 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021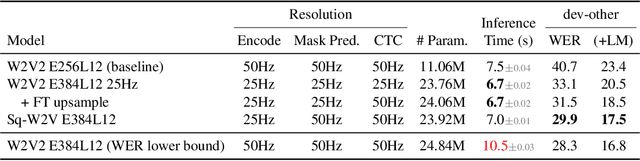
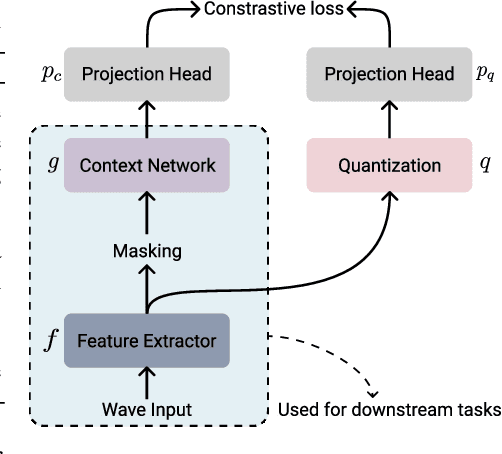
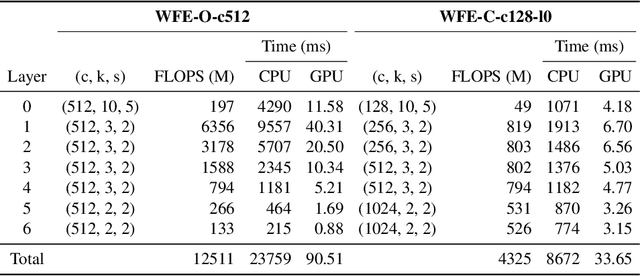
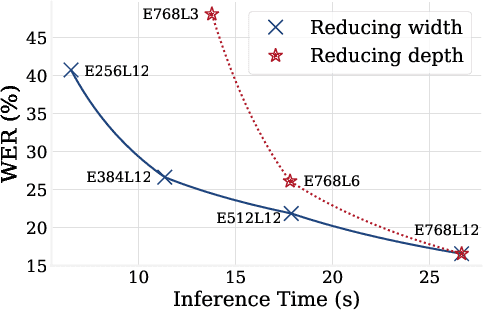
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Multi-mode Transformer Transducer with Stochastic Future Context
Jun 17, 2021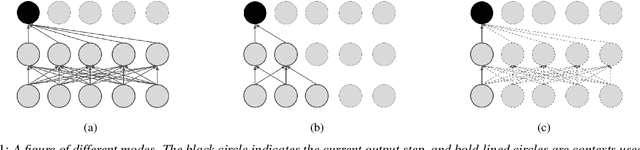
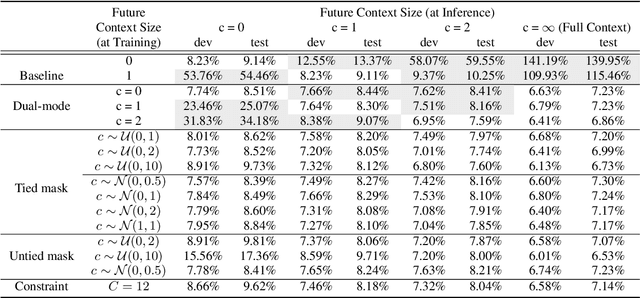
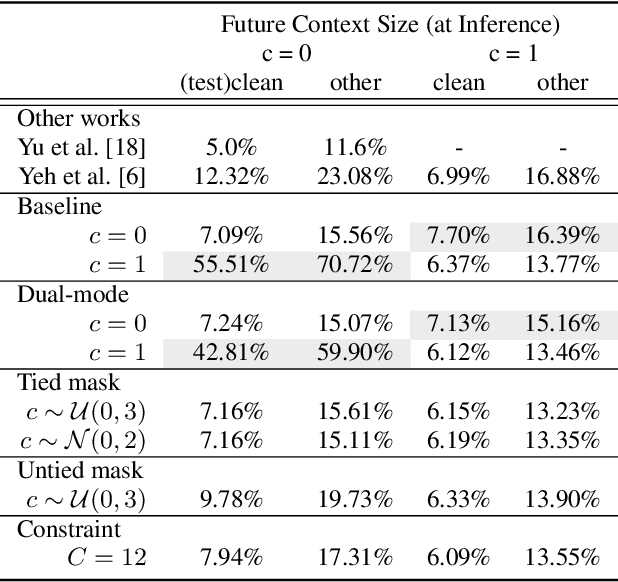
Automatic speech recognition (ASR) models make fewer errors when more surrounding speech information is presented as context. Unfortunately, acquiring a larger future context leads to higher latency. There exists an inevitable trade-off between speed and accuracy. Naively, to fit different latency requirements, people have to store multiple models and pick the best one under the constraints. Instead, a more desirable approach is to have a single model that can dynamically adjust its latency based on different constraints, which we refer to as Multi-mode ASR. A Multi-mode ASR model can fulfill various latency requirements during inference -- when a larger latency becomes acceptable, the model can process longer future context to achieve higher accuracy and when a latency budget is not flexible, the model can be less dependent on future context but still achieve reliable accuracy. In pursuit of Multi-mode ASR, we propose Stochastic Future Context, a simple training procedure that samples one streaming configuration in each iteration. Through extensive experiments on AISHELL-1 and LibriSpeech datasets, we show that a Multi-mode ASR model rivals, if not surpasses, a set of competitive streaming baselines trained with different latency budgets.
Sequential Routing Framework: Fully Capsule Network-based Speech Recognition
Jul 23, 2020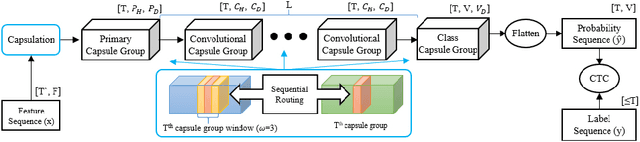
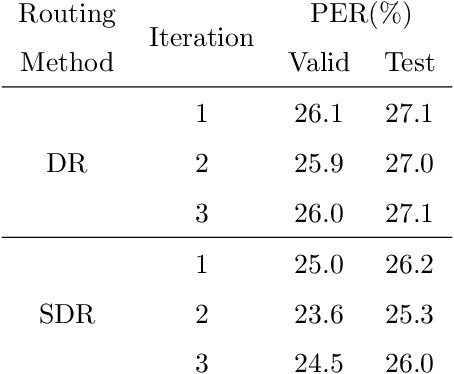
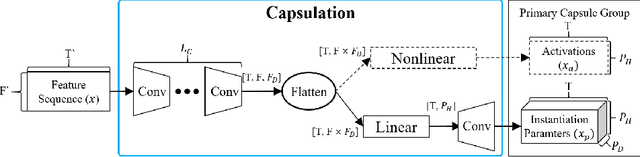
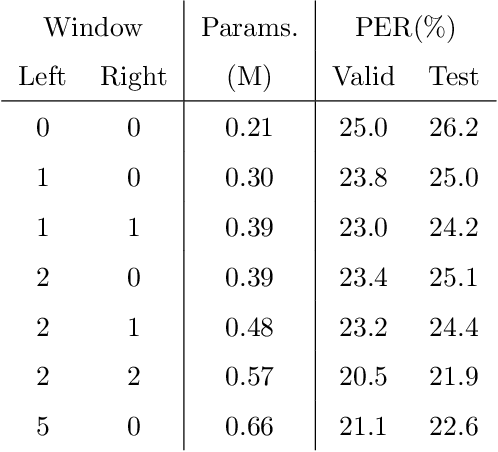
Capsule networks (CapsNets) have recently gotten attention as alternatives for convolutional neural networks (CNNs) with their greater hierarchical representation capabilities. In this paper, we introduce the sequential routing framework (SRF) which we believe is the first method to adapt a CapsNet-only structure to sequence-to-sequence recognition. In SRF, input sequences are capsulized then sliced by the window size. Each sliced window is classified to a label at the corresponding time through iterative routing mechanisms. Afterwards, training losses are computed using connectionist temporal classification (CTC). During routing, two kinds of information, learnable weights and iteration outputs are shared across the slices. By sharing the information, the required parameter numbers can be controlled by the given window size regardless of the length of sequences. Moreover, the method can minimize decoding speed degradation caused by the routing iterations since it can operate in a non-iterative manner at inference time without dropping accuracy. We empirically proved the validity of our method by performing phoneme sequence recognition tasks on the TIMIT corpus. The proposed method attains an 82.6% phoneme recognition rate. It is 0.8% more accurate than that of CNN-based CTC networks and on par with that of recurrent neural network transducers (RNN-Ts). Even more, the method requires less than half the parameters compared to the two architectures.
Small energy masking for improved neural network training for end-to-end speech recognition
Feb 15, 2020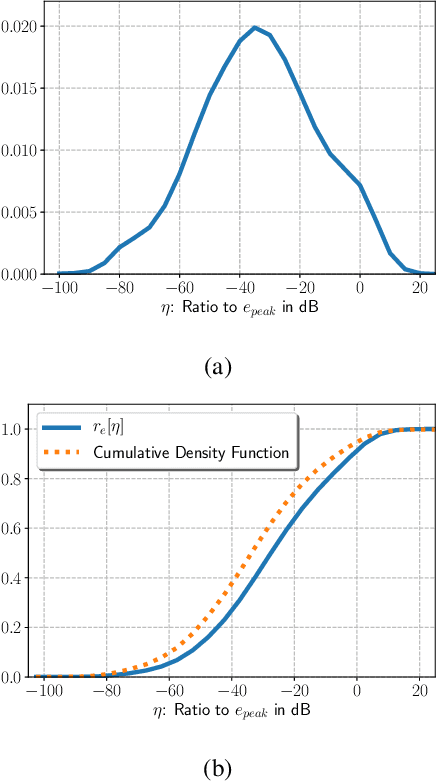
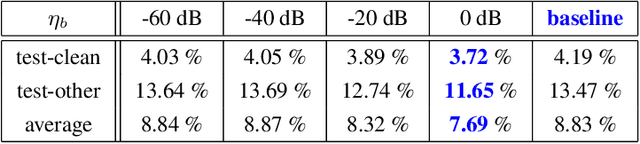
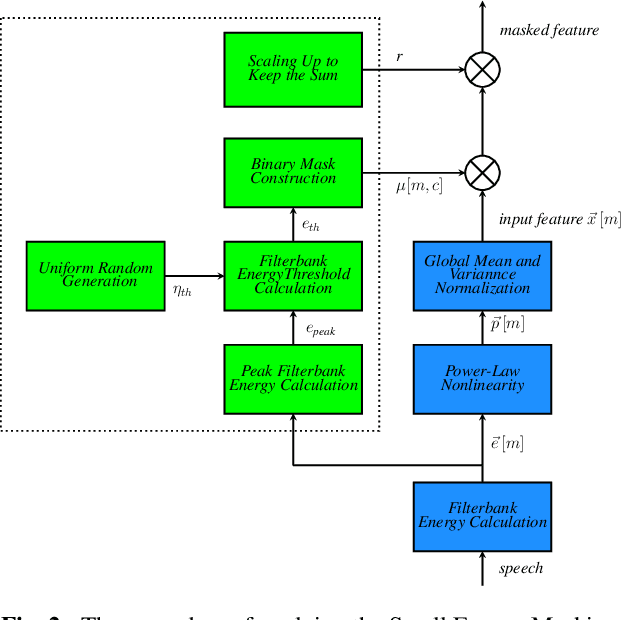
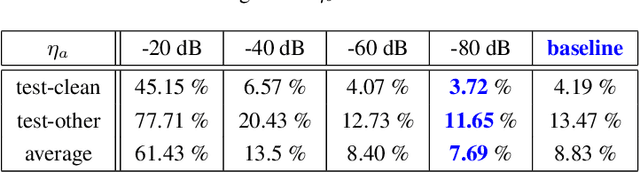
In this paper, we present a Small Energy Masking (SEM) algorithm, which masks inputs having values below a certain threshold. More specifically, a time-frequency bin is masked if the filterbank energy in this bin is less than a certain energy threshold. A uniform distribution is employed to randomly generate the ratio of this energy threshold to the peak filterbank energy of each utterance in decibels. The unmasked feature elements are scaled so that the total sum of the feature values remain the same through this masking procedure. This very simple algorithm shows relatively 11.2 % and 13.5 % Word Error Rate (WER) improvements on the standard LibriSpeech test-clean and test-other sets over the baseline end-to-end speech recognition system. Additionally, compared to the input dropout algorithm, SEM algorithm shows relatively 7.7 % and 11.6 % improvements on the same LibriSpeech test-clean and test-other sets. With a modified shallow-fusion technique with a Transformer LM, we obtained a 2.62 % WER on the LibriSpeech test-clean set and a 7.87 % WER on the LibriSpeech test-other set.
Attention based on-device streaming speech recognition with large speech corpus
Jan 02, 2020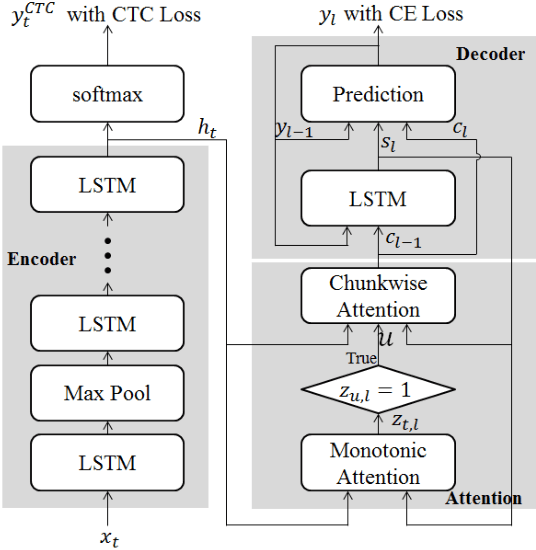
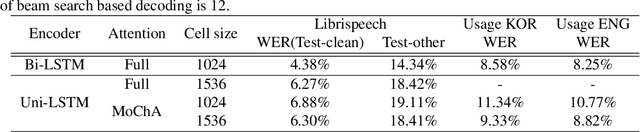

In this paper, we present a new on-device automatic speech recognition (ASR) system based on monotonic chunk-wise attention (MoChA) models trained with large (> 10K hours) corpus. We attained around 90% of a word recognition rate for general domain mainly by using joint training of connectionist temporal classifier (CTC) and cross entropy (CE) losses, minimum word error rate (MWER) training, layer-wise pre-training and data augmentation methods. In addition, we compressed our models by more than 3.4 times smaller using an iterative hyper low-rank approximation (LRA) method while minimizing the degradation in recognition accuracy. The memory footprint was further reduced with 8-bit quantization to bring down the final model size to lower than 39 MB. For on-demand adaptation, we fused the MoChA models with statistical n-gram models, and we could achieve a relatively 36% improvement on average in word error rate (WER) for target domains including the general domain.
Improved Multi-Stage Training of Online Attention-based Encoder-Decoder Models
Dec 28, 2019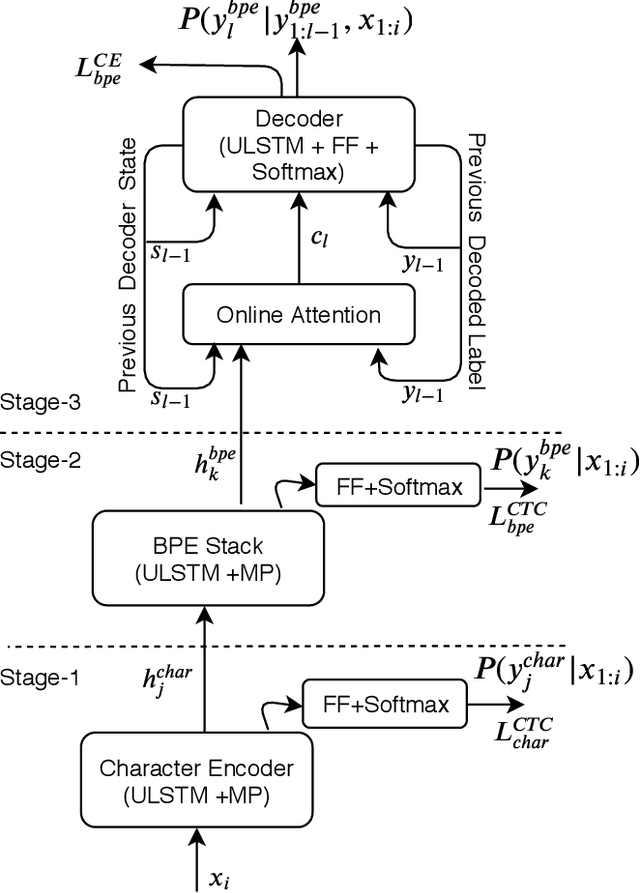

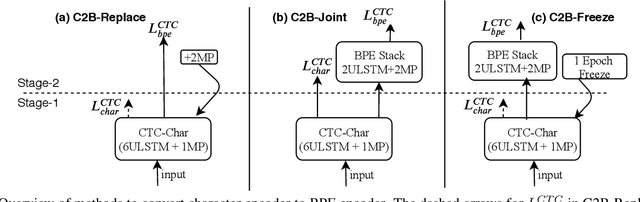
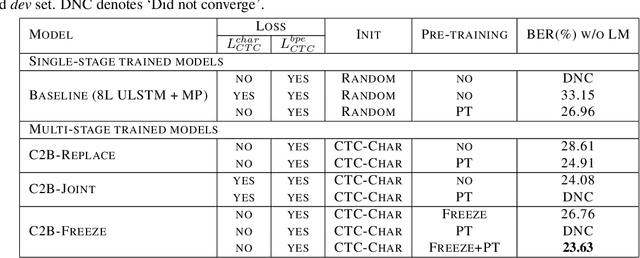
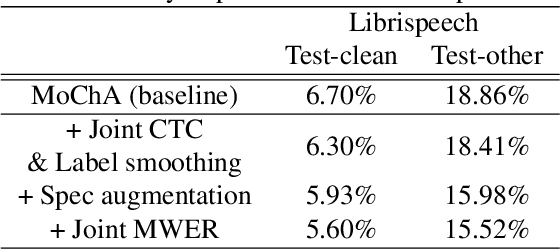
In this paper, we propose a refined multi-stage multi-task training strategy to improve the performance of online attention-based encoder-decoder (AED) models. A three-stage training based on three levels of architectural granularity namely, character encoder, byte pair encoding (BPE) based encoder, and attention decoder, is proposed. Also, multi-task learning based on two-levels of linguistic granularity namely, character and BPE, is used. We explore different pre-training strategies for the encoders including transfer learning from a bidirectional encoder. Our encoder-decoder models with online attention show 35% and 10% relative improvement over their baselines for smaller and bigger models, respectively. Our models achieve a word error rate (WER) of 5.04% and 4.48% on the Librispeech test-clean data for the smaller and bigger models respectively after fusion with long short-term memory (LSTM) based external language model (LM).
power-law nonlinearity with maximally uniform distribution criterion for improved neural network training in automatic speech recognition
Dec 22, 2019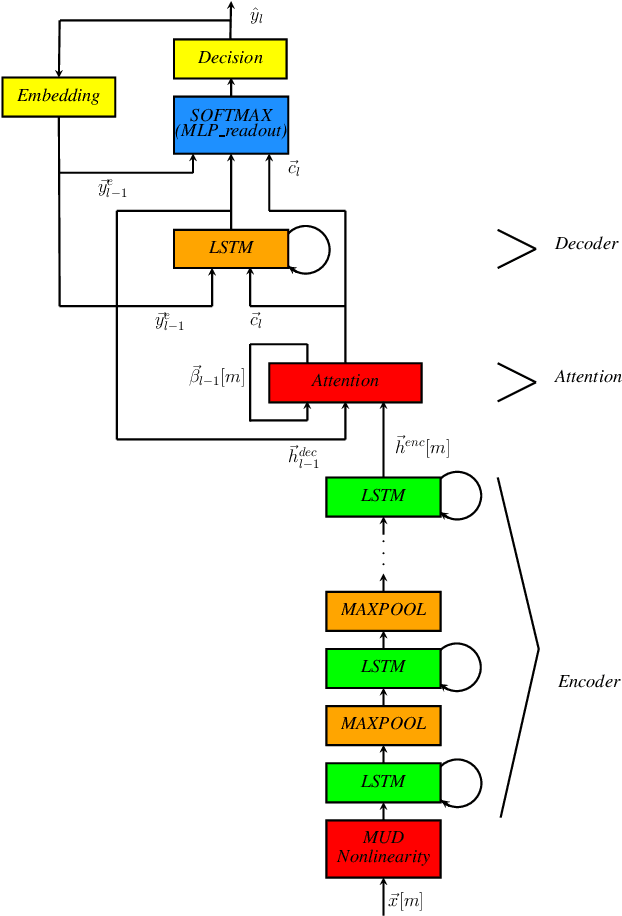
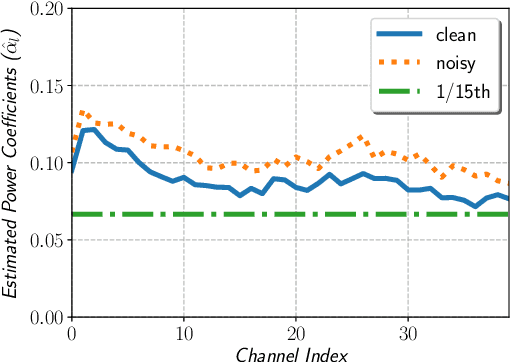
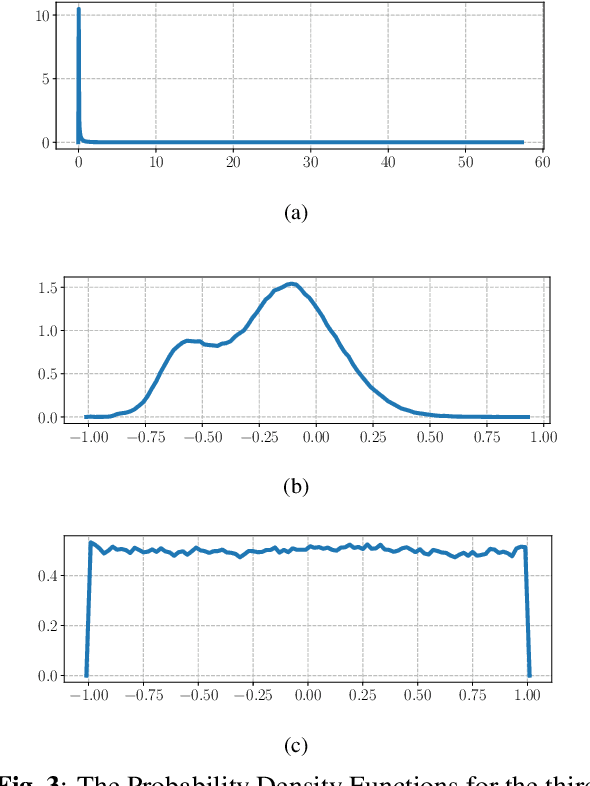
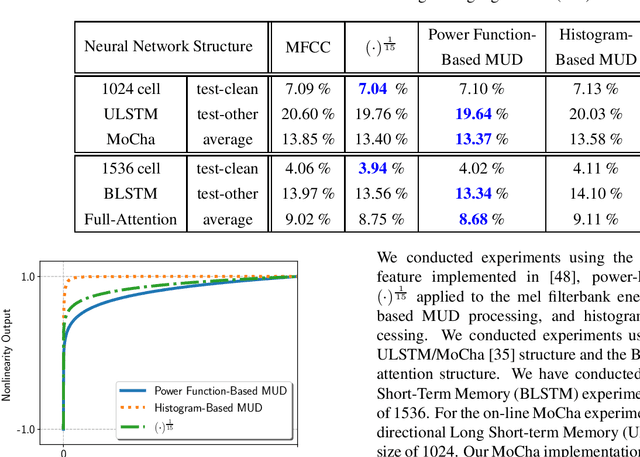
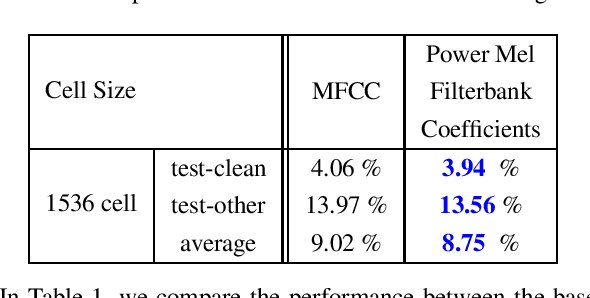
In this paper, we describe the Maximum Uniformity of Distribution (MUD) algorithm with the power-law nonlinearity. In this approach, we hypothesize that neural network training will become more stable if feature distribution is not too much skewed. We propose two different types of MUD approaches: power function-based MUD and histogram-based MUD. In these approaches, we first obtain the mel filterbank coefficients and apply nonlinearity functions for each filterbank channel. With the power function-based MUD, we apply a power-function based nonlinearity where power function coefficients are chosen to maximize the likelihood assuming that nonlinearity outputs follow the uniform distribution. With the histogram-based MUD, the empirical Cumulative Density Function (CDF) from the training database is employed to transform the original distribution into a uniform distribution. In MUD processing, we do not use any prior knowledge (e.g. logarithmic relation) about the energy of the incoming signal and the perceived intensity by a human. Experimental results using an end-to-end speech recognition system demonstrate that power-function based MUD shows better result than the conventional Mel Filterbank Cepstral Coefficients (MFCCs). On the LibriSpeech database, we could achieve 4.02 % WER on test-clean and 13.34 % WER on test-other without using any Language Models (LMs). The major contribution of this work is that we developed a new algorithm for designing the compressive nonlinearity in a data-driven way, which is much more flexible than the previous approaches and may be extended to other domains as well.
end-to-end training of a large vocabulary end-to-end speech recognition system
Dec 22, 2019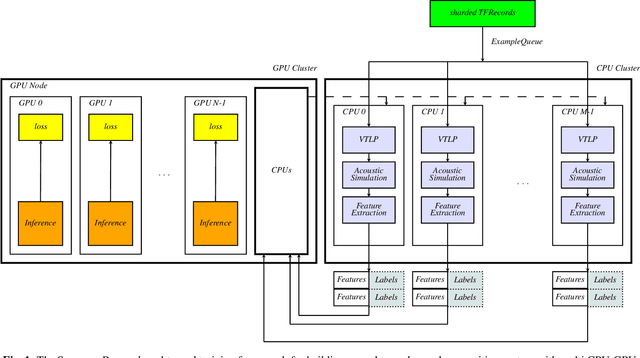
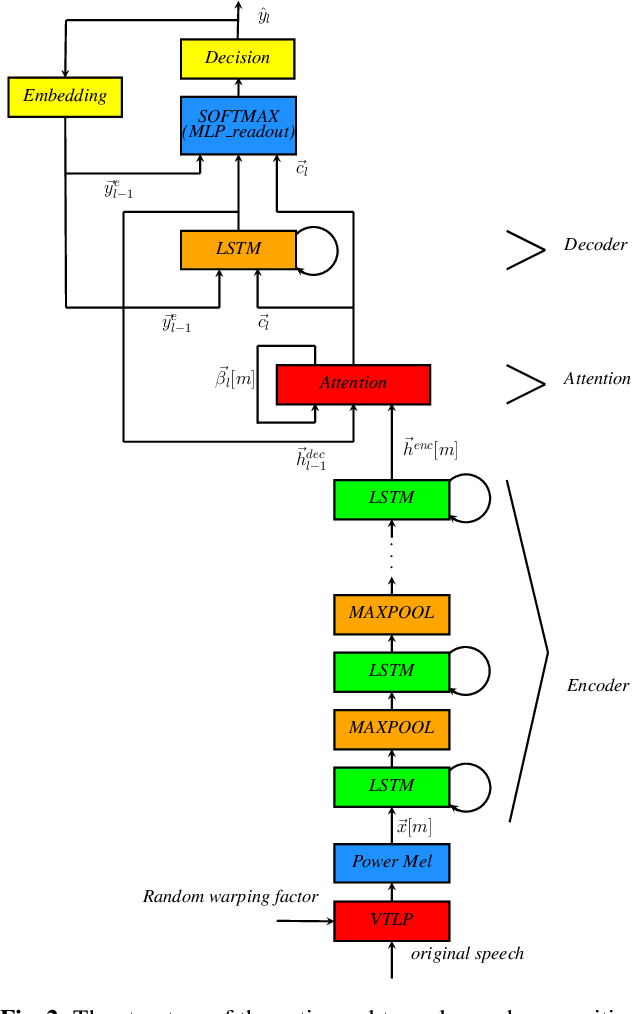
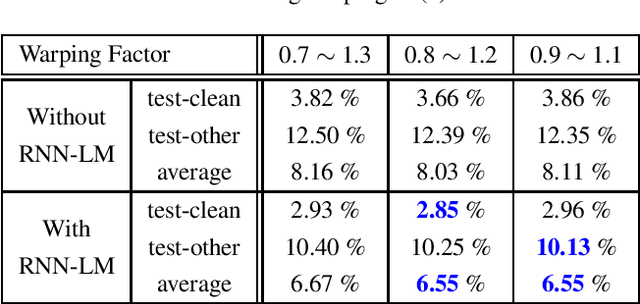
In this paper, we present an end-to-end training framework for building state-of-the-art end-to-end speech recognition systems. Our training system utilizes a cluster of Central Processing Units(CPUs) and Graphics Processing Units (GPUs). The entire data reading, large scale data augmentation, neural network parameter updates are all performed "on-the-fly". We use vocal tract length perturbation [1] and an acoustic simulator [2] for data augmentation. The processed features and labels are sent to the GPU cluster. The Horovod allreduce approach is employed to train neural network parameters. We evaluated the effectiveness of our system on the standard Librispeech corpus [3] and the 10,000-hr anonymized Bixby English dataset. Our end-to-end speech recognition system built using this training infrastructure showed a 2.44 % WER on test-clean of the LibriSpeech test set after applying shallow fusion with a Transformer language model (LM). For the proprietary English Bixby open domain test set, we obtained a WER of 7.92 % using a Bidirectional Full Attention (BFA) end-to-end model after applying shallow fusion with an RNN-LM. When the monotonic chunckwise attention (MoCha) based approach is employed for streaming speech recognition, we obtained a WER of 9.95 % on the same Bixby open domain test set.