 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAM: Graph-based Attention Model for Healthcare Representation Learning
Apr 01, 2017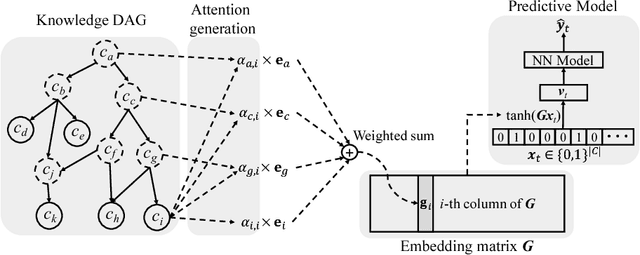
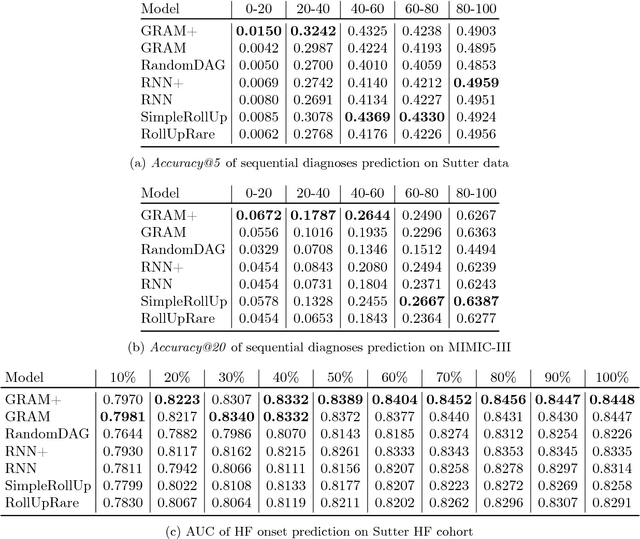

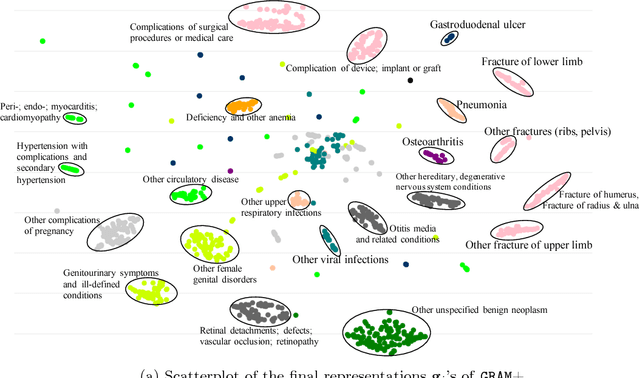
Deep learning methods exhibit promising performance for predictive modeling in healthcare, but two important challenges remain: -Data insufficiency:Often in healthcare predictive modeling, the sample size is insufficient for deep learning methods to achieve satisfactory results. -Interpretation:The representations learned by deep learning methods should align with medical knowledge. To address these challenges, we propose a GRaph-based Attention Model, GRAM that supplements electronic health records (EHR) with hierarchical information inherent to medical ontologies. Based on the data volume and the ontology structure, GRAM represents a medical concept as a combination of its ancestors in the ontology via an attention mechanism. We compared predictive performance (i.e. accuracy, data needs, interpretability) of GRAM to various methods including the recurrent neural network (RNN) in two sequential diagnoses prediction tasks and one heart failure prediction task. Compared to the basic RNN, GRAM achieved 10% higher accuracy for predicting diseases rarely observed in the training data and 3% improved area under the ROC curve for predicting heart failure using an order of magnitude less training data. Additionally, unlike other methods, the medical concept representations learned by GRAM are well aligned with the medical ontology. Finally, GRAM exhibits intuitive attention behaviors by adaptively generalizing to higher level concepts when facing data insufficiency at the lower level concepts.
Joint Modeling of Event Sequence and Time Series with Attentional Twin Recurrent Neural Networks
Mar 24, 2017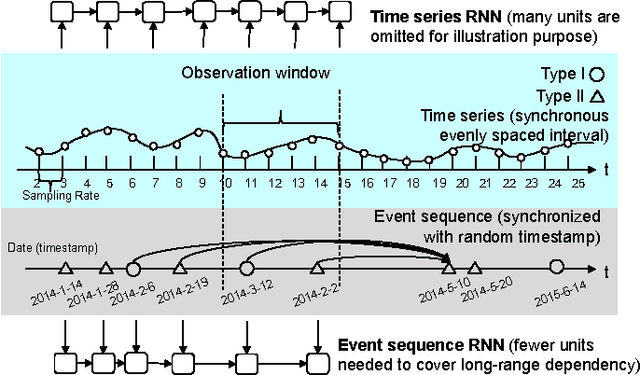
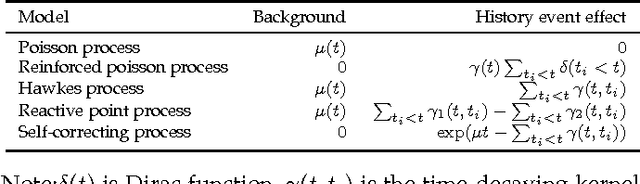
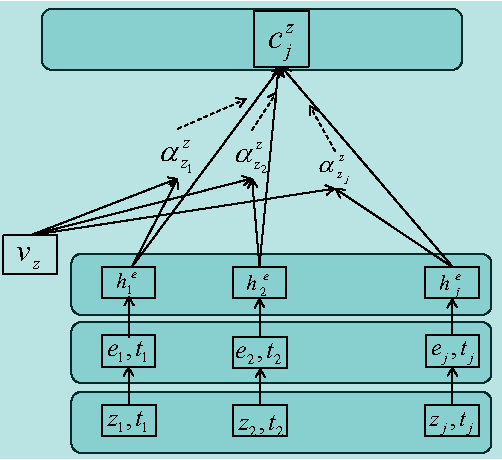
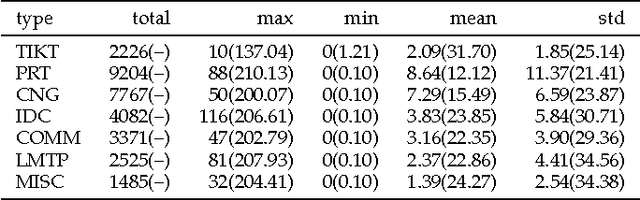
A variety of real-world processes (over networks) produce sequences of data whose complex temporal dynamics need to be studied. More especially, the event timestamps can carry important information about the underlying network dynamics, which otherwise are not available from the time-series evenly sampled from continuous signals. Moreover, in most complex processes, event sequences and evenly-sampled times series data can interact with each other, which renders joint modeling of those two sources of data necessary. To tackle the above problems, in this paper, we utilize the rich framework of (temporal) point processes to model event data and timely update its intensity function by the synergic twin Recurrent Neural Networks (RNNs). In the proposed architecture, the intensity function is synergistically modulated by one RNN with asynchronous events as input and another RNN with time series as input. Furthermore, to enhance the interpretability of the model, the attention mechanism for the neural point process is introduced. The whole model with event type and timestamp prediction output layers can be trained end-to-end and allows a black-box treatment for modeling the intensity. We substantiate the superiority of our model in synthetic data and three real-world benchmark datasets.
Diverse Neural Network Learns True Target Functions
Mar 03, 2017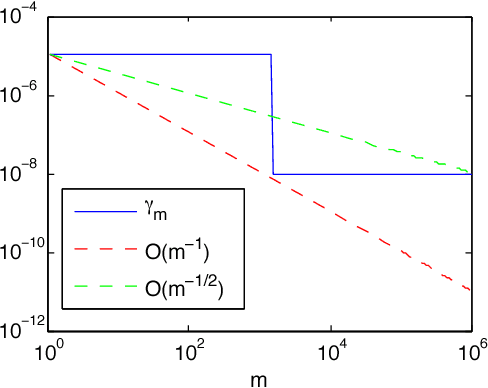

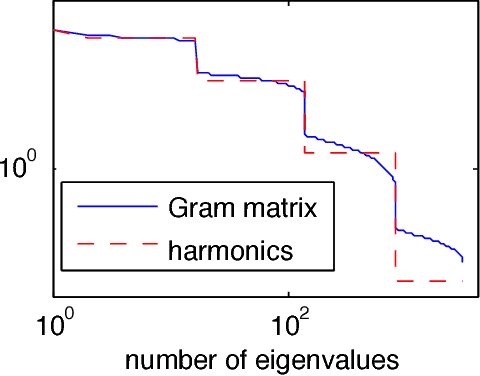
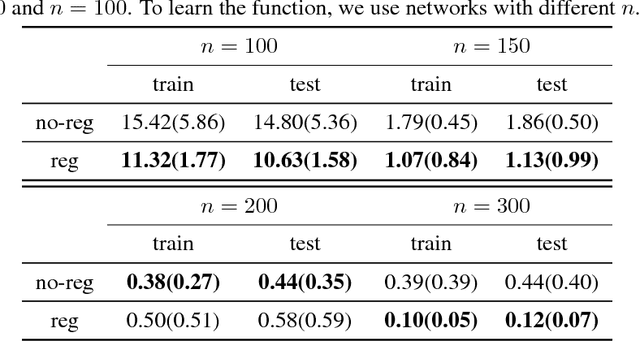
Neural networks are a powerful class of functions that can be trained with simple gradient descent to achieve state-of-the-art performance on a variety of applications. Despite their practical success, there is a paucity of results that provide theoretical guarantees on why they are so effective. Lying in the center of the problem is the difficulty of analyzing the non-convex loss function with potentially numerous local minima and saddle points. Can neural networks corresponding to the stationary points of the loss function learn the true target function? If yes, what are the key factors contributing to such nice optimization properties? In this paper, we answer these questions by analyzing one-hidden-layer neural networks with ReLU activation, and show that despite the non-convexity, neural networks with diverse units have no spurious local minima. We bypass the non-convexity issue by directly analyzing the first order optimality condition, and show that the loss can be made arbitrarily small if the minimum singular value of the "extended feature matrix" is large enough. We make novel use of techniques from kernel methods and geometric discrepancy, and identify a new relation linking the smallest singular value to the spectrum of a kernel function associated with the activation function and to the diversity of the units. Our results also suggest a novel regularization function to promote unit diversity for potentially better generalization.
Deep Coevolutionary Network: Embedding User and Item Features for Recommendation
Feb 28, 2017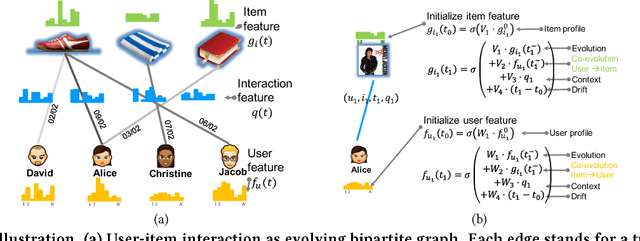

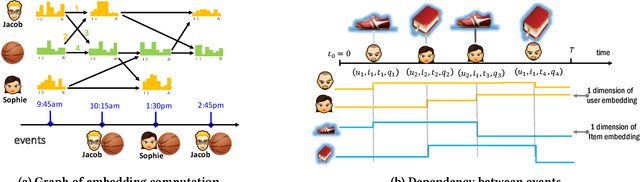
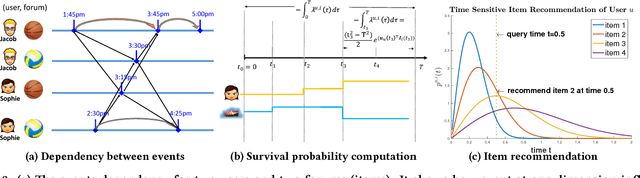
Recommender systems often use latent features to explain the behaviors of users and capture the properties of items. As users interact with different items over time, user and item features can influence each other, evolve and co-evolve over time. The compatibility of user and item's feature further influence the future interaction between users and items. Recently, point process based models have been proposed in the literature aiming to capture the temporally evolving nature of these latent features. However, these models often make strong parametric assumptions about the evolution process of the user and item latent features, which may not reflect the reality, and has limited power in expressing the complex and nonlinear dynamics underlying these processes. To address these limitations, we propose a novel deep coevolutionary network model (DeepCoevolve), for learning user and item features based on their interaction graph. DeepCoevolve use recurrent neural network (RNN) over evolving networks to define the intensity function in point processes, which allows the model to capture complex mutual influence between users and items, and the feature evolution over time. We also develop an efficient procedure for training the model parameters, and show that the learned models lead to significant improvements in recommendation and activity prediction compared to previous state-of-the-arts parametric models.
Scalable Influence Maximization for Multiple Products in Continuous-Time Diffusion Networks
Jan 29, 2017
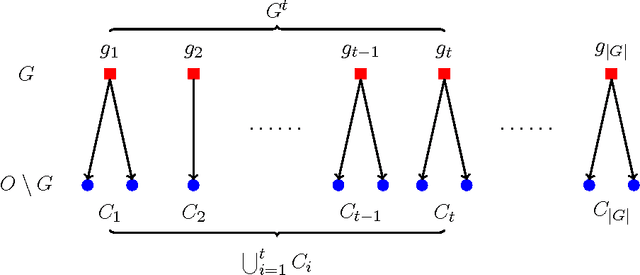
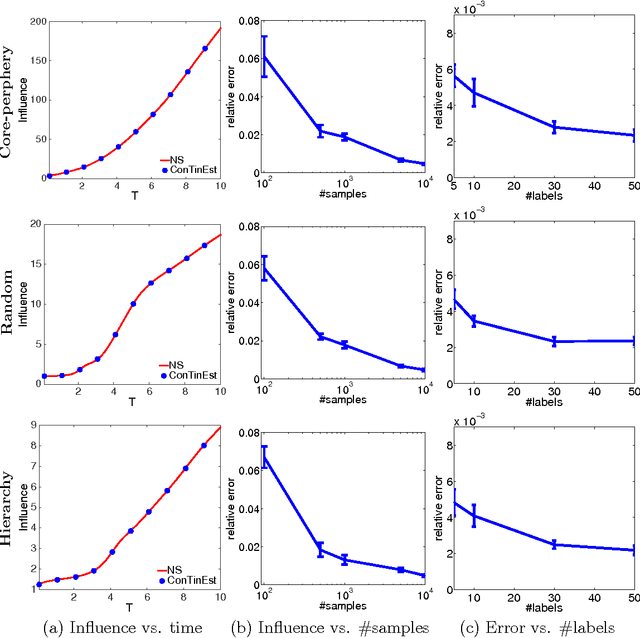
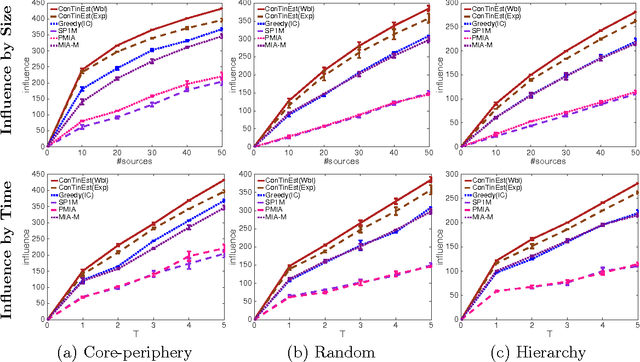
A typical viral marketing model identifies influential users in a social network to maximize a single product adoption assuming unlimited user attention, campaign budgets, and time. In reality, multiple products need campaigns, users have limited attention, convincing users incurs costs, and advertisers have limited budgets and expect the adoptions to be maximized soon. Facing these user, monetary, and timing constraints, we formulate the problem as a submodular maximization task in a continuous-time diffusion model under the intersection of a matroid and multiple knapsack constraints. We propose a randomized algorithm estimating the user influence in a network ($|\mathcal{V}|$ nodes, $|\mathcal{E}|$ edges) to an accuracy of $\epsilon$ with $n=\mathcal{O}(1/\epsilon^2)$ randomizations and $\tilde{\mathcal{O}}(n|\mathcal{E}|+n|\mathcal{V}|)$ computations. By exploiting the influence estimation algorithm as a subroutine, we develop an adaptive threshold greedy algorithm achieving an approximation factor $k_a/(2+2 k)$ of the optimal when $k_a$ out of the $k$ knapsack constraints are active. Extensive experiments on networks of millions of nodes demonstrate that the proposed algorithms achieve the state-of-the-art in terms of effectiveness and scalability.
Learning from Conditional Distributions via Dual Embeddings
Dec 31, 2016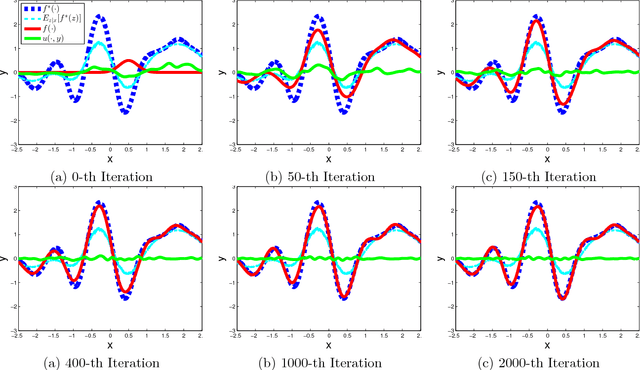
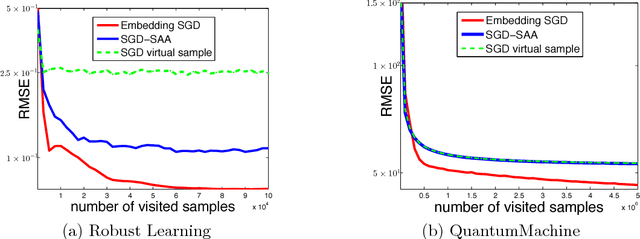
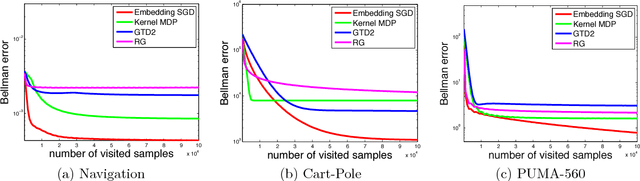
Many machine learning tasks, such as learning with invariance and policy evaluation in reinforcement learning, can be characterized as problems of learning from conditional distributions. In such problems, each sample $x$ itself is associated with a conditional distribution $p(z|x)$ represented by samples $\{z_i\}_{i=1}^M$, and the goal is to learn a function $f$ that links these conditional distributions to target values $y$. These learning problems become very challenging when we only have limited samples or in the extreme case only one sample from each conditional distribution. Commonly used approaches either assume that $z$ is independent of $x$, or require an overwhelmingly large samples from each conditional distribution. To address these challenges, we propose a novel approach which employs a new min-max reformulation of the learning from conditional distribution problem. With such new reformulation, we only need to deal with the joint distribution $p(z,x)$. We also design an efficient learning algorithm, Embedding-SGD, and establish theoretical sample complexity for such problems. Finally, our numerical experiments on both synthetic and real-world datasets show that the proposed approach can significantly improve over the existing algorithms.
Data-Driven Threshold Machine: Scan Statistics, Change-Point Detection, and Extreme Bandits
Oct 14, 2016
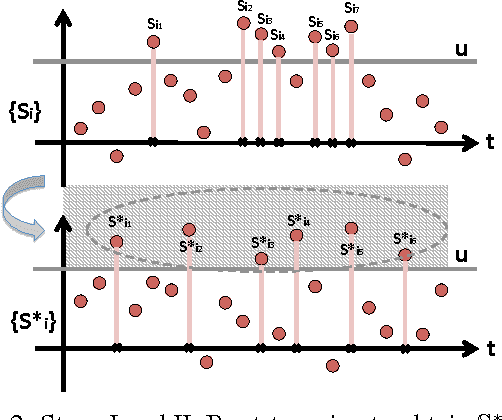
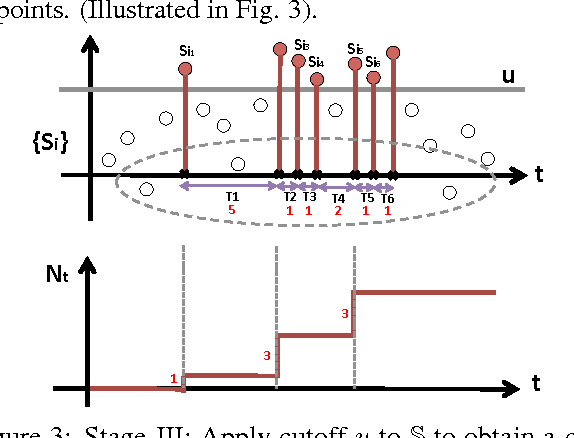
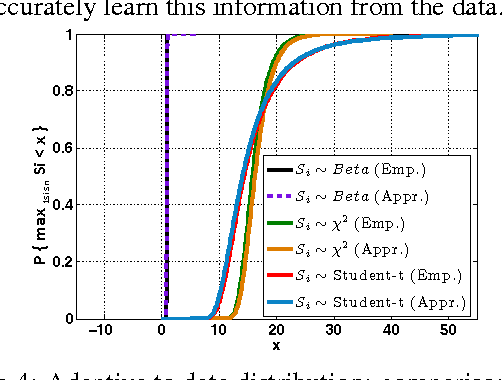
We present a novel distribution-free approach, the data-driven threshold machine (DTM), for a fundamental problem at the core of many learning tasks: choose a threshold for a given pre-specified level that bounds the tail probability of the maximum of a (possibly dependent but stationary) random sequence. We do not assume data distribution, but rather relying on the asymptotic distribution of extremal values, and reduce the problem to estimate three parameters of the extreme value distributions and the extremal index. We specially take care of data dependence via estimating extremal index since in many settings, such as scan statistics, change-point detection, and extreme bandits, where dependence in the sequence of statistics can be significant. Key features of our DTM also include robustness and the computational efficiency, and it only requires one sample path to form a reliable estimate of the threshold, in contrast to the Monte Carlo sampling approach which requires drawing a large number of sample paths. We demonstrate the good performance of DTM via numerical examples in various dependent settings.
Discriminative Embeddings of Latent Variable Models for Structured Data
Sep 26, 2016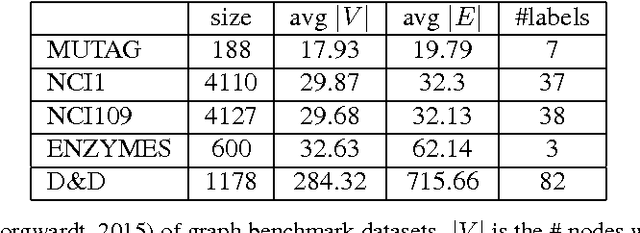
Kernel classifiers and regressors designed for structured data, such as sequences, trees and graphs, have significantly advanced a number of interdisciplinary areas such as computational biology and drug design. Typically, kernels are designed beforehand for a data type which either exploit statistics of the structures or make use of probabilistic generative models, and then a discriminative classifier is learned based on the kernels via convex optimization. However, such an elegant two-stage approach also limited kernel methods from scaling up to millions of data points, and exploiting discriminative information to learn feature representations. We propose, structure2vec, an effective and scalable approach for structured data representation based on the idea of embedding latent variable models into feature spaces, and learning such feature spaces using discriminative information. Interestingly, structure2vec extracts features by performing a sequence of function mappings in a way similar to graphical model inference procedures, such as mean field and belief propagation. In applications involving millions of data points, we showed that structure2vec runs 2 times faster, produces models which are $10,000$ times smaller, while at the same time achieving the state-of-the-art predictive performance.
Detecting weak changes in dynamic events over networks
Sep 16, 2016

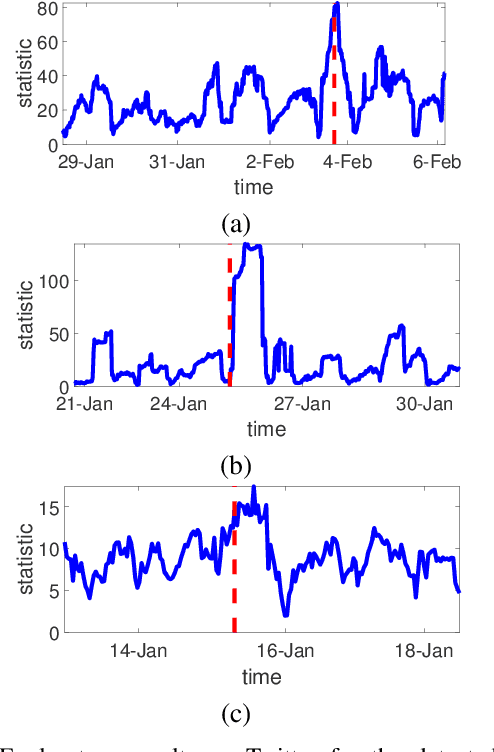
Large volume of networked streaming event data are becoming increasingly available in a wide variety of applications, such as social network analysis, Internet traffic monitoring and healthcare analytics. Streaming event data are discrete observation occurred in continuous time, and the precise time interval between two events carries a great deal of information about the dynamics of the underlying systems. How to promptly detect changes in these dynamic systems using these streaming event data? In this paper, we propose a novel change-point detection framework for multi-dimensional event data over networks. We cast the problem into sequential hypothesis test, and derive the likelihood ratios for point processes, which are computed efficiently via an EM-like algorithm that is parameter-free and can be computed in a distributed fashion. We derive a highly accurate theoretical characterization of the false-alarm-rate, and show that it can achieve weak signal detection by aggregating local statistics over time and networks. Finally, we demonstrate the good performance of our algorithm on numerical examples and real-world datasets from twitter and Memetracker.
Fast and Simple Optimization for Poisson Likelihood Models
Aug 03, 2016
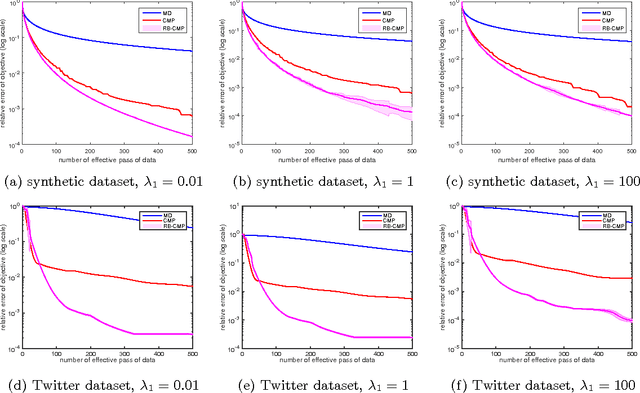
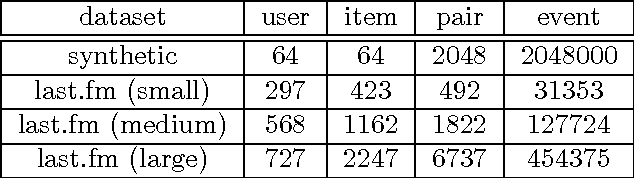
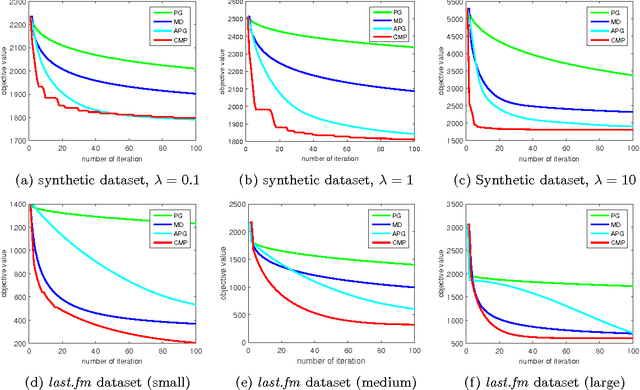
Poisson likelihood models have been prevalently used in imaging, social networks, and time series analysis. We propose fast, simple, theoretically-grounded, and versatile, optimization algorithms for Poisson likelihood modeling. The Poisson log-likelihood is concave but not Lipschitz-continuous. Since almost all gradient-based optimization algorithms rely on Lipschitz-continuity, optimizing Poisson likelihood models with a guarantee of convergence can be challenging, especially for large-scale problems. We present a new perspective allowing to efficiently optimize a wide range of penalized Poisson likelihood objectives. We show that an appropriate saddle point reformulation enjoys a favorable geometry and a smooth structure. Therefore, we can design a new gradient-based optimization algorithm with $O(1/t)$ convergence rate, in contrast to the usual $O(1/\sqrt{t})$ rate of non-smooth minimization alternatives. Furthermore, in order to tackle problems with large samples, we also develop a randomized block-decomposition variant that enjoys the same convergence rate yet more efficient iteration cost. Experimental results on several point process applications including social network estimation and temporal recommendation show that the proposed algorithm and its randomized block variant outperform existing methods both on synthetic and real-world datasets.