 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Synthetic Gradients and Decoupled Neural Interfaces
Mar 01, 2017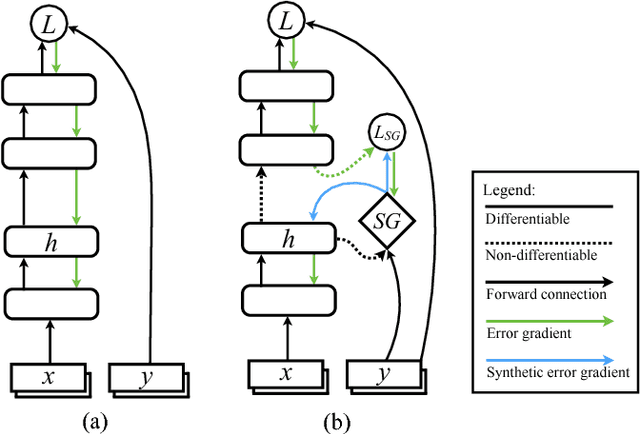
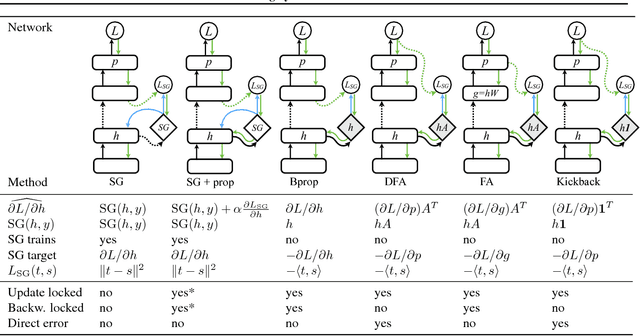
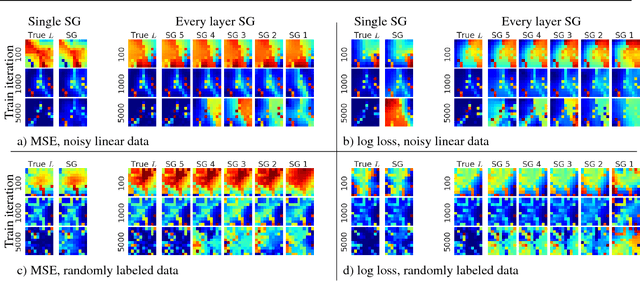
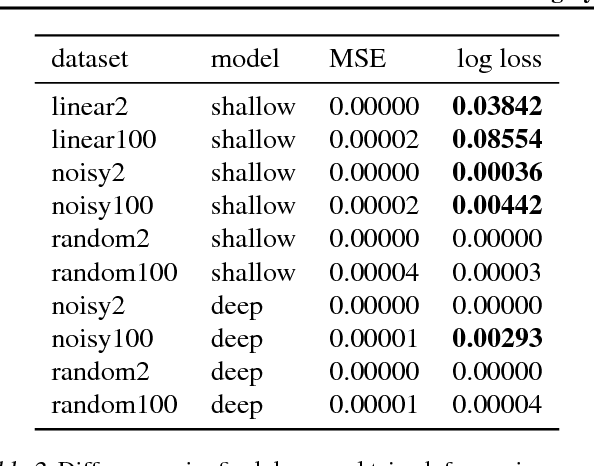
When training neural networks, the use of Synthetic Gradients (SG) allows layers or modules to be trained without update locking - without waiting for a true error gradient to be backpropagated - resulting in Decoupled Neural Interfaces (DNIs). This unlocked ability of being able to update parts of a neural network asynchronously and with only local information was demonstrated to work empirically in Jaderberg et al (2016). However, there has been very little demonstration of what changes DNIs and SGs impose from a functional, representational, and learning dynamics point of view. In this paper, we study DNIs through the use of synthetic gradients on feed-forward networks to better understand their behaviour and elucidate their effect on optimisation. We show that the incorporation of SGs does not affect the representational strength of the learning system for a neural network, and prove the convergence of the learning system for linear and deep linear models. On practical problems we investigate the mechanism by which synthetic gradient estimators approximate the true loss, and, surprisingly, how that leads to drastically different layer-wise representations. Finally, we also expose the relationship of using synthetic gradients to other error approximation techniques and find a unifying language for discussion and comparison.
Learning to Navigate in Complex Environments
Jan 13, 2017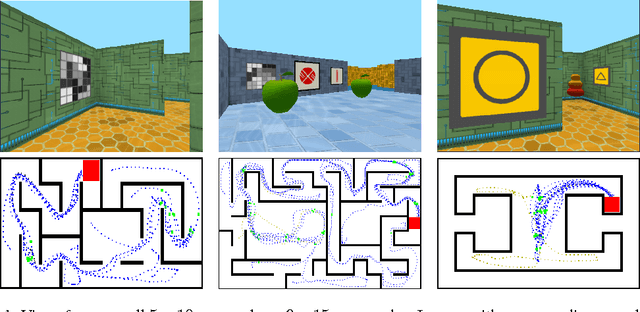
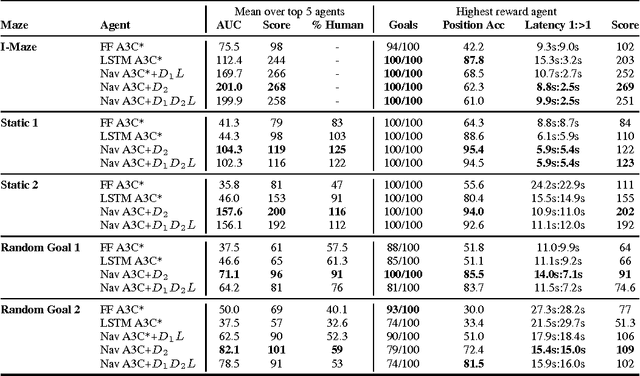
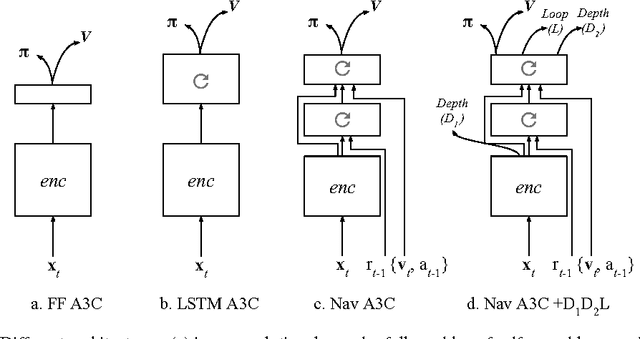
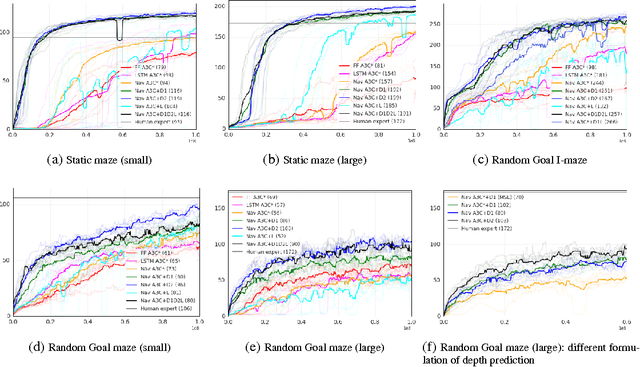
Learning to navigate in complex environments with dynamic elements is an important milestone in developing AI agents. In this work we formulate the navigation question as a reinforcement learning problem and show that data efficiency and task performance can be dramatically improved by relying on additional auxiliary tasks leveraging multimodal sensory inputs. In particular we consider jointly learning the goal-driven reinforcement learning problem with auxiliary depth prediction and loop closure classification tasks. This approach can learn to navigate from raw sensory input in complicated 3D mazes, approaching human-level performance even under conditions where the goal location changes frequently. We provide detailed analysis of the agent behaviour, its ability to localise, and its network activity dynamics, showing that the agent implicitly learns key navigation abilities.
Interaction Networks for Learning about Objects, Relations and Physics
Dec 01, 2016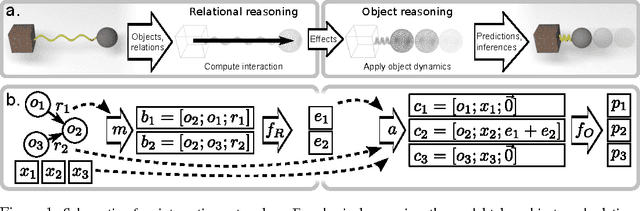


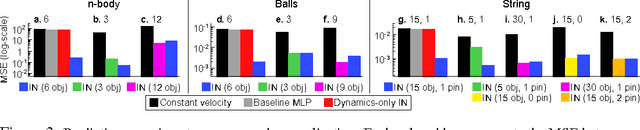
Reasoning about objects, relations, and physics is central to human intelligence, and a key goal of artificial intelligence. Here we introduce the interaction network, a model which can reason about how objects in complex systems interact, supporting dynamical predictions, as well as inferences about the abstract properties of the system. Our model takes graphs as input, performs object- and relation-centric reasoning in a way that is analogous to a simulation, and is implemented using deep neural networks. We evaluate its ability to reason about several challenging physical domains: n-body problems, rigid-body collision, and non-rigid dynamics. Our results show it can be trained to accurately simulate the physical trajectories of dozens of objects over thousands of time steps, estimate abstract quantities such as energy, and generalize automatically to systems with different numbers and configurations of objects and relations. Our interaction network implementation is the first general-purpose, learnable physics engine, and a powerful general framework for reasoning about object and relations in a wide variety of complex real-world domains.
Reinforcement Learning with Unsupervised Auxiliary Tasks
Nov 16, 2016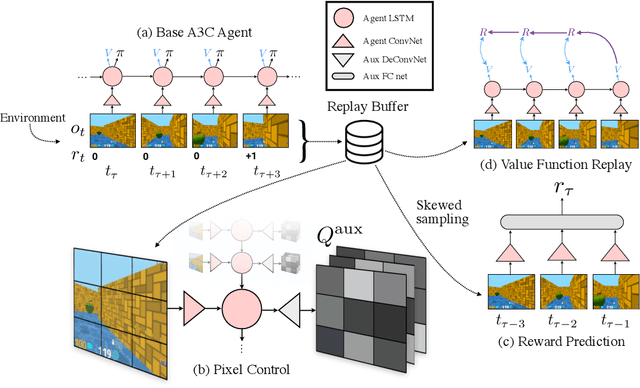
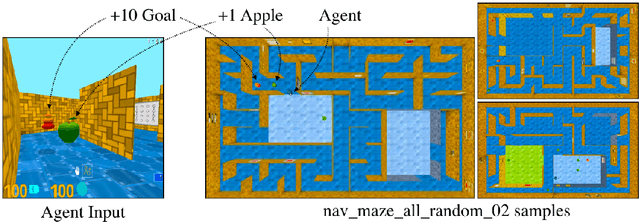
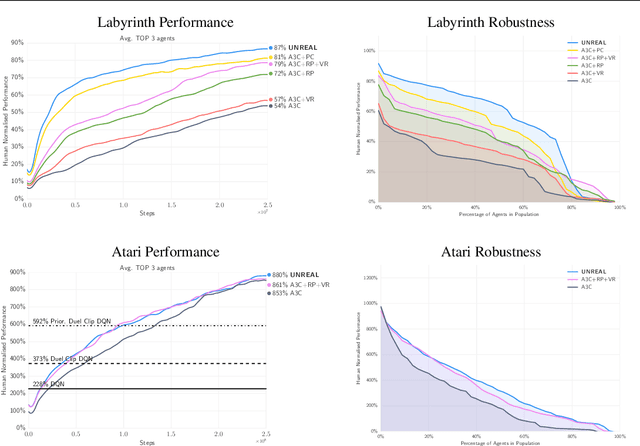
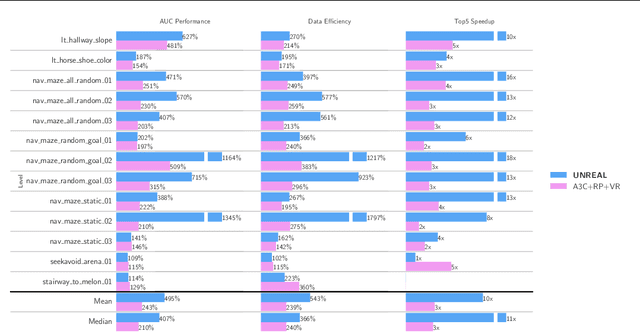
Deep reinforcement learning agents have achieved state-of-the-art results by directly maximising cumulative reward. However, environments contain a much wider variety of possible training signals. In this paper, we introduce an agent that also maximises many other pseudo-reward functions simultaneously by reinforcement learning. All of these tasks share a common representation that, like unsupervised learning, continues to develop in the absence of extrinsic rewards. We also introduce a novel mechanism for focusing this representation upon extrinsic rewards, so that learning can rapidly adapt to the most relevant aspects of the actual task. Our agent significantly outperforms the previous state-of-the-art on Atari, averaging 880\% expert human performance, and a challenging suite of first-person, three-dimensional \emph{Labyrinth} tasks leading to a mean speedup in learning of 10$\times$ and averaging 87\% expert human performance on Labyrinth.
Video Pixel Networks
Oct 03, 2016
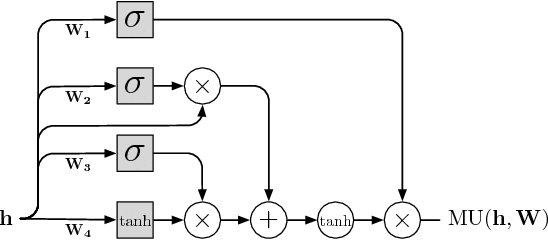


We propose a probabilistic video model, the Video Pixel Network (VPN), that estimates the discrete joint distribution of the raw pixel values in a video. The model and the neural architecture reflect the time, space and color structure of video tensors and encode it as a four-dimensional dependency chain. The VPN approaches the best possible performance on the Moving MNIST benchmark, a leap over the previous state of the art, and the generated videos show only minor deviations from the ground truth. The VPN also produces detailed samples on the action-conditional Robotic Pushing benchmark and generalizes to the motion of novel objects.
WaveNet: A Generative Model for Raw Audio
Sep 19, 2016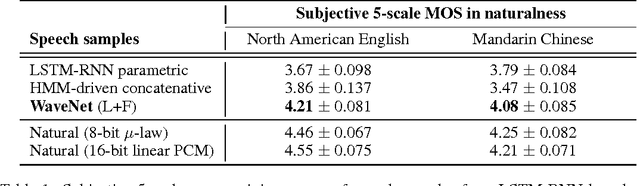
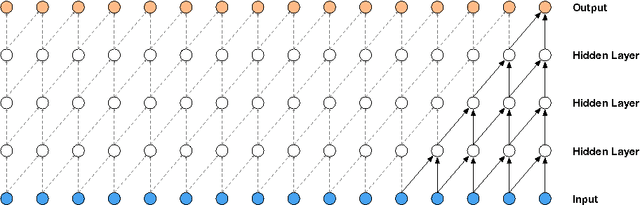
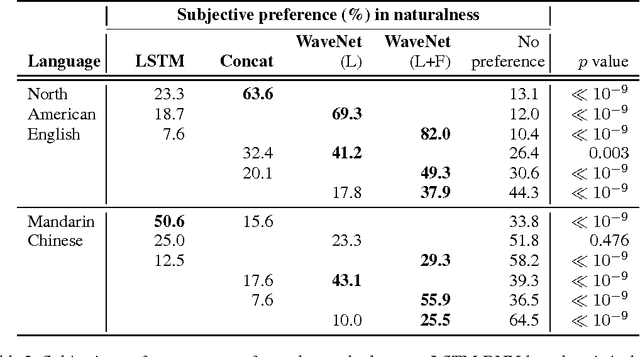
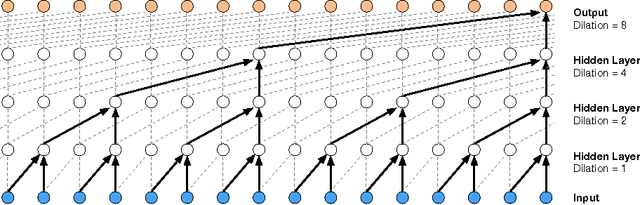
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-of-the-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
Progressive Neural Networks
Sep 07, 2016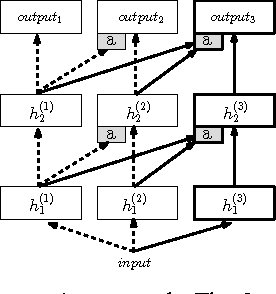
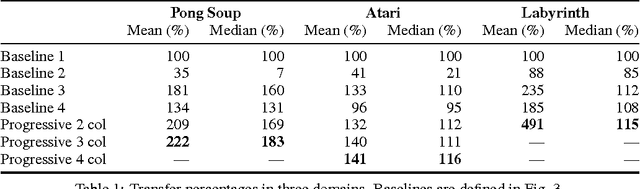

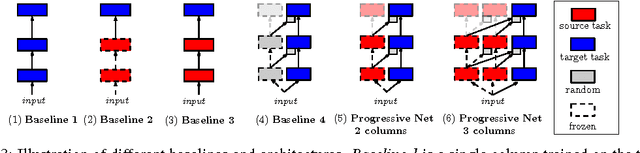
Learning to solve complex sequences of tasks--while both leveraging transfer and avoiding catastrophic forgetting--remains a key obstacle to achieving human-level intelligence. The progressive networks approach represents a step forward in this direction: they are immune to forgetting and can leverage prior knowledge via lateral connections to previously learned features. We evaluate this architecture extensively on a wide variety of reinforcement learning tasks (Atari and 3D maze games), and show that it outperforms common baselines based on pretraining and finetuning. Using a novel sensitivity measure, we demonstrate that transfer occurs at both low-level sensory and high-level control layers of the learned policy.
Pixel Recurrent Neural Networks
Aug 19, 2016

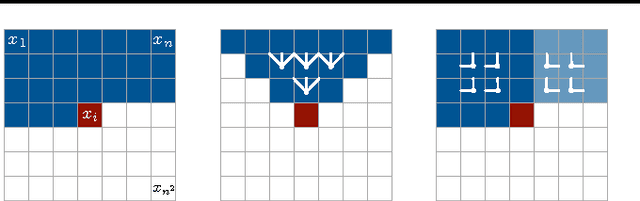
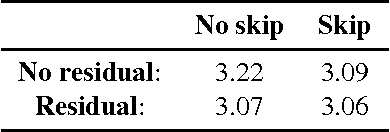
Modeling the distribution of natural images is a landmark problem in unsupervised learning. This task requires an image model that is at once expressive, tractable and scalable. We present a deep neural network that sequentially predicts the pixels in an image along the two spatial dimensions. Our method models the discrete probability of the raw pixel values and encodes the complete set of dependencies in the image. Architectural novelties include fast two-dimensional recurrent layers and an effective use of residual connections in deep recurrent networks. We achieve log-likelihood scores on natural images that are considerably better than the previous state of the art. Our main results also provide benchmarks on the diverse ImageNet dataset. Samples generated from the model appear crisp, varied and globally coherent.
Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
Aug 12, 2016
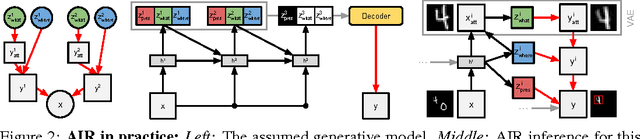

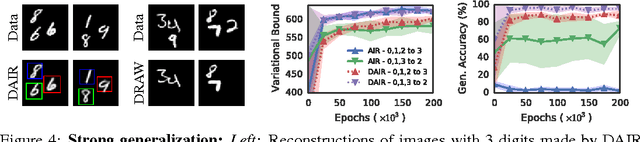
We present a framework for efficient inference in structured image models that explicitly reason about objects. We achieve this by performing probabilistic inference using a recurrent neural network that attends to scene elements and processes them one at a time. Crucially, the model itself learns to choose the appropriate number of inference steps. We use this scheme to learn to perform inference in partially specified 2D models (variable-sized variational auto-encoders) and fully specified 3D models (probabilistic renderers). We show that such models learn to identify multiple objects - counting, locating and classifying the elements of a scene - without any supervision, e.g., decomposing 3D images with various numbers of objects in a single forward pass of a neural network. We further show that the networks produce accurate inferences when compared to supervised counterparts, and that their structure leads to improved generalization.
Conditional Image Generation with PixelCNN Decoders
Jun 18, 2016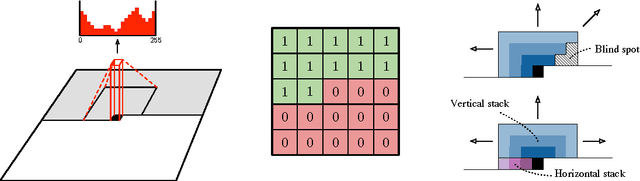
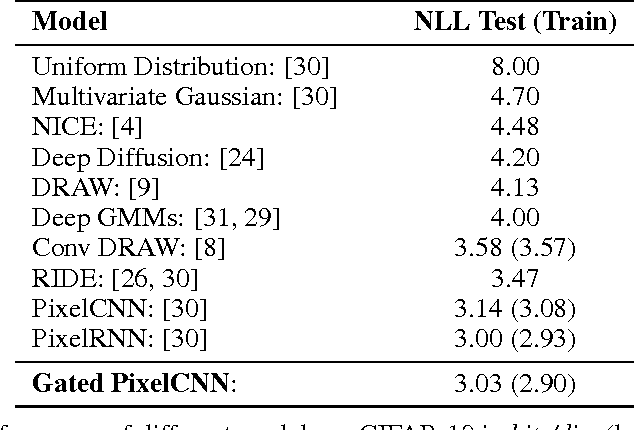
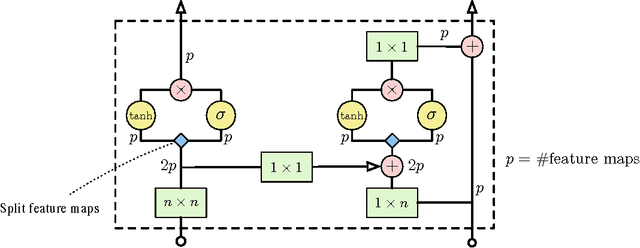
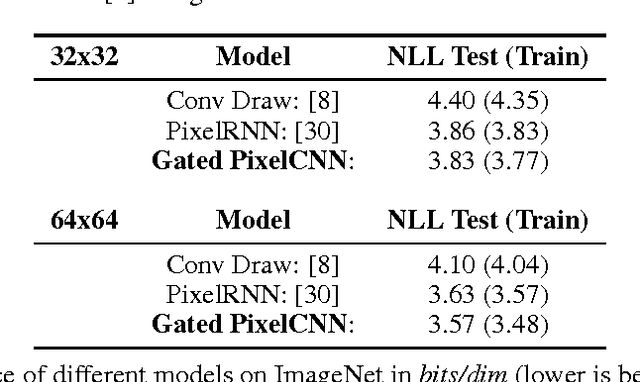
This work explores conditional image generation with a new image density model based on the PixelCNN architecture. The model can be conditioned on any vector, including descriptive labels or tags, or latent embeddings created by other networks. When conditioned on class labels from the ImageNet database, the model is able to generate diverse, realistic scenes representing distinct animals, objects, landscapes and structures. When conditioned on an embedding produced by a convolutional network given a single image of an unseen face, it generates a variety of new portraits of the same person with different facial expressions, poses and lighting conditions. We also show that conditional PixelCNN can serve as a powerful decoder in an image autoencoder. Additionally, the gated convolutional layers in the proposed model improve the log-likelihood of PixelCNN to match the state-of-the-art performance of PixelRNN on ImageNet, with greatly reduced computational cost.