 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-Vision: Evaluating Multimodal LLMs Logic Understanding and Code Generation Capabilities
Feb 17, 2025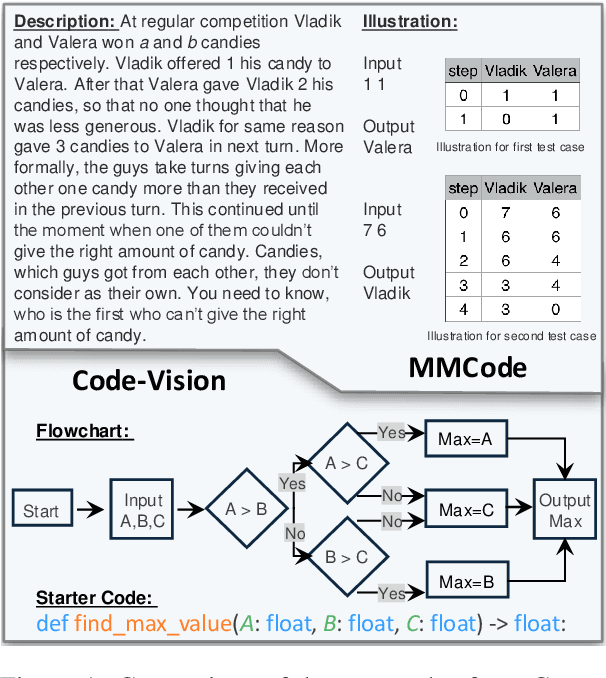

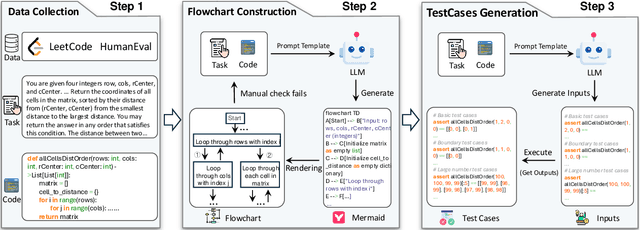
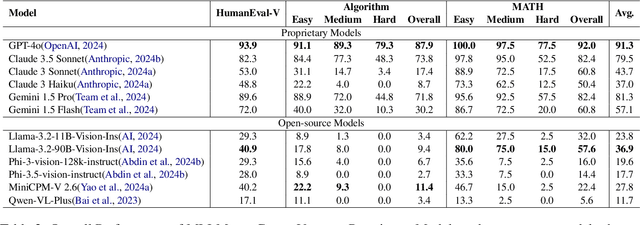
This paper introduces Code-Vision, a benchmark designed to evaluate the logical understanding and code generation capabilities of Multimodal Large Language Models (MLLMs). It challenges MLLMs to generate a correct program that fulfills specific functionality requirements based on a given flowchart, which visually represents the desired algorithm or process. Code-Vision comprises three subsets: HumanEval-V, Algorithm, and MATH, which evaluate MLLMs' coding abilities across basic programming, algorithmic, and mathematical problem-solving domains. Our experiments evaluate 12 MLLMs on Code-Vision. Experimental results demonstrate that there is a large performance difference between proprietary and open-source models. On Hard problems, GPT-4o can achieve 79.3% pass@1, but the best open-source model only achieves 15%. Further experiments reveal that Code-Vision can pose unique challenges compared to other multimodal reasoning benchmarks MMCode and MathVista. We also explore the reason for the poor performance of the open-source models. All data and codes are available at https://github.com/wanghanbinpanda/CodeVision.
Locate-then-edit for Multi-hop Factual Recall under Knowledge Editing
Oct 08, 2024



The locate-then-edit paradigm has shown significant promise for knowledge editing (KE) in Large Language Models (LLMs). While previous methods perform well on single-hop fact recall tasks, they consistently struggle with multi-hop factual recall tasks involving newly edited knowledge. In this paper, leveraging tools in mechanistic interpretability, we first identify that in multi-hop tasks, LLMs tend to retrieve implicit subject knowledge from deeper MLP layers, unlike single-hop tasks, which rely on earlier layers. This distinction explains the poor performance of current methods in multi-hop queries, as they primarily focus on editing shallow layers, leaving deeper layers unchanged. To address this, we propose IFMET, a novel locate-then-edit KE approach designed to edit both shallow and deep MLP layers. IFMET employs multi-hop editing prompts and supplementary sets to locate and modify knowledge across different reasoning stages. Experimental results demonstrate that IFMET significantly improves performance on multi-hop factual recall tasks, effectively overcoming the limitations of previous locate-then-edit methods.
Leveraging Logical Rules in Knowledge Editing: A Cherry on the Top
May 27, 2024



Multi-hop Question Answering (MQA) under knowledge editing (KE) is a key challenge in Large Language Models (LLMs). While best-performing solutions in this domain use a plan and solve paradigm to split a question into sub-questions followed by response generation, we claim that this approach is sub-optimal as it fails for hard to decompose questions, and it does not explicitly cater to correlated knowledge updates resulting as a consequence of knowledge edits. This has a detrimental impact on the overall consistency of the updated knowledge. To address these issues, in this paper, we propose a novel framework named RULE-KE, i.e., RULE based Knowledge Editing, which is a cherry on the top for augmenting the performance of all existing MQA methods under KE. Specifically, RULE-KE leverages rule discovery to discover a set of logical rules. Then, it uses these discovered rules to update knowledge about facts highly correlated with the edit. Experimental evaluation using existing and newly curated datasets (i.e., RKE-EVAL) shows that RULE-KE helps augment both performances of parameter-based and memory-based solutions up to 92% and 112.9%, respectively.
Multi-hop Question Answering under Temporal Knowledge Editing
Mar 30, 2024



Multi-hop question answering (MQA) under knowledge editing (KE) has garnered significant attention in the era of large language models. However, existing models for MQA under KE exhibit poor performance when dealing with questions containing explicit temporal contexts. To address this limitation, we propose a novel framework, namely TEMPoral knowLEdge augmented Multi-hop Question Answering (TEMPLE-MQA). Unlike previous methods, TEMPLE-MQA first constructs a time-aware graph (TAG) to store edit knowledge in a structured manner. Then, through our proposed inference path, structural retrieval, and joint reasoning stages, TEMPLE-MQA effectively discerns temporal contexts within the question query. Experiments on benchmark datasets demonstrate that TEMPLE-MQA significantly outperforms baseline models. Additionally, we contribute a new dataset, namely TKEMQA, which serves as the inaugural benchmark tailored specifically for MQA with temporal scopes.
Dialectical Alignment: Resolving the Tension of 3H and Security Threats of LLMs
Mar 30, 2024



With the rise of large language models (LLMs), ensuring they embody the principles of being helpful, honest, and harmless (3H), known as Human Alignment, becomes crucial. While existing alignment methods like RLHF, DPO, etc., effectively fine-tune LLMs to match preferences in the preference dataset, they often lead LLMs to highly receptive human input and external evidence, even when this information is poisoned. This leads to a tendency for LLMs to be Adaptive Chameleons when external evidence conflicts with their parametric memory. This exacerbates the risk of LLM being attacked by external poisoned data, which poses a significant security risk to LLM system applications such as Retrieval-augmented generation (RAG). To address the challenge, we propose a novel framework: Dialectical Alignment (DA), which (1) utilizes AI feedback to identify optimal strategies for LLMs to navigate inter-context conflicts and context-memory conflicts with different external evidence in context window (i.e., different ratios of poisoned factual contexts); (2) constructs the SFT dataset as well as the preference dataset based on the AI feedback and strategies above; (3) uses the above datasets for LLM alignment to defense poisoned context attack while preserving the effectiveness of in-context knowledge editing. Our experiments show that the dialectical alignment model improves poisoned data attack defense by 20 and does not require any additional prompt engineering or prior declaration of ``you may be attacked`` to the LLMs' context window.
PROMPT-SAW: Leveraging Relation-Aware Graphs for Textual Prompt Compression
Mar 30, 2024



Large language models (LLMs) have shown exceptional abilities for multiple different natural language processing tasks. While prompting is a crucial tool for LLM inference, we observe that there is a significant cost associated with exceedingly lengthy prompts. Existing attempts to compress lengthy prompts lead to sub-standard results in terms of readability and interpretability of the compressed prompt, with a detrimental impact on prompt utility. To address this, we propose PROMPT-SAW: Prompt compresSion via Relation AWare graphs, an effective strategy for prompt compression over task-agnostic and task-aware prompts. PROMPT-SAW uses the prompt's textual information to build a graph, later extracts key information elements in the graph to come up with the compressed prompt. We also propose GSM8K-AUG, i.e., an extended version of the existing GSM8k benchmark for task-agnostic prompts in order to provide a comprehensive evaluation platform. Experimental evaluation using benchmark datasets shows that prompts compressed by PROMPT-SAW are not only better in terms of readability, but they also outperform the best-performing baseline models by up to 14.3 and 13.7 respectively for task-aware and task-agnostic settings while compressing the original prompt text by 33.0 and 56.7.