 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Bidirectional Transformer for Temporal Representation Learning
Paper and Code
Jun 13, 2019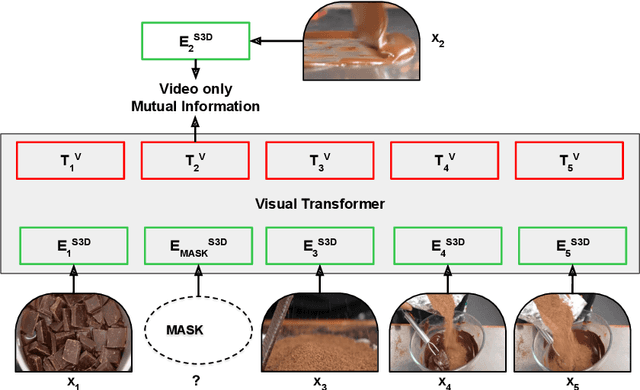

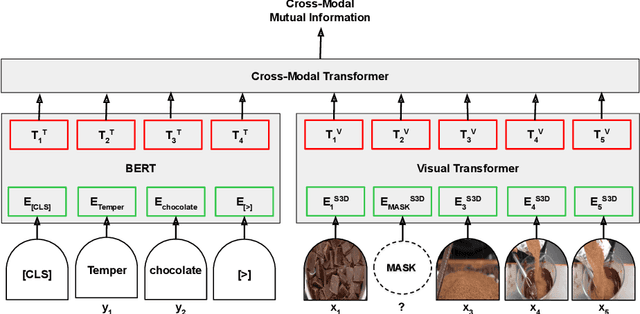
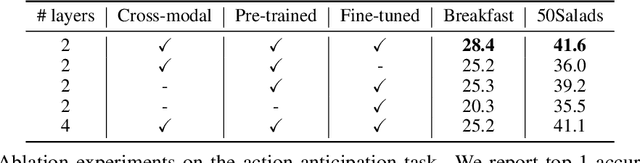
This paper aims at learning representations for long sequences of continuous signals. Recently, the BERT model has demonstrated the effectiveness of stacked transformers for representing sequences of discrete signals (i.e. word tokens). Inspired by its success, we adopt the stacked transformer architecture, but generalize its training objective to maximize the mutual information between the masked signals, and the bidirectional context, via contrastive loss. This enables the model to handle continuous signals, such as visual features. We further consider the case when there are multiple sequences that are semantically aligned at the sequence-level but not at the element-level (e.g. video and ASR), where we propose to use a Transformer to estimate the mutual information between the two sequences, which is again maximized via contrastive loss. We demonstrate the effectiveness of the learned representations on modeling long video sequences for action anticipation and video captioning. The results show that our method, referred to by Contrastive Bidirectional Transformer ({\bf CBT}), outperforms various baselines significantly. Furthermore, we improve over the state of the art.