 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGP-MoLFormer-Sim: Test Time Molecular Optimization through Contextual Similarity Guidance
Jun 05, 2025The ability to design molecules while preserving similarity to a target molecule and/or property is crucial for various applications in drug discovery, chemical design, and biology. We introduce in this paper an efficient training-free method for navigating and sampling from the molecular space with a generative Chemical Language Model (CLM), while using the molecular similarity to the target as a guide. Our method leverages the contextual representations learned from the CLM itself to estimate the molecular similarity, which is then used to adjust the autoregressive sampling strategy of the CLM. At each step of the decoding process, the method tracks the distance of the current generations from the target and updates the logits to encourage the preservation of similarity in generations. We implement the method using a recently proposed $\sim$47M parameter SMILES-based CLM, GP-MoLFormer, and therefore refer to the method as GP-MoLFormer-Sim, which enables a test-time update of the deep generative policy to reflect the contextual similarity to a set of guide molecules. The method is further integrated into a genetic algorithm (GA) and tested on a set of standard molecular optimization benchmarks involving property optimization, molecular rediscovery, and structure-based drug design. Results show that, GP-MoLFormer-Sim, combined with GA (GP-MoLFormer-Sim+GA) outperforms existing training-free baseline methods, when the oracle remains black-box. The findings in this work are a step forward in understanding and guiding the generative mechanisms of CLMs.
Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
May 28, 2025We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
Distributional Preference Alignment of LLMs via Optimal Transport
Jun 09, 2024



Current LLM alignment techniques use pairwise human preferences at a sample level, and as such, they do not imply an alignment on the distributional level. We propose in this paper Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT aligns LLMs on unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. We introduce a convex relaxation of this first-order stochastic dominance and cast it as an optimal transport problem with a smooth and convex cost. Thanks to the one-dimensional nature of the resulting optimal transport problem and the convexity of the cost, it has a closed-form solution via sorting on empirical measures. We fine-tune LLMs with this AOT objective, which enables alignment by penalizing the violation of the stochastic dominance of the reward distribution of the positive samples on the reward distribution of the negative samples. We analyze the sample complexity of AOT by considering the dual of the OT problem and show that it converges at the parametric rate. Empirically, we show on a diverse set of alignment datasets and LLMs that AOT leads to state-of-the-art models in the 7B family of models when evaluated with Open LLM Benchmarks and AlpacaEval.
Risk Assessment and Statistical Significance in the Age of Foundation Models
Oct 11, 2023



We propose a distributional framework for assessing socio-technical risks of foundation models with quantified statistical significance. Our approach hinges on a new statistical relative testing based on first and second order stochastic dominance of real random variables. We show that the second order statistics in this test are linked to mean-risk models commonly used in econometrics and mathematical finance to balance risk and utility when choosing between alternatives. Using this framework, we formally develop a risk-aware approach for foundation model selection given guardrails quantified by specified metrics. Inspired by portfolio optimization and selection theory in mathematical finance, we define a \emph{metrics portfolio} for each model as a means to aggregate a collection of metrics, and perform model selection based on the stochastic dominance of these portfolios. The statistical significance of our tests is backed theoretically by an asymptotic analysis via central limit theorems instantiated in practice via a bootstrap variance estimate. We use our framework to compare various large language models regarding risks related to drifting from instructions and outputting toxic content.
Assessment of Prediction Intervals Using Uncertainty Characteristics Curves
Oct 04, 2023



Accurate quantification of model uncertainty has long been recognized as a fundamental requirement for trusted AI. In regression tasks, uncertainty is typically quantified using prediction intervals calibrated to an ad-hoc operating point, making evaluation and comparison across different studies relatively difficult. Our work leverages: (1) the concept of operating characteristics curves and (2) the notion of a gain over a null reference, to derive a novel operating point agnostic assessment methodology for prediction intervals. The paper defines the Uncertainty Characteristics Curve and demonstrates its utility in selected scenarios. We argue that the proposed method addresses the current need for comprehensive assessment of prediction intervals and thus represents a valuable addition to the uncertainty quantification toolbox.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Uncertainty Quantification 360: A Holistic Toolkit for Quantifying and Communicating the Uncertainty of AI
Jun 04, 2021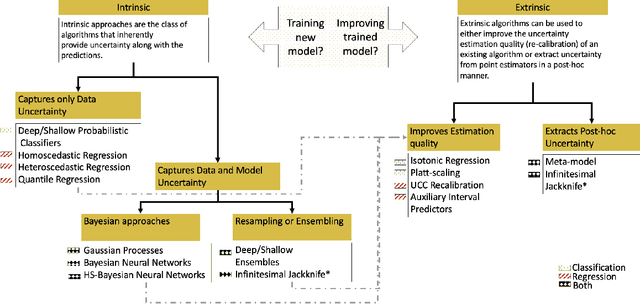
In this paper, we describe an open source Python toolkit named Uncertainty Quantification 360 (UQ360) for the uncertainty quantification of AI models. The goal of this toolkit is twofold: first, to provide a broad range of capabilities to streamline as well as foster the common practices of quantifying, evaluating, improving, and communicating uncertainty in the AI application development lifecycle; second, to encourage further exploration of UQ's connections to other pillars of trustworthy AI such as fairness and transparency through the dissemination of latest research and education materials. Beyond the Python package (\url{https://github.com/IBM/UQ360}), we have developed an interactive experience (\url{http://uq360.mybluemix.net}) and guidance materials as educational tools to aid researchers and developers in producing and communicating high-quality uncertainties in an effective manner.
Uncertainty Characteristics Curves: A Systematic Assessment of Prediction Intervals
Jun 01, 2021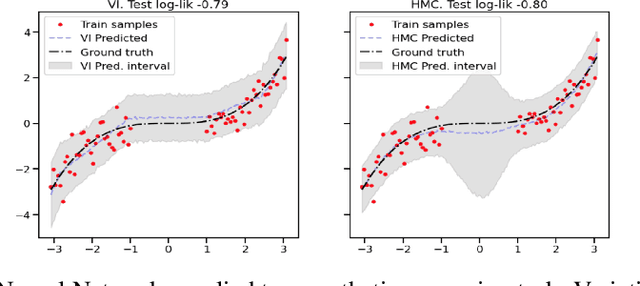
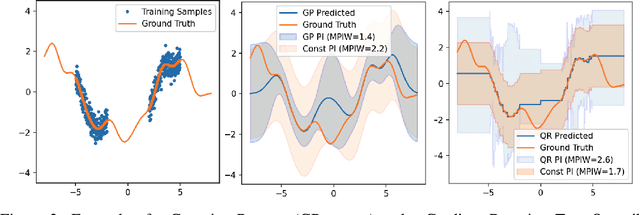

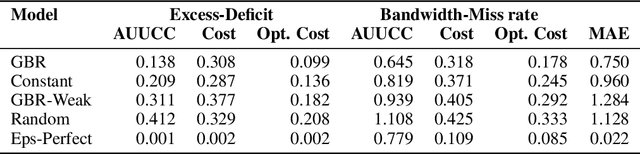
Accurate quantification of model uncertainty has long been recognized as a fundamental requirement for trusted AI. In regression tasks, uncertainty is typically quantified using prediction intervals calibrated to a specific operating point, making evaluation and comparison across different studies difficult. Our work leverages: (1) the concept of operating characteristics curves and (2) the notion of a gain over a simple reference, to derive a novel operating point agnostic assessment methodology for prediction intervals. The paper describes the corresponding algorithm, provides a theoretical analysis, and demonstrates its utility in multiple scenarios. We argue that the proposed method addresses the current need for comprehensive assessment of prediction intervals and thus represents a valuable addition to the uncertainty quantification toolbox.
Learning Prediction Intervals for Model Performance
Dec 15, 2020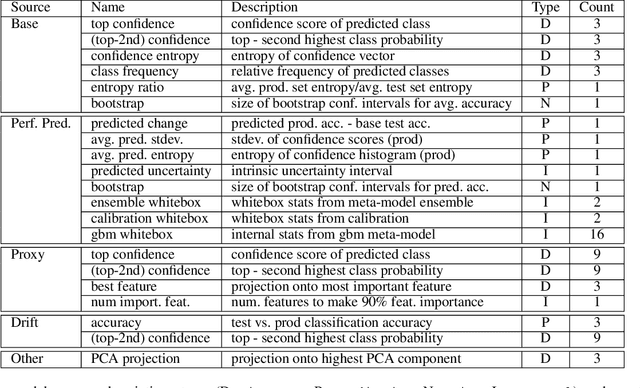
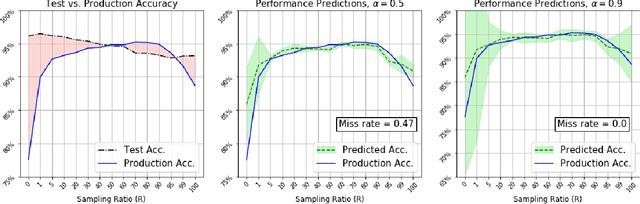
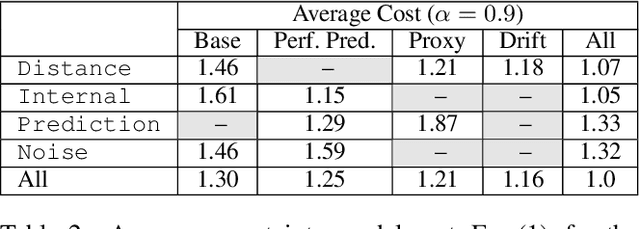
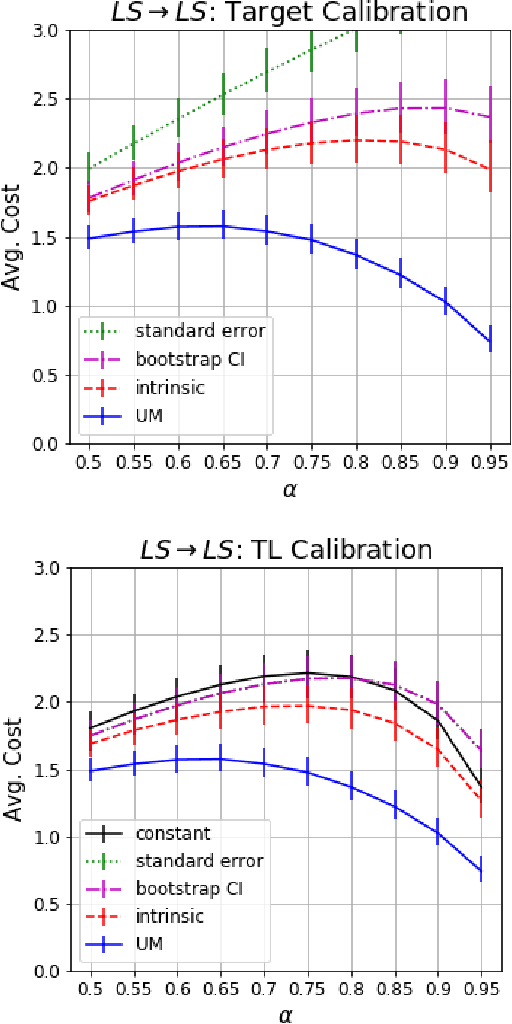
Understanding model performance on unlabeled data is a fundamental challenge of developing, deploying, and maintaining AI systems. Model performance is typically evaluated using test sets or periodic manual quality assessments, both of which require laborious manual data labeling. Automated performance prediction techniques aim to mitigate this burden, but potential inaccuracy and a lack of trust in their predictions has prevented their widespread adoption. We address this core problem of performance prediction uncertainty with a method to compute prediction intervals for model performance. Our methodology uses transfer learning to train an uncertainty model to estimate the uncertainty of model performance predictions. We evaluate our approach across a wide range of drift conditions and show substantial improvement over competitive baselines. We believe this result makes prediction intervals, and performance prediction in general, significantly more practical for real-world use.
Not Your Grandfathers Test Set: Reducing Labeling Effort for Testing
Jul 10, 2020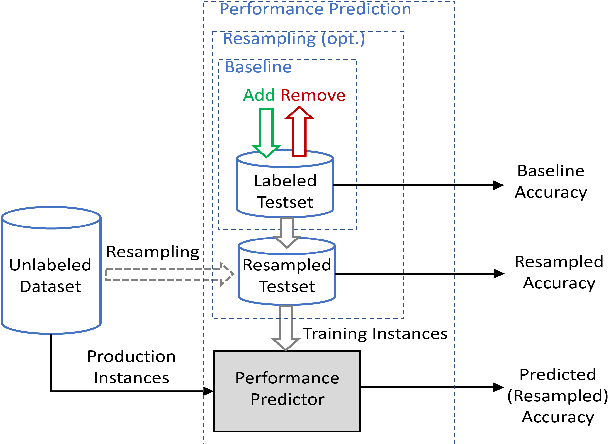

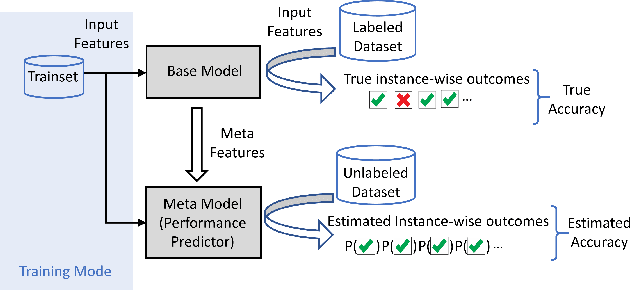

Building and maintaining high-quality test sets remains a laborious and expensive task. As a result, test sets in the real world are often not properly kept up to date and drift from the production traffic they are supposed to represent. The frequency and severity of this drift raises serious concerns over the value of manually labeled test sets in the QA process. This paper proposes a simple but effective technique that drastically reduces the effort needed to construct and maintain a high-quality test set (reducing labeling effort by 80-100% across a range of practical scenarios). This result encourages a fundamental rethinking of the testing process by both practitioners, who can use these techniques immediately to improve their testing, and researchers who can help address many of the open questions raised by this new approach.