 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019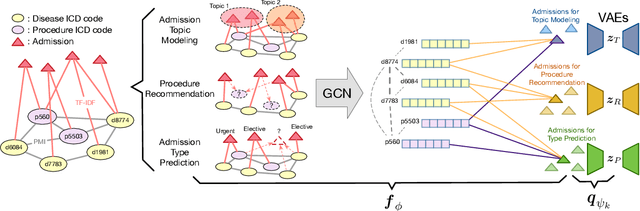


We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.
Syntax-Infused Transformer and BERT models for Machine Translation and Natural Language Understanding
Nov 10, 2019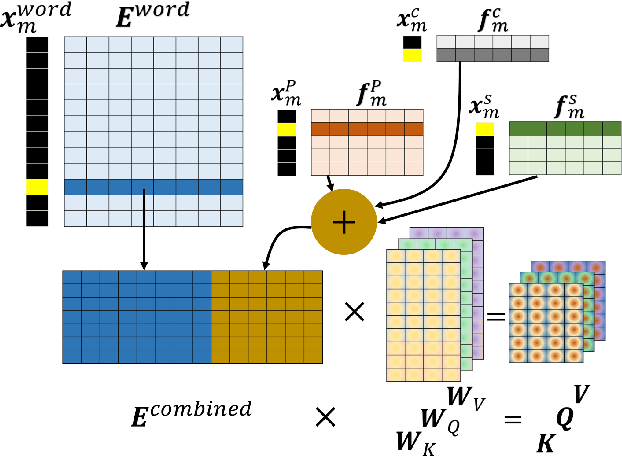
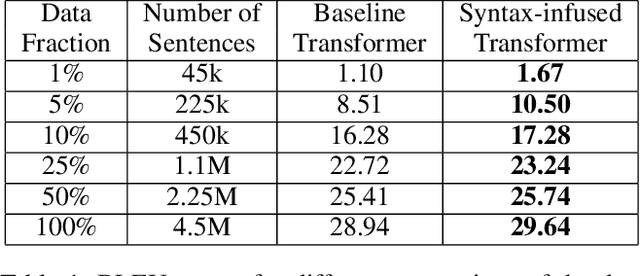
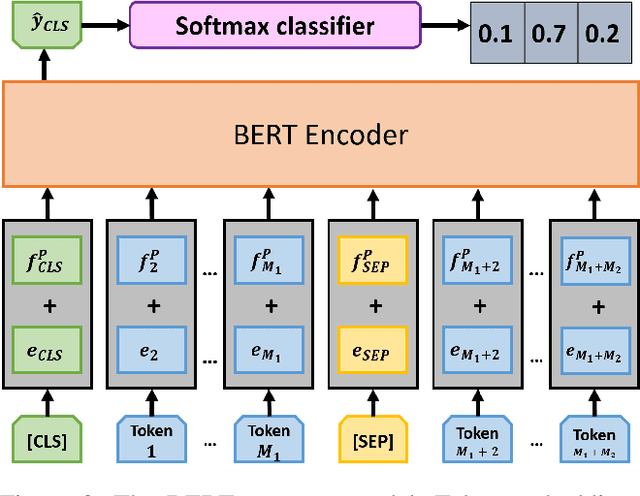

Attention-based models have shown significant improvement over traditional algorithms in several NLP tasks. The Transformer, for instance, is an illustrative example that generates abstract representations of tokens inputted to an encoder based on their relationships to all tokens in a sequence. Recent studies have shown that although such models are capable of learning syntactic features purely by seeing examples, explicitly feeding this information to deep learning models can significantly enhance their performance. Leveraging syntactic information like part of speech (POS) may be particularly beneficial in limited training data settings for complex models such as the Transformer. We show that the syntax-infused Transformer with multiple features achieves an improvement of 0.7 BLEU when trained on the full WMT 14 English to German translation dataset and a maximum improvement of 1.99 BLEU points when trained on a fraction of the dataset. In addition, we find that the incorporation of syntax into BERT fine-tuning outperforms baseline on a number of downstream tasks from the GLUE benchmark.
Collaborative Filtering with A Synthetic Feedback Loop
Oct 21, 2019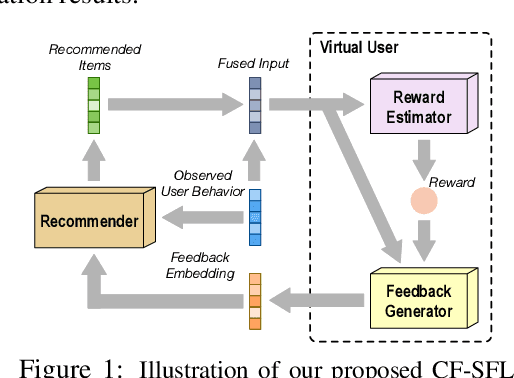
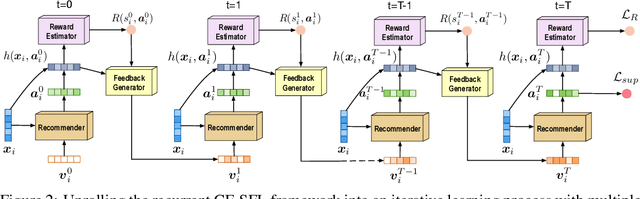

We propose a novel learning framework for recommendation systems, assisting collaborative filtering with a synthetic feedback loop. The proposed framework consists of a "recommender" and a "virtual user." The recommender is formulizd as a collaborative-filtering method, recommending items according to observed user behavior. The virtual user estimates rewards from the recommended items and generates the influence of the rewards on observed user behavior. The recommender connected with the virtual user constructs a closed loop, that recommends users with items and imitates the unobserved feedback of the users to the recommended items. The synthetic feedback is used to augment observed user behavior and improve recommendation results. Such a model can be interpreted as the inverse reinforcement learning, which can be learned effectively via rollout (simulation). Experimental results show that the proposed framework is able to boost the performance of existing collaborative filtering methods on multiple datasets.
An Optimal Transport Framework for Zero-Shot Learning
Oct 20, 2019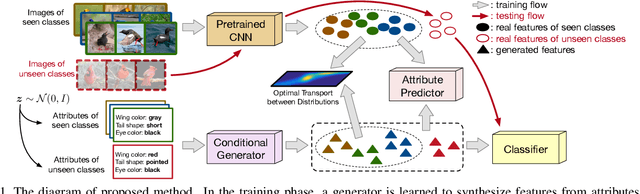
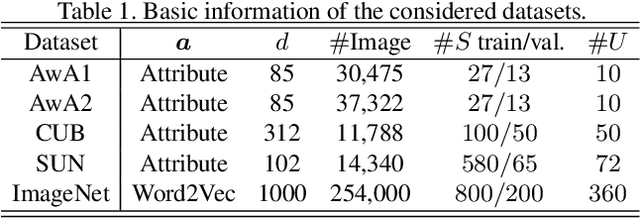
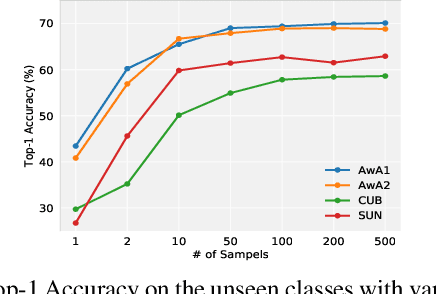
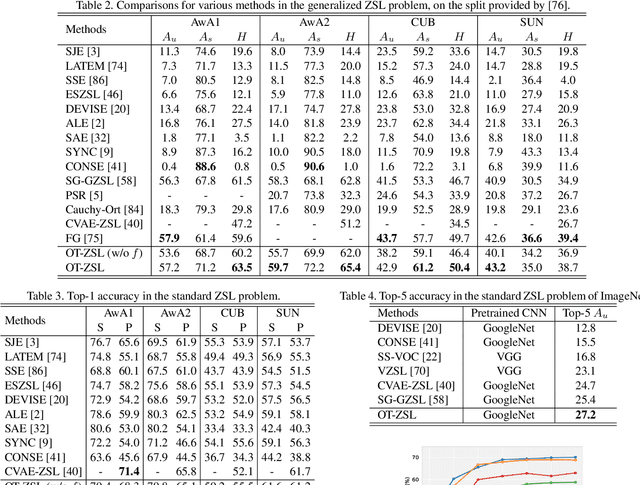
We present an optimal transport (OT) framework for generalized zero-shot learning (GZSL) of imaging data, seeking to distinguish samples for both seen and unseen classes, with the help of auxiliary attributes. The discrepancy between features and attributes is minimized by solving an optimal transport problem. {Specifically, we build a conditional generative model to generate features from seen-class attributes, and establish an optimal transport between the distribution of the generated features and that of the real features.} The generative model and the optimal transport are optimized iteratively with an attribute-based regularizer, that further enhances the discriminative power of the generated features. A classifier is learned based on the features generated for both the seen and unseen classes. In addition to generalized zero-shot learning, our framework is also applicable to standard and transductive ZSL problems. Experiments show that our optimal transport-based method outperforms state-of-the-art methods on several benchmark datasets.
Gaussian-Process-Based Dynamic Embedding for Textual Networks
Oct 10, 2019



Textual network embedding aims to learn low-dimensional representations of text-annotated nodes in a graph. Prior works have typically focused on fixed graph structures. However, real-world networks are often dynamic. We address this challenge with a novel end-to-end node-embedding model, called Dynamic Embedding for Textual Networks with a Gaussian Process (DetGP). Because the structure is allowed to be dynamic, our method uses the Gaussian process to take advantage of its non-parametric properties. After training, DetGP can be applied efficiently to dynamic graphs without re-training or backpropagation. To use both local and global graph structures, diffusion is used to model multiple hops between neighbors. The relative importance of global versus local structure for the embeddings is learned automatically. With the non-parametric nature of the Gaussian process, updating the embeddings for a changed graph structure requires only a forward pass through the learned model. Experiments demonstrate the empirical effectiveness of our method compared to baseline approaches, on link prediction and node classification. We further show that DetGP can be straightforwardly and efficiently applied to dynamic textual networks.
Kernel-Based Approaches for Sequence Modeling: Connections to Neural Methods
Oct 09, 2019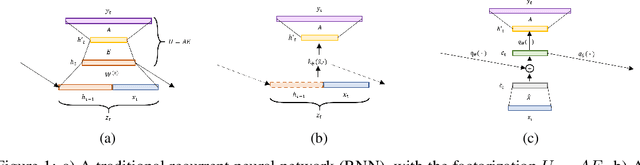

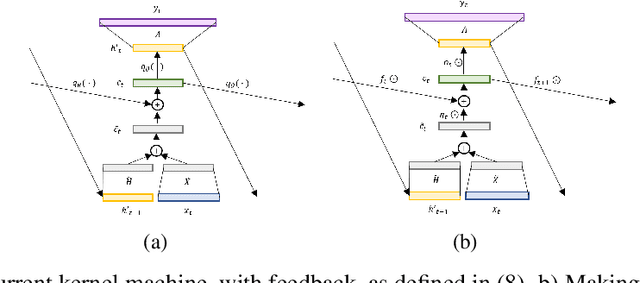
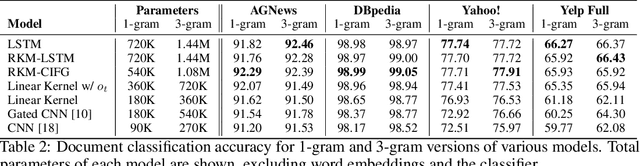
We investigate time-dependent data analysis from the perspective of recurrent kernel machines, from which models with hidden units and gated memory cells arise naturally. By considering dynamic gating of the memory cell, a model closely related to the long short-term memory (LSTM) recurrent neural network is derived. Extending this setup to $n$-gram filters, the convolutional neural network (CNN), Gated CNN, and recurrent additive network (RAN) are also recovered as special cases. Our analysis provides a new perspective on the LSTM, while also extending it to $n$-gram convolutional filters. Experiments are performed on natural language processing tasks and on analysis of local field potentials (neuroscience). We demonstrate that the variants we derive from kernels perform on par or even better than traditional neural methods. For the neuroscience application, the new models demonstrate significant improvements relative to the prior state of the art.
Straight-Through Estimator as Projected Wasserstein Gradient Flow
Oct 05, 2019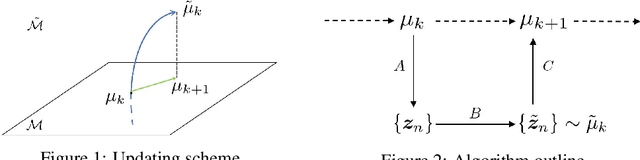
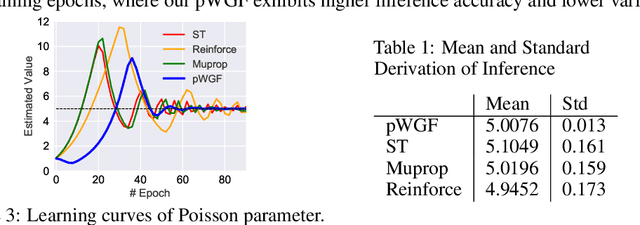
The Straight-Through (ST) estimator is a widely used technique for back-propagating gradients through discrete random variables. However, this effective method lacks theoretical justification. In this paper, we show that ST can be interpreted as the simulation of the projected Wasserstein gradient flow (pWGF). Based on this understanding, a theoretical foundation is established to justify the convergence properties of ST. Further, another pWGF estimator variant is proposed, which exhibits superior performance on distributions with infinite support,e.g., Poisson distributions. Empirically, we show that ST and our proposed estimator, while applied to different types of discrete structures (including both Bernoulli and Poisson latent variables), exhibit comparable or even better performances relative to other state-of-the-art methods. Our results uncover the origin of the widespread adoption of the ST estimator and represent a helpful step towards exploring alternative gradient estimators for discrete variables.
Fused Gromov-Wasserstein Alignment for Hawkes Processes
Oct 04, 2019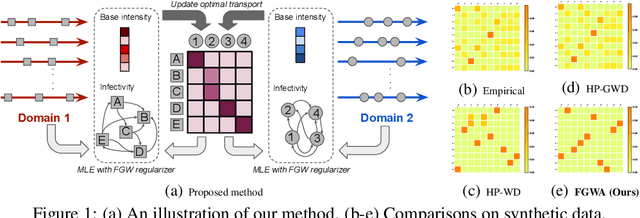
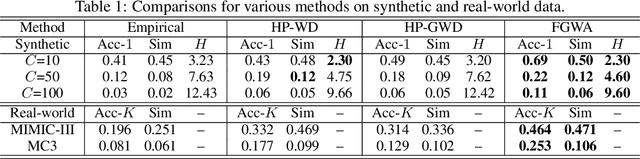
We propose a novel fused Gromov-Wasserstein alignment method to jointly learn the Hawkes processes in different event spaces, and align their event types. Given two Hawkes processes, we use fused Gromov-Wasserstein discrepancy to measure their dissimilarity, which considers both the Wasserstein discrepancy based on their base intensities and the Gromov-Wasserstein discrepancy based on their infectivity matrices. Accordingly, the learned optimal transport reflects the correspondence between the event types of these two Hawkes processes. The Hawkes processes and their optimal transport are learned jointly via maximum likelihood estimation, with a fused Gromov-Wasserstein regularizer. Experimental results show that the proposed method works well on synthetic and real-world data.
Improving Textual Network Learning with Variational Homophilic Embeddings
Sep 30, 2019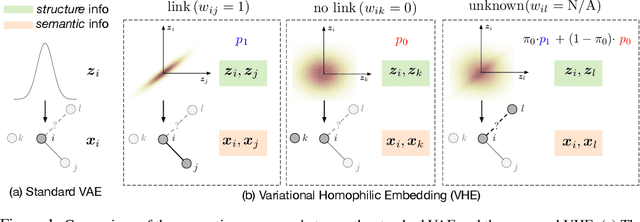
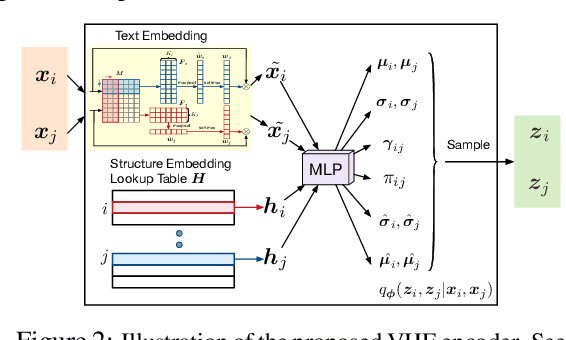
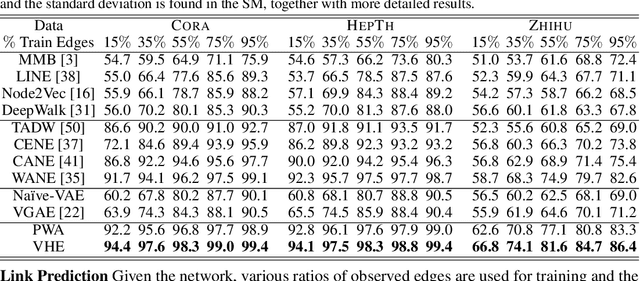
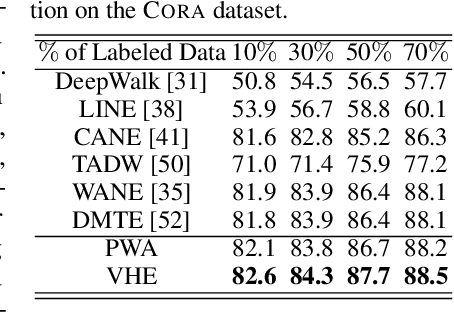
The performance of many network learning applications crucially hinges on the success of network embedding algorithms, which aim to encode rich network information into low-dimensional vertex-based vector representations. This paper considers a novel variational formulation of network embeddings, with special focus on textual networks. Different from most existing methods that optimize a discriminative objective, we introduce Variational Homophilic Embedding (VHE), a fully generative model that learns network embeddings by modeling the semantic (textual) information with a variational autoencoder, while accounting for the structural (topology) information through a novel homophilic prior design. Homophilic vertex embeddings encourage similar embedding vectors for related (connected) vertices. The proposed VHE promises better generalization for downstream tasks, robustness to incomplete observations, and the ability to generalize to unseen vertices. Extensive experiments on real-world networks, for multiple tasks, demonstrate that the proposed method consistently achieves superior performance relative to competing state-of-the-art approaches.
Ouroboros: On Accelerating Training of Transformer-Based Language Models
Sep 14, 2019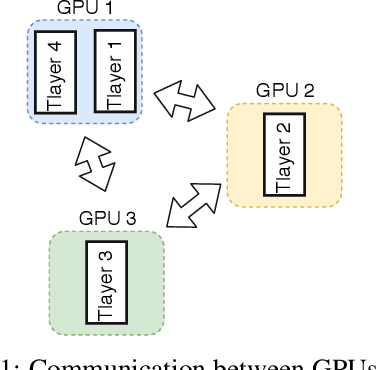

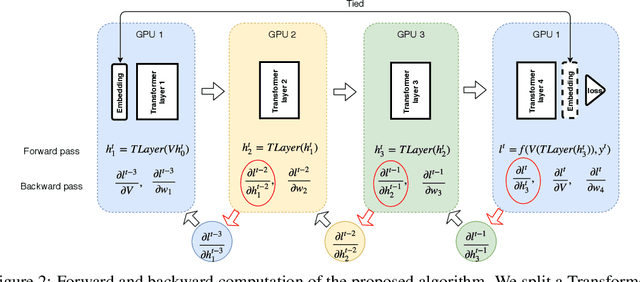
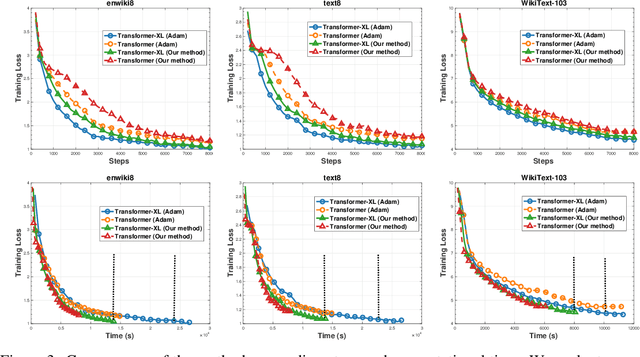
Language models are essential for natural language processing (NLP) tasks, such as machine translation and text summarization. Remarkable performance has been demonstrated recently across many NLP domains via a Transformer-based language model with over a billion parameters, verifying the benefits of model size. Model parallelism is required if a model is too large to fit in a single computing device. Current methods for model parallelism either suffer from backward locking in backpropagation or are not applicable to language models. We propose the first model-parallel algorithm that speeds the training of Transformer-based language models. We also prove that our proposed algorithm is guaranteed to converge to critical points for non-convex problems. Extensive experiments on Transformer and Transformer-XL language models demonstrate that the proposed algorithm obtains a much faster speedup beyond data parallelism, with comparable or better accuracy. Code to reproduce experiments is to be found at \url{https://github.com/LaraQianYang/Ouroboros}.