 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextDescriptives: A Python package for calculating a large variety of statistics from text
Jan 05, 2023TextDescriptives is a Python package for calculating a large variety of statistics from text. It is built on top of spaCy and can be easily integrated into existing workflows. The package has already been used for analysing the linguistic stability of clinical texts, creating features for predicting neuropsychiatric conditions, and analysing linguistic goals of primary school students. This paper describes the package and its features.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Anatomy-guided domain adaptation for 3D in-bed human pose estimation
Nov 22, 20223D human pose estimation is a key component of clinical monitoring systems. The clinical applicability of deep pose estimation models, however, is limited by their poor generalization under domain shifts along with their need for sufficient labeled training data. As a remedy, we present a novel domain adaptation method, adapting a model from a labeled source to a shifted unlabeled target domain. Our method comprises two complementary adaptation strategies based on prior knowledge about human anatomy. First, we guide the learning process in the target domain by constraining predictions to the space of anatomically plausible poses. To this end, we embed the prior knowledge into an anatomical loss function that penalizes asymmetric limb lengths, implausible bone lengths, and implausible joint angles. Second, we propose to filter pseudo labels for self-training according to their anatomical plausibility and incorporate the concept into the Mean Teacher paradigm. We unify both strategies in a point cloud-based framework applicable to unsupervised and source-free domain adaptation. Evaluation is performed for in-bed pose estimation under two adaptation scenarios, using the public SLP dataset and a newly created dataset. Our method consistently outperforms various state-of-the-art domain adaptation methods, surpasses the baseline model by 31%/66%, and reduces the domain gap by 65%/82%. Source code is available at https://github.com/multimodallearning/da-3dhpe-anatomy.
Adapting the Mean Teacher for keypoint-based lung registration under geometric domain shifts
Jul 01, 2022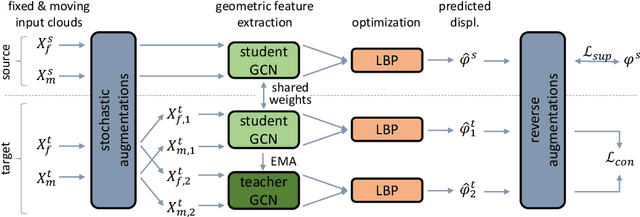
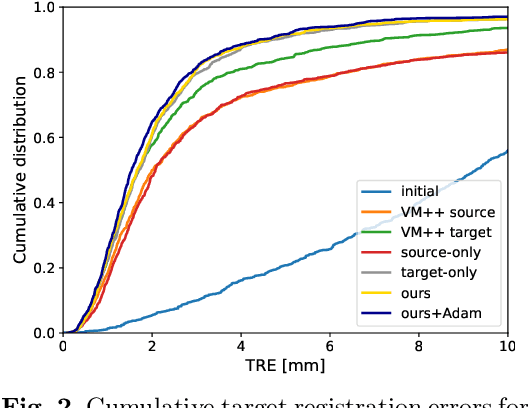
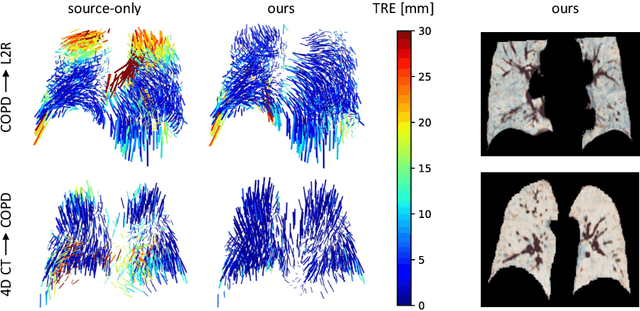
Recent deep learning-based methods for medical image registration achieve results that are competitive with conventional optimization algorithms at reduced run times. However, deep neural networks generally require plenty of labeled training data and are vulnerable to domain shifts between training and test data. While typical intensity shifts can be mitigated by keypoint-based registration, these methods still suffer from geometric domain shifts, for instance, due to different fields of view. As a remedy, in this work, we present a novel approach to geometric domain adaptation for image registration, adapting a model from a labeled source to an unlabeled target domain. We build on a keypoint-based registration model, combining graph convolutions for geometric feature learning with loopy belief optimization, and propose to reduce the domain shift through self-ensembling. To this end, we embed the model into the Mean Teacher paradigm. We extend the Mean Teacher to this context by 1) adapting the stochastic augmentation scheme and 2) combining learned feature extraction with differentiable optimization. This enables us to guide the learning process in the unlabeled target domain by enforcing consistent predictions of the learning student and the temporally averaged teacher model. We evaluate the method for exhale-to-inhale lung CT registration under two challenging adaptation scenarios (DIR-Lab 4D CT to COPD, COPD to Learn2Reg). Our method consistently improves on the baseline model by 50%/47% while even matching the accuracy of models trained on target data. Source code is available at https://github.com/multimodallearning/registration-da-mean-teacher.
Voxelmorph++ Going beyond the cranial vault with keypoint supervision and multi-channel instance optimisation
Feb 28, 2022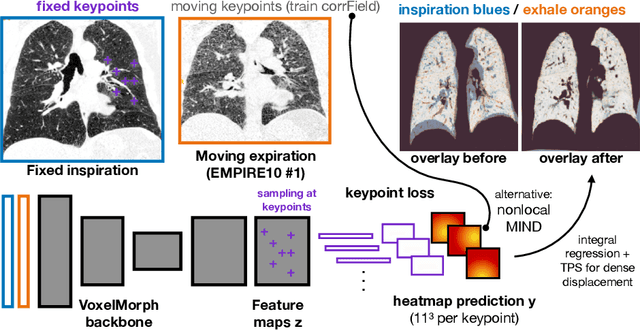
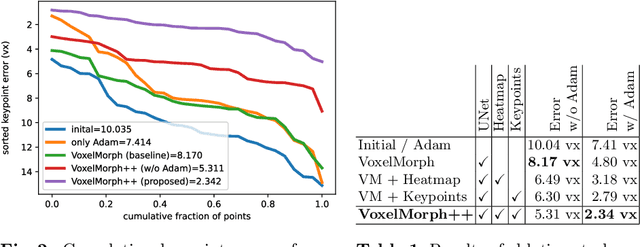
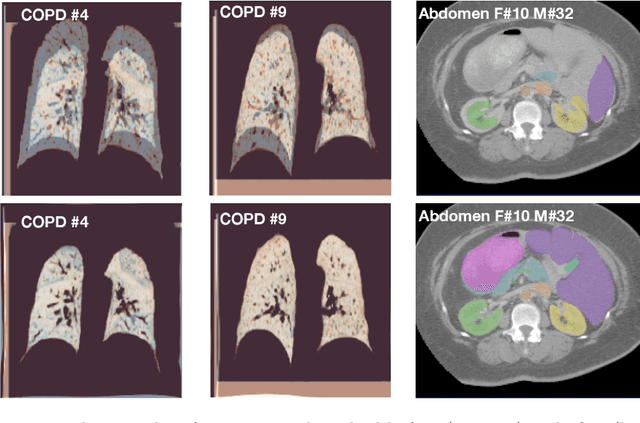
The majority of current research in deep learning based image registration addresses inter-patient brain registration with moderate deformation magnitudes. The recent Learn2Reg medical registration benchmark has demonstrated that single-scale U-Net architectures, such as VoxelMorph that directly employ a spatial transformer loss, often do not generalise well beyond the cranial vault and fall short of state-of-the-art performance for abdominal or intra-patient lung registration. Here, we propose two straightforward steps that greatly reduce this gap in accuracy. First, we employ keypoint self-supervision with a novel network head that predicts a discretised heatmap and robustly reduces large deformations for better robustness. Second, we replace multiple learned fine-tuning steps by a single instance optimisation with hand-crafted features and the Adam optimiser. Different to other related work, including FlowNet or PDD-Net, our approach does not require a fully discretised architecture with correlation layer. Our ablation study demonstrates the importance of keypoints in both self-supervised and unsupervised (using only a MIND metric) settings. On a multi-centric inspiration-exhale lung CT dataset, including very challenging COPD scans, our method outperforms VoxelMorph by improving nonlinear alignment by 77% compared to 19% - reaching target registration errors of 2 mm that outperform all but one learning methods published to date. Extending the method to semantic features sets new stat-of-the-art performance on inter-subject abdominal CT registration.
CrossMoDA 2021 challenge: Benchmark of Cross-Modality Domain Adaptation techniques for Vestibular Schwnannoma and Cochlea Segmentation
Jan 08, 2022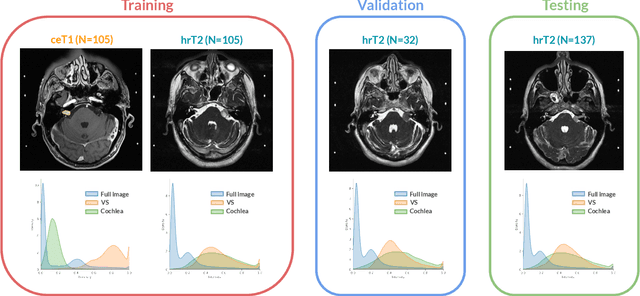
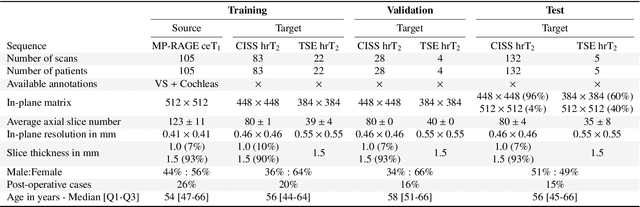
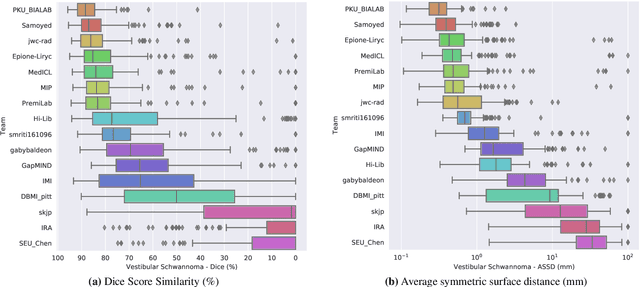
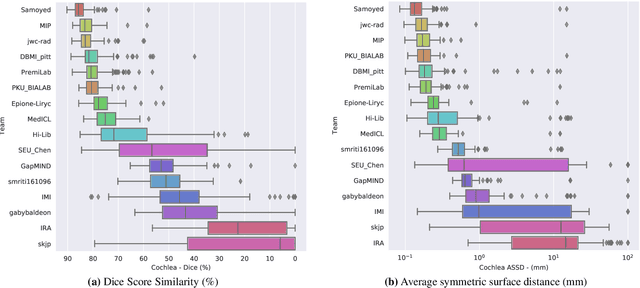
Domain Adaptation (DA) has recently raised strong interests in the medical imaging community. While a large variety of DA techniques has been proposed for image segmentation, most of these techniques have been validated either on private datasets or on small publicly available datasets. Moreover, these datasets mostly addressed single-class problems. To tackle these limitations, the Cross-Modality Domain Adaptation (crossMoDA) challenge was organised in conjunction with the 24th International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI 2021). CrossMoDA is the first large and multi-class benchmark for unsupervised cross-modality DA. The challenge's goal is to segment two key brain structures involved in the follow-up and treatment planning of vestibular schwannoma (VS): the VS and the cochleas. Currently, the diagnosis and surveillance in patients with VS are performed using contrast-enhanced T1 (ceT1) MRI. However, there is growing interest in using non-contrast sequences such as high-resolution T2 (hrT2) MRI. Therefore, we created an unsupervised cross-modality segmentation benchmark. The training set provides annotated ceT1 (N=105) and unpaired non-annotated hrT2 (N=105). The aim was to automatically perform unilateral VS and bilateral cochlea segmentation on hrT2 as provided in the testing set (N=137). A total of 16 teams submitted their algorithm for the evaluation phase. The level of performance reached by the top-performing teams is strikingly high (best median Dice - VS:88.4%; Cochleas:85.7%) and close to full supervision (median Dice - VS:92.5%; Cochleas:87.7%). All top-performing methods made use of an image-to-image translation approach to transform the source-domain images into pseudo-target-domain images. A segmentation network was then trained using these generated images and the manual annotations provided for the source image.
Learn2Reg: comprehensive multi-task medical image registration challenge, dataset and evaluation in the era of deep learning
Dec 23, 2021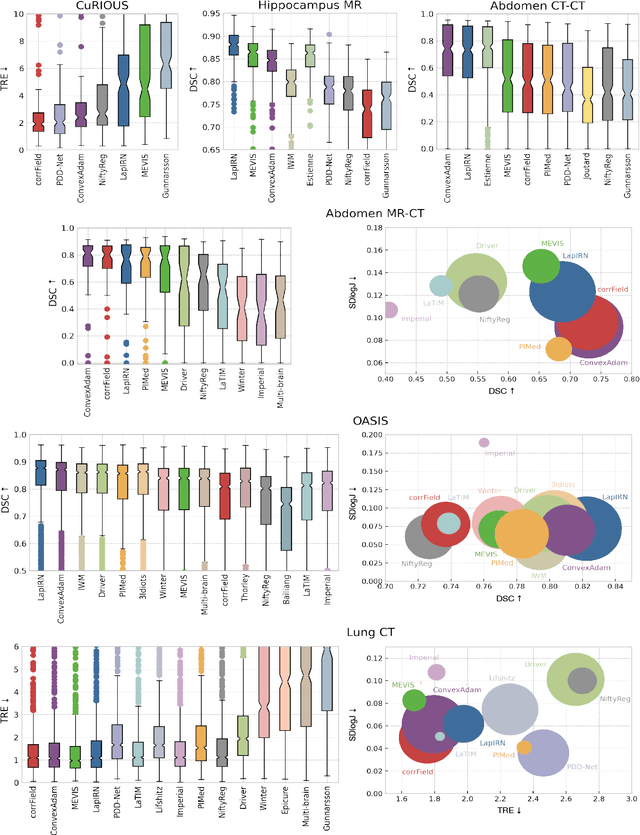
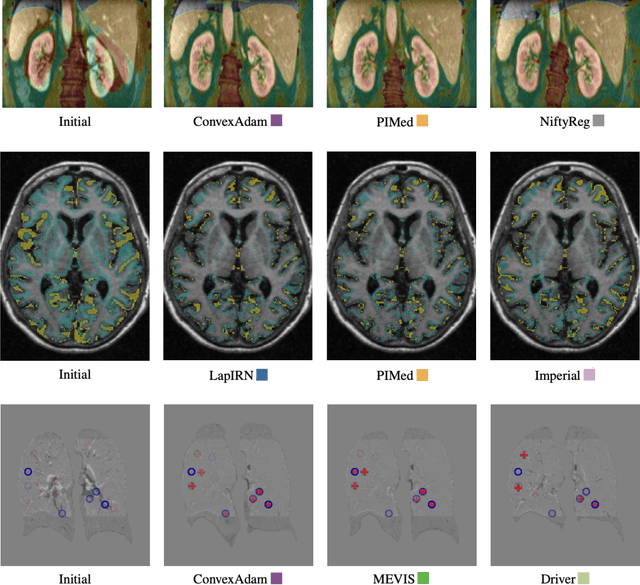
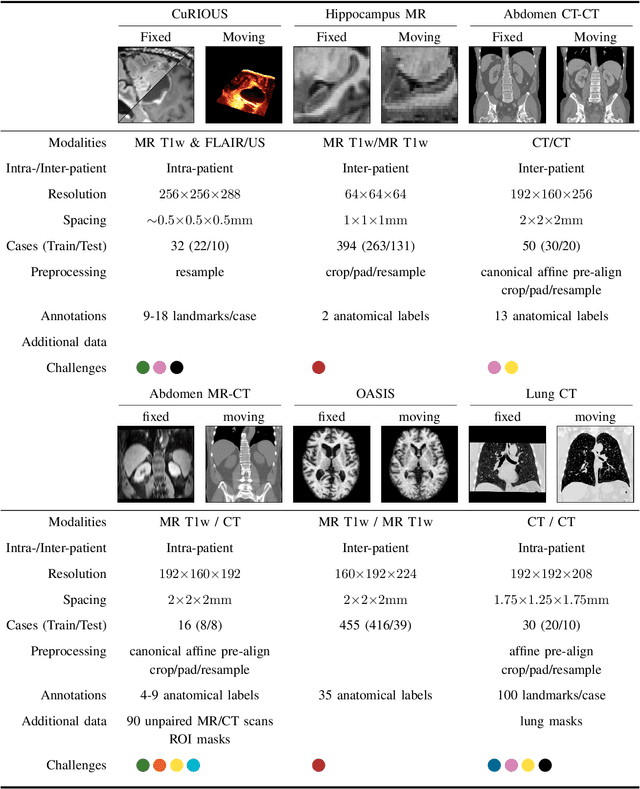
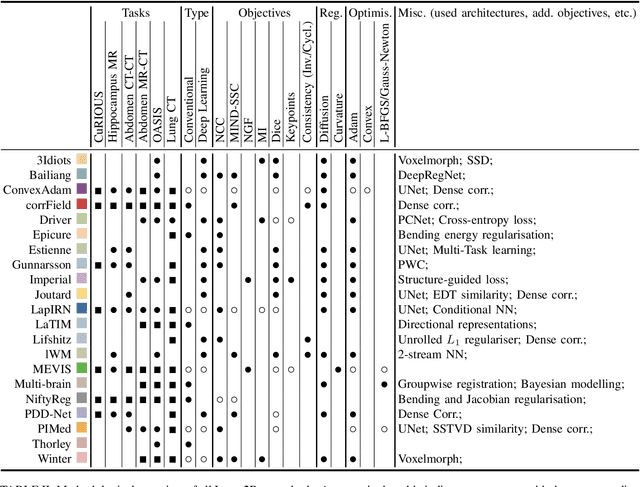
Image registration is a fundamental medical image analysis task, and a wide variety of approaches have been proposed. However, only a few studies have comprehensively compared medical image registration approaches on a wide range of clinically relevant tasks, in part because of the lack of availability of such diverse data. This limits the development of registration methods, the adoption of research advances into practice, and a fair benchmark across competing approaches. The Learn2Reg challenge addresses these limitations by providing a multi-task medical image registration benchmark for comprehensive characterisation of deformable registration algorithms. A continuous evaluation will be possible at https://learn2reg.grand-challenge.org. Learn2Reg covers a wide range of anatomies (brain, abdomen, and thorax), modalities (ultrasound, CT, MR), availability of annotations, as well as intra- and inter-patient registration evaluation. We established an easily accessible framework for training and validation of 3D registration methods, which enabled the compilation of results of over 65 individual method submissions from more than 20 unique teams. We used a complementary set of metrics, including robustness, accuracy, plausibility, and runtime, enabling unique insight into the current state-of-the-art of medical image registration. This paper describes datasets, tasks, evaluation methods and results of the challenge, and the results of further analysis of transferability to new datasets, the importance of label supervision, and resulting bias.
Fast 3D registration with accurate optimisation and little learning for Learn2Reg 2021
Dec 06, 2021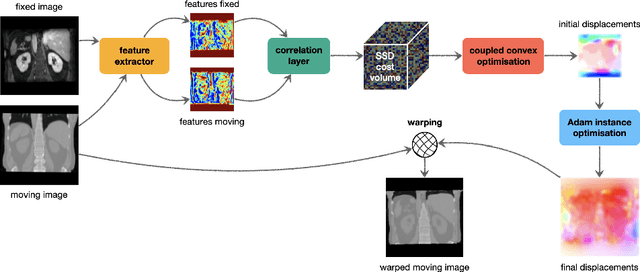
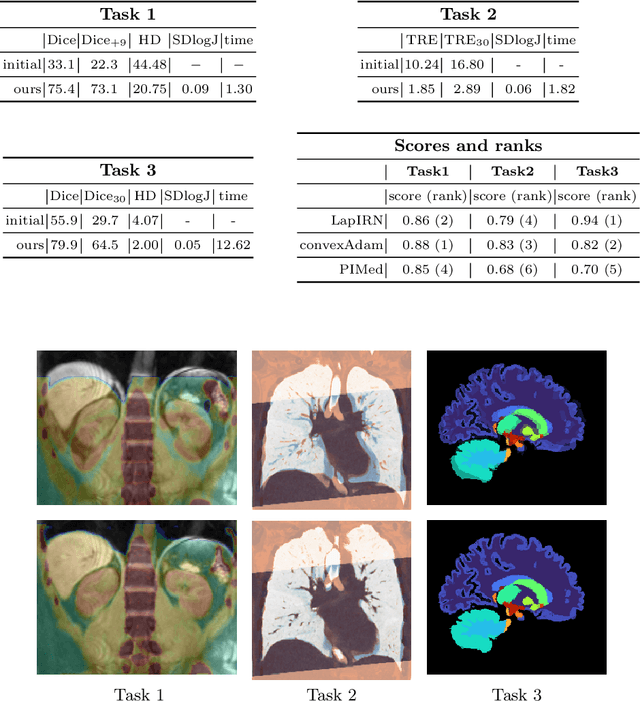
Current approaches for deformable medical image registration often struggle to fulfill all of the following criteria: versatile applicability, small computation or training times, and the being able to estimate large deformations. Furthermore, end-to-end networks for supervised training of registration often become overly complex and difficult to train. For the Learn2Reg2021 challenge, we aim to address these issues by decoupling feature learning and geometric alignment. First, we introduce a new very fast and accurate optimisation method. By using discretised displacements and a coupled convex optimisation procedure, we are able to robustly cope with large deformations. With the help of an Adam-based instance optimisation, we achieve very accurate registration performances and by using regularisation, we obtain smooth and plausible deformation fields. Second, to be versatile for different registration tasks, we extract hand-crafted features that are modality and contrast invariant and complement them with semantic features from a task-specific segmentation U-Net. With our results we were able to achieve the overall Learn2Reg2021 challenge's second place, winning Task 1 and being second and third in the other two tasks.
DaCy: A Unified Framework for Danish NLP
Jul 12, 2021
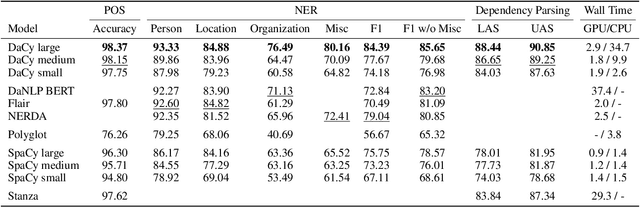
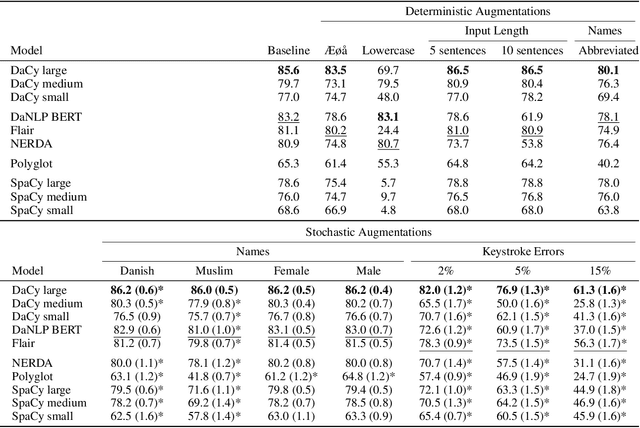
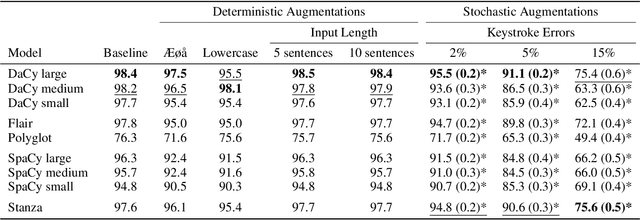
Danish natural language processing (NLP) has in recent years obtained considerable improvements with the addition of multiple new datasets and models. However, at present, there is no coherent framework for applying state-of-the-art models for Danish. We present DaCy: a unified framework for Danish NLP built on SpaCy. DaCy uses efficient multitask models which obtain state-of-the-art performance on named entity recognition, part-of-speech tagging, and dependency parsing. DaCy contains tools for easy integration of existing models such as for polarity, emotion, or subjectivity detection. In addition, we conduct a series of tests for biases and robustness of Danish NLP pipelines through augmentation of the test set of DaNE. DaCy large compares favorably and is especially robust to long input lengths and spelling variations and errors. All models except DaCy large display significant biases related to ethnicity while only Polyglot shows a significant gender bias. We argue that for languages with limited benchmark sets, data augmentation can be particularly useful for obtaining more realistic and fine-grained performance estimates. We provide a series of augmenters as a first step towards a more thorough evaluation of language models for low and medium resource languages and encourage further development.
Deep learning based geometric registration for medical images: How accurate can we get without visual features?
Mar 01, 2021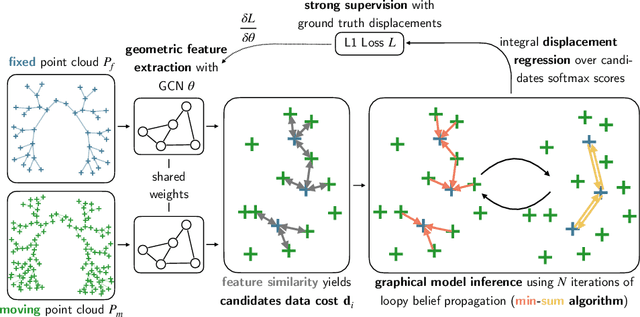
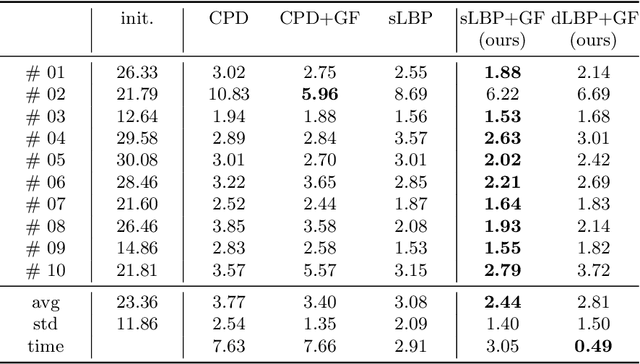
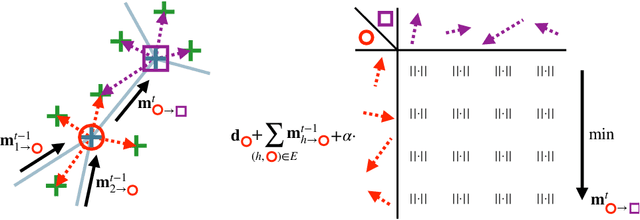
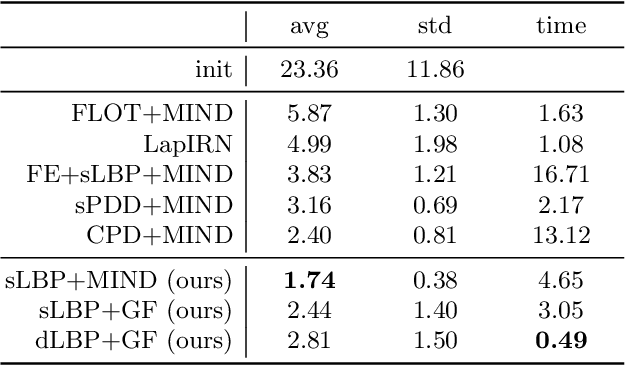
As in other areas of medical image analysis, e.g. semantic segmentation, deep learning is currently driving the development of new approaches for image registration. Multi-scale encoder-decoder network architectures achieve state-of-the-art accuracy on tasks such as intra-patient alignment of abdominal CT or brain MRI registration, especially when additional supervision, such as anatomical labels, is available. The success of these methods relies to a large extent on the outstanding ability of deep CNNs to extract descriptive visual features from the input images. In contrast to conventional methods, the explicit inclusion of geometric information plays only a minor role, if at all. In this work we take a look at an exactly opposite approach by investigating a deep learning framework for registration based solely on geometric features and optimisation. We combine graph convolutions with loopy belief message passing to enable highly accurate 3D point cloud registration. Our experimental validation is conducted on complex key-point graphs of inner lung structures, strongly outperforming dense encoder-decoder networks and other point set registration methods. Our code is publicly available at https://github.com/multimodallearning/deep-geo-reg.