 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-IQ Verified
Jun 17, 2026Video generative models ( VGMs) have become a new frontier that can be used not just for video generation but for a multitude of downstream tasks, including world modeling. To advance these tasks, a good video model must understand the physical reality of the world. Evaluating this understanding is an emerging field and has led to the Physics-IQ benchmark, which quantifies this explicitly by comparing model-generated videos to real-world videos of physical experiments. In this work, we present a systematic audit of the Physics-IQ benchmark, expose shortcomings and propose three solutions that sharpen how we can measure physical understanding of VGMs. Specifically, we improve prompt and ground-truth quality to reduce the influence of confounding factors and further introduce a sample-level scoring system that weights each sample and metric equally. Our resulting benchmark, Physics-IQ Verified, refines 57.6\% of all samples and improves over 34.8\% of prompts. In a comparison study using six image-to-video generative models, we observe moderate but meaningful ranking changes (Kendall's $τ= 0.46$). We hope Physics-IQ Verified advances the community by providing a more reliable signal toward physically accurate VGMs. The code for the benchmark can be accessed at https://github.com/google-deepmind/physics-iq-benchmark
Unified Neural Scaling Laws
May 25, 2026We present a functional form (that we refer to as a Unified Neural Scaling Law (UNSL)) that accurately models and extrapolates the scaling behaviors of deep neural networks as multiple dimensions all vary simultaneously (i.e. how the evaluation metric of interest varies as one simultaneously varies the number of model parameters, training dataset size, number of training steps, number of inference steps, amount of compute, and various hyperparameters) for various architectures and for each of various tasks within a varied set of upstream and downstream tasks. This set includes large-scale vision, language, math, and reinforcement learning. When compared to other functional forms for neural scaling, this functional form yields extrapolations of scaling behavior that are considerably more accurate on this set.
Amortized In-Context Bayesian Posterior Estimation
Feb 10, 2025Bayesian inference provides a natural way of incorporating prior beliefs and assigning a probability measure to the space of hypotheses. Current solutions rely on iterative routines like Markov Chain Monte Carlo (MCMC) sampling and Variational Inference (VI), which need to be re-run whenever new observations are available. Amortization, through conditional estimation, is a viable strategy to alleviate such difficulties and has been the guiding principle behind simulation-based inference, neural processes and in-context methods using pre-trained models. In this work, we conduct a thorough comparative analysis of amortized in-context Bayesian posterior estimation methods from the lens of different optimization objectives and architectural choices. Such methods train an amortized estimator to perform posterior parameter inference by conditioning on a set of data examples passed as context to a sequence model such as a transformer. In contrast to language models, we leverage permutation invariant architectures as the true posterior is invariant to the ordering of context examples. Our empirical study includes generalization to out-of-distribution tasks, cases where the assumed underlying model is misspecified, and transfer from simulated to real problems. Subsequently, it highlights the superiority of the reverse KL estimator for predictive problems, especially when combined with the transformer architecture and normalizing flows.
Do generative video models learn physical principles from watching videos?
Jan 14, 2025
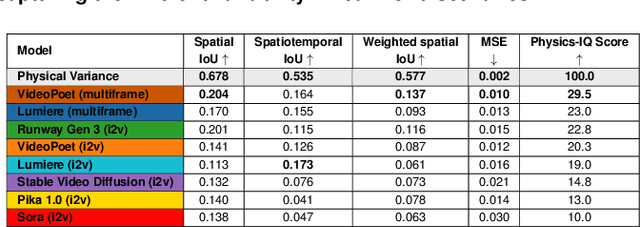


AI video generation is undergoing a revolution, with quality and realism advancing rapidly. These advances have led to a passionate scientific debate: Do video models learn ``world models'' that discover laws of physics -- or, alternatively, are they merely sophisticated pixel predictors that achieve visual realism without understanding the physical principles of reality? We address this question by developing Physics-IQ, a comprehensive benchmark dataset that can only be solved by acquiring a deep understanding of various physical principles, like fluid dynamics, optics, solid mechanics, magnetism and thermodynamics. We find that across a range of current models (Sora, Runway, Pika, Lumiere, Stable Video Diffusion, and VideoPoet), physical understanding is severely limited, and unrelated to visual realism. At the same time, some test cases can already be successfully solved. This indicates that acquiring certain physical principles from observation alone may be possible, but significant challenges remain. While we expect rapid advances ahead, our work demonstrates that visual realism does not imply physical understanding. Our project page is at https://physics-iq.github.io; code at https://github.com/google-deepmind/physics-IQ-benchmark.
Decoupling Semantic Similarity from Spatial Alignment for Neural Networks
Oct 30, 2024



What representation do deep neural networks learn? How similar are images to each other for neural networks? Despite the overwhelming success of deep learning methods key questions about their internal workings still remain largely unanswered, due to their internal high dimensionality and complexity. To address this, one approach is to measure the similarity of activation responses to various inputs. Representational Similarity Matrices (RSMs) distill this similarity into scalar values for each input pair. These matrices encapsulate the entire similarity structure of a system, indicating which input leads to similar responses. While the similarity between images is ambiguous, we argue that the spatial location of semantic objects does neither influence human perception nor deep learning classifiers. Thus this should be reflected in the definition of similarity between image responses for computer vision systems. Revisiting the established similarity calculations for RSMs we expose their sensitivity to spatial alignment. In this paper, we propose to solve this through semantic RSMs, which are invariant to spatial permutation. We measure semantic similarity between input responses by formulating it as a set-matching problem. Further, we quantify the superiority of semantic RSMs over spatio-semantic RSMs through image retrieval and by comparing the similarity between representations to the similarity between predicted class probabilities.
Towards flexible perception with visual memory
Aug 15, 2024



Training a neural network is a monolithic endeavor, akin to carving knowledge into stone: once the process is completed, editing the knowledge in a network is nearly impossible, since all information is distributed across the network's weights. We here explore a simple, compelling alternative by marrying the representational power of deep neural networks with the flexibility of a database. Decomposing the task of image classification into image similarity (from a pre-trained embedding) and search (via fast nearest neighbor retrieval from a knowledge database), we build a simple and flexible visual memory that has the following key capabilities: (1.) The ability to flexibly add data across scales: from individual samples all the way to entire classes and billion-scale data; (2.) The ability to remove data through unlearning and memory pruning; (3.) An interpretable decision-mechanism on which we can intervene to control its behavior. Taken together, these capabilities comprehensively demonstrate the benefits of an explicit visual memory. We hope that it might contribute to a conversation on how knowledge should be represented in deep vision models -- beyond carving it in ``stone'' weights.
Intriguing properties of generative classifiers
Sep 28, 2023



What is the best paradigm to recognize objects -- discriminative inference (fast but potentially prone to shortcut learning) or using a generative model (slow but potentially more robust)? We build on recent advances in generative modeling that turn text-to-image models into classifiers. This allows us to study their behavior and to compare them against discriminative models and human psychophysical data. We report four intriguing emergent properties of generative classifiers: they show a record-breaking human-like shape bias (99% for Imagen), near human-level out-of-distribution accuracy, state-of-the-art alignment with human classification errors, and they understand certain perceptual illusions. Our results indicate that while the current dominant paradigm for modeling human object recognition is discriminative inference, zero-shot generative models approximate human object recognition data surprisingly well.
Text-to-Image Diffusion Models are Zero-Shot Classifiers
Mar 27, 2023The excellent generative capabilities of text-to-image diffusion models suggest they learn informative representations of image-text data. However, what knowledge their representations capture is not fully understood, and they have not been thoroughly explored on downstream tasks. We investigate diffusion models by proposing a method for evaluating them as zero-shot classifiers. The key idea is using a diffusion model's ability to denoise a noised image given a text description of a label as a proxy for that label's likelihood. We apply our method to Imagen, using it to probe fine-grained aspects of Imagen's knowledge and comparing it with CLIP's zero-shot abilities. Imagen performs competitively with CLIP on a wide range of zero-shot image classification datasets. Additionally, it achieves state-of-the-art results on shape/texture bias tests and can successfully perform attribute binding while CLIP cannot. Although generative pre-training is prevalent in NLP, visual foundation models often use other methods such as contrastive learning. Based on our findings, we argue that generative pre-training should be explored as a compelling alternative for vision and vision-language problems.
Path Integral Stochastic Optimal Control for Sampling Transition Paths
Jun 27, 2022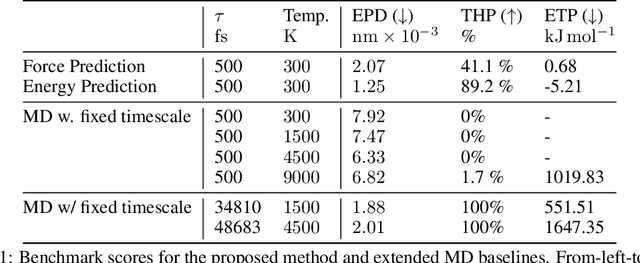
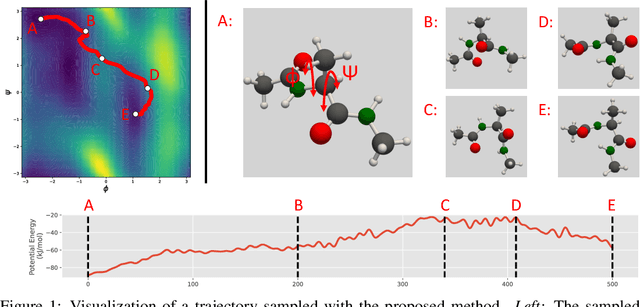
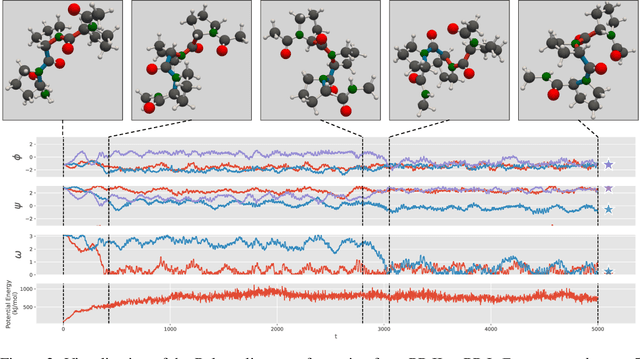
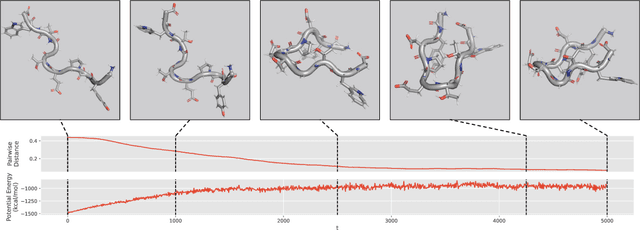
We consider the problem of Sampling Transition Paths. Given two metastable conformational states of a molecular system, eg. a folded and unfolded protein, we aim to sample the most likely transition path between the two states. Sampling such a transition path is computationally expensive due to the existence of high free energy barriers between the two states. To circumvent this, previous work has focused on simplifying the trajectories to occur along specific molecular descriptors called Collective Variables (CVs). However, finding CVs is not trivial and requires chemical intuition. For larger molecules, where intuition is not sufficient, using these CV-based methods biases the transition along possibly irrelevant dimensions. Instead, this work proposes a method for sampling transition paths that consider the entire geometry of the molecules. To achieve this, we first relate the problem to recent work on the Schrodinger bridge problem and stochastic optimal control. Using this relation, we construct a method that takes into account important characteristics of molecular systems such as second-order dynamics and invariance to rotations and translations. We demonstrate our method on the commonly studied Alanine Dipeptide, but also consider larger proteins such as Polyproline and Chignolin.
Particle Dynamics for Learning EBMs
Nov 26, 2021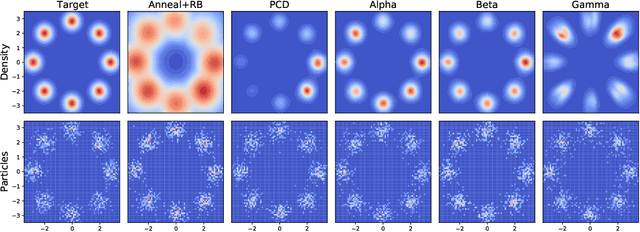
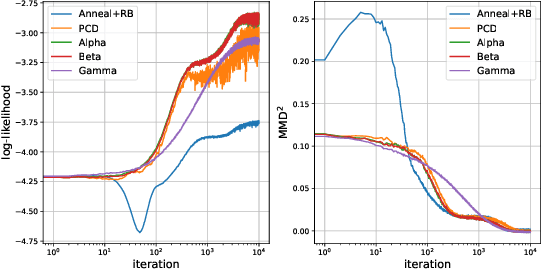
Energy-based modeling is a promising approach to unsupervised learning, which yields many downstream applications from a single model. The main difficulty in learning energy-based models with the "contrastive approaches" is the generation of samples from the current energy function at each iteration. Many advances have been made to accomplish this subroutine cheaply. Nevertheless, all such sampling paradigms run MCMC targeting the current model, which requires infinitely long chains to generate samples from the true energy distribution and is problematic in practice. This paper proposes an alternative approach to getting these samples and avoiding crude MCMC sampling from the current model. We accomplish this by viewing the evolution of the modeling distribution as (i) the evolution of the energy function, and (ii) the evolution of the samples from this distribution along some vector field. We subsequently derive this time-dependent vector field such that the particles following this field are approximately distributed as the current density model. Thereby we match the evolution of the particles with the evolution of the energy function prescribed by the learning procedure. Importantly, unlike Monte Carlo sampling, our method targets to match the current distribution in a finite time. Finally, we demonstrate its effectiveness empirically compared to MCMC-based learning methods.