 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Noisy Anchors for One-stage Object Detection
Dec 11, 2019
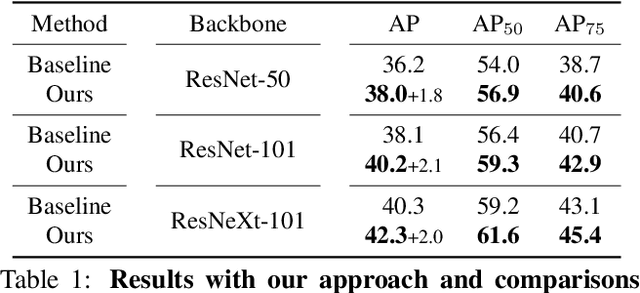
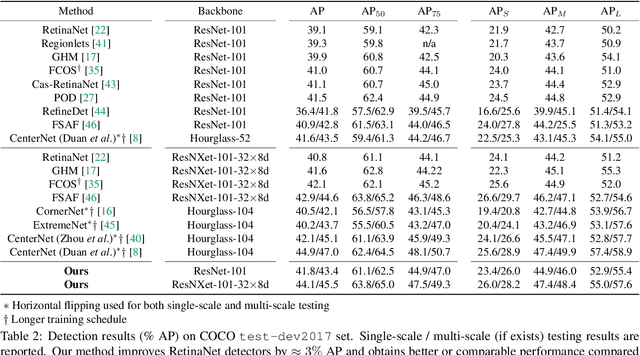
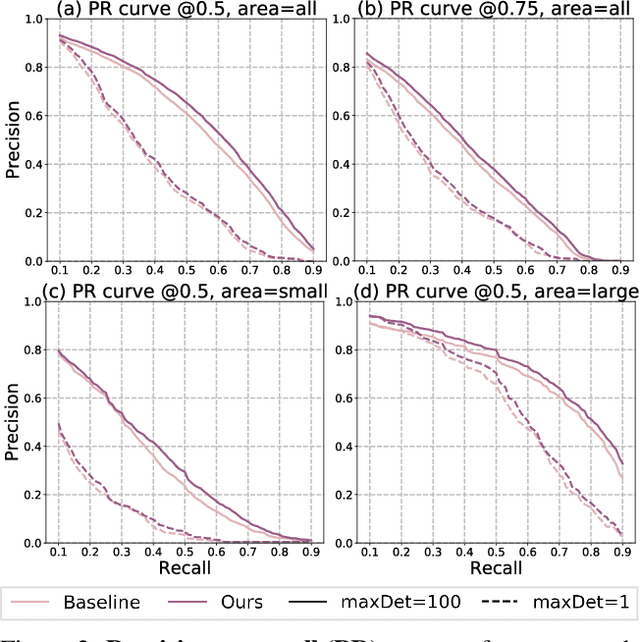
State-of-the-art object detectors rely on regressing and classifying an extensive list of possible anchors, which are divided into positive and negative samples based on their intersection-over-union (IoU) with corresponding groundtruth objects. Such a harsh split conditioned on IoU results in binary labels that are potentially noisy and challenging for training. In this paper, we propose to mitigate noise incurred by imperfect label assignment such that the contributions of anchors are dynamically determined by a carefully constructed cleanliness score associated with each anchor. Exploring outputs from both regression and classification branches, the cleanliness scores, estimated without incurring any additional computational overhead, are used not only as soft labels to supervise the training of the classification branch but also sample re-weighting factors for improved localization and classification accuracy. We conduct extensive experiments on COCO, and demonstrate, among other things, the proposed approach steadily improves RetinaNet by ~2% with various backbones.
LiteEval: A Coarse-to-Fine Framework for Resource Efficient Video Recognition
Dec 03, 2019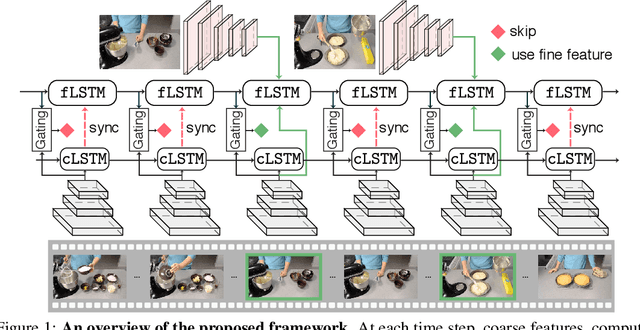
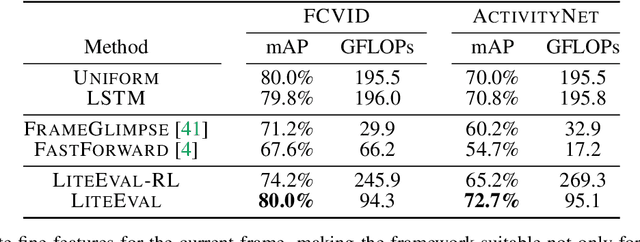
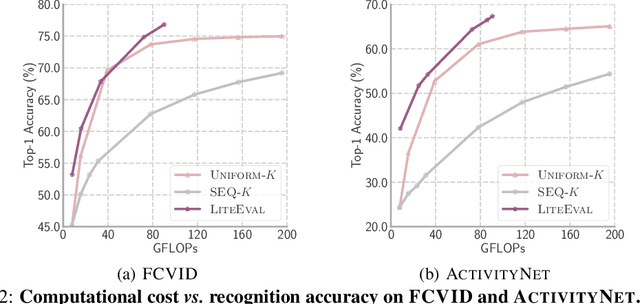
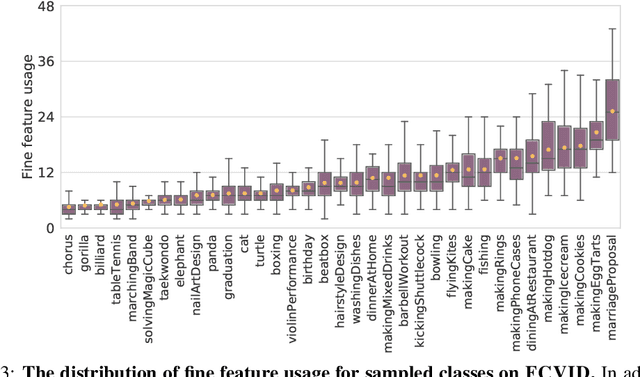
This paper presents LiteEval, a simple yet effective coarse-to-fine framework for resource efficient video recognition, suitable for both online and offline scenarios. Exploiting decent yet computationally efficient features derived at a coarse scale with a lightweight CNN model, LiteEval dynamically decides on-the-fly whether to compute more powerful features for incoming video frames at a finer scale to obtain more details. This is achieved by a coarse LSTM and a fine LSTM operating cooperatively, as well as a conditional gating module to learn when to allocate more computation. Extensive experiments are conducted on two large-scale video benchmarks, FCVID and ActivityNet, and the results demonstrate LiteEval requires substantially less computation while offering excellent classification accuracy for both online and offline predictions.
Consistency-Based Semi-Supervised Active Learning: Towards Minimizing Labeling Cost
Oct 16, 2019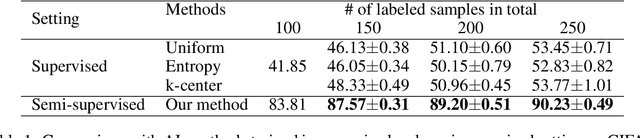
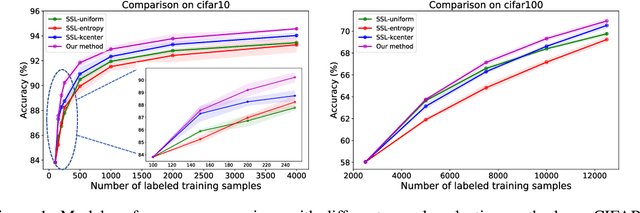
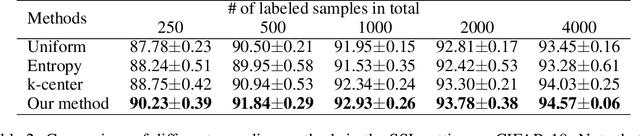
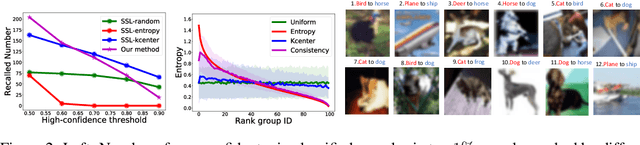
Active learning (AL) integrates data labeling and model training to minimize the labeling cost by prioritizing the selection of high value data that can best improve model performance. Readily-available unlabeled data are used for selection mechanisms, but are not used for model training in most conventional pool-based AL methods. To minimize the labeling cost, we unify unlabeled sample selection and model training based on two principles. First, we exploit both labeled and unlabeled data using semi-supervised learning (SSL) to distill information from unlabeled data that improves representation learning and sample selection. Second, we propose a simple yet effective selection metric that is coherent with the training objective such that the selected samples are effective at improving model performance. Experimental results demonstrate superior performance of our proposed principles for limited labeled data compared to alternative AL and SSL combinations. In addition, we study an important problem -- "When can we start AL?". We propose a measure that is empirically correlated with the AL target loss and can be used to assist in determining the proper start point.
Cross-X Learning for Fine-Grained Visual Categorization
Sep 10, 2019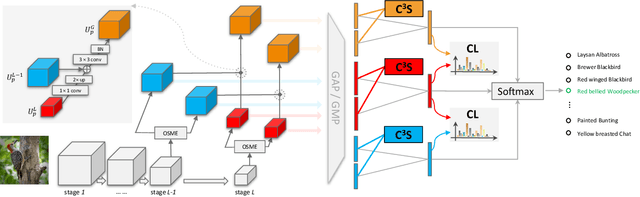
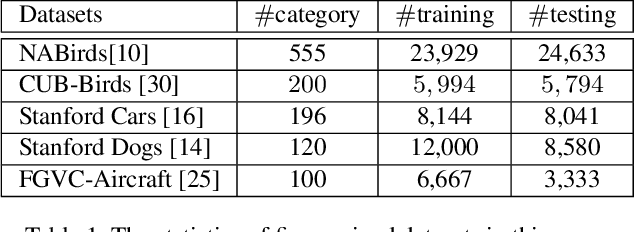
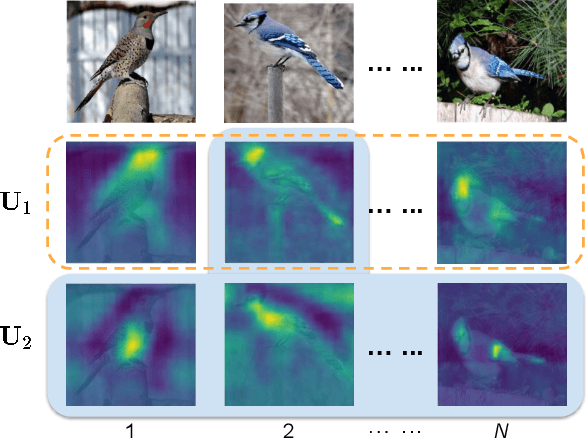
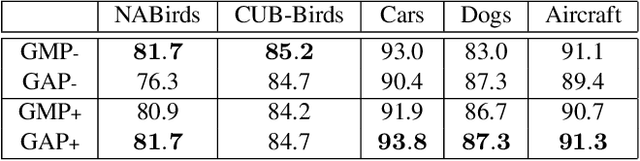
Recognizing objects from subcategories with very subtle differences remains a challenging task due to the large intra-class and small inter-class variation. Recent work tackles this problem in a weakly-supervised manner: object parts are first detected and the corresponding part-specific features are extracted for fine-grained classification. However, these methods typically treat the part-specific features of each image in isolation while neglecting their relationships between different images. In this paper, we propose Cross-X learning, a simple yet effective approach that exploits the relationships between different images and between different network layers for robust multi-scale feature learning. Our approach involves two novel components: (i) a cross-category cross-semantic regularizer that guides the extracted features to represent semantic parts and, (ii) a cross-layer regularizer that improves the robustness of multi-scale features by matching the prediction distribution across multiple layers. Our approach can be easily trained end-to-end and is scalable to large datasets like NABirds. We empirically analyze the contributions of different components of our approach and demonstrate its robustness, effectiveness and state-of-the-art performance on five benchmark datasets. Code is available at \url{https://github.com/cswluo/CrossX}.
HiCoRe: Visual Hierarchical Context-Reasoning
Sep 02, 2019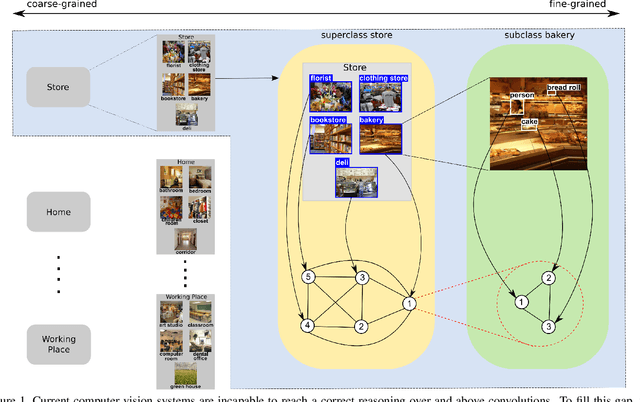
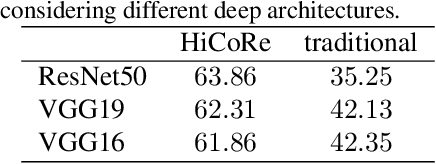
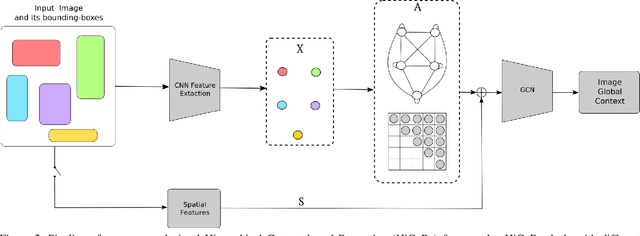
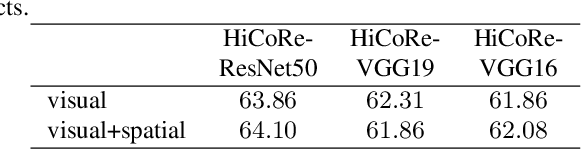
Reasoning about images/objects and their hierarchical interactions is a key concept for the next generation of computer vision approaches. Here we present a new framework to deal with it through a visual hierarchical context-based reasoning. Current reasoning methods use the fine-grained labels from images' objects and their interactions to predict labels to new objects. Our framework modifies this current information flow. It goes beyond and is independent of the fine-grained labels from the objects to define the image context. It takes into account the hierarchical interactions between different abstraction levels (i.e. taxonomy) of information in the images and their bounding-boxes. Besides these connections, it considers their intrinsic characteristics. To do so, we build and apply graphs to graph convolution networks with convolutional neural networks. We show a strong effectiveness over widely used convolutional neural networks, reaching a gain 3 times greater on well-known image datasets. We evaluate the capability and the behavior of our framework under different scenarios, considering distinct (superclass, subclass and hierarchical) granularity levels. We also explore attention mechanisms through graph attention networks and pre-processing methods considering dimensionality expansion and/or reduction of the features' representations. Further analyses are performed comparing supervised and semi-supervised approaches.
WSLLN: Weakly Supervised Natural Language Localization Networks
Aug 31, 2019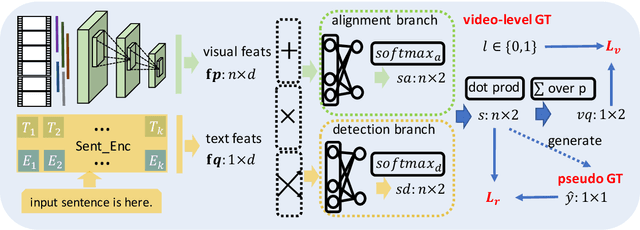

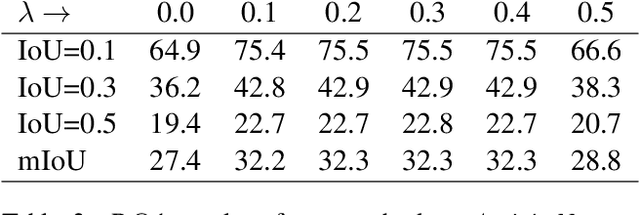
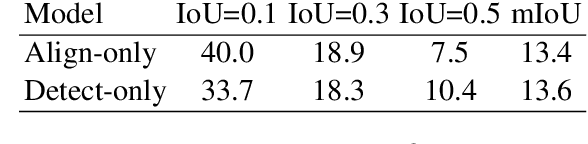
We propose weakly supervised language localization networks (WSLLN) to detect events in long, untrimmed videos given language queries. To learn the correspondence between visual segments and texts, most previous methods require temporal coordinates (start and end times) of events for training, which leads to high costs of annotation. WSLLN relieves the annotation burden by training with only video-sentence pairs without accessing to temporal locations of events. With a simple end-to-end structure, WSLLN measures segment-text consistency and conducts segment selection (conditioned on the text) simultaneously. Results from both are merged and optimized as a video-sentence matching problem. Experiments on ActivityNet Captions and DiDeMo demonstrate that WSLLN achieves state-of-the-art performance.
Truncated Cauchy Non-negative Matrix Factorization
Jun 02, 2019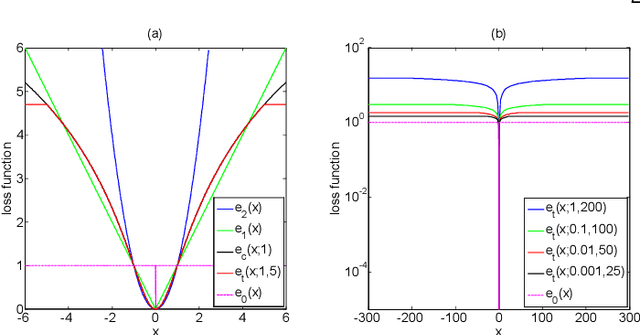



Non-negative matrix factorization (NMF) minimizes the Euclidean distance between the data matrix and its low rank approximation, and it fails when applied to corrupted data because the loss function is sensitive to outliers. In this paper, we propose a Truncated CauchyNMF loss that handle outliers by truncating large errors, and develop a Truncated CauchyNMF to robustly learn the subspace on noisy datasets contaminated by outliers. We theoretically analyze the robustness of Truncated CauchyNMF comparing with the competing models and theoretically prove that Truncated CauchyNMF has a generalization bound which converges at a rate of order $O(\sqrt{{\ln n}/{n}})$, where $n$ is the sample size. We evaluate Truncated CauchyNMF by image clustering on both simulated and real datasets. The experimental results on the datasets containing gross corruptions validate the effectiveness and robustness of Truncated CauchyNMF for learning robust subspaces.
An Analysis of Object Embeddings for Image Retrieval
May 28, 2019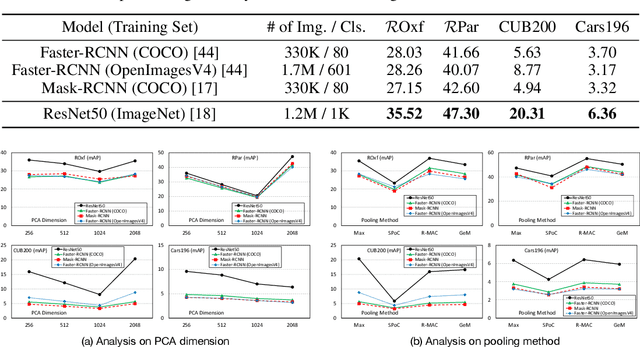

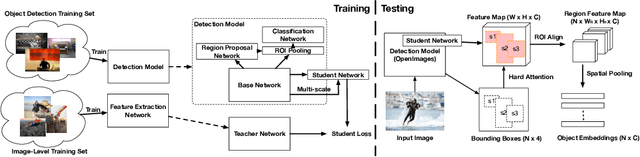
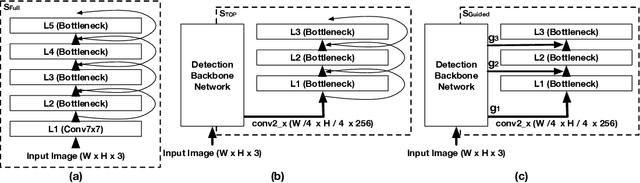
We present an analysis of embeddings extracted from different pre-trained models for content-based image retrieval. Specifically, we study embeddings from image classification and object detection models. We discover that even with additional human annotations such as bounding boxes and segmentation masks, the discriminative power of the embeddings based on modern object detection models is significantly worse than their classification counterparts for the retrieval task. At the same time, our analysis also unearths that object detection model can help retrieval task by acting as a hard attention module for extracting object embeddings that focus on salient region from the convolutional feature map. In order to efficiently extract object embeddings, we introduce a simple guided student-teacher training paradigm for learning discriminative embeddings within the object detection framework. We support our findings with strong experimental results.
Adversarial Training for Free!
Apr 29, 2019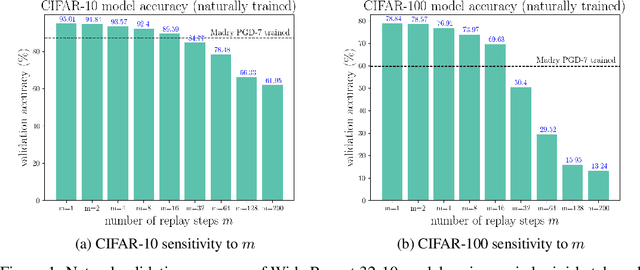
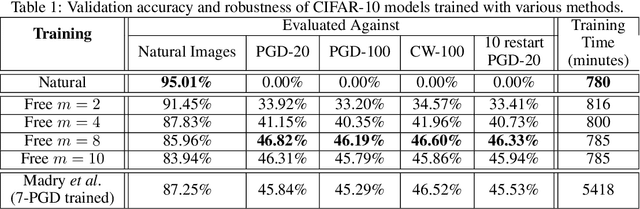
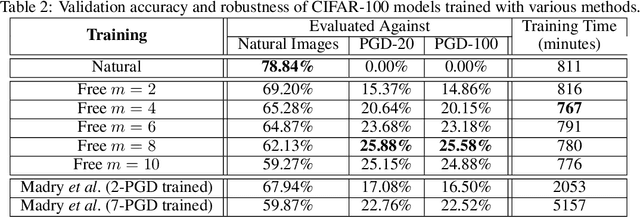

Adversarial training, in which a network is trained on adversarial examples, is one of the few defenses against adversarial attacks that withstands strong attacks. Unfortunately, the high cost of generating strong adversarial examples makes standard adversarial training impractical on large-scale problems like ImageNet. We present an algorithm that eliminates the overhead cost of generating adversarial examples by recycling the gradient information computed when updating model parameters. Our "free" adversarial training algorithm achieves state-of-the-art robustness on CIFAR-10 and CIFAR-100 datasets at negligible additional cost compared to natural training, and can be 7 to 30 times faster than other strong adversarial training methods. Using a single workstation with 4 P100 GPUs and 2 days of runtime, we can train a robust model for the large-scale ImageNet classification task that maintains 40% accuracy against PGD attacks.
ACE: Adapting to Changing Environments for Semantic Segmentation
Apr 12, 2019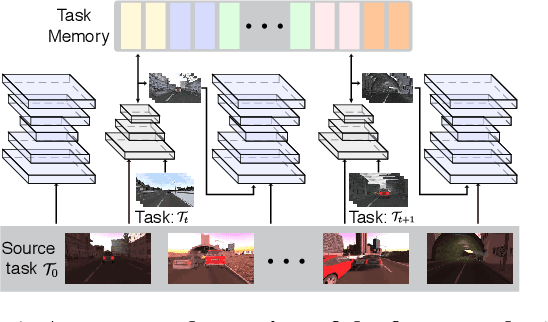
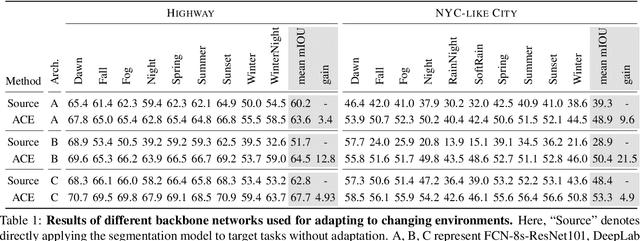
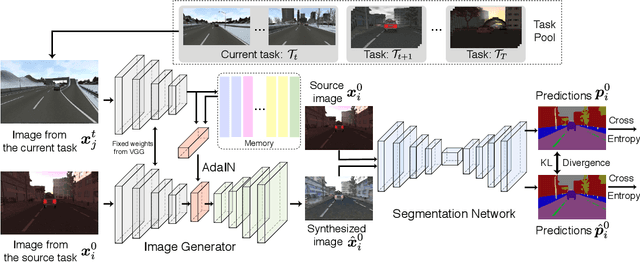
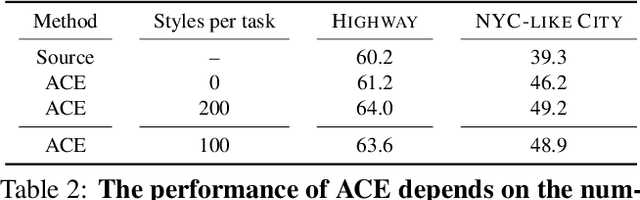
Deep neural networks exhibit exceptional accuracy when they are trained and tested on the same data distributions. However, neural classifiers are often extremely brittle when confronted with domain shift---changes in the input distribution that occur over time. We present ACE, a framework for semantic segmentation that dynamically adapts to changing environments over the time. By aligning the distribution of labeled training data from the original source domain with the distribution of incoming data in a shifted domain, ACE synthesizes labeled training data for environments as it sees them. This stylized data is then used to update a segmentation model so that it performs well in new environments. To avoid forgetting knowledge from past environments, we introduce a memory that stores feature statistics from previously seen domains. These statistics can be used to replay images in any of the previously observed domains, thus preventing catastrophic forgetting. In addition to standard batch training using stochastic gradient decent (SGD), we also experiment with fast adaptation methods based on adaptive meta-learning. Extensive experiments are conducted on two datasets from SYNTHIA, the results demonstrate the effectiveness of the proposed approach when adapting to a number of tasks.