 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleAR: Customizing Multimodal Autoregressive Model for Style-Aligned Text-to-Image Generation
May 26, 2025
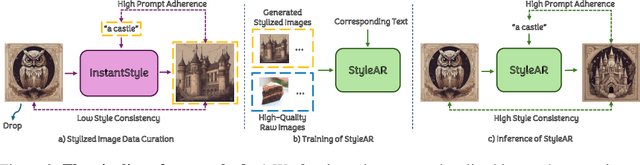

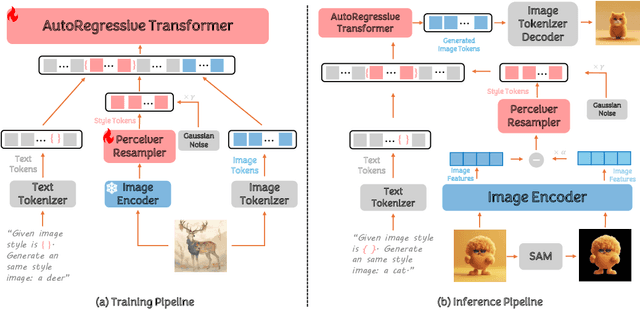
In the current research landscape, multimodal autoregressive (AR) models have shown exceptional capabilities across various domains, including visual understanding and generation. However, complex tasks such as style-aligned text-to-image generation present significant challenges, particularly in data acquisition. In analogy to instruction-following tuning for image editing of AR models, style-aligned generation requires a reference style image and prompt, resulting in a text-image-to-image triplet where the output shares the style and semantics of the input. However, acquiring large volumes of such triplet data with specific styles is considerably more challenging than obtaining conventional text-to-image data used for training generative models. To address this issue, we propose StyleAR, an innovative approach that combines a specially designed data curation method with our proposed AR models to effectively utilize text-to-image binary data for style-aligned text-to-image generation. Our method synthesizes target stylized data using a reference style image and prompt, but only incorporates the target stylized image as the image modality to create high-quality binary data. To facilitate binary data training, we introduce a CLIP image encoder with a perceiver resampler that translates the image input into style tokens aligned with multimodal tokens in AR models and implement a style-enhanced token technique to prevent content leakage which is a common issue in previous work. Furthermore, we mix raw images drawn from large-scale text-image datasets with stylized images to enhance StyleAR's ability to extract richer stylistic features and ensure style consistency. Extensive qualitative and quantitative experiments demonstrate our superior performance.
Artificial Intelligence Bias on English Language Learners in Automatic Scoring
May 15, 2025This study investigated potential scoring biases and disparities toward English Language Learners (ELLs) when using automatic scoring systems for middle school students' written responses to science assessments. We specifically focus on examining how unbalanced training data with ELLs contributes to scoring bias and disparities. We fine-tuned BERT with four datasets: responses from (1) ELLs, (2) non-ELLs, (3) a mixed dataset reflecting the real-world proportion of ELLs and non-ELLs (unbalanced), and (4) a balanced mixed dataset with equal representation of both groups. The study analyzed 21 assessment items: 10 items with about 30,000 ELL responses, five items with about 1,000 ELL responses, and six items with about 200 ELL responses. Scoring accuracy (Acc) was calculated and compared to identify bias using Friedman tests. We measured the Mean Score Gaps (MSGs) between ELLs and non-ELLs and then calculated the differences in MSGs generated through both the human and AI models to identify the scoring disparities. We found that no AI bias and distorted disparities between ELLs and non-ELLs were found when the training dataset was large enough (ELL = 30,000 and ELL = 1,000), but concerns could exist if the sample size is limited (ELL = 200).
FedADP: Unified Model Aggregation for Federated Learning with Heterogeneous Model Architectures
May 10, 2025



Traditional Federated Learning (FL) faces significant challenges in terms of efficiency and accuracy, particularly in heterogeneous environments where clients employ diverse model architectures and have varying computational resources. Such heterogeneity complicates the aggregation process, leading to performance bottlenecks and reduced model generalizability. To address these issues, we propose FedADP, a federated learning framework designed to adapt to client heterogeneity by dynamically adjusting model architectures during aggregation. FedADP enables effective collaboration among clients with differing capabilities, maximizing resource utilization and ensuring model quality. Our experimental results demonstrate that FedADP significantly outperforms existing methods, such as FlexiFed, achieving an accuracy improvement of up to 23.30%, thereby enhancing model adaptability and training efficiency in heterogeneous real-world settings.
3D Gaussian Splatting Data Compression with Mixture of Priors
May 06, 20253D Gaussian Splatting (3DGS) data compression is crucial for enabling efficient storage and transmission in 3D scene modeling. However, its development remains limited due to inadequate entropy models and suboptimal quantization strategies for both lossless and lossy compression scenarios, where existing methods have yet to 1) fully leverage hyperprior information to construct robust conditional entropy models, and 2) apply fine-grained, element-wise quantization strategies for improved compression granularity. In this work, we propose a novel Mixture of Priors (MoP) strategy to simultaneously address these two challenges. Specifically, inspired by the Mixture-of-Experts (MoE) paradigm, our MoP approach processes hyperprior information through multiple lightweight MLPs to generate diverse prior features, which are subsequently integrated into the MoP feature via a gating mechanism. To enhance lossless compression, the resulting MoP feature is utilized as a hyperprior to improve conditional entropy modeling. Meanwhile, for lossy compression, we employ the MoP feature as guidance information in an element-wise quantization procedure, leveraging a prior-guided Coarse-to-Fine Quantization (C2FQ) strategy with a predefined quantization step value. Specifically, we expand the quantization step value into a matrix and adaptively refine it from coarse to fine granularity, guided by the MoP feature, thereby obtaining a quantization step matrix that facilitates element-wise quantization. Extensive experiments demonstrate that our proposed 3DGS data compression framework achieves state-of-the-art performance across multiple benchmarks, including Mip-NeRF360, BungeeNeRF, DeepBlending, and Tank&Temples.
Multi-segment Soft Robot Control via Deep Koopman-based Model Predictive Control
May 01, 2025Soft robots, compared to regular rigid robots, as their multiple segments with soft materials bring flexibility and compliance, have the advantages of safe interaction and dexterous operation in the environment. However, due to its characteristics of high dimensional, nonlinearity, time-varying nature, and infinite degree of freedom, it has been challenges in achieving precise and dynamic control such as trajectory tracking and position reaching. To address these challenges, we propose a framework of Deep Koopman-based Model Predictive Control (DK-MPC) for handling multi-segment soft robots. We first employ a deep learning approach with sampling data to approximate the Koopman operator, which therefore linearizes the high-dimensional nonlinear dynamics of the soft robots into a finite-dimensional linear representation. Secondly, this linearized model is utilized within a model predictive control framework to compute optimal control inputs that minimize the tracking error between the desired and actual state trajectories. The real-world experiments on the soft robot "Chordata" demonstrate that DK-MPC could achieve high-precision control, showing the potential of DK-MPC for future applications to soft robots.
Is Intelligence the Right Direction in New OS Scheduling for Multiple Resources in Cloud Environments?
Apr 21, 2025



Making it intelligent is a promising way in System/OS design. This paper proposes OSML+, a new ML-based resource scheduling mechanism for co-located cloud services. OSML+ intelligently schedules the cache and main memory bandwidth resources at the memory hierarchy and the computing core resources simultaneously. OSML+ uses a multi-model collaborative learning approach during its scheduling and thus can handle complicated cases, e.g., avoiding resource cliffs, sharing resources among applications, enabling different scheduling policies for applications with different priorities, etc. OSML+ can converge faster using ML models than previous studies. Moreover, OSML+ can automatically learn on the fly and handle dynamically changing workloads accordingly. Using transfer learning technologies, we show our design can work well across various cloud servers, including the latest off-the-shelf large-scale servers. Our experimental results show that OSML+ supports higher loads and meets QoS targets with lower overheads than previous studies.
Efficient ANN-Guided Distillation: Aligning Rate-based Features of Spiking Neural Networks through Hybrid Block-wise Replacement
Mar 20, 2025Spiking Neural Networks (SNNs) have garnered considerable attention as a potential alternative to Artificial Neural Networks (ANNs). Recent studies have highlighted SNNs' potential on large-scale datasets. For SNN training, two main approaches exist: direct training and ANN-to-SNN (ANN2SNN) conversion. To fully leverage existing ANN models in guiding SNN learning, either direct ANN-to-SNN conversion or ANN-SNN distillation training can be employed. In this paper, we propose an ANN-SNN distillation framework from the ANN-to-SNN perspective, designed with a block-wise replacement strategy for ANN-guided learning. By generating intermediate hybrid models that progressively align SNN feature spaces to those of ANN through rate-based features, our framework naturally incorporates rate-based backpropagation as a training method. Our approach achieves results comparable to or better than state-of-the-art SNN distillation methods, showing both training and learning efficiency.
DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
Mar 19, 2025Accurate and efficient modeling of agent interactions is essential for trajectory generation, the core of autonomous driving systems. Existing methods, scene-centric, agent-centric, and query-centric frameworks, each present distinct advantages and drawbacks, creating an impossible triangle among accuracy, computational time, and memory efficiency. To break this limitation, we propose Directional Rotary Position Embedding (DRoPE), a novel adaptation of Rotary Position Embedding (RoPE), originally developed in natural language processing. Unlike traditional relative position embedding (RPE), which introduces significant space complexity, RoPE efficiently encodes relative positions without explicitly increasing complexity but faces inherent limitations in handling angular information due to periodicity. DRoPE overcomes this limitation by introducing a uniform identity scalar into RoPE's 2D rotary transformation, aligning rotation angles with realistic agent headings to naturally encode relative angular information. We theoretically analyze DRoPE's correctness and efficiency, demonstrating its capability to simultaneously optimize trajectory generation accuracy, time complexity, and space complexity. Empirical evaluations compared with various state-of-the-art trajectory generation models, confirm DRoPE's good performance and significantly reduced space complexity, indicating both theoretical soundness and practical effectiveness. The video documentation is available at https://drope-traj.github.io/.
Time-EAPCR-T: A Universal Deep Learning Approach for Anomaly Detection in Industrial Equipment
Mar 16, 2025With the advancement of Industry 4.0, intelligent manufacturing extensively employs sensors for real-time multidimensional data collection, playing a crucial role in equipment monitoring, process optimisation, and efficiency enhancement. Industrial data exhibit characteristics such as multi-source heterogeneity, nonlinearity, strong coupling, and temporal interactions, while also being affected by noise interference. These complexities make it challenging for traditional anomaly detection methods to extract key features, impacting detection accuracy and stability. Traditional machine learning approaches often struggle with such complex data due to limitations in processing capacity and generalisation ability, making them inadequate for practical applications. While deep learning feature extraction modules have demonstrated remarkable performance in image and text processing, they remain ineffective when applied to multi-source heterogeneous industrial data lacking explicit correlations. Moreover, existing multi-source heterogeneous data processing techniques still rely on dimensionality reduction and feature selection, which can lead to information loss and difficulty in capturing high-order interactions. To address these challenges, this study applies the EAPCR and Time-EAPCR models proposed in previous research and introduces a new model, Time-EAPCR-T, where Transformer replaces the LSTM module in the time-series processing component of Time-EAPCR. This modification effectively addresses multi-source data heterogeneity, facilitates efficient multi-source feature fusion, and enhances the temporal feature extraction capabilities of multi-source industrial data.Experimental results demonstrate that the proposed method outperforms existing approaches across four industrial datasets, highlighting its broad application potential.
Proxy-Tuning: Tailoring Multimodal Autoregressive Models for Subject-Driven Image Generation
Mar 13, 2025



Multimodal autoregressive (AR) models, based on next-token prediction and transformer architecture, have demonstrated remarkable capabilities in various multimodal tasks including text-to-image (T2I) generation. Despite their strong performance in general T2I tasks, our research reveals that these models initially struggle with subject-driven image generation compared to dominant diffusion models. To address this limitation, we introduce Proxy-Tuning, leveraging diffusion models to enhance AR models' capabilities in subject-specific image generation. Our method reveals a striking weak-to-strong phenomenon: fine-tuned AR models consistently outperform their diffusion model supervisors in both subject fidelity and prompt adherence. We analyze this performance shift and identify scenarios where AR models excel, particularly in multi-subject compositions and contextual understanding. This work not only demonstrates impressive results in subject-driven AR image generation, but also unveils the potential of weak-to-strong generalization in the image generation domain, contributing to a deeper understanding of different architectures' strengths and limitations.