 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlex: Towards Reliability using Pretrained Large Model Extensions
Jul 15, 2022

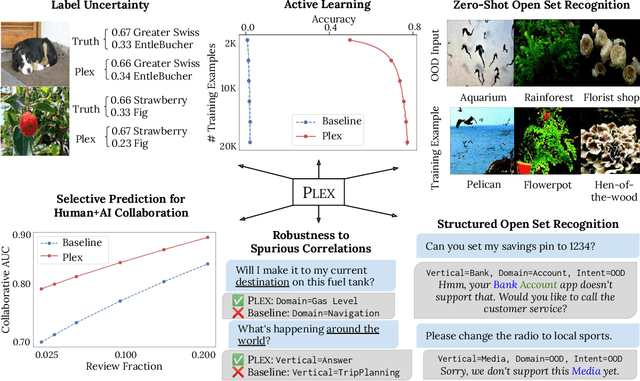

A recent trend in artificial intelligence is the use of pretrained models for language and vision tasks, which have achieved extraordinary performance but also puzzling failures. Probing these models' abilities in diverse ways is therefore critical to the field. In this paper, we explore the reliability of models, where we define a reliable model as one that not only achieves strong predictive performance but also performs well consistently over many decision-making tasks involving uncertainty (e.g., selective prediction, open set recognition), robust generalization (e.g., accuracy and proper scoring rules such as log-likelihood on in- and out-of-distribution datasets), and adaptation (e.g., active learning, few-shot uncertainty). We devise 10 types of tasks over 40 datasets in order to evaluate different aspects of reliability on both vision and language domains. To improve reliability, we developed ViT-Plex and T5-Plex, pretrained large model extensions for vision and language modalities, respectively. Plex greatly improves the state-of-the-art across reliability tasks, and simplifies the traditional protocol as it improves the out-of-the-box performance and does not require designing scores or tuning the model for each task. We demonstrate scaling effects over model sizes up to 1B parameters and pretraining dataset sizes up to 4B examples. We also demonstrate Plex's capabilities on challenging tasks including zero-shot open set recognition, active learning, and uncertainty in conversational language understanding.
Hands-free Telelocomotion of a Wheeled Humanoid toward Dynamic Mobile Manipulation via Teleoperation
Mar 07, 2022
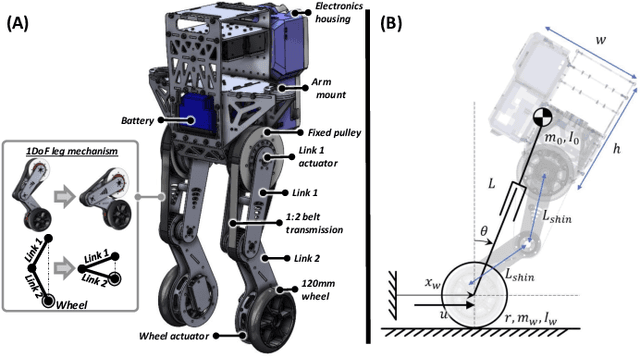
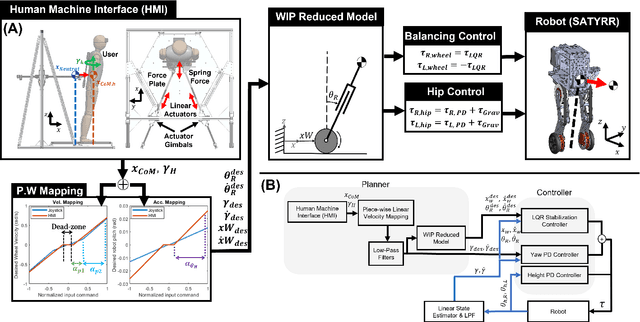
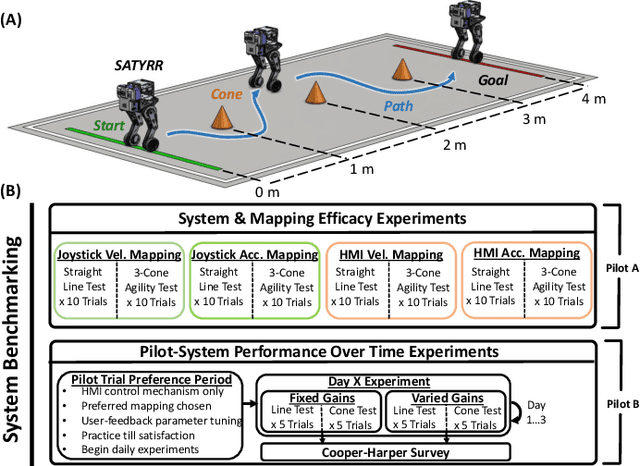
Robotic systems that can dynamically combine manipulation and locomotion could facilitate dangerous or physically demanding labor. For instance, firefighter humanoid robots could leverage their body by leaning against collapsed building rubble to push it aside. Here we introduce a teleoperation system that targets the realization of these tasks using human whole-body motor skills. We describe a new wheeled humanoid platform, SATYRR, and a novel hands-free teleoperation architecture using a whole-body Human Machine Interface (HMI). This system enables telelocomotion of the humanoid robot using the operator body motion, freeing their arms for manipulation tasks. In this study we evaluate the efficacy of the proposed system on hardware, and explore the control of SATYRR using two teleoperation mappings that map the operators body pitch and twist to the robot velocity or acceleration. Through experiments and user feedback we showcase our preliminary findings of the pilot-system response. Results suggest that the HMI is capable of effectively telelocomoting SATYRR, that pilot preferences should dictate the appropriate motion mapping and gains, and finally that the pilot can better learn to control the system over time. This study represents a fundamental step towards the realization of combined manipulation and locomotion via teleoperation.
Efficient Online Bayesian Inference for Neural Bandits
Dec 01, 2021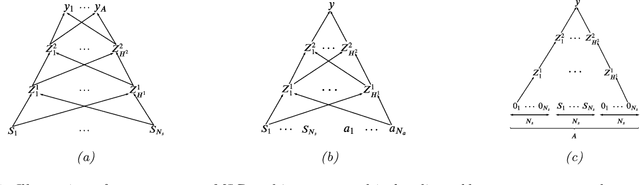
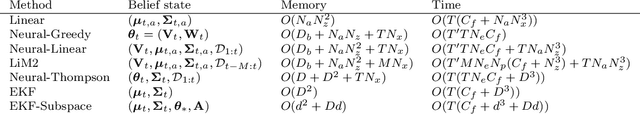
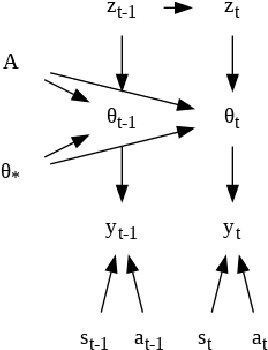
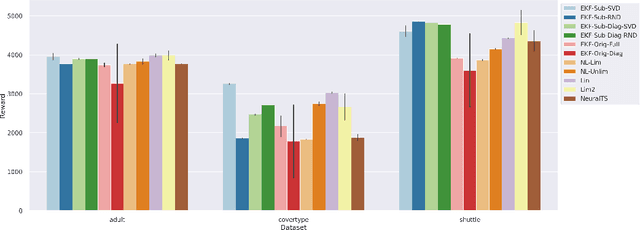
In this paper we present a new algorithm for online (sequential) inference in Bayesian neural networks, and show its suitability for tackling contextual bandit problems. The key idea is to combine the extended Kalman filter (which locally linearizes the likelihood function at each time step) with a (learned or random) low-dimensional affine subspace for the parameters; the use of a subspace enables us to scale our algorithm to models with $\sim 1M$ parameters. While most other neural bandit methods need to store the entire past dataset in order to avoid the problem of "catastrophic forgetting", our approach uses constant memory. This is possible because we represent uncertainty about all the parameters in the model, not just the final linear layer. We show good results on the "Deep Bayesian Bandit Showdown" benchmark, as well as MNIST and a recommender system.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021
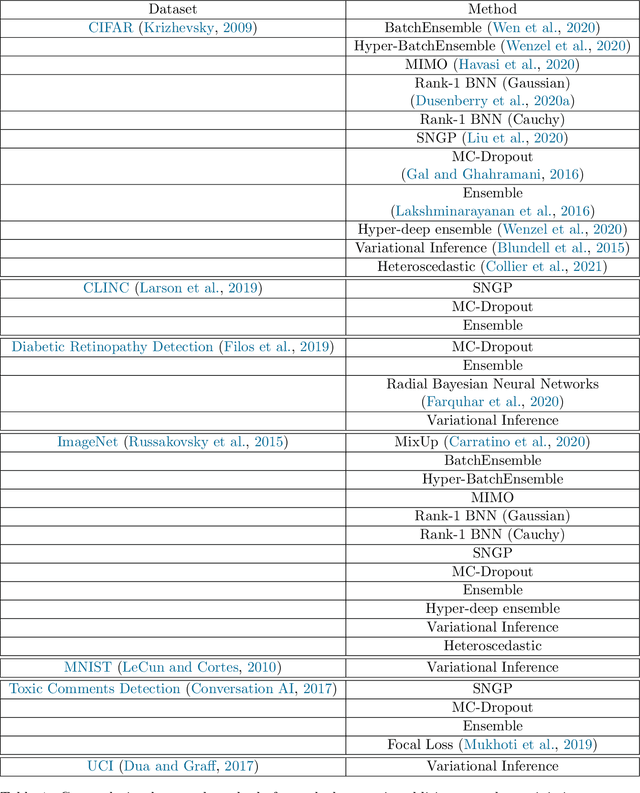
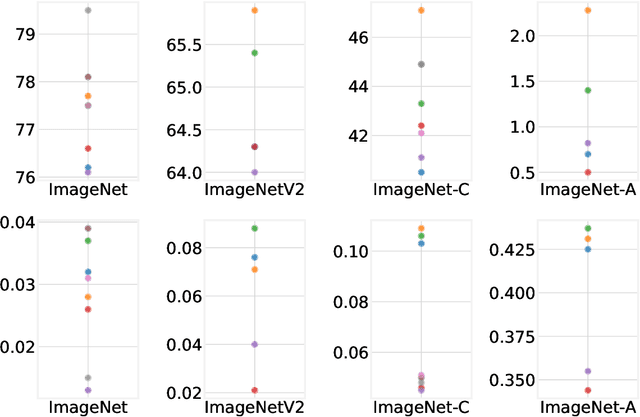
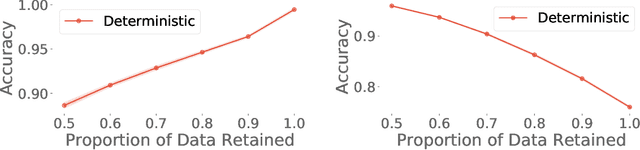
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Risk score learning for COVID-19 contact tracing apps
Apr 17, 2021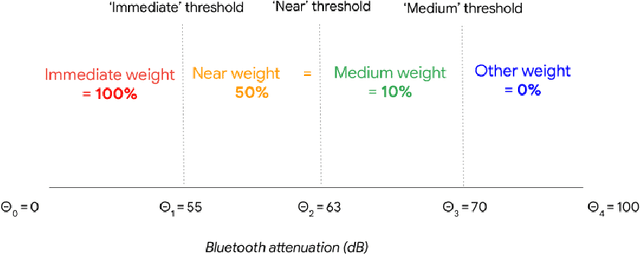
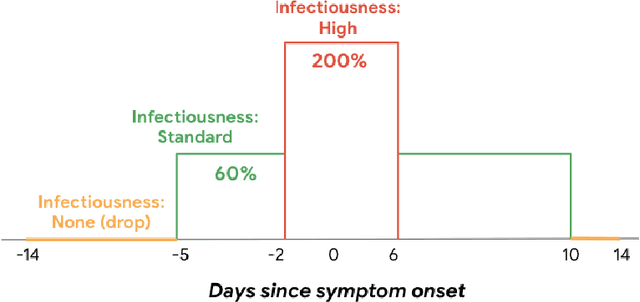
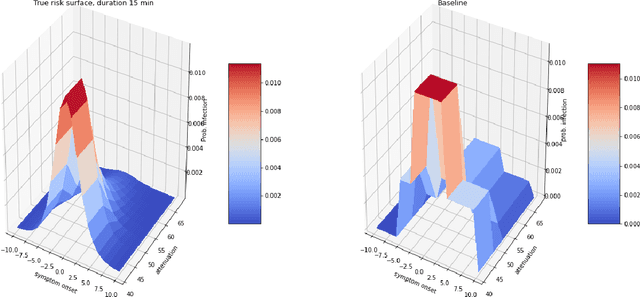
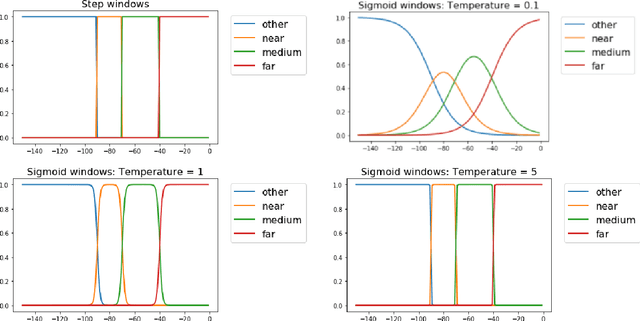
Digital contact tracing apps for COVID-19, such as the one developed by Google and Apple, need to estimate the risk that a user was infected during a particular exposure, in order to decide whether to notify the user to take precautions, such as entering into quarantine, or requesting a test. Such risk score models contain numerous parameters that must be set by the public health authority. Although expert guidance for how to set these parameters has been provided (e.g. https://github.com/lfph/gaen-risk-scoring/blob/main/risk-scoring.md), it is natural to ask if we could do better using a data-driven approach. This can be particularly useful when the risk factors of the disease change, e.g., due to the evolution of new variants, or the adoption of vaccines. In this paper, we show that machine learning methods can be used to automatically optimize the parameters of the risk score model, provided we have access to exposure and outcome data. Although this data is already being collected in an aggregated, privacy-preserving way by several health authorities, in this paper we limit ourselves to simulated data, so that we can systematically study the different factors that affect the feasibility of the approach. In particular, we show that the parameters become harder to estimate when there is more missing data (e.g., due to infections which were not recorded by the app). Nevertheless, the learning approach outperforms a strong manually designed baseline.
HOPPY: An Open-source Kit for Education with Dynamic Legged Robots
Mar 15, 2021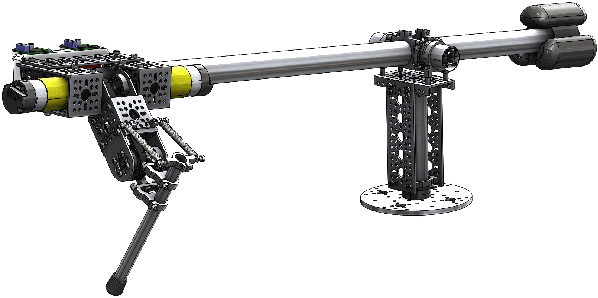
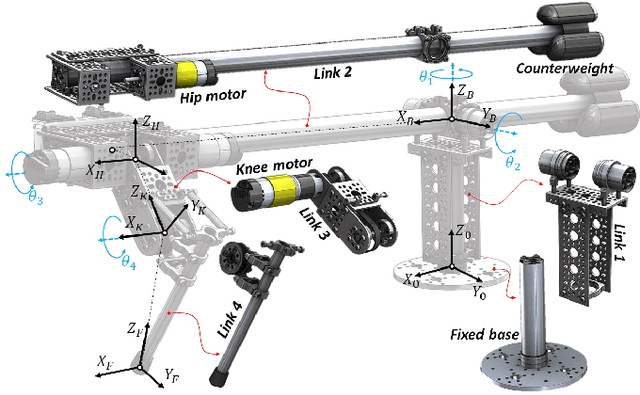
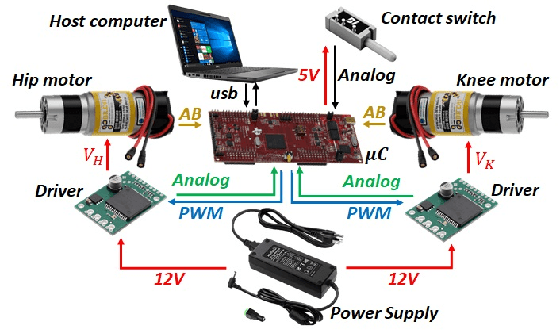
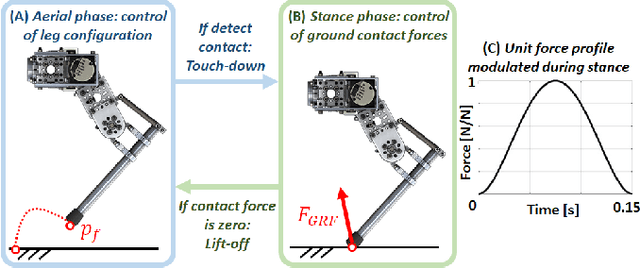
This paper introduces HOPPY, an open-source, low-cost, robust, and modular kit for robotics education. The robot dynamically hops around a rotating gantry with a fixed base. The kit is intended to lower the entry barrier for studying dynamic robots and legged locomotion with real systems. It bridges the theoretical content of fundamental robotic courses with real dynamic robots by facilitating and guiding the software and hardware integration. This paper describes the topics which can be studied using the kit, lists its components, discusses preferred practices for implementation, presents results from experiments with the simulator and the real system, and suggests further improvements. A simple heuristic-based controller is described to achieve velocities up to 1.7m/s, navigate small objects, and mitigate external disturbances when the robot is aided by a counterweight. HOPPY was utilized as the subject of a semester-long project for the Robot Dynamics and Control course at the University of Illinois at Urbana-Champaign. The positive feedback from the students and instructors about the hands-on activities during the course motivates us to share this kit and continue improving in the future.
A Comparison Between Joint Space and Task Space Mappings for Dynamic Teleoperation of an Anthropomorphic Robotic Arm in Reaction Tests
Nov 04, 2020
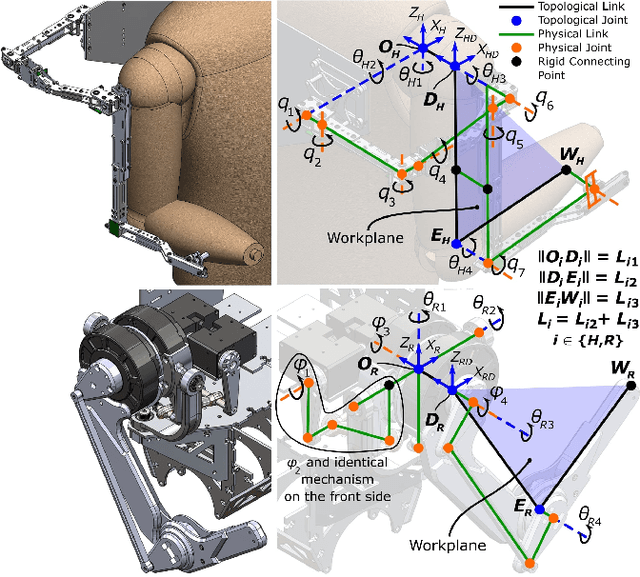
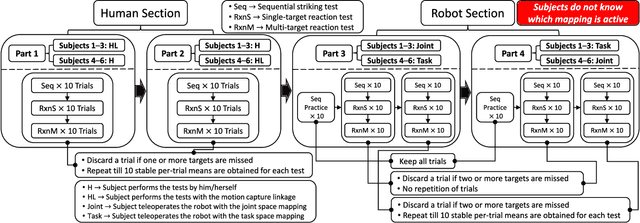
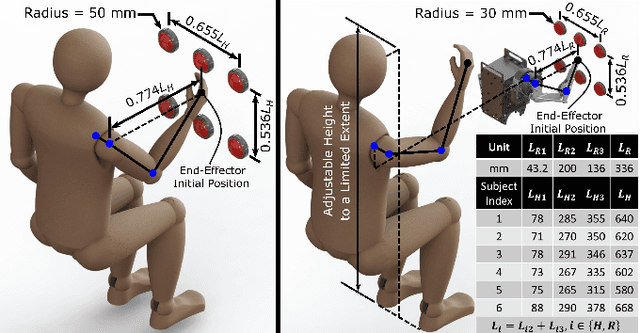
Teleoperation (i.e., controlling a robot with human motion) proves promising in enabling a humanoid robot to move as dynamically as a human. But how to map human motion to a humanoid robot matters because a human and a humanoid robot rarely have identical topologies and dimensions. This work presents an experimental study that utilizes reaction tests to compare the proposed joint space mapping and the proposed task space mapping for dynamic teleoperation of an anthropomorphic robotic arm that possesses human-level dynamic motion capabilities. The experimental results suggest that the robot achieved similar and, in some cases, human-level dynamic performances with both mappings for the six participating human subjects. All subjects became proficient at teleoperating the robot with both mappings after practice, despite that the subjects and the robot differed in size and link length ratio and that the teleoperation required the subjects to move unintuitively. Yet, most subjects developed their teleoperation proficiencies more quickly with the task space mapping than with the joint space mapping after similar amounts of practice. This study also indicates the potential values of a three-dimensional task space mapping, a teleoperation training simulator, and force feedback to the human pilot for intuitive and dynamic teleoperation of a humanoid robot's arms.
HOPPY: An open-source and low-cost kit for dynamic robotics education
Oct 27, 2020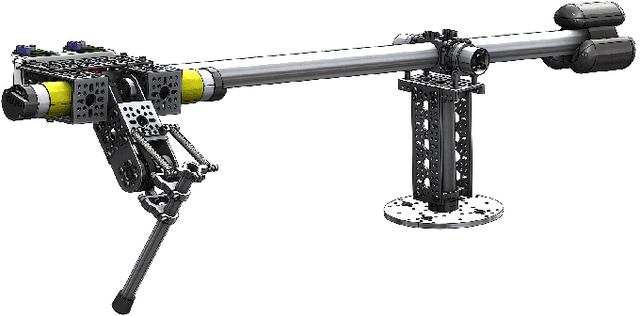
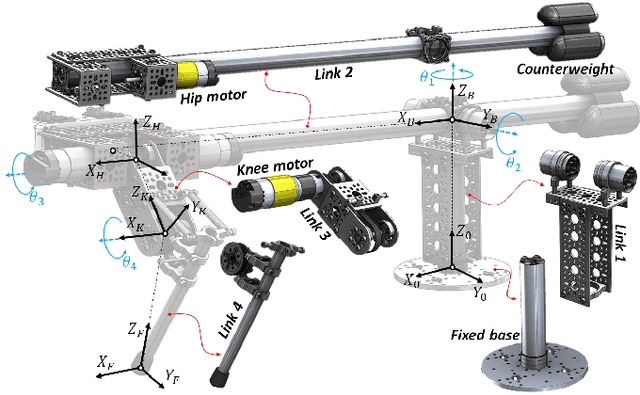
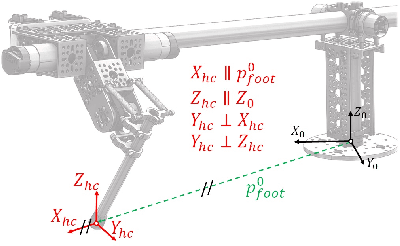
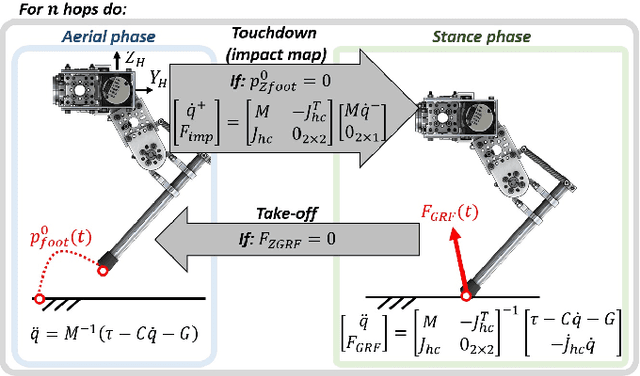
This letter introduces HOPPY, an open-source, low-cost, robust, and modular kit for robotics education. The robot dynamically hops around a rotating gantry with a fixed base. The kit lowers the entry barrier for studying dynamic robots and legged locomotion in real systems. The kit bridges the theoretical content of fundamental robotic courses and real dynamic robots by facilitating and guiding the software and hardware integration. This letter describes the topics which can be studied using the kit, lists its components, discusses best practices for implementation, presents results from experiments with the simulator and the real system, and suggests further improvements. A simple controller is described to achieve velocities up to 2m/s, navigate small objects, and mitigate external disturbances (kicks). HOPPY was utilized as the topic of a semester-long project for the Robot Dynamics and Control course at the University of Illinois at Urbana-Champaign. Students provided an overwhelmingly positive feedback from the hands-on activities during the course and the instructors will continue to improve the kit for upcoming semesters.
Population-Based Black-Box Optimization for Biological Sequence Design
Jun 05, 2020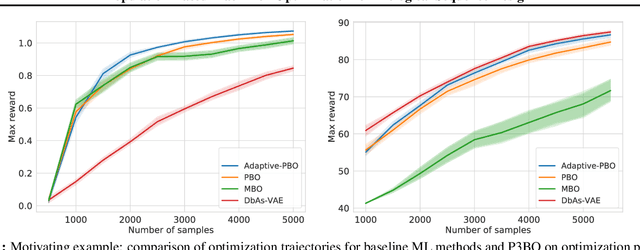
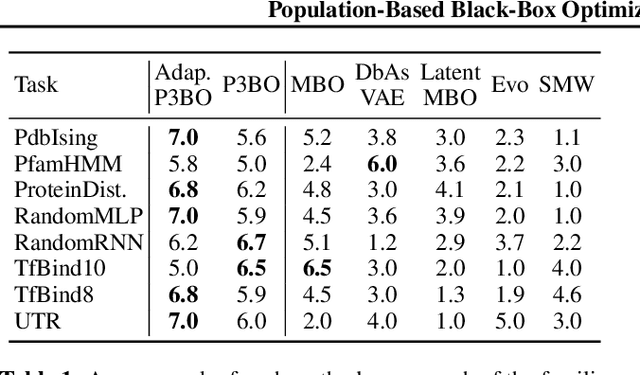
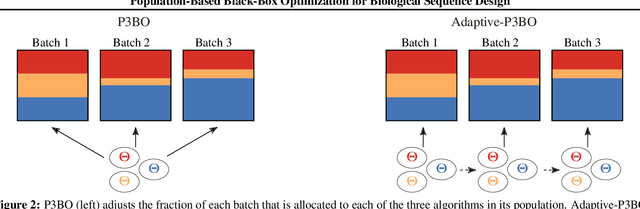
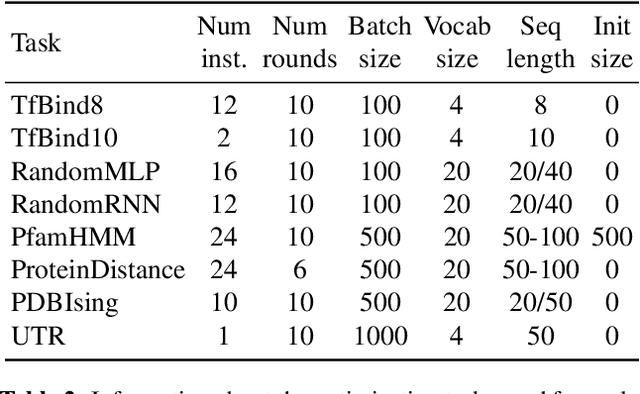
The use of black-box optimization for the design of new biological sequences is an emerging research area with potentially revolutionary impact. The cost and latency of wet-lab experiments requires methods that find good sequences in few experimental rounds of large batches of sequences--a setting that off-the-shelf black-box optimization methods are ill-equipped to handle. We find that the performance of existing methods varies drastically across optimization tasks, posing a significant obstacle to real-world applications. To improve robustness, we propose Population-Based Black-Box Optimization (P3BO), which generates batches of sequences by sampling from an ensemble of methods. The number of sequences sampled from any method is proportional to the quality of sequences it previously proposed, allowing P3BO to combine the strengths of individual methods while hedging against their innate brittleness. Adapting the hyper-parameters of each of the methods online using evolutionary optimization further improves performance. Through extensive experiments on in-silico optimization tasks, we show that P3BO outperforms any single method in its population, proposing higher quality sequences as well as more diverse batches. As such, P3BO and Adaptive-P3BO are a crucial step towards deploying ML to real-world sequence design.
Machine Learning on Graphs: A Model and Comprehensive Taxonomy
May 07, 2020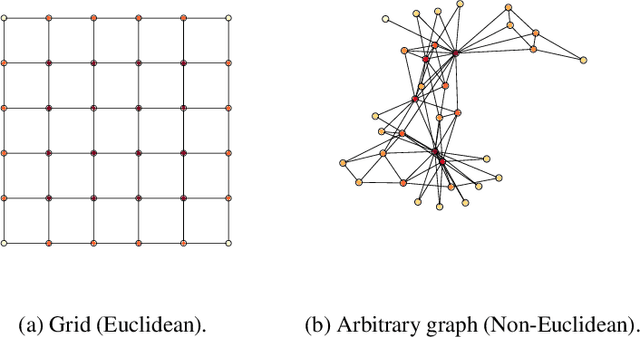
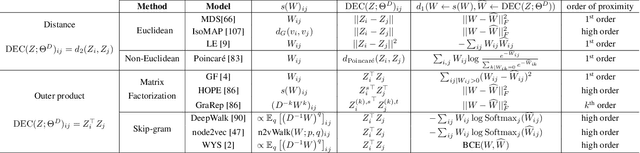
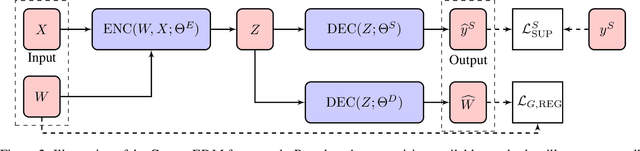

There has been a surge of recent interest in learning representations for graph-structured data. Graph representation learning methods have generally fallen into three main categories, based on the availability of labeled data. The first, network embedding (such as shallow graph embedding or graph auto-encoders), focuses on learning unsupervised representations of relational structure. The second, graph regularized neural networks, leverages graphs to augment neural network losses with a regularization objective for semi-supervised learning. The third, graph neural networks, aims to learn differentiable functions over discrete topologies with arbitrary structure. However, despite the popularity of these areas there has been surprisingly little work on unifying the three paradigms. Here, we aim to bridge the gap between graph neural networks, network embedding and graph regularization models. We propose a comprehensive taxonomy of representation learning methods for graph-structured data, aiming to unify several disparate bodies of work. Specifically, we propose a Graph Encoder Decoder Model (GRAPHEDM), which generalizes popular algorithms for semi-supervised learning on graphs (e.g. GraphSage, Graph Convolutional Networks, Graph Attention Networks), and unsupervised learning of graph representations (e.g. DeepWalk, node2vec, etc) into a single consistent approach. To illustrate the generality of this approach, we fit over thirty existing methods into this framework. We believe that this unifying view both provides a solid foundation for understanding the intuition behind these methods, and enables future research in the area.