 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking the Limits of In-Context Reinforcement Learning for Ad-Hoc Teamwork
May 23, 2026In-Context Reinforcement Learning (ICRL) has enabled foundation agents to adapt instantaneously to novel tasks, yet its efficacy in Ad-Hoc Teamwork (AHT)-where coordination with unknown partners is required-remains unexplored. To rigorously evaluate this, we introduce a large-scale benchmark ICRL4AHT, built upon a high-throughput JAX implementation of Overcooked-V2. Our benchmark includes a large, diverse teammate suite spanning both RL and heuristic policies, enabling controlled train-test shifts, and provides a reproducible end-to-end pipeline for teammate generation, learning-history collection, dataset construction, and online multi-episode evaluation. We evaluate representative history-conditioned ICRL algorithms, including Algorithm Distillation (AD) and Decision-Pretrained Transformer (DPT), across millions of transitions. Results reveal notable limitations: contrary to their success in single-agent domains, these baselines fail to exhibit robust test-time adaptation in multi-agent settings. Specifically, these methods frequently underperform random baselines across both unseen teammate and unseen layout tracks, with no clear in-context improvement over long horizons. These findings highlight the challenges of strategic inference under partial observability within the OvercookedV2 AHT protocol, establishing our benchmark as a critical testbed for next-generation coordination algorithms.
When Good Equations Get Bad Scores: Improving Symbolic Regression Through Better Parameter Optimization
May 22, 2026Symbolic Regression (SR) plays a central role in scientific knowledge discovery by distilling mathematical equations from observational data. Most existing SR methods function within a bi-level optimization framework: an outer loop that searches for the discrete equation structure, and an inner loop that optimizes the continuous parameters of that structure. Crucially, parameter-fitting quality directly determines a structure's score and thus the outer-loop search. However, nonlinear operators make the inner loop highly non-convex, and budget-driven reliance on fast local solvers (e.g., BFGS) often yields poor local minima and underestimated scores for correct structures. This ``Good Structure, Bad Score'' phenomenon becomes a key bottleneck, degrading efficiency and misguiding the search away from the true equation. To resolve this, we propose SAGE-Fit (Structure-Aware and Semantics-Guided Evaluator for Symbolic Regression), an SR-native fitting framework that exploits the dual native priors of symbolic expressions. By capitalizing on the structural and semantic priors unique to SR, we design tailored modules for each property, thereby effectively mitigating this optimization bottleneck. Extensive experiments demonstrate that our approach, as a plug-and-play module, significantly enhances evaluation fidelity and universally improves the performance of various SR systems.
Focus On Details: Online Multi-object Tracking with Diverse Fine-grained Representation
Mar 08, 2023Discriminative representation is essential to keep a unique identifier for each target in Multiple object tracking (MOT). Some recent MOT methods extract features of the bounding box region or the center point as identity embeddings. However, when targets are occluded, these coarse-grained global representations become unreliable. To this end, we propose exploring diverse fine-grained representation, which describes appearance comprehensively from global and local perspectives. This fine-grained representation requires high feature resolution and precise semantic information. To effectively alleviate the semantic misalignment caused by indiscriminate contextual information aggregation, Flow Alignment FPN (FAFPN) is proposed for multi-scale feature alignment aggregation. It generates semantic flow among feature maps from different resolutions to transform their pixel positions. Furthermore, we present a Multi-head Part Mask Generator (MPMG) to extract fine-grained representation based on the aligned feature maps. Multiple parallel branches of MPMG allow it to focus on different parts of targets to generate local masks without label supervision. The diverse details in target masks facilitate fine-grained representation. Eventually, benefiting from a Shuffle-Group Sampling (SGS) training strategy with positive and negative samples balanced, we achieve state-of-the-art performance on MOT17 and MOT20 test sets. Even on DanceTrack, where the appearance of targets is extremely similar, our method significantly outperforms ByteTrack by 5.0% on HOTA and 5.6% on IDF1. Extensive experiments have proved that diverse fine-grained representation makes Re-ID great again in MOT.
End-to-end Optimized Video Compression with MV-Residual Prediction
May 26, 2020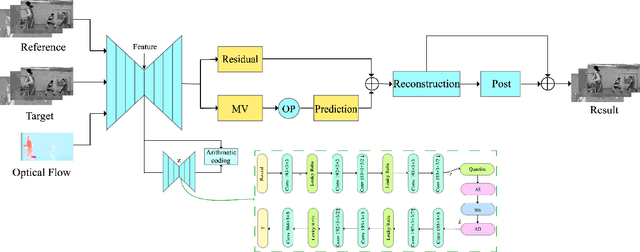

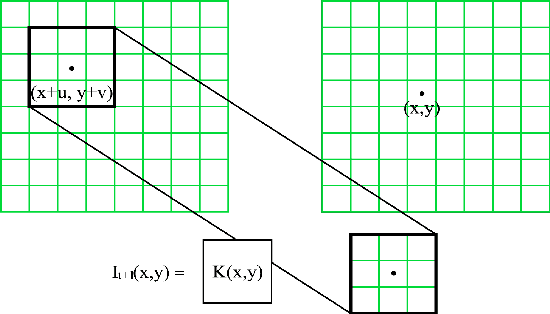
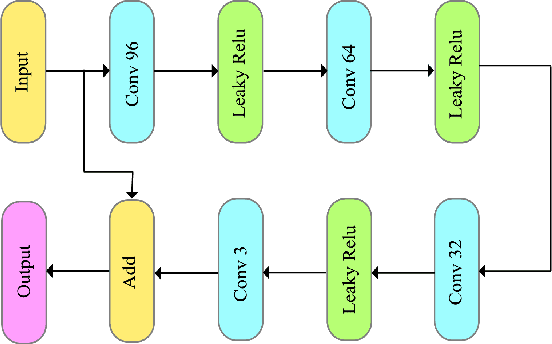
We present an end-to-end trainable framework for P-frame compression in this paper. A joint motion vector (MV) and residual prediction network MV-Residual is designed to extract the ensembled features of motion representations and residual information by treating the two successive frames as inputs. The prior probability of the latent representations is modeled by a hyperprior autoencoder and trained jointly with the MV-Residual network. Specially, the spatially-displaced convolution is applied for video frame prediction, in which a motion kernel for each pixel is learned to generate predicted pixel by applying the kernel at a displaced location in the source image. Finally, novel rate allocation and post-processing strategies are used to produce the final compressed bits, considering the bits constraint of the challenge. The experimental results on validation set show that the proposed optimized framework can generate the highest MS-SSIM for P-frame compression competition.