 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Data Integration
Jun 10, 2020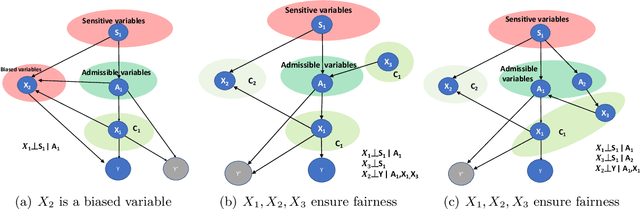
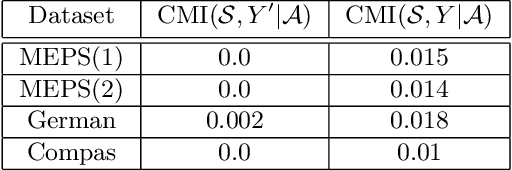
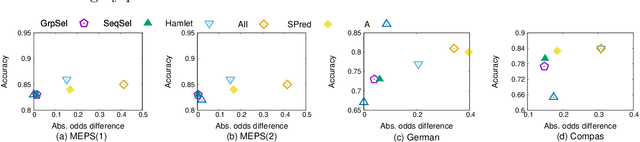
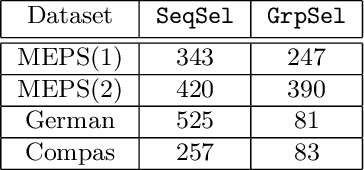
The use of machine learning (ML) in high-stakes societal decisions has encouraged the consideration of fairness throughout the ML lifecycle. Although data integration is one of the primary steps to generate high quality training data, most of the fairness literature ignores this stage. In this work, we consider fairness in the integration component of data management, aiming to identify features that improve prediction without adding any bias to the dataset. We work under the causal interventional fairness paradigm. Without requiring the underlying structural causal model a priori, we propose an approach to identify a sub-collection of features that ensure the fairness of the dataset by performing conditional independence tests between different subsets of features. We use group testing to improve the complexity of the approach. We theoretically prove the correctness of the proposed algorithm to identify features that ensure interventional fairness and show that sub-linear conditional independence tests are sufficient to identify these variables. A detailed empirical evaluation is performed on real-world datasets to demonstrate the efficacy and efficiency of our technique.
Invariant Risk Minimization Games
Mar 18, 2020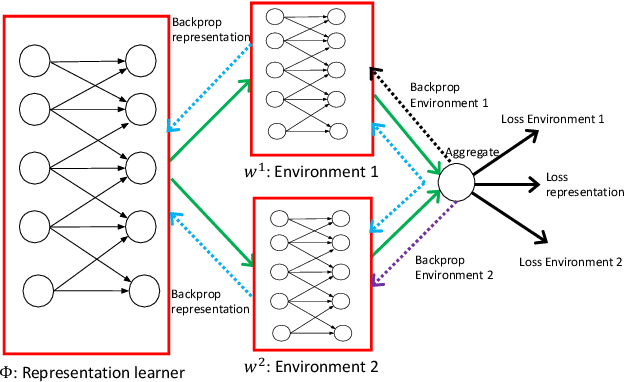
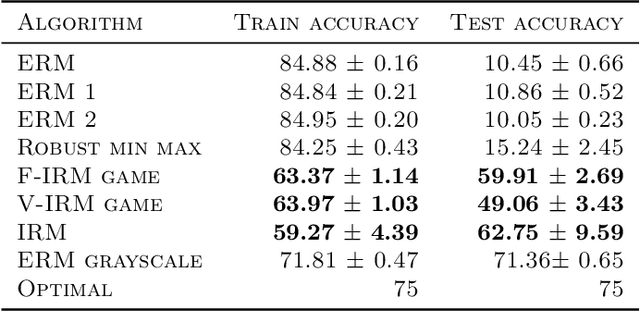
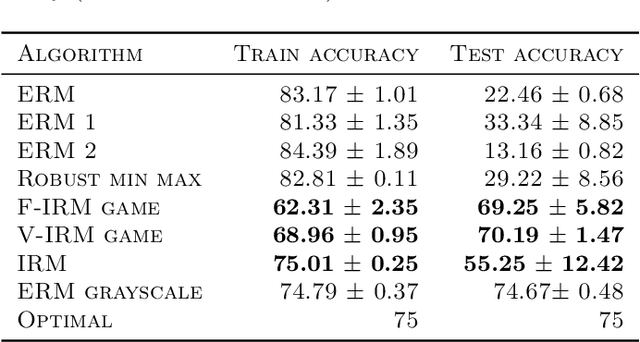
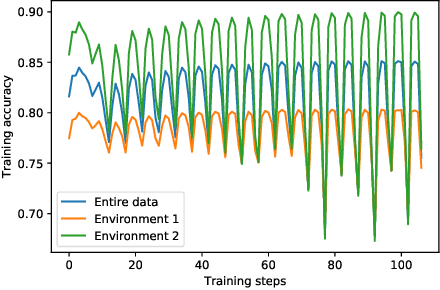
The standard risk minimization paradigm of machine learning is brittle when operating in environments whose test distributions are different from the training distribution due to spurious correlations. Training on data from many environments and finding invariant predictors reduces the effect of spurious features by concentrating models on features that have a causal relationship with the outcome. In this work, we pose such invariant risk minimization as finding the Nash equilibrium of an ensemble game among several environments. By doing so, we develop a simple training algorithm that uses best response dynamics and, in our experiments, yields similar or better empirical accuracy with much lower variance than the challenging bi-level optimization problem of Arjovsky et al. (2019). One key theoretical contribution is showing that the set of Nash equilibria for the proposed game are equivalent to the set of invariant predictors for any finite number of environments, even with nonlinear classifiers and transformations. As a result, our method also retains the generalization guarantees to a large set of environments shown in Arjovsky et al. (2019). The proposed algorithm adds to the collection of successful game-theoretic machine learning algorithms such as generative adversarial networks.
Joint Optimization of AI Fairness and Utility: A Human-Centered Approach
Feb 05, 2020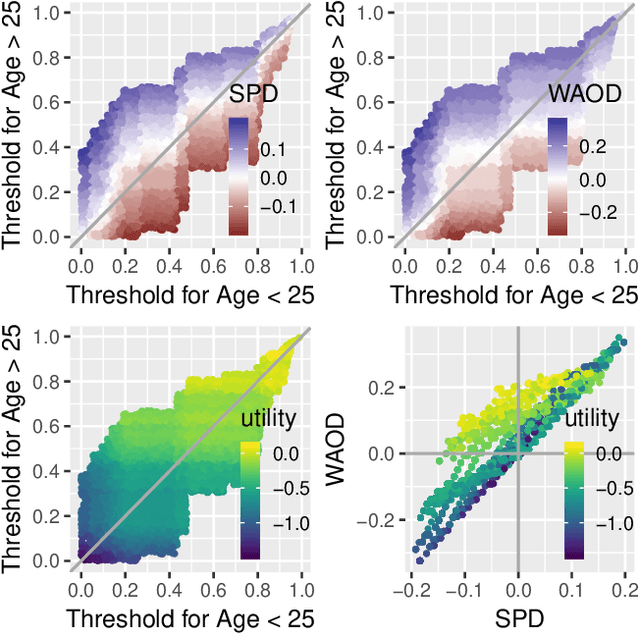
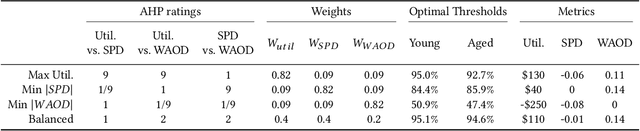
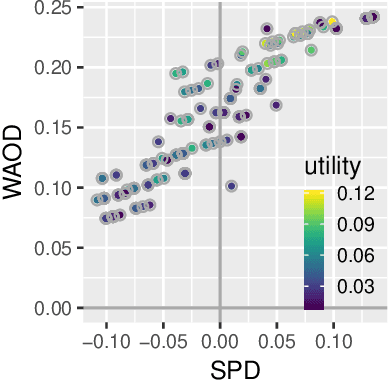

Today, AI is increasingly being used in many high-stakes decision-making applications in which fairness is an important concern. Already, there are many examples of AI being biased and making questionable and unfair decisions. The AI research community has proposed many methods to measure and mitigate unwanted biases, but few of them involve inputs from human policy makers. We argue that because different fairness criteria sometimes cannot be simultaneously satisfied, and because achieving fairness often requires sacrificing other objectives such as model accuracy, it is key to acquire and adhere to human policy makers' preferences on how to make the tradeoff among these objectives. In this paper, we propose a framework and some exemplar methods for eliciting such preferences and for optimizing an AI model according to these preferences.
Drug Repurposing for Cancer: An NLP Approach to Identify Low-Cost Therapies
Dec 05, 2019
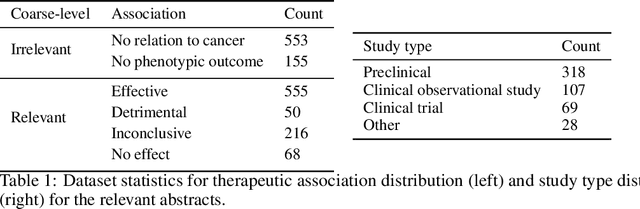
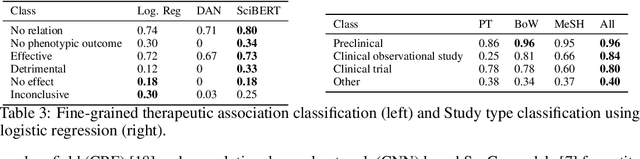
More than 200 generic drugs approved by the U.S. Food and Drug Administration for non-cancer indications have shown promise for treating cancer. Due to their long history of safe patient use, low cost, and widespread availability, repurposing of generic drugs represents a major opportunity to rapidly improve outcomes for cancer patients and reduce healthcare costs worldwide. Evidence on the efficacy of non-cancer generic drugs being tested for cancer exists in scientific publications, but trying to manually identify and extract such evidence is intractable. In this paper, we introduce a system to automate this evidence extraction from PubMed abstracts. Our primary contribution is to define the natural language processing pipeline required to obtain such evidence, comprising the following modules: querying, filtering, cancer type entity extraction, therapeutic association classification, and study type classification. Using the subject matter expertise on our team, we create our own datasets for these specialized domain-specific tasks. We obtain promising performance in each of the modules by utilizing modern language modeling techniques and plan to treat them as baseline approaches for future improvement of individual components.
Preservation of Anomalous Subgroups On Machine Learning Transformed Data
Nov 09, 2019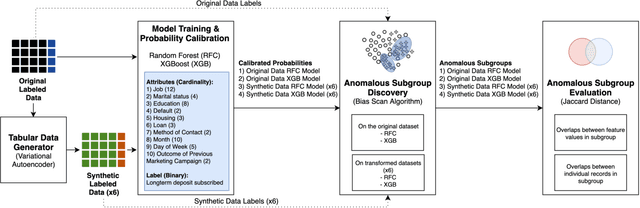
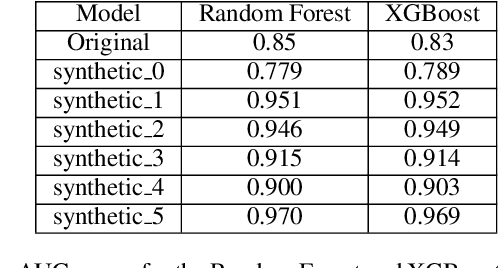
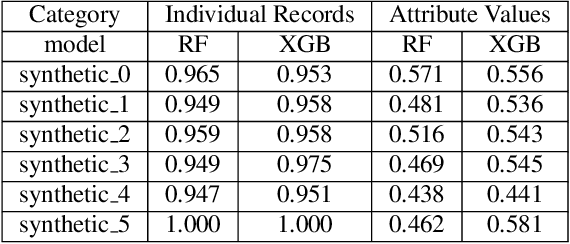
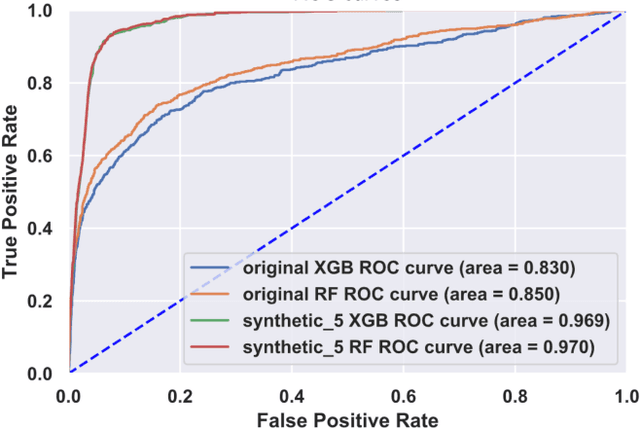
In this paper, we investigate the effect of machine learning based anonymization on anomalous subgroup preservation. In particular, we train a binary classifier to discover the most anomalous subgroup in a dataset by maximizing the bias between the group's predicted odds ratio from the model and observed odds ratio from the data. We then perform anonymization using a variational autoencoder (VAE) to synthesize an entirely new dataset that would ideally be drawn from the distribution of the original data. We repeat the anomalous subgroup discovery task on the new data and compare it to what was identified pre-anonymization. We evaluated our approach using publicly available datasets from the financial industry. Our evaluation confirmed that the approach was able to produce synthetic datasets that preserved a high level of subgroup differentiation as identified initially in the original dataset. Such a distinction was maintained while having distinctly different records between the synthetic and original dataset. Finally, we packed the above end to end process into what we call Utility Guaranteed Deep Privacy (UGDP) system. UGDP can be easily extended to onboard alternative generative approaches such as GANs to synthesize tabular data.
DADI: Dynamic Discovery of Fair Information with Adversarial Reinforcement Learning
Oct 30, 2019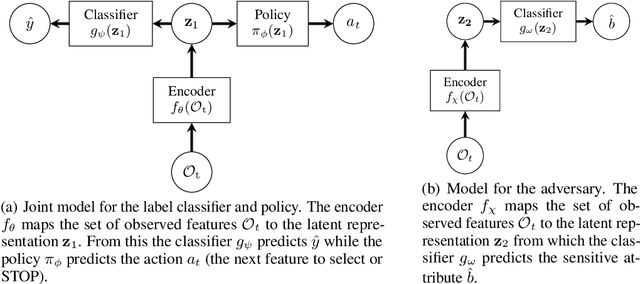
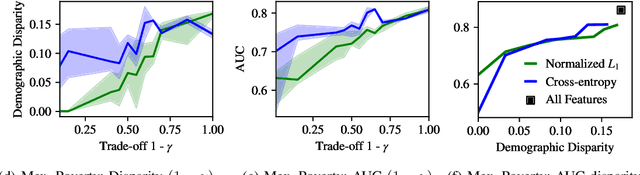
We introduce a framework for dynamic adversarial discovery of information (DADI), motivated by a scenario where information (a feature set) is used by third parties with unknown objectives. We train a reinforcement learning agent to sequentially acquire a subset of the information while balancing accuracy and fairness of predictors downstream. Based on the set of already acquired features, the agent decides dynamically to either collect more information from the set of available features or to stop and predict using the information that is currently available. Building on previous work exploring adversarial representation learning, we attain group fairness (demographic parity) by rewarding the agent with the adversary's loss, computed over the final feature set. Importantly, however, the framework provides a more general starting point for fair or private dynamic information discovery. Finally, we demonstrate empirically, using two real-world datasets, that we can trade-off fairness and predictive performance
Estimating Skin Tone and Effects on Classification Performance in Dermatology Datasets
Oct 29, 2019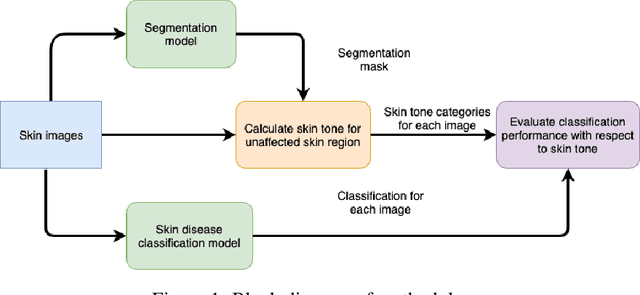
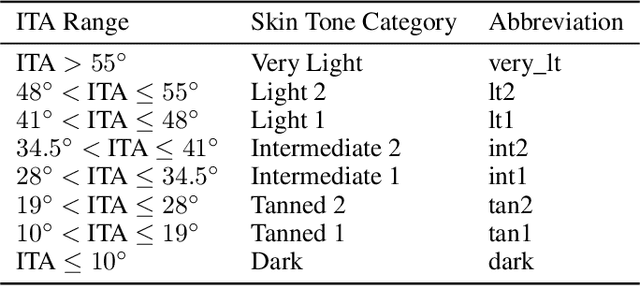
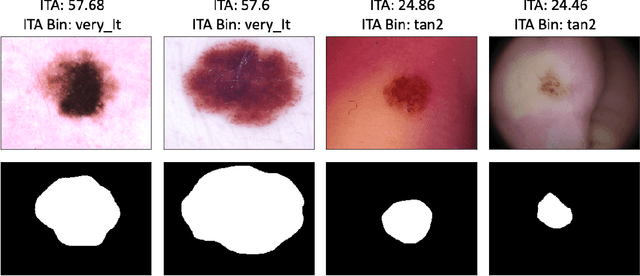

Recent advances in computer vision and deep learning have led to breakthroughs in the development of automated skin image analysis. In particular, skin cancer classification models have achieved performance higher than trained expert dermatologists. However, no attempt has been made to evaluate the consistency in performance of machine learning models across populations with varying skin tones. In this paper, we present an approach to estimate skin tone in benchmark skin disease datasets, and investigate whether model performance is dependent on this measure. Specifically, we use individual typology angle (ITA) to approximate skin tone in dermatology datasets. We look at the distribution of ITA values to better understand skin color representation in two benchmark datasets: 1) the ISIC 2018 Challenge dataset, a collection of dermoscopic images of skin lesions for the detection of skin cancer, and 2) the SD-198 dataset, a collection of clinical images capturing a wide variety of skin diseases. To estimate ITA, we first develop segmentation models to isolate non-diseased areas of skin. We find that the majority of the data in the the two datasets have ITA values between 34.5{\deg} and 48{\deg}, which are associated with lighter skin, and is consistent with under-representation of darker skinned populations in these datasets. We also find no measurable correlation between performance of machine learning model and ITA values, though more comprehensive data is needed for further validation.
An Information-Theoretic Perspective on the Relationship Between Fairness and Accuracy
Oct 17, 2019
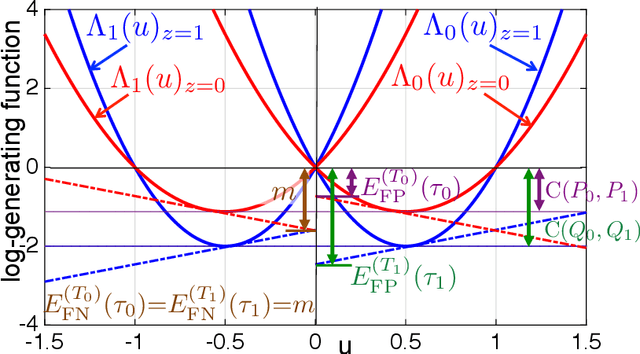
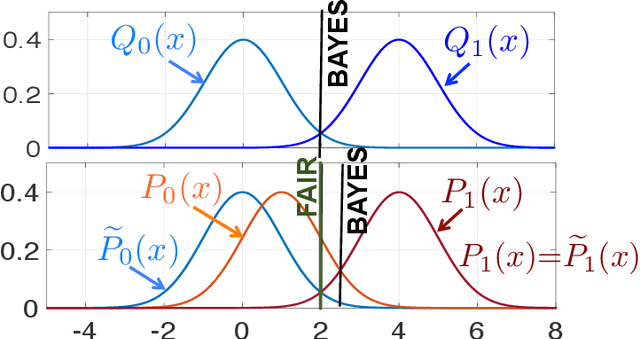
Our goal is to understand the so-called trade-off between fairness and accuracy. In this work, using a tool from information theory called Chernoff information, we derive fundamental limits on this relationship that explain why the accuracy on a given dataset often decreases as fairness increases. Novel to this work, we examine the problem of fair classification through the lens of a mismatched hypothesis testing problem, i.e., where we are trying to find a classifier that distinguishes between two "ideal" distributions but instead we are given two mismatched distributions that are biased. Based on this perspective, we contend that measuring accuracy with respect to the given (possibly biased) dataset is a problematic measure of performance. Instead one should also consider accuracy with respect to an ideal dataset that is unbiased. We formulate an optimization to find such ideal distributions and show that the optimization is feasible. Lastly, when the Chernoff information for one group is strictly less than another in the given dataset, we derive the information-theoretic criterion under which collection of more features can actually improve the Chernoff information and achieve fairness without compromising accuracy on the available data.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019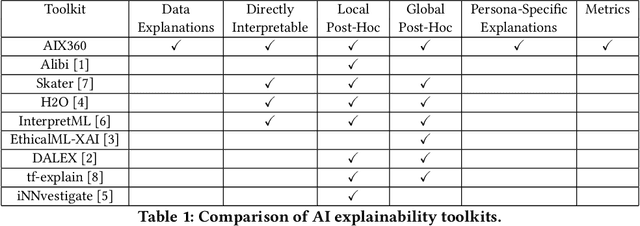
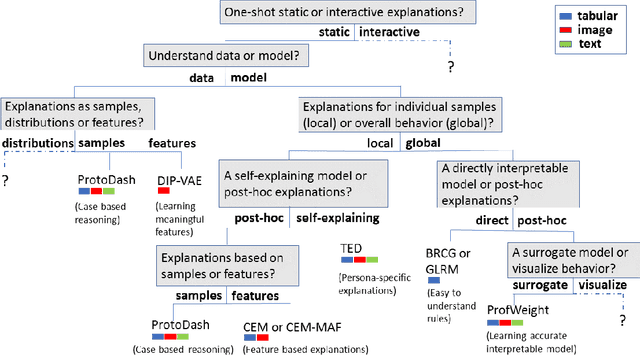
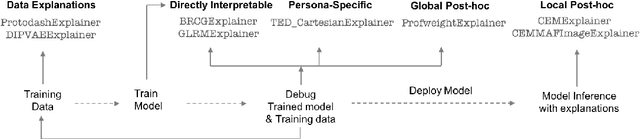
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
How Data Scientists Work Together With Domain Experts in Scientific Collaborations: To Find The Right Answer Or To Ask The Right Question?
Sep 08, 2019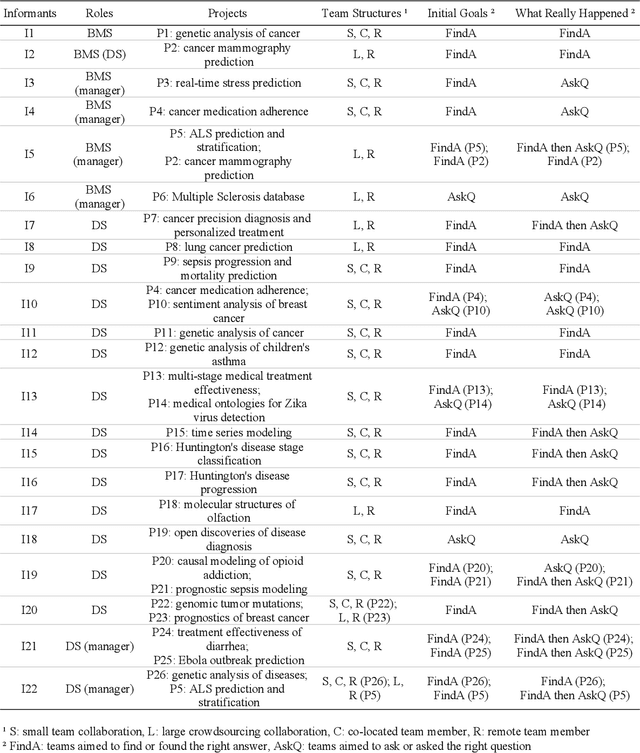

In recent years there has been an increasing trend in which data scientists and domain experts work together to tackle complex scientific questions. However, such collaborations often face challenges. In this paper, we aim to decipher this collaboration complexity through a semi-structured interview study with 22 interviewees from teams of bio-medical scientists collaborating with data scientists. In the analysis, we adopt the Olsons' four-dimensions framework proposed in Distance Matters to code interview transcripts. Our findings suggest that besides the glitches in the collaboration readiness, technology readiness, and coupling of work dimensions, the tensions that exist in the common ground building process influence the collaboration outcomes, and then persist in the actual collaboration process. In contrast to prior works' general account of building a high level of common ground, the breakdowns of content common ground together with the strengthen of process common ground in this process is more beneficial for scientific discovery. We discuss why that is and what the design suggestions are, and conclude the paper with future directions and limitations.