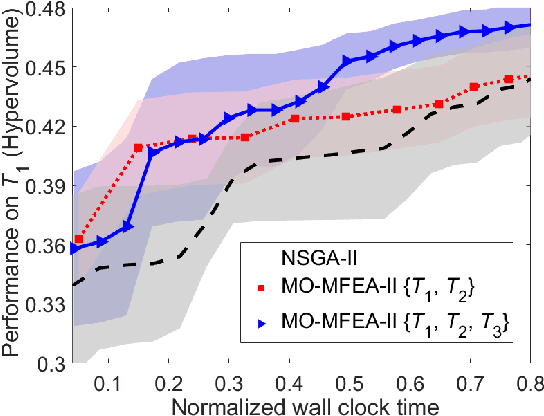
Until recently, the potential to transfer evolved skills across distinct optimization problem instances (or tasks) was seldom explored in evolutionary computation. The concept of evolutionary multitasking (EMT) fills this gap. It unlocks a population's implicit parallelism to jointly solve a set of tasks, hence creating avenues for skills transfer between them. Despite it being early days, the idea of EMT has begun to show promise in a range of real-world applications. In the backdrop of recent advances, the contribution of this paper is twofold. First, we present a review of several application-oriented explorations of EMT in the literature, assimilating them into half a dozen broad categories according to their respective application areas. Each category elaborates fundamental motivations to multitask, and contains a representative experimental study (referred from the literature). Second, we present a set of recipes by which general problem formulations of practical interest, those that cut across different disciplines, could be transformed in the new light of EMT. We intend our discussions to underscore the practical utility of existing EMT methods, and spark future research toward novel algorithms crafted for real-world deployment.
Learning to Match Features with Seeded Graph Matching Network
Aug 19, 2021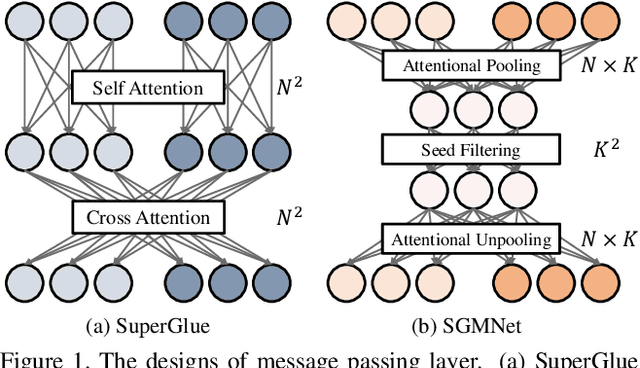
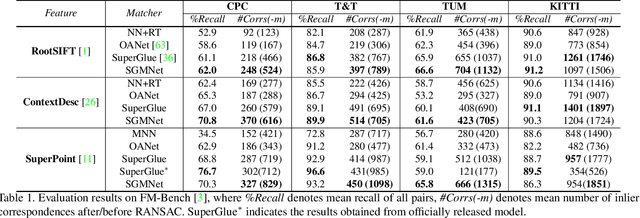
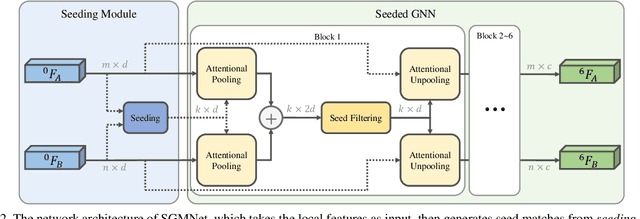
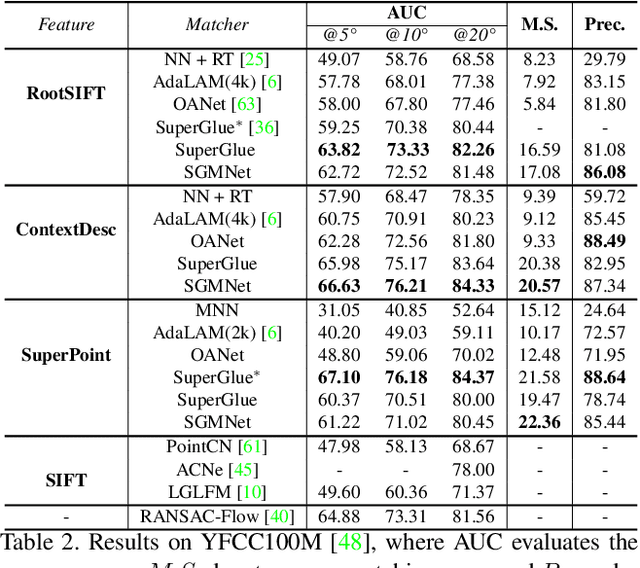
Matching local features across images is a fundamental problem in computer vision. Targeting towards high accuracy and efficiency, we propose Seeded Graph Matching Network, a graph neural network with sparse structure to reduce redundant connectivity and learn compact representation. The network consists of 1) Seeding Module, which initializes the matching by generating a small set of reliable matches as seeds. 2) Seeded Graph Neural Network, which utilizes seed matches to pass messages within/across images and predicts assignment costs. Three novel operations are proposed as basic elements for message passing: 1) Attentional Pooling, which aggregates keypoint features within the image to seed matches. 2) Seed Filtering, which enhances seed features and exchanges messages across images. 3) Attentional Unpooling, which propagates seed features back to original keypoints. Experiments show that our method reduces computational and memory complexity significantly compared with typical attention-based networks while competitive or higher performance is achieved.
Self-Guided Curriculum Learning for Neural Machine Translation
May 15, 2021

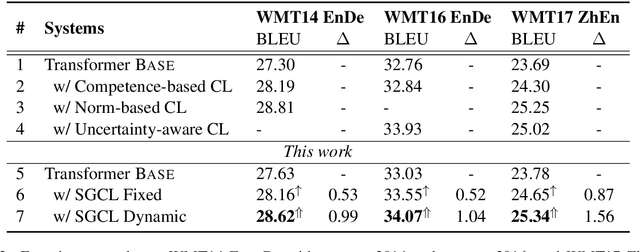
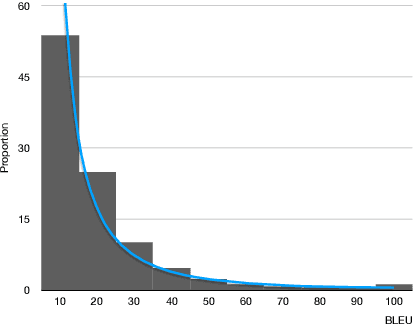
In the field of machine learning, the well-trained model is assumed to be able to recover the training labels, i.e. the synthetic labels predicted by the model should be as close to the ground-truth labels as possible. Inspired by this, we propose a self-guided curriculum strategy to encourage the learning of neural machine translation (NMT) models to follow the above recovery criterion, where we cast the recovery degree of each training example as its learning difficulty. Specifically, we adopt the sentence level BLEU score as the proxy of recovery degree. Different from existing curricula relying on linguistic prior knowledge or third-party language models, our chosen learning difficulty is more suitable to measure the degree of knowledge mastery of the NMT models. Experiments on translation benchmarks, including WMT14 English$\Rightarrow$German and WMT17 Chinese$\Rightarrow$English, demonstrate that our approach can consistently improve translation performance against strong baseline Transformer.