 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered Explainable AI (XAI): From Algorithms to User Experiences
Oct 23, 2021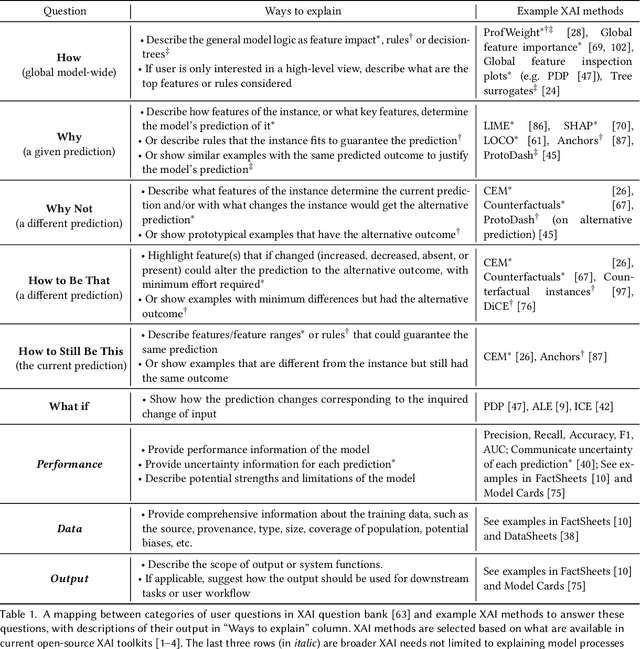
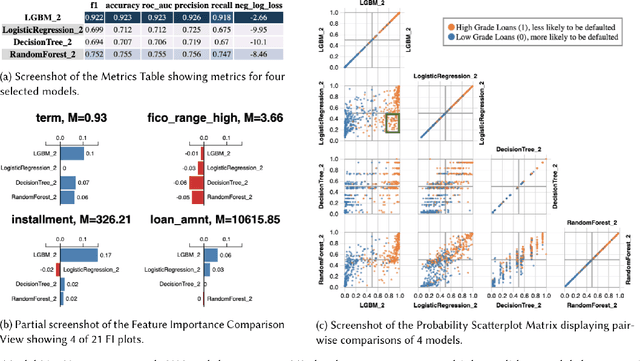
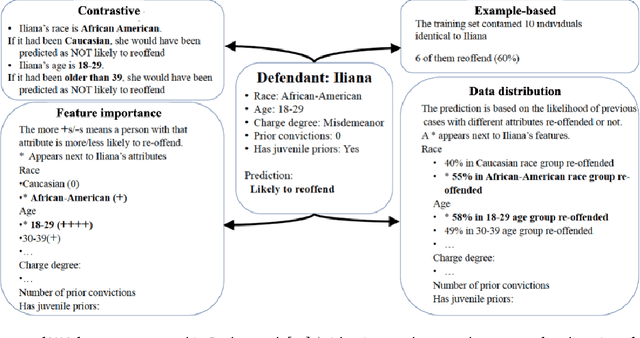
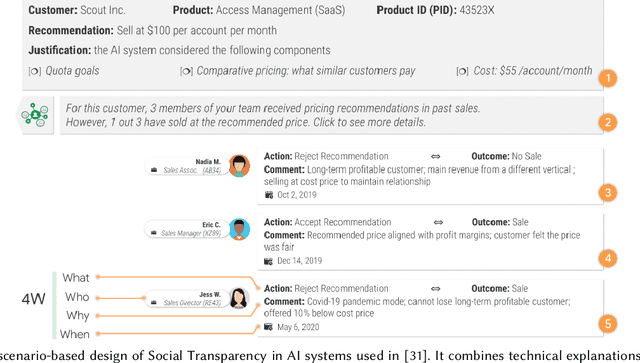
As a technical sub-field of artificial intelligence (AI), explainable AI (XAI) has produced a vast collection of algorithms, providing a toolbox for researchers and practitioners to build XAI applications. With the rich application opportunities, explainability has moved beyond a demand by data scientists or researchers to comprehend the models they are developing, to become an essential requirement for people to trust and adopt AI deployed in numerous domains. However, explainability is an inherently human-centric property and the field is starting to embrace human-centered approaches. Human-computer interaction (HCI) research and user experience (UX) design in this area are becoming increasingly important. In this chapter, we begin with a high-level overview of the technical landscape of XAI algorithms, then selectively survey our own and other recent HCI works that take human-centered approaches to design, evaluate, provide conceptual and methodological tools for XAI. We ask the question "\textit{what are human-centered approaches doing for XAI}" and highlight three roles that they play in shaping XAI technologies by helping navigate, assess and expand the XAI toolbox: to drive technical choices by users' explainability needs, to uncover pitfalls of existing XAI methods and inform new methods, and to provide conceptual frameworks for human-compatible XAI.
An Empirical Study of Accuracy, Fairness, Explainability, Distributional Robustness, and Adversarial Robustness
Sep 29, 2021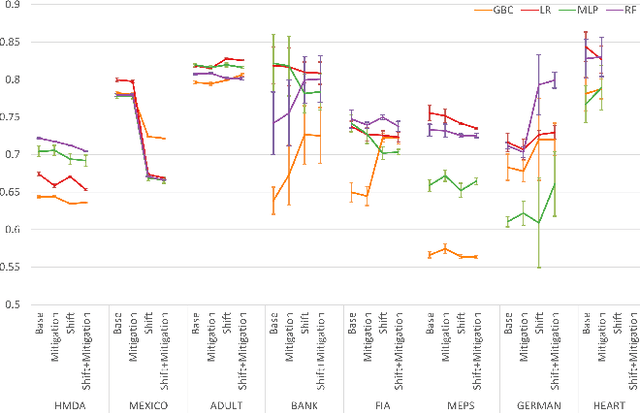
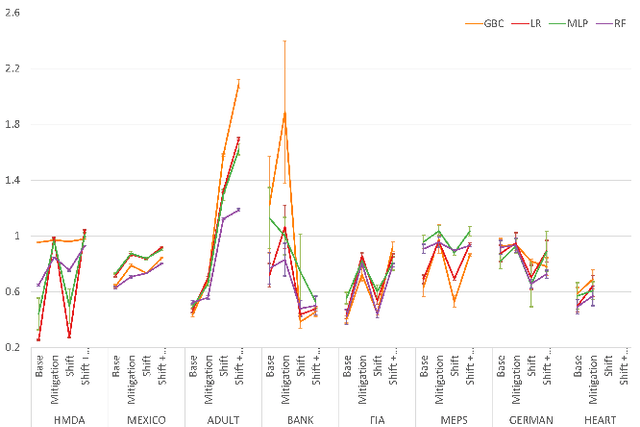
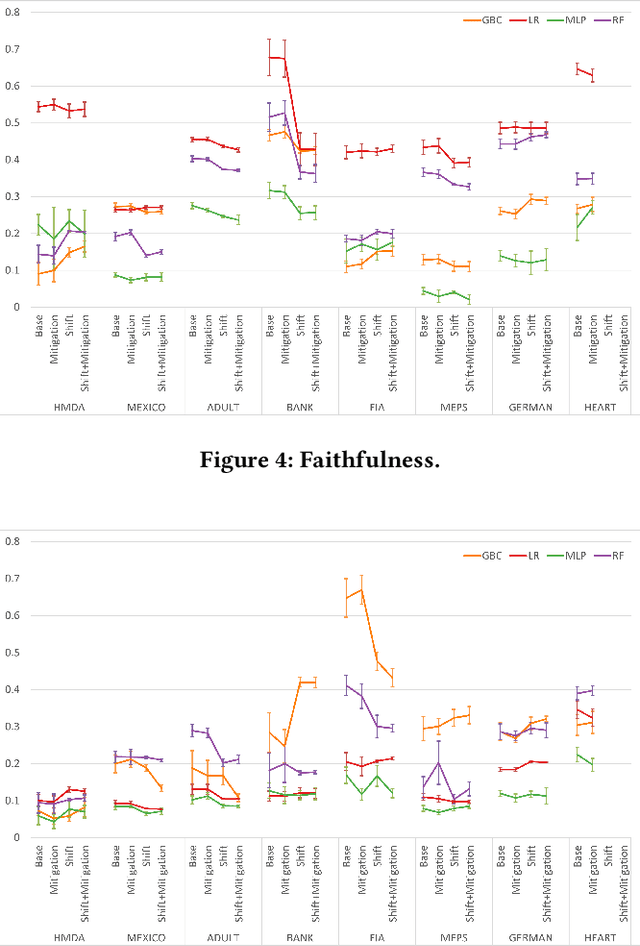
To ensure trust in AI models, it is becoming increasingly apparent that evaluation of models must be extended beyond traditional performance metrics, like accuracy, to other dimensions, such as fairness, explainability, adversarial robustness, and distribution shift. We describe an empirical study to evaluate multiple model types on various metrics along these dimensions on several datasets. Our results show that no particular model type performs well on all dimensions, and demonstrate the kinds of trade-offs involved in selecting models evaluated along multiple dimensions.
AI Explainability 360: Impact and Design
Sep 24, 2021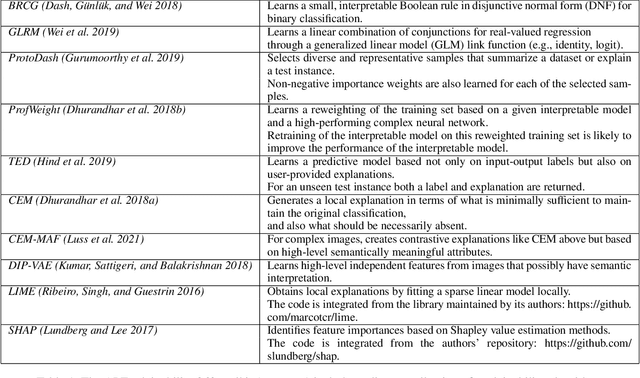
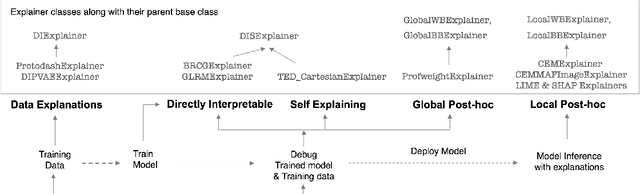

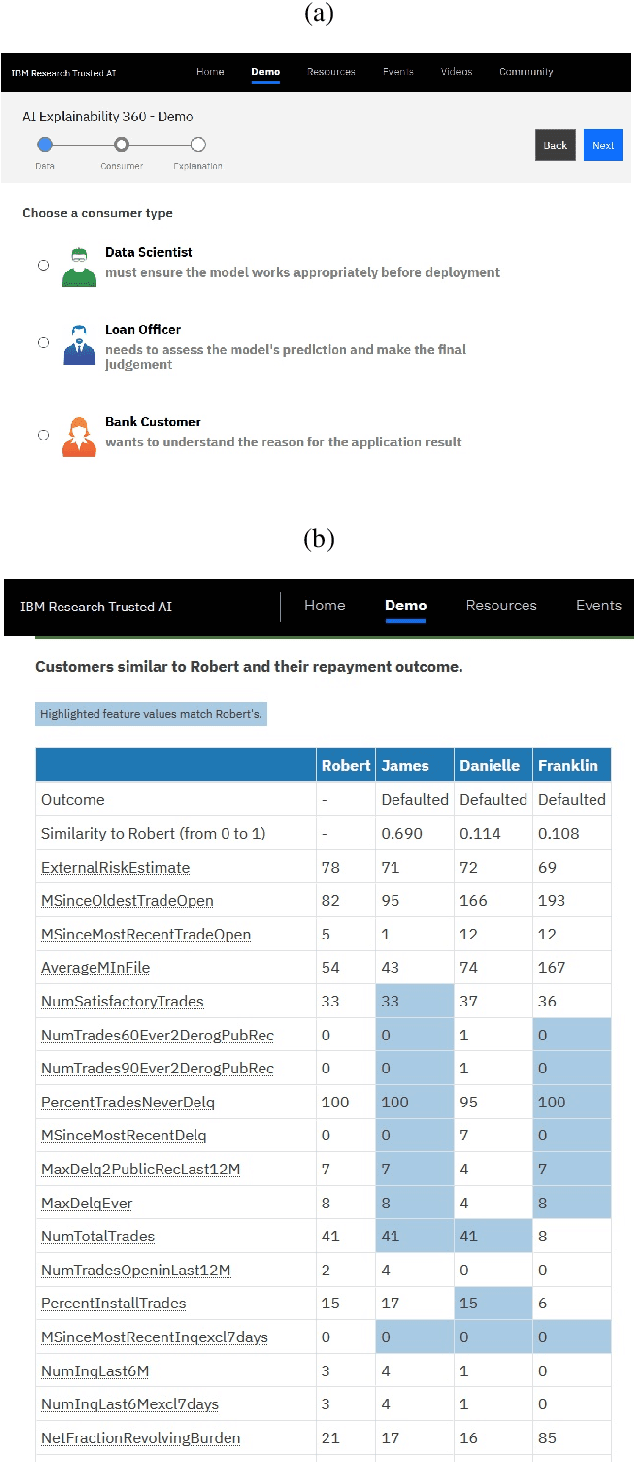
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Towards Interpreting Zoonotic Potential of Betacoronavirus Sequences With Attention
Aug 18, 2021
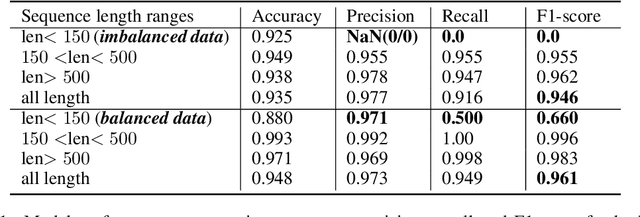
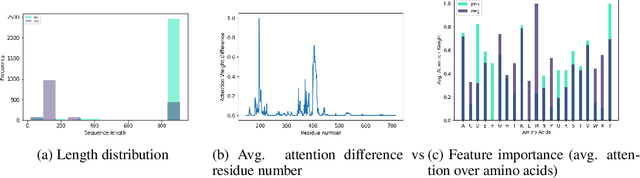
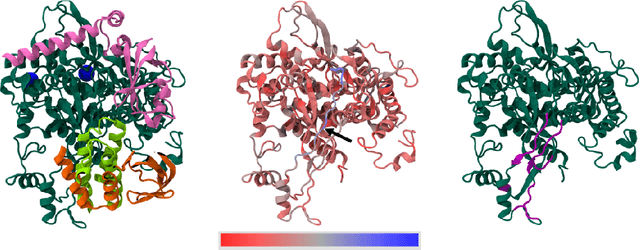
Current methods for viral discovery target evolutionarily conserved proteins that accurately identify virus families but remain unable to distinguish the zoonotic potential of newly discovered viruses. Here, we apply an attention-enhanced long-short-term memory (LSTM) deep neural net classifier to a highly conserved viral protein target to predict zoonotic potential across betacoronaviruses. The classifier performs with a 94% accuracy. Analysis and visualization of attention at the sequence and structure-level features indicate possible association between important protein-protein interactions governing viral replication in zoonotic betacoronaviruses and zoonotic transmission.
Biomedical Interpretable Entity Representations
Jun 17, 2021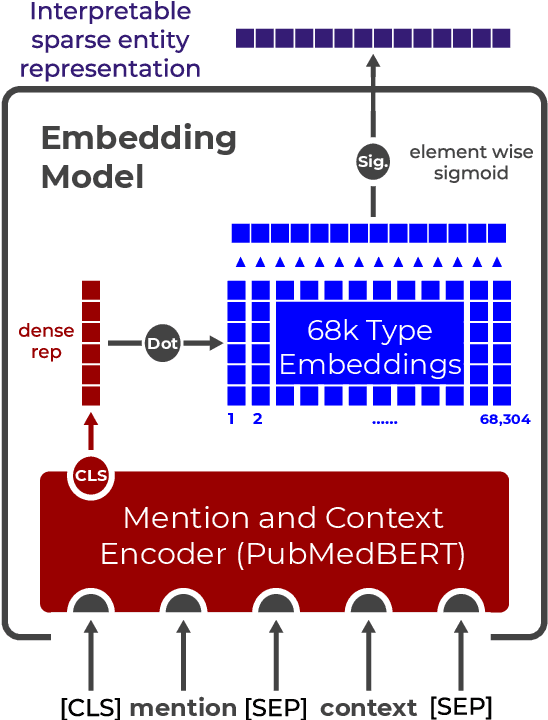
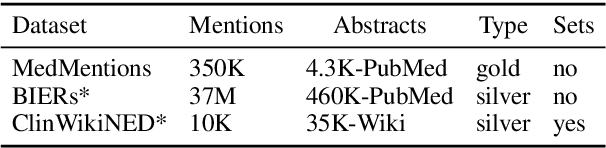
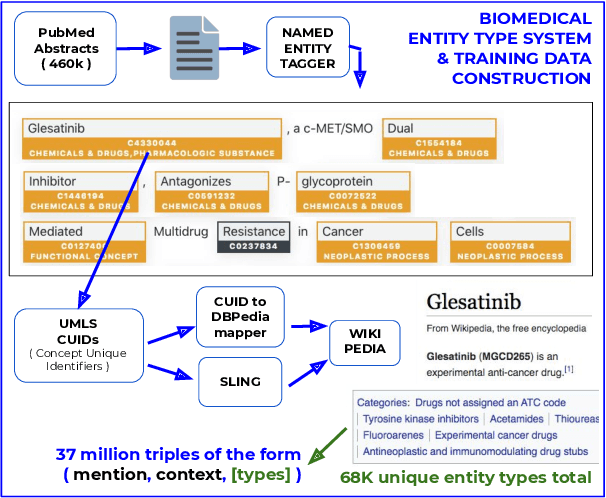
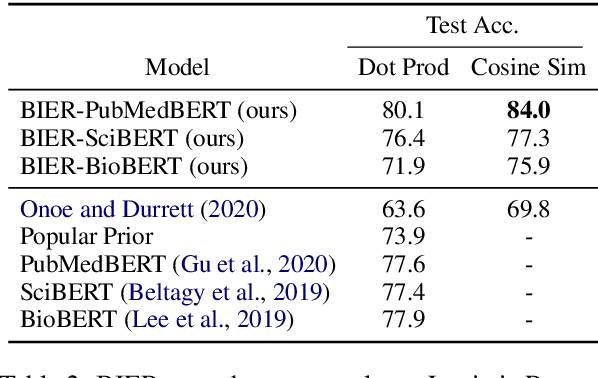
Pre-trained language models induce dense entity representations that offer strong performance on entity-centric NLP tasks, but such representations are not immediately interpretable. This can be a barrier to model uptake in important domains such as biomedicine. There has been recent work on general interpretable representation learning (Onoe and Durrett, 2020), but these domain-agnostic representations do not readily transfer to the important domain of biomedicine. In this paper, we create a new entity type system and training set from a large corpus of biomedical texts by mapping entities to concepts in a medical ontology, and from these to Wikipedia pages whose categories are our types. From this mapping we derive Biomedical Interpretable Entity Representations(BIERs), in which dimensions correspond to fine-grained entity types, and values are predicted probabilities that a given entity is of the corresponding type. We propose a novel method that exploits BIER's final sparse and intermediate dense representations to facilitate model and entity type debugging. We show that BIERs achieve strong performance in biomedical tasks including named entity disambiguation and entity label classification, and we provide error analysis to highlight the utility of their interpretability, particularly in low-supervision settings. Finally, we provide our induced 68K biomedical type system, the corresponding 37 million triples of derived data used to train BIER models and our best performing model.
Uncertainty Quantification 360: A Holistic Toolkit for Quantifying and Communicating the Uncertainty of AI
Jun 04, 2021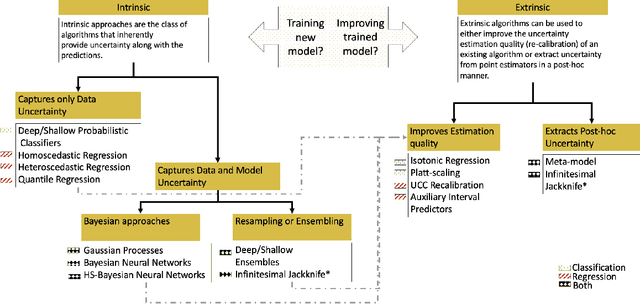
In this paper, we describe an open source Python toolkit named Uncertainty Quantification 360 (UQ360) for the uncertainty quantification of AI models. The goal of this toolkit is twofold: first, to provide a broad range of capabilities to streamline as well as foster the common practices of quantifying, evaluating, improving, and communicating uncertainty in the AI application development lifecycle; second, to encourage further exploration of UQ's connections to other pillars of trustworthy AI such as fairness and transparency through the dissemination of latest research and education materials. Beyond the Python package (\url{https://github.com/IBM/UQ360}), we have developed an interactive experience (\url{http://uq360.mybluemix.net}) and guidance materials as educational tools to aid researchers and developers in producing and communicating high-quality uncertainties in an effective manner.
Socially Responsible AI Algorithms: Issues, Purposes, and Challenges
Jan 12, 2021
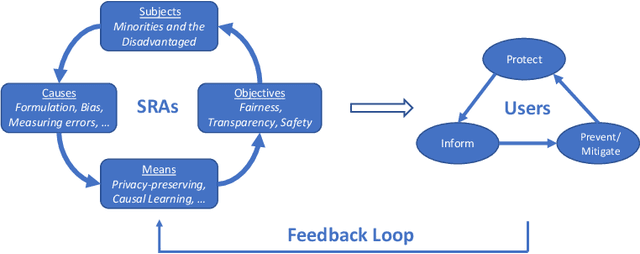

In the current era, people and society have grown increasingly reliant on Artificial Intelligence (AI) technologies. AI has the potential to drive us towards a future in which all of humanity flourishes. It also comes with substantial risks for oppression and calamity. Discussions about whether we should (re)trust AI have repeatedly emerged in recent years and in many quarters, including industry, academia, health care, services, and so on. Technologists and AI researchers have a responsibility to develop trustworthy AI systems. They have responded with great efforts of designing more responsible AI algorithms. However, existing technical solutions are narrow in scope and have been primarily directed towards algorithms for scoring or classification tasks, with an emphasis on fairness and unwanted bias. To build long-lasting trust between AI and human beings, we argue that the key is to think beyond algorithmic fairness and connect major aspects of AI that potentially cause AI's indifferent behavior. In this survey, we provide a systematic framework of Socially Responsible AI Algorithms that aims to examine the subjects of AI indifference and the need for socially responsible AI algorithms, define the objectives, and introduce the means by which we may achieve these objectives. We further discuss how to leverage this framework to improve societal well-being through protection, information, and prevention/mitigation.
Learning to Initialize Gradient Descent Using Gradient Descent
Dec 22, 2020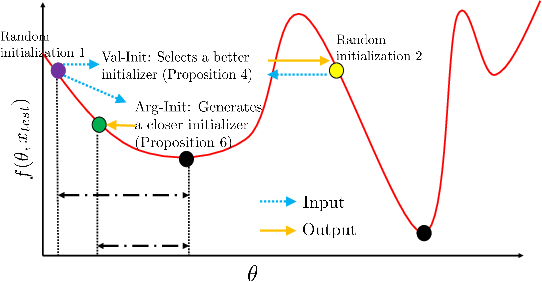
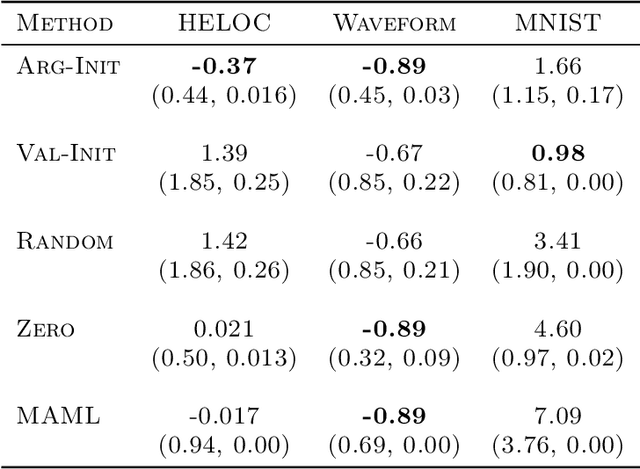
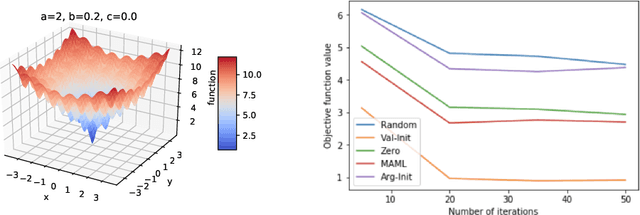
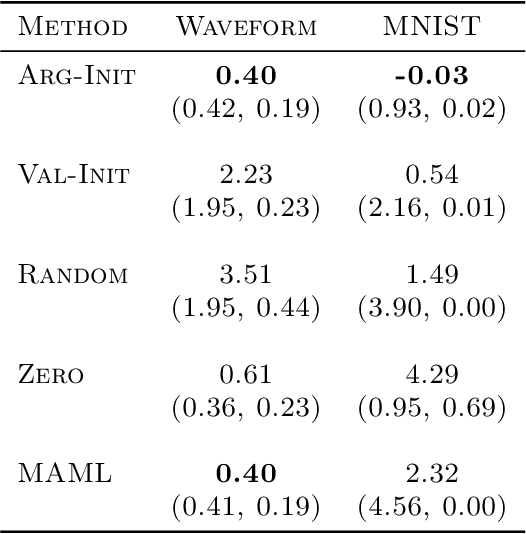
Non-convex optimization problems are challenging to solve; the success and computational expense of a gradient descent algorithm or variant depend heavily on the initialization strategy. Often, either random initialization is used or initialization rules are carefully designed by exploiting the nature of the problem class. As a simple alternative to hand-crafted initialization rules, we propose an approach for learning "good" initialization rules from previous solutions. We provide theoretical guarantees that establish conditions that are sufficient in all cases and also necessary in some under which our approach performs better than random initialization. We apply our methodology to various non-convex problems such as generating adversarial examples, generating post hoc explanations for black-box machine learning models, and allocating communication spectrum, and show consistent gains over other initialization techniques.
Empirical or Invariant Risk Minimization? A Sample Complexity Perspective
Oct 30, 2020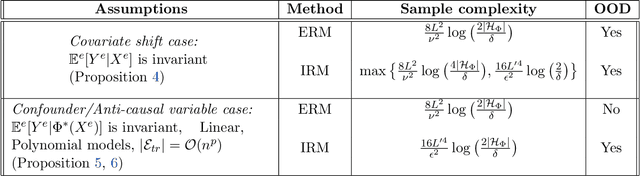
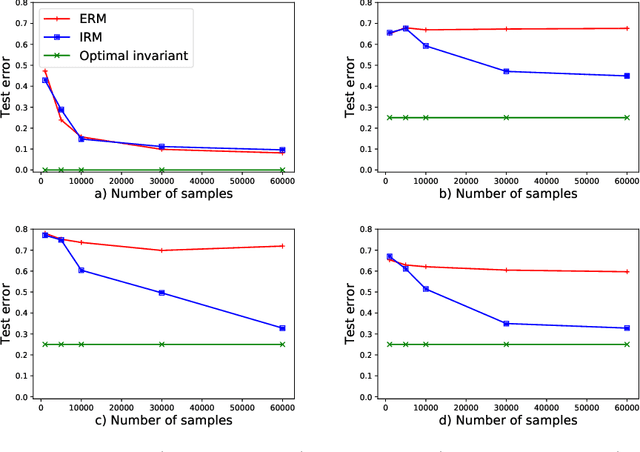
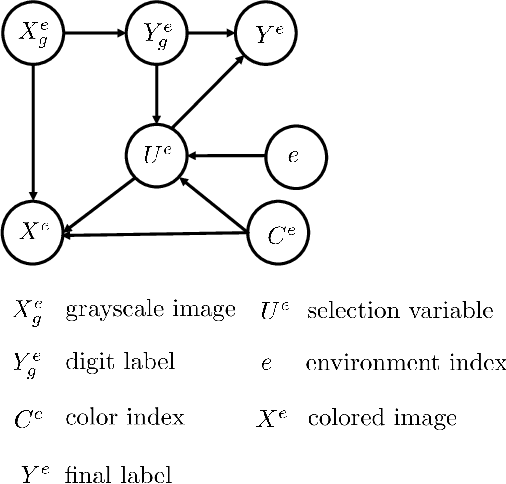
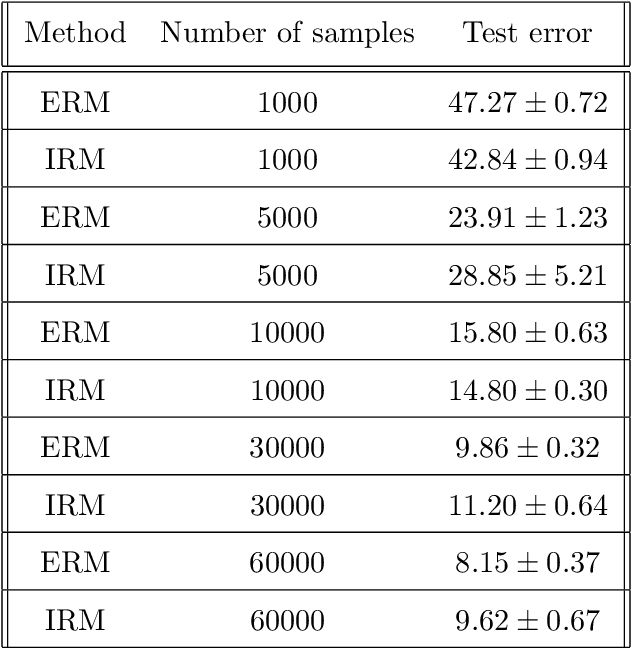
Recently, invariant risk minimization (IRM) was proposed as a promising solution to address out-of-distribution (OOD) generalization. However, it is unclear when IRM should be preferred over the widely-employed empirical risk minimization (ERM) framework. In this work, we analyze both these frameworks from the perspective of sample complexity, thus taking a firm step towards answering this important question. We find that depending on the type of data generation mechanism, the two approaches might have very different finite sample and asymptotic behavior. For example, in the covariate shift setting we see that the two approaches not only arrive at the same asymptotic solution, but also have similar finite sample behavior with no clear winner. For other distribution shifts such as those involving confounders or anti-causal variables, however, the two approaches arrive at different asymptotic solutions where IRM is guaranteed to be close to the desired OOD solutions in the finite sample regime, while ERM is biased even asymptotically. We further investigate how different factors -- the number of environments, complexity of the model, and IRM penalty weight -- impact the sample complexity of IRM in relation to its distance from the OOD solutions
Deciding Fast and Slow: The Role of Cognitive Biases in AI-assisted Decision-making
Oct 15, 2020
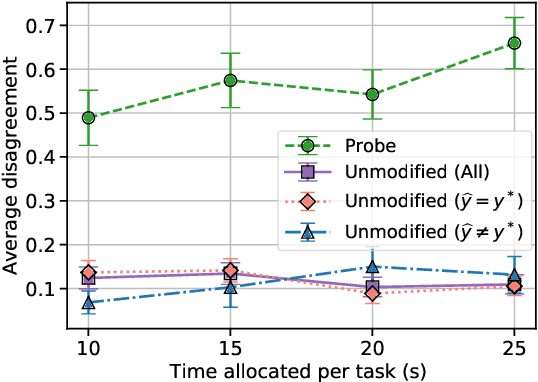
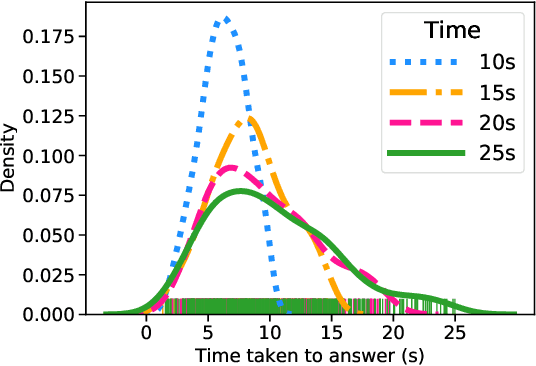
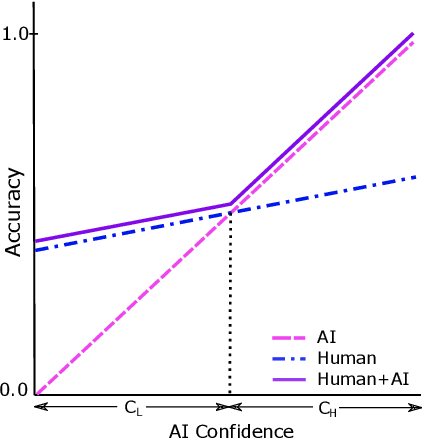
Several strands of research have aimed to bridge the gap between artificial intelligence (AI) and human decision-makers in AI-assisted decision-making, where humans are the consumers of AI model predictions and the ultimate decision-makers in high-stakes applications. However, people's perception and understanding is often distorted by their cognitive biases, like confirmation bias, anchoring bias, availability bias, to name a few. In this work, we use knowledge from the field of cognitive science to account for cognitive biases in the human-AI collaborative decision-making system and mitigate their negative effects. To this end, we mathematically model cognitive biases and provide a general framework through which researchers and practitioners can understand the interplay between cognitive biases and human-AI accuracy. We then focus on anchoring bias, a bias commonly witnessed in human-AI partnerships. We devise a cognitive science-driven, time-based approach to de-anchoring. A user experiment shows the effectiveness of this approach in human-AI collaborative decision-making. Using the results from this first experiment, we design a time allocation strategy for a resource constrained setting so as to achieve optimal human-AI collaboration under some assumptions. A second user study shows that our time allocation strategy can effectively debias the human when the AI model has low confidence and is incorrect.