 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVEB: Massive Video Embedding Benchmark
Jun 12, 2026We introduce the Massive Video Embedding Benchmark (MVEB), a 23-task benchmark for video embeddings spanning classification, zero-shot classification, clustering, pair classification, retrieval, and video-centric question answering. We evaluate 33 models and find that no single model dominates: MLLM-based embeddings lead on classification, clustering, pair classification, and QA; multimodal binding leads on retrieval and zero-shot classification; generative MLLMs without contrastive adaptation collapse on cross-modal tasks. Paired video-only vs. audio+video evaluations show that audio's contribution depends on dataset annotation provenance: audio helps when labels were produced from both modalities and hurts when they were produced from visuals alone, a six-point gap consistent across model families. MVEB is derived from MVEB+, a 184-task pool, and is designed to maintain task diversity while reducing evaluation cost. It integrates into the MTEB ecosystem for unified evaluation across text, image, audio, and video. We release MVEB and all 184 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
Modeling semantic association in self-paced reading with language model embeddings
Jun 05, 2026Semantic association between a word and its context has been identified as an important component of reading comprehension, even when word predictability is accounted for. Recent research has highlighted the potential of language model ( LM) embeddings to quantify semantic association. Yet, embedding-based semantic association have been operationalized in a myriad of ways. In this study, we use embeddings from LMs to estimate semantic association on a corpus of joint electroencephalography (EEG) and self-paced reading of natural, Dutch texts. Semantic association is calculated in ten different implementations that vary the embedding model and context lengths. The effects of semantic association across the different implementations on the N400 and self-paced reading times are examined using Bayesian hierarchical models and Bayes factor. The results show that the choice of embedding model can alter the estimated effect of semantic association on both the N400 and self-paced reading times. Furthermore, the results demonstrate a promising potential of sentence embeddings for capturing semantic association, as only implementations relying on sentence embeddings indicate reliable results of semantic association beyond word predictability on both neural and behavioral measures. Together, these findings highlight the importance of methodological choices in quantifying semantic association.
Naturalistic measure of social norms alignment
May 22, 2026Social norms reflect shared expectations on acceptable behavior. Measuring social norms alignment remains challenging, with existing approaches typically relying on artificial closed-form evaluations such as multiple-choice questionnaires or measuring agreement with predefined statements. In the context of this work, social norms alignment refers to measuring an agreement between solutions with respect to the social problem or dilemma. We propose a framework for measuring social norm alignment in naturalistic, free-form settings through solution matching. The framework enables us to measure alignment between any two dilemma responses e.g., LLMs to a human, LLMs to LLMs, or human to human. We introduce two metrics: stated and explicit agreement accuracy, and construct a dataset of 3k non-trivial social dilemmas in Danish. All dilemmas are assigned reference solutions derived from three panelists, who serve as culturally grounded judges. We evaluate the agreement of several LLMs and human responses in an interaction setup that resembles natural user-model conversations. Our results show that the proposed metrics produce consistent model rankings and reveal variation in agreement across different types of dilemmas, with higher agreement observed for topics such as neighbor conflicts and shared living situations. Overall, our work introduces a dataset and evaluation framework for studying culturally grounded social reasoning in naturalistic open-ended conversations.
One prompt is not enough: Instruction Sensitivity Undermines Embedding Model Evaluation
May 21, 2026Instruction embedding models have become common among state-of-the-art models, however are evaluated using a single prompt per task. The single-point evaluation ignores a main problem of the instruction-based approach namely: sensitivity to the phrasing of the instruction. We present an empirical study of prompt sensitivity across 6 embedding models, 11 datasets, and 15 task-specific prompts per dataset, a total of 990. We show that reported scores misrepresent the distribution of scores over plausible prompts. The default prompt can both systematically understate or overstate performance. Furthermore, we show that the leaderboard ranking is not robust to prompt selection: by choosing prompts favorably, any model in our study can be promoted to first place. Our findings suggest that single-prompt evaluation is insufficient for instruction-tuned embedding models and that benchmarks should incorporate prompt robustness, either by evaluating over multiple prompts or by reporting sensitivity alongside point estimates.
Closed-form predictive coding via hierarchical Gaussian filters
May 19, 2026Predictive coding (PC) offers a local and biologically grounded alternative to backpropagation in the training of artificial neural networks, yet to date, it remains slower, and performance degrades sharply as network depth increases. We trace both problems to a single simplification: current PC networks fix the precision matrix to the identity, discarding precision-weighted prediction errors that the variational derivation requires to be fast, local, and Bayesian. We close this gap by expressing predictive coding networks as deep hierarchical Gaussian filters (HGFs) and restore precision-weighted message passing, yielding dynamic uncertainty estimates and Hebbian-compatible update rules at every layer. The resulting networks can simultaneously learn activations, weights, and precisions under a single free-energy objective, with no global error signal, and resolve inference without requiring iterations or automatic differentiation. On FashionMNIST, our solution approaches backpropagation in epoch-level wall-clock cost while converging in fewer epochs, and outperforms it on online, data efficiency, and concept-drift tasks. We thus establish that closed-form variational inference with online precision learning provides a tractable foundation for deep predictive coding networks, retaining biological and interpretative advantages, without requiring iterative relaxation or global error signals.
MAEB: Massive Audio Embedding Benchmark
Feb 17, 2026We introduce the Massive Audio Embedding Benchmark (MAEB), a large-scale benchmark covering 30 tasks across speech, music, environmental sounds, and cross-modal audio-text reasoning in 100+ languages. We evaluate 50+ models and find that no single model dominates across all tasks: contrastive audio-text models excel at environmental sound classification (e.g., ESC50) but score near random on multilingual speech tasks (e.g., SIB-FLEURS), while speech-pretrained models show the opposite pattern. Clustering remains challenging for all models, with even the best-performing model achieving only modest results. We observe that models excelling on acoustic understanding often perform poorly on linguistic tasks, and vice versa. We also show that the performance of audio encoders on MAEB correlates highly with their performance when used in audio large language models. MAEB is derived from MAEB+, a collection of 98 tasks. MAEB is designed to maintain task diversity while reducing evaluation cost, and it integrates into the MTEB ecosystem for unified evaluation across text, image, and audio modalities. We release MAEB and all 98 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
Is Sentiment Banana-Shaped? Exploring the Geometry and Portability of Sentiment Concept Vectors
Jan 12, 2026Use cases of sentiment analysis in the humanities often require contextualized, continuous scores. Concept Vector Projections (CVP) offer a recent solution: by modeling sentiment as a direction in embedding space, they produce continuous, multilingual scores that align closely with human judgments. Yet the method's portability across domains and underlying assumptions remain underexplored. We evaluate CVP across genres, historical periods, languages, and affective dimensions, finding that concept vectors trained on one corpus transfer well to others with minimal performance loss. To understand the patterns of generalization, we further examine the linearity assumption underlying CVP. Our findings suggest that while CVP is a portable approach that effectively captures generalizable patterns, its linearity assumption is approximate, pointing to potential for further development.
Continuous sentiment scores for literary and multilingual contexts
Aug 20, 2025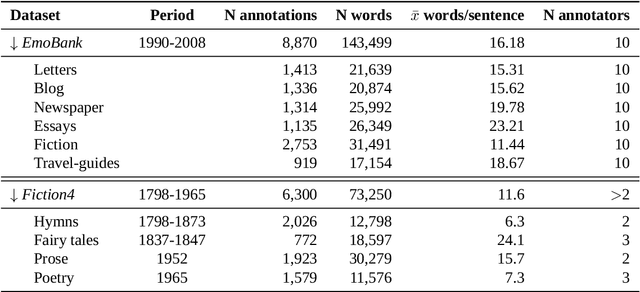



Sentiment Analysis is widely used to quantify sentiment in text, but its application to literary texts poses unique challenges due to figurative language, stylistic ambiguity, as well as sentiment evocation strategies. Traditional dictionary-based tools often underperform, especially for low-resource languages, and transformer models, while promising, typically output coarse categorical labels that limit fine-grained analysis. We introduce a novel continuous sentiment scoring method based on concept vector projection, trained on multilingual literary data, which more effectively captures nuanced sentiment expressions across genres, languages, and historical periods. Our approach outperforms existing tools on English and Danish texts, producing sentiment scores whose distribution closely matches human ratings, enabling more accurate analysis and sentiment arc modeling in literature.
MIEB: Massive Image Embedding Benchmark
Apr 14, 2025Image representations are often evaluated through disjointed, task-specific protocols, leading to a fragmented understanding of model capabilities. For instance, it is unclear whether an image embedding model adept at clustering images is equally good at retrieving relevant images given a piece of text. We introduce the Massive Image Embedding Benchmark (MIEB) to evaluate the performance of image and image-text embedding models across the broadest spectrum to date. MIEB spans 38 languages across 130 individual tasks, which we group into 8 high-level categories. We benchmark 50 models across our benchmark, finding that no single method dominates across all task categories. We reveal hidden capabilities in advanced vision models such as their accurate visual representation of texts, and their yet limited capabilities in interleaved encodings and matching images and texts in the presence of confounders. We also show that the performance of vision encoders on MIEB correlates highly with their performance when used in multimodal large language models. Our code, dataset, and leaderboard are publicly available at https://github.com/embeddings-benchmark/mteb.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.