 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Information Extraction with Cross-Task and Cross-Instance High-Order Modeling
Dec 17, 2022



Prior works on Information Extraction (IE) typically predict different tasks and instances (e.g., event triggers, entities, roles, relations) independently, while neglecting their interactions and leading to model inefficiency. In this work, we introduce a joint IE framework, HighIE, that learns and predicts multiple IE tasks by integrating high-order cross-task and cross-instance dependencies. Specifically, we design two categories of high-order factors: homogeneous factors and heterogeneous factors. Then, these factors are utilized to jointly predict labels of all instances. To address the intractability problem of exact high-order inference, we incorporate a high-order neural decoder that is unfolded from a mean-field variational inference method. The experimental results show that our approach achieves consistent improvements on three IE tasks compared with our baseline and prior work.
Modeling Label Correlations for Ultra-Fine Entity Typing with Neural Pairwise Conditional Random Field
Dec 03, 2022Ultra-fine entity typing (UFET) aims to predict a wide range of type phrases that correctly describe the categories of a given entity mention in a sentence. Most recent works infer each entity type independently, ignoring the correlations between types, e.g., when an entity is inferred as a president, it should also be a politician and a leader. To this end, we use an undirected graphical model called pairwise conditional random field (PCRF) to formulate the UFET problem, in which the type variables are not only unarily influenced by the input but also pairwisely relate to all the other type variables. We use various modern backbones for entity typing to compute unary potentials, and derive pairwise potentials from type phrase representations that both capture prior semantic information and facilitate accelerated inference. We use mean-field variational inference for efficient type inference on very large type sets and unfold it as a neural network module to enable end-to-end training. Experiments on UFET show that the Neural-PCRF consistently outperforms its backbones with little cost and results in a competitive performance against cross-encoder based SOTA while being thousands of times faster. We also find Neural- PCRF effective on a widely used fine-grained entity typing dataset with a smaller type set. We pack Neural-PCRF as a network module that can be plugged onto multi-label type classifiers with ease and release it in https://github.com/modelscope/adaseq/tree/master/examples/NPCRF.
Named Entity and Relation Extraction with Multi-Modal Retrieval
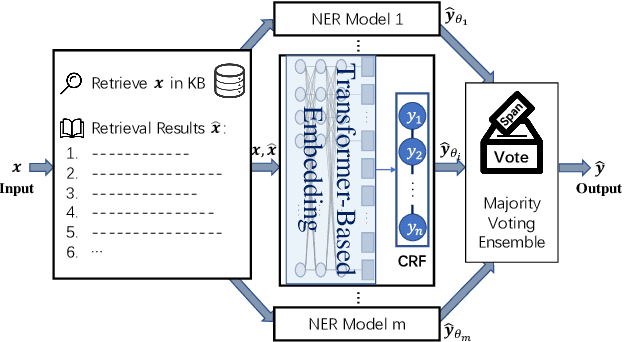
Dec 03, 2022Multi-modal named entity recognition (NER) and relation extraction (RE) aim to leverage relevant image information to improve the performance of NER and RE. Most existing efforts largely focused on directly extracting potentially useful information from images (such as pixel-level features, identified objects, and associated captions). However, such extraction processes may not be knowledge aware, resulting in information that may not be highly relevant. In this paper, we propose a novel Multi-modal Retrieval based framework (MoRe). MoRe contains a text retrieval module and an image-based retrieval module, which retrieve related knowledge of the input text and image in the knowledge corpus respectively. Next, the retrieval results are sent to the textual and visual models respectively for predictions. Finally, a Mixture of Experts (MoE) module combines the predictions from the two models to make the final decision. Our experiments show that both our textual model and visual model can achieve state-of-the-art performance on four multi-modal NER datasets and one multi-modal RE dataset. With MoE, the model performance can be further improved and our analysis demonstrates the benefits of integrating both textual and visual cues for such tasks.
Dynamic Programming in Rank Space: Scaling Structured Inference with Low-Rank HMMs and PCFGs
May 01, 2022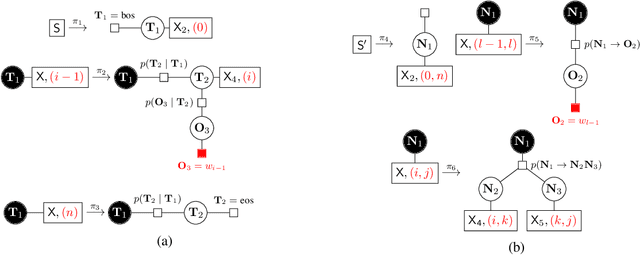
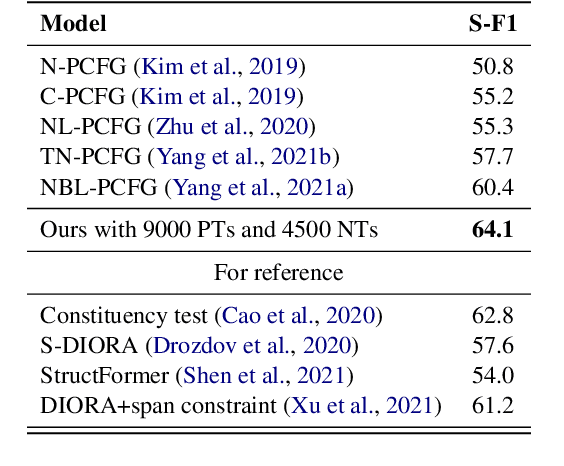
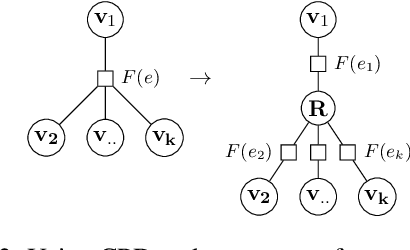
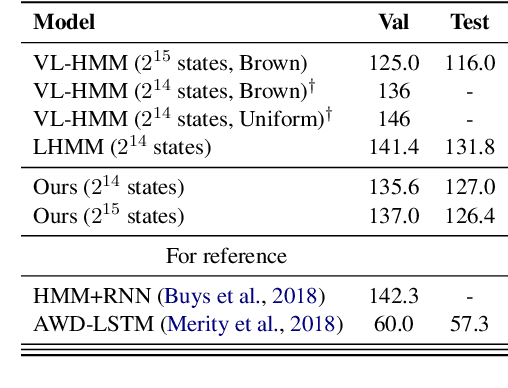
Hidden Markov Models (HMMs) and Probabilistic Context-Free Grammars (PCFGs) are widely used structured models, both of which can be represented as factor graph grammars (FGGs), a powerful formalism capable of describing a wide range of models. Recent research found it beneficial to use large state spaces for HMMs and PCFGs. However, inference with large state spaces is computationally demanding, especially for PCFGs. To tackle this challenge, we leverage tensor rank decomposition (aka.\ CPD) to decrease inference computational complexities for a subset of FGGs subsuming HMMs and PCFGs. We apply CPD on the factors of an FGG and then construct a new FGG defined in the rank space. Inference with the new FGG produces the same result but has a lower time complexity when the rank size is smaller than the state size. We conduct experiments on HMM language modeling and unsupervised PCFG parsing, showing better performance than previous work. Our code is publicly available at \url{https://github.com/VPeterV/RankSpace-Models}.
Modeling Label Correlations for Second-Order Semantic Dependency Parsing with Mean-Field Inference
Apr 07, 2022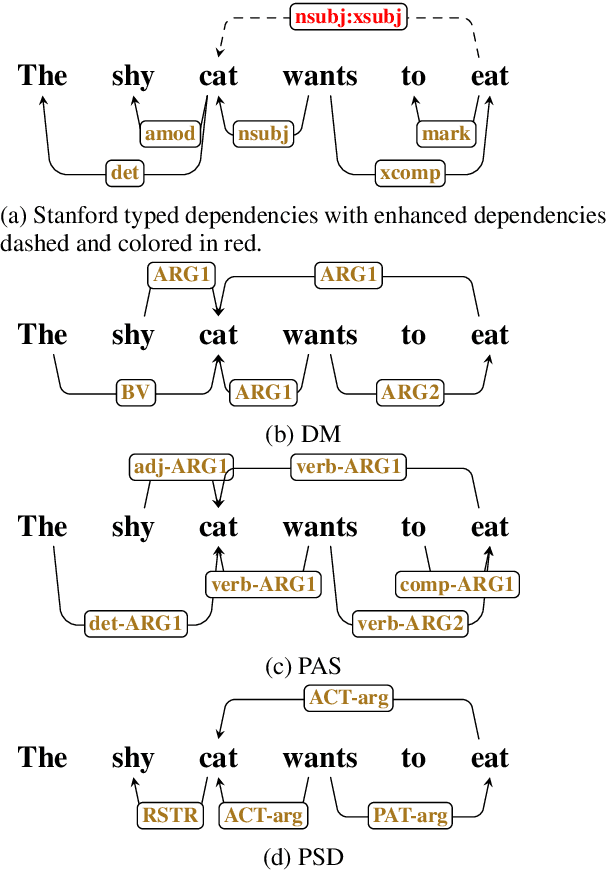
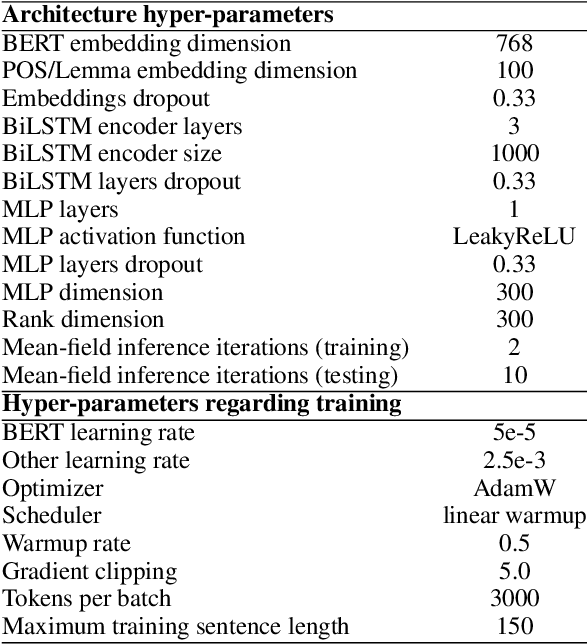
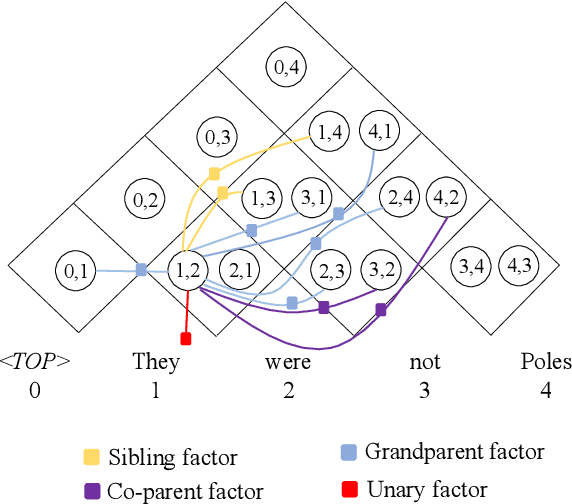
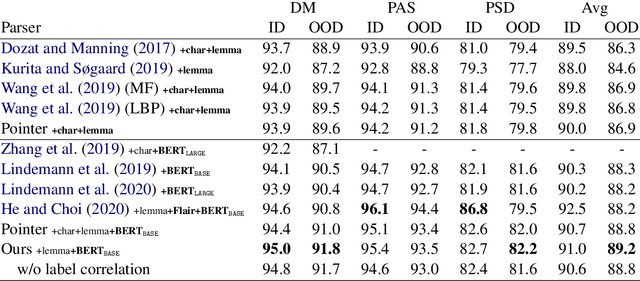
Second-order semantic parsing with end-to-end mean-field inference has been shown good performance. In this work we aim to improve this method by modeling label correlations between adjacent arcs. However, direct modeling leads to memory explosion because second-order score tensors have sizes of $O(n^3L^2)$ ($n$ is the sentence length and $L$ is the number of labels), which is not affordable. To tackle this computational challenge, we leverage tensor decomposition techniques, and interestingly, we show that the large second-order score tensors have no need to be materialized during mean-field inference, thereby reducing the computational complexity from cubic to quadratic. We conduct experiments on SemEval 2015 Task 18 English datasets, showing the effectiveness of modeling label correlations. Our code is publicly available at https://github.com/sustcsonglin/mean-field-dep-parsing.
Nested Named Entity Recognition as Latent Lexicalized Constituency Parsing
Mar 09, 2022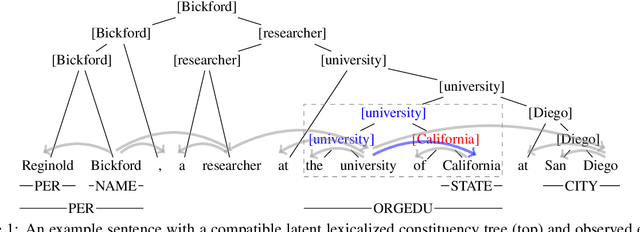
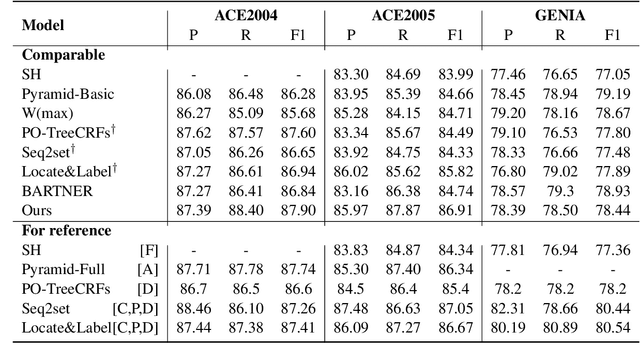
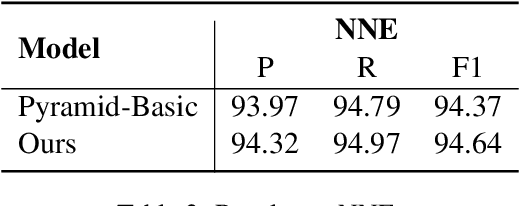

Nested named entity recognition (NER) has been receiving increasing attention. Recently, (Fu et al, 2021) adapt a span-based constituency parser to tackle nested NER. They treat nested entities as partially-observed constituency trees and propose the masked inside algorithm for partial marginalization. However, their method cannot leverage entity heads, which have been shown useful in entity mention detection and entity typing. In this work, we resort to more expressive structures, lexicalized constituency trees in which constituents are annotated by headwords, to model nested entities. We leverage the Eisner-Satta algorithm to perform partial marginalization and inference efficiently. In addition, we propose to use (1) a two-stage strategy (2) a head regularization loss and (3) a head-aware labeling loss in order to enhance the performance. We make a thorough ablation study to investigate the functionality of each component. Experimentally, our method achieves the state-of-the-art performance on ACE2004, ACE2005 and NNE, and competitive performance on GENIA, and meanwhile has a fast inference speed.
DAMO-NLP at SemEval-2022 Task 11: A Knowledge-based System for Multilingual Named Entity Recognition
Mar 01, 2022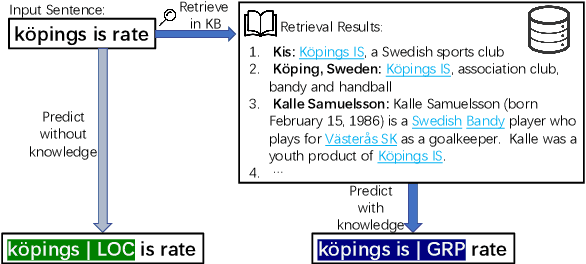

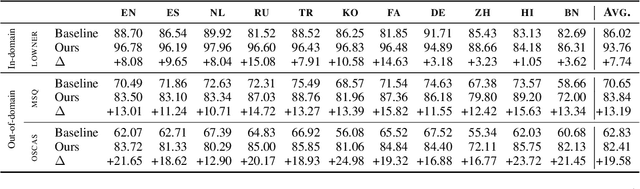
The MultiCoNER shared task aims at detecting semantically ambiguous and complex named entities in short and low-context settings for multiple languages. The lack of contexts makes the recognition of ambiguous named entities challenging. To alleviate this issue, our team DAMO-NLP proposes a knowledge-based system, where we build a multilingual knowledge base based on Wikipedia to provide related context information to the named entity recognition (NER) model. Given an input sentence, our system effectively retrieves related contexts from the knowledge base. The original input sentences are then augmented with such context information, allowing significantly better contextualized token representations to be captured. Our system wins 10 out of 13 tracks in the MultiCoNER shared task.
ITA: Image-Text Alignments for Multi-Modal Named Entity Recognition
Dec 13, 2021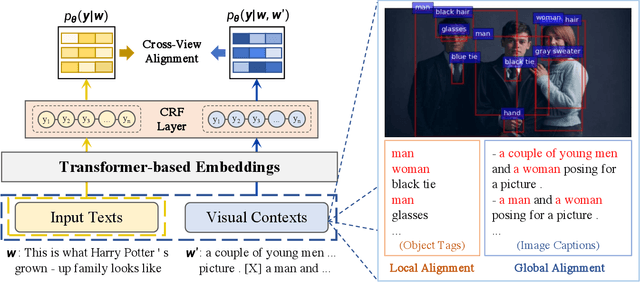
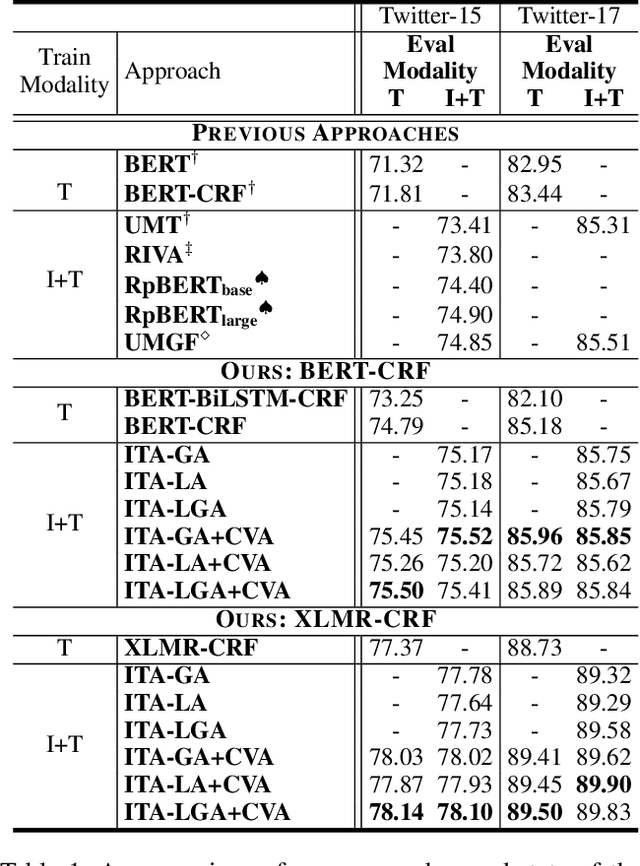
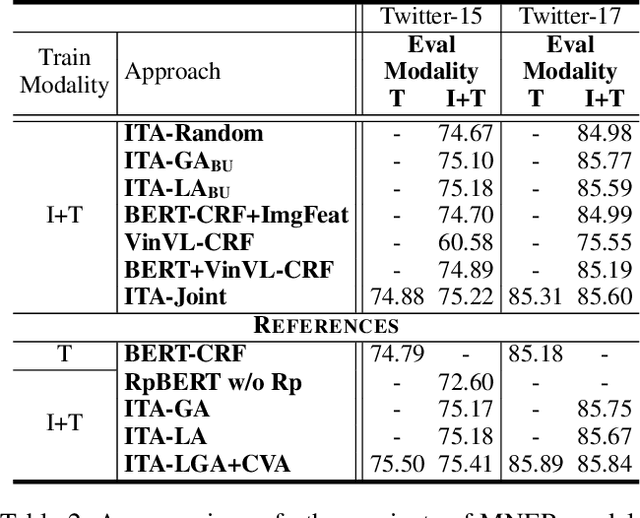
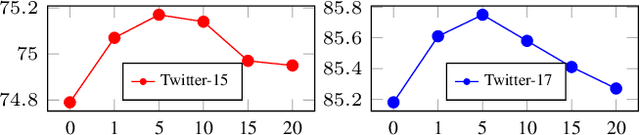
Recently, Multi-modal Named Entity Recognition (MNER) has attracted a lot of attention. Most of the work utilizes image information through region-level visual representations obtained from a pretrained object detector and relies on an attention mechanism to model the interactions between image and text representations. However, it is difficult to model such interactions as image and text representations are trained separately on the data of their respective modality and are not aligned in the same space. As text representations take the most important role in MNER, in this paper, we propose {\bf I}mage-{\bf t}ext {\bf A}lignments (ITA) to align image features into the textual space, so that the attention mechanism in transformer-based pretrained textual embeddings can be better utilized. ITA first locally and globally aligns regional object tags and image-level captions as visual contexts, concatenates them with the input texts as a new cross-modal input, and then feeds it into a pretrained textual embedding model. This makes it easier for the attention module of a pretrained textual embedding model to model the interaction between the two modalities since they are both represented in the textual space. ITA further aligns the output distributions predicted from the cross-modal input and textual input views so that the MNER model can be more practical and robust to noises from images. In our experiments, we show that ITA models can achieve state-of-the-art accuracy on multi-modal Named Entity Recognition datasets, even without image information.
Bottom-Up Constituency Parsing and Nested Named Entity Recognition with Pointer Networks
Oct 11, 2021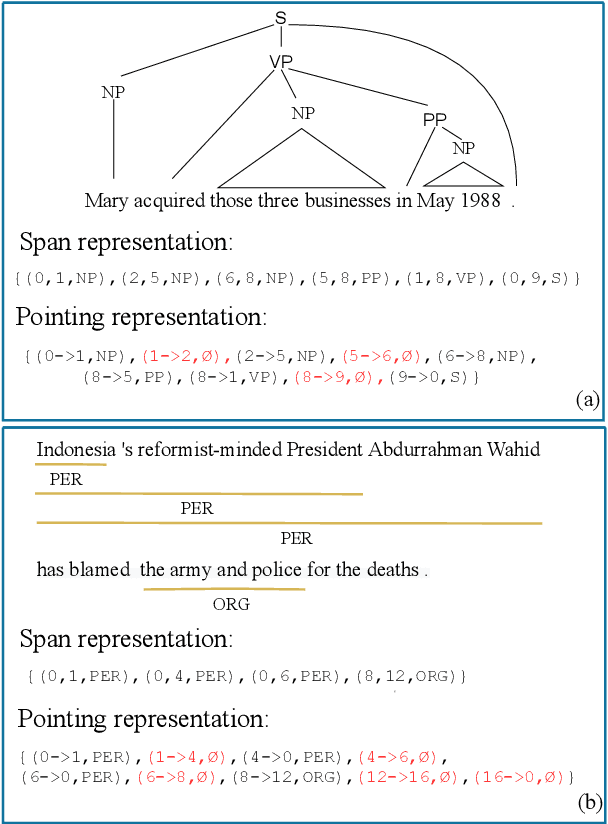

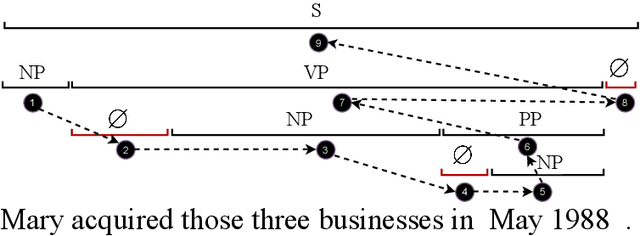
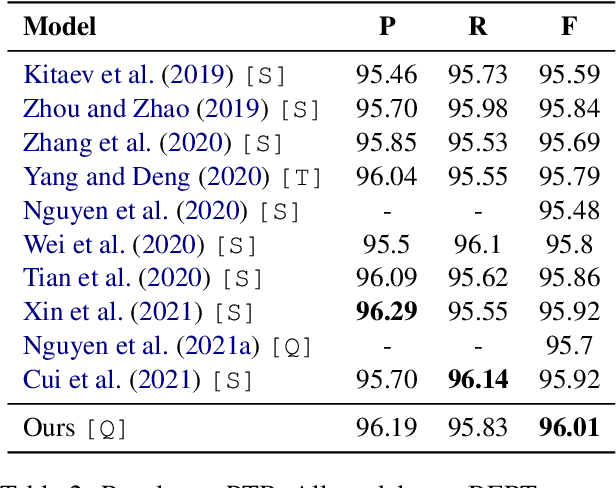
Constituency parsing and nested named entity recognition (NER) are typical \textit{nested structured prediction} tasks since they both aim to predict a collection of nested and non-crossing spans. There are many previous studies adapting constituency parsing methods to tackle nested NER. In this work, we propose a novel global pointing mechanism for bottom-up parsing with pointer networks to do both tasks, which needs linear steps to parse. Our method obtain the state-of-the-art performance on PTB among all BERT-based models (96.01 F1 score) and competitive performance on CTB7 in constituency parsing; and comparable performance on three benchmark datasets of nested NER: ACE2004, ACE2005, and GENIA. Our code is publicly available at \url{https://github.com/sustcsonglin/pointer-net-for-nested}
Combining graph-based and headed span-based projective dependency parsing
Aug 12, 2021
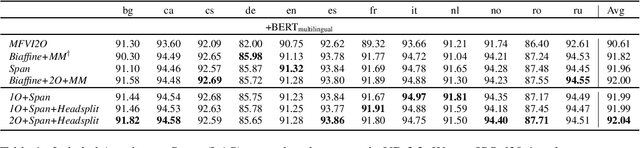
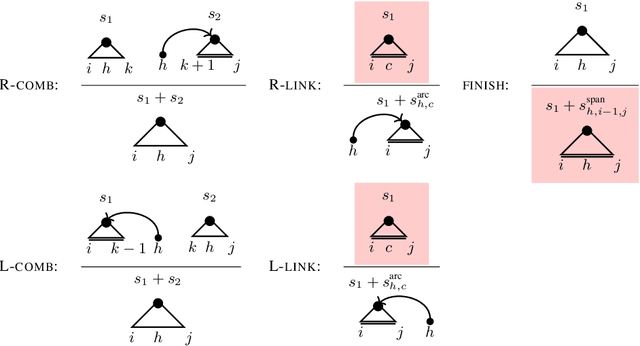
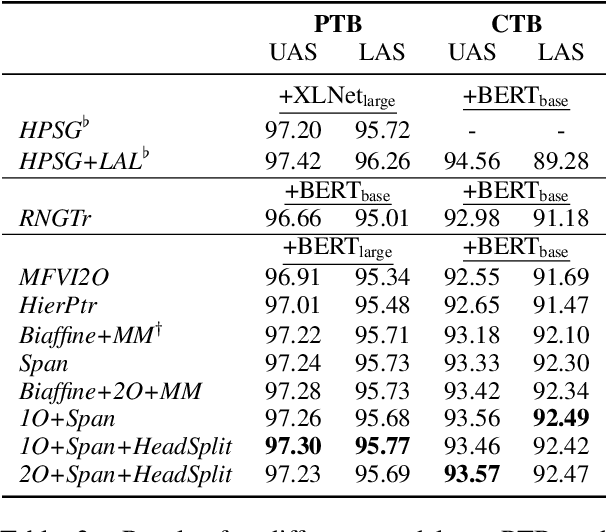
Graph-based methods are popular in dependency parsing for decades. Recently, \citet{yang2021headed} propose a headed span-based method. Both of them score all possible trees and globally find the highest-scoring tree. In this paper, we combine these two kinds of methods, designing several dynamic programming algorithms for joint inference. Experiments show the effectiveness of our proposed methods\footnote{Our code is publicly available at \url{https://github.com/sustcsonglin/span-based-dependency-parsing}.}.