 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Semantic Similarity from Spatial Alignment for Neural Networks
Oct 30, 2024



What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs. Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair. These matrices encapsulate the entire similarity structure of a system, indicating which input leads to similar responses. While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper, we propose to solve this through semantic RSMs, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of semantic RSMs over spatio-semantic RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.
Data-Centric Strategies for Overcoming PET/CT Heterogeneity: Insights from the AutoPET III Lesion Segmentation Challenge
Sep 16, 2024

The third autoPET challenge introduced a new data-centric task this year, shifting the focus from model development to improving metastatic lesion segmentation on PET/CT images through data quality and handling strategies. In response, we developed targeted methods to enhance segmentation performance tailored to the characteristics of PET/CT imaging. Our approach encompasses two key elements. First, to address potential alignment errors between CT and PET modalities as well as the prevalence of punctate lesions, we modified the baseline data augmentation scheme and extended it with misalignment augmentation. This adaptation aims to improve segmentation accuracy, particularly for tiny metastatic lesions. Second, to tackle the variability in image dimensions significantly affecting the prediction time, we implemented a dynamic ensembling and test-time augmentation (TTA) strategy. This method optimizes the use of ensembling and TTA within a 5-minute prediction time limit, effectively leveraging the generalization potential for both small and large images. Both of our solutions are designed to be robust across different tracers and institutional settings, offering a general, yet imaging-specific approach to the multi-tracer and multi-institutional challenges of the competition. We made the challenge repository with our modifications publicly available at \url{https://github.com/MIC-DKFZ/miccai2024_autopet3_datacentric}.
From FDG to PSMA: A Hitchhiker's Guide to Multitracer, Multicenter Lesion Segmentation in PET/CT Imaging
Sep 14, 2024

Automated lesion segmentation in PET/CT scans is crucial for improving clinical workflows and advancing cancer diagnostics. However, the task is challenging due to physiological variability, different tracers used in PET imaging, and diverse imaging protocols across medical centers. To address this, the autoPET series was created to challenge researchers to develop algorithms that generalize across diverse PET/CT environments. This paper presents our solution for the autoPET III challenge, targeting multitracer, multicenter generalization using the nnU-Net framework with the ResEncL architecture. Key techniques include misalignment data augmentation and multi-modal pretraining across CT, MR, and PET datasets to provide an initial anatomical understanding. We incorporate organ supervision as a multitask approach, enabling the model to distinguish between physiological uptake and tracer-specific patterns, which is particularly beneficial in cases where no lesions are present. Compared to the default nnU-Net, which achieved a Dice score of 57.61, or the larger ResEncL (65.31) our model significantly improved performance with a Dice score of 68.40, alongside a reduction in false positive (FPvol: 7.82) and false negative (FNvol: 10.35) volumes. These results underscore the effectiveness of combining advanced network design, augmentation, pretraining, and multitask learning for PET/CT lesion segmentation. Code is publicly available at https://github.com/MIC-DKFZ/autopet-3-submission.
Overcoming Common Flaws in the Evaluation of Selective Classification Systems
Jul 01, 2024



Selective Classification, wherein models can reject low-confidence predictions, promises reliable translation of machine-learning based classification systems to real-world scenarios such as clinical diagnostics. While current evaluation of these systems typically assumes fixed working points based on pre-defined rejection thresholds, methodological progress requires benchmarking the general performance of systems akin to the $\mathrm{AUROC}$ in standard classification. In this work, we define 5 requirements for multi-threshold metrics in selective classification regarding task alignment, interpretability, and flexibility, and show how current approaches fail to meet them. We propose the Area under the Generalized Risk Coverage curve ($\mathrm{AUGRC}$), which meets all requirements and can be directly interpreted as the average risk of undetected failures. We empirically demonstrate the relevance of $\mathrm{AUGRC}$ on a comprehensive benchmark spanning 6 data sets and 13 confidence scoring functions. We find that the proposed metric substantially changes metric rankings on 5 out of the 6 data sets.
Enhancing predictive imaging biomarker discovery through treatment effect analysis
Jun 04, 2024


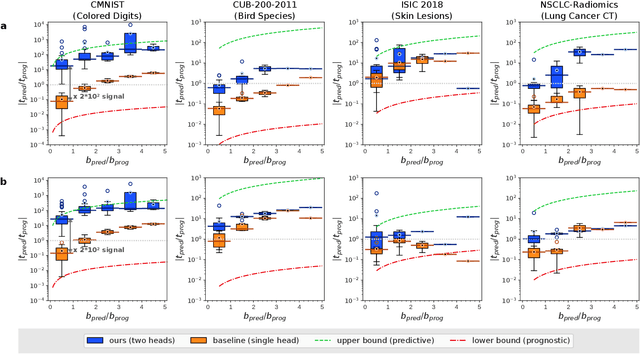
Identifying predictive biomarkers, which forecast individual treatment effectiveness, is crucial for personalized medicine and informs decision-making across diverse disciplines. These biomarkers are extracted from pre-treatment data, often within randomized controlled trials, and have to be distinguished from prognostic biomarkers, which are independent of treatment assignment. Our study focuses on the discovery of predictive imaging biomarkers, aiming to leverage pre-treatment images to unveil new causal relationships. Previous approaches relied on labor-intensive handcrafted or manually derived features, which may introduce biases. In response, we present a new task of discovering predictive imaging biomarkers directly from the pre-treatment images to learn relevant image features. We propose an evaluation protocol for this task to assess a model's ability to identify predictive imaging biomarkers and differentiate them from prognostic ones. It employs statistical testing and a comprehensive analysis of image feature attribution. We explore the suitability of deep learning models originally designed for estimating the conditional average treatment effect (CATE) for this task, which previously have been primarily assessed for the precision of CATE estimation, overlooking the evaluation of imaging biomarker discovery. Our proof-of-concept analysis demonstrates promising results in discovering and validating predictive imaging biomarkers from synthetic outcomes and real-world image datasets.
Fair Evaluation of Federated Learning Algorithms for Automated Breast Density Classification: The Results of the 2022 ACR-NCI-NVIDIA Federated Learning Challenge
May 22, 2024The correct interpretation of breast density is important in the assessment of breast cancer risk. AI has been shown capable of accurately predicting breast density, however, due to the differences in imaging characteristics across mammography systems, models built using data from one system do not generalize well to other systems. Though federated learning (FL) has emerged as a way to improve the generalizability of AI without the need to share data, the best way to preserve features from all training data during FL is an active area of research. To explore FL methodology, the breast density classification FL challenge was hosted in partnership with the American College of Radiology, Harvard Medical School's Mass General Brigham, University of Colorado, NVIDIA, and the National Institutes of Health National Cancer Institute. Challenge participants were able to submit docker containers capable of implementing FL on three simulated medical facilities, each containing a unique large mammography dataset. The breast density FL challenge ran from June 15 to September 5, 2022, attracting seven finalists from around the world. The winning FL submission reached a linear kappa score of 0.653 on the challenge test data and 0.413 on an external testing dataset, scoring comparably to a model trained on the same data in a central location.
* 16 pages, 9 figures
Mitigating False Predictions In Unreasonable Body Regions
Apr 24, 2024



Despite considerable strides in developing deep learning models for 3D medical image segmentation, the challenge of effectively generalizing across diverse image distributions persists. While domain generalization is acknowledged as vital for robust application in clinical settings, the challenges stemming from training with a limited Field of View (FOV) remain unaddressed. This limitation leads to false predictions when applied to body regions beyond the FOV of the training data. In response to this problem, we propose a novel loss function that penalizes predictions in implausible body regions, applicable in both single-dataset and multi-dataset training schemes. It is realized with a Body Part Regression model that generates axial slice positional scores. Through comprehensive evaluation using a test set featuring varying FOVs, our approach demonstrates remarkable improvements in generalization capabilities. It effectively mitigates false positive tumor predictions up to 85% and significantly enhances overall segmentation performance.
Automatic classification of prostate MR series type using image content and metadata
Apr 16, 2024


With the wealth of medical image data, efficient curation is essential. Assigning the sequence type to magnetic resonance images is necessary for scientific studies and artificial intelligence-based analysis. However, incomplete or missing metadata prevents effective automation. We therefore propose a deep-learning method for classification of prostate cancer scanning sequences based on a combination of image data and DICOM metadata. We demonstrate superior results compared to metadata or image data alone, and make our code publicly available at https://github.com/deepakri201/DICOMScanClassification.
Embarrassingly Simple Scribble Supervision for 3D Medical Segmentation
Mar 19, 2024



Traditionally, segmentation algorithms require dense annotations for training, demanding significant annotation efforts, particularly within the 3D medical imaging field. Scribble-supervised learning emerges as a possible solution to this challenge, promising a reduction in annotation efforts when creating large-scale datasets. Recently, a plethora of methods for optimized learning from scribbles have been proposed, but have so far failed to position scribble annotation as a beneficial alternative. We relate this shortcoming to two major issues: 1) the complex nature of many methods which deeply ties them to the underlying segmentation model, thus preventing a migration to more powerful state-of-the-art models as the field progresses and 2) the lack of a systematic evaluation to validate consistent performance across the broader medical domain, resulting in a lack of trust when applying these methods to new segmentation problems. To address these issues, we propose a comprehensive scribble supervision benchmark consisting of seven datasets covering a diverse set of anatomies and pathologies imaged with varying modalities. We furthermore propose the systematic use of partial losses, i.e. losses that are only computed on annotated voxels. Contrary to most existing methods, these losses can be seamlessly integrated into state-of-the-art segmentation methods, enabling them to learn from scribble annotations while preserving their original loss formulations. Our evaluation using nnU-Net reveals that while most existing methods suffer from a lack of generalization, the proposed approach consistently delivers state-of-the-art performance. Thanks to its simplicity, our approach presents an embarrassingly simple yet effective solution to the challenges of scribble supervision. Source code as well as our extensive scribble benchmarking suite will be made publicly available upon publication.
DALSA: Domain Adaptation for Supervised Learning From Sparsely Annotated MR Images
Mar 12, 2024



We propose a new method that employs transfer learning techniques to effectively correct sampling selection errors introduced by sparse annotations during supervised learning for automated tumor segmentation. The practicality of current learning-based automated tissue classification approaches is severely impeded by their dependency on manually segmented training databases that need to be recreated for each scenario of application, site, or acquisition setup. The comprehensive annotation of reference datasets can be highly labor-intensive, complex, and error-prone. The proposed method derives high-quality classifiers for the different tissue classes from sparse and unambiguous annotations and employs domain adaptation techniques for effectively correcting sampling selection errors introduced by the sparse sampling. The new approach is validated on labeled, multi-modal MR images of 19 patients with malignant gliomas and by comparative analysis on the BraTS 2013 challenge data sets. Compared to training on fully labeled data, we reduced the time for labeling and training by a factor greater than 70 and 180 respectively without sacrificing accuracy. This dramatically eases the establishment and constant extension of large annotated databases in various scenarios and imaging setups and thus represents an important step towards practical applicability of learning-based approaches in tissue classification.