 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Closed-Source LLM's Knowledge for Locally Stable and Economic Biomedical Entity Linking
May 26, 2025Biomedical entity linking aims to map nonstandard entities to standard entities in a knowledge base. Traditional supervised methods perform well but require extensive annotated data to transfer, limiting their usage in low-resource scenarios. Large language models (LLMs), especially closed-source LLMs, can address these but risk stability issues and high economic costs: using these models is restricted by commercial companies and brings significant economic costs when dealing with large amounts of data. To address this, we propose ``RPDR'', a framework combining closed-source LLMs and open-source LLMs for re-ranking candidates retrieved by a retriever fine-tuned with a small amount of data. By prompting a closed-source LLM to generate training data from unannotated data and fine-tuning an open-source LLM for re-ranking, we effectively distill the knowledge to the open-source LLM that can be deployed locally, thus avoiding the stability issues and the problem of high economic costs. We evaluate RPDR on two datasets, including one real-world dataset and one publicly available dataset involving two languages: Chinese and English. RPDR achieves 0.019 Acc@1 improvement and 0.036 Acc@1 improvement on the Aier dataset and the Ask A Patient dataset when the amount of training data is not enough. The results demonstrate the superiority and generalizability of the proposed framework.
Dual-Agent Reinforcement Learning for Automated Feature Generation
May 19, 2025Feature generation involves creating new features from raw data to capture complex relationships among the original features, improving model robustness and machine learning performance. Current methods using reinforcement learning for feature generation have made feature exploration more flexible and efficient. However, several challenges remain: first, during feature expansion, a large number of redundant features are generated. When removing them, current methods only retain the best features each round, neglecting those that perform poorly initially but could improve later. Second, the state representation used by current methods fails to fully capture complex feature relationships. Third, there are significant differences between discrete and continuous features in tabular data, requiring different operations for each type. To address these challenges, we propose a novel dual-agent reinforcement learning method for feature generation. Two agents are designed: the first generates new features, and the second determines whether they should be preserved. A self-attention mechanism enhances state representation, and diverse operations distinguish interactions between discrete and continuous features. The experimental results on multiple datasets demonstrate that the proposed method is effective. The code is available at https://github.com/extess0/DARL.
Entropy-based Exploration Conduction for Multi-step Reasoning
Mar 20, 2025In large language model (LLM) reasoning, multi-step processes have proven effective for solving complex tasks. However, the depth of exploration can significantly affect the reasoning performance. Existing methods to automatically decide the depth often bring high costs and lack flexibility, and thus undermine the model's reasoning accuracy. To address these issues, we propose Entropy-based Exploration Depth Conduction (Entro-duction), a novel method that dynamically adjusts the exploration depth during multi-step reasoning by monitoring LLM's output entropy and variance entropy. We employ these two metrics to capture the model's current uncertainty and the fluctuation of uncertainty across consecutive reasoning steps. Based on the observed changes, the LLM selects whether to deepen, expand or stop exploration according to the probability. In this way, we balance the reasoning accuracy and exploration effectiveness. Experimental results across four benchmark datasets demonstrate the efficacy of Entro-duction. We further conduct experiments and analysis on the components of Entro-duction to discuss their contributions to reasoning performance.
Uncertainty-Aware Global-View Reconstruction for Multi-View Multi-Label Feature Selection
Mar 18, 2025



In recent years, multi-view multi-label learning (MVML) has gained popularity due to its close resemblance to real-world scenarios. However, the challenge of selecting informative features to ensure both performance and efficiency remains a significant question in MVML. Existing methods often extract information separately from the consistency part and the complementary part, which may result in noise due to unclear segmentation. In this paper, we propose a unified model constructed from the perspective of global-view reconstruction. Additionally, while feature selection methods can discern the importance of features, they typically overlook the uncertainty of samples, which is prevalent in realistic scenarios. To address this, we incorporate the perception of sample uncertainty during the reconstruction process to enhance trustworthiness. Thus, the global-view is reconstructed through the graph structure between samples, sample confidence, and the view relationship. The accurate mapping is established between the reconstructed view and the label matrix. Experimental results demonstrate the superior performance of our method on multi-view datasets.
Reconsidering Feature Structure Information and Latent Space Alignment in Partial Multi-label Feature Selection
Mar 13, 2025



The purpose of partial multi-label feature selection is to select the most representative feature subset, where the data comes from partial multi-label datasets that have label ambiguity issues. For label disambiguation, previous methods mainly focus on utilizing the information inside the labels and the relationship between the labels and features. However, the information existing in the feature space is rarely considered, especially in partial multi-label scenarios where the noises is considered to be concentrated in the label space while the feature information is correct. This paper proposes a method based on latent space alignment, which uses the information mined in feature space to disambiguate in latent space through the structural consistency between labels and features. In addition, previous methods overestimate the consistency of features and labels in the latent space after convergence. We comprehensively consider the similarity of latent space projections to feature space and label space, and propose new feature selection term. This method also significantly improves the positive label identification ability of the selected features. Comprehensive experiments demonstrate the superiority of the proposed method.
Deep Cut-informed Graph Embedding and Clustering
Mar 09, 2025Graph clustering aims to divide the graph into different clusters. The recently emerging deep graph clustering approaches are largely built on graph neural networks (GNN). However, GNN is designed for general graph encoding and there is a common issue of representation collapse in existing GNN-based deep graph clustering algorithms. We attribute two main reasons for such issue: (i) the inductive bias of GNN models: GNNs tend to generate similar representations for proximal nodes. Since graphs often contain a non-negligible amount of inter-cluster links, the bias results in error message passing and leads to biased clustering; (ii) the clustering guided loss function: most traditional approaches strive to make all samples closer to pre-learned cluster centers, which cause a degenerate solution assigning all data points to a single label thus make all samples and less discriminative. To address these challenges, we investigate graph clustering from a graph cut perspective and propose an innovative and non-GNN-based Deep Cut-informed Graph embedding and Clustering framework, namely DCGC. This framework includes two modules: (i) cut-informed graph encoding; (ii) self-supervised graph clustering via optimal transport. For the encoding module, we derive a cut-informed graph embedding objective to fuse graph structure and attributes by minimizing their joint normalized cut. For the clustering module, we utilize the optimal transport theory to obtain the clustering assignments, which can balance the guidance of proximity to the pre-learned cluster center. With the above two tailored designs, DCGC is more suitable for the graph clustering task, which can effectively alleviate the problem of representation collapse and achieve better performance. We conduct extensive experiments to demonstrate that our method is simple but effective compared with benchmarks.
Diversity-Oriented Data Augmentation with Large Language Models
Feb 17, 2025Data augmentation is an essential technique in natural language processing (NLP) for enriching training datasets by generating diverse samples. This process is crucial for improving the robustness and generalization capabilities of NLP models. However, a significant challenge remains: \textit{Insufficient Attention to Sample Distribution Diversity}. Most existing methods focus on increasing the sample numbers while neglecting the sample distribution diversity, which can lead to model overfitting. In response, we explore data augmentation's impact on dataset diversity and propose a \textbf{\underline{D}}iversity-\textbf{\underline{o}}riented data \textbf{\underline{Aug}}mentation framework (\textbf{DoAug}). % \(\mathscr{DoAug}\) Specifically, we utilize a diversity-oriented fine-tuning approach to train an LLM as a diverse paraphraser, which is capable of augmenting textual datasets by generating diversified paraphrases. Then, we apply the LLM paraphraser to a selected coreset of highly informative samples and integrate the paraphrases with the original data to create a more diverse augmented dataset. Finally, we conduct extensive experiments on 12 real-world textual datasets. The results show that our fine-tuned LLM augmenter improves diversity while preserving label consistency, thereby enhancing the robustness and performance of downstream tasks. Specifically, it achieves an average performance gain of \(10.52\%\), surpassing the runner-up baseline with more than three percentage points.
LEKA:LLM-Enhanced Knowledge Augmentation
Jan 29, 2025



Humans excel in analogical learning and knowledge transfer and, more importantly, possess a unique understanding of identifying appropriate sources of knowledge. From a model's perspective, this presents an interesting challenge. If models could autonomously retrieve knowledge useful for transfer or decision-making to solve problems, they would transition from passively acquiring to actively accessing and learning from knowledge. However, filling models with knowledge is relatively straightforward -- it simply requires more training and accessible knowledge bases. The more complex task is teaching models about which knowledge can be analogized and transferred. Therefore, we design a knowledge augmentation method LEKA for knowledge transfer that actively searches for suitable knowledge sources that can enrich the target domain's knowledge. This LEKA method extracts key information from textual information from the target domain, retrieves pertinent data from external data libraries, and harmonizes retrieved data with the target domain data in feature space and marginal probability measures. We validate the effectiveness of our approach through extensive experiments across various domains and demonstrate significant improvements over traditional methods in reducing computational costs, automating data alignment, and optimizing transfer learning outcomes.
Iterative Feature Space Optimization through Incremental Adaptive Evaluation
Jan 24, 2025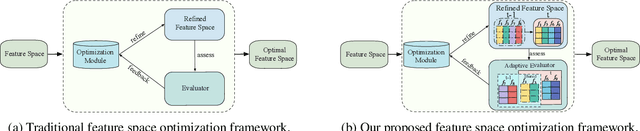
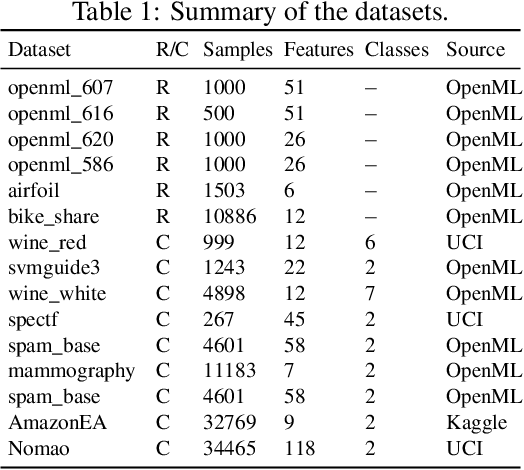
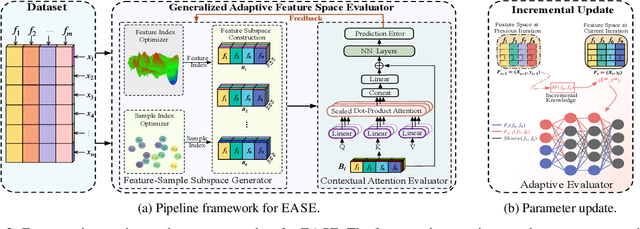
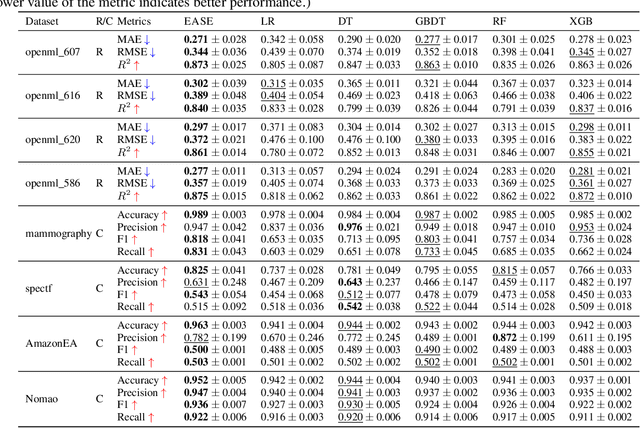
Iterative feature space optimization involves systematically evaluating and adjusting the feature space to improve downstream task performance. However, existing works suffer from three key limitations:1) overlooking differences among data samples leads to evaluation bias; 2) tailoring feature spaces to specific machine learning models results in overfitting and poor generalization; 3) requiring the evaluator to be retrained from scratch during each optimization iteration significantly reduces the overall efficiency of the optimization process. To bridge these gaps, we propose a gEneralized Adaptive feature Space Evaluator (EASE) to efficiently produce optimal and generalized feature spaces. This framework consists of two key components: Feature-Sample Subspace Generator and Contextual Attention Evaluator. The first component aims to decouple the information distribution within the feature space to mitigate evaluation bias. To achieve this, we first identify features most relevant to prediction tasks and samples most challenging for evaluation based on feedback from the subsequent evaluator. This decoupling strategy makes the evaluator consistently target the most challenging aspects of the feature space. The second component intends to incrementally capture evolving patterns of the feature space for efficient evaluation. We propose a weighted-sharing multi-head attention mechanism to encode key characteristics of the feature space into an embedding vector for evaluation. Moreover, the evaluator is updated incrementally, retaining prior evaluation knowledge while incorporating new insights, as consecutive feature spaces during the optimization process share partial information. Extensive experiments on fourteen real-world datasets demonstrate the effectiveness of the proposed framework. Our code and data are publicly available.
Towards Data-Centric AI: A Comprehensive Survey of Traditional, Reinforcement, and Generative Approaches for Tabular Data Transformation
Jan 17, 2025



Tabular data is one of the most widely used formats across industries, driving critical applications in areas such as finance, healthcare, and marketing. In the era of data-centric AI, improving data quality and representation has become essential for enhancing model performance, particularly in applications centered around tabular data. This survey examines the key aspects of tabular data-centric AI, emphasizing feature selection and feature generation as essential techniques for data space refinement. We provide a systematic review of feature selection methods, which identify and retain the most relevant data attributes, and feature generation approaches, which create new features to simplify the capture of complex data patterns. This survey offers a comprehensive overview of current methodologies through an analysis of recent advancements, practical applications, and the strengths and limitations of these techniques. Finally, we outline open challenges and suggest future perspectives to inspire continued innovation in this field.