 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Scientific Creativity with Retrieval across Knowledge Domains
Jun 02, 2022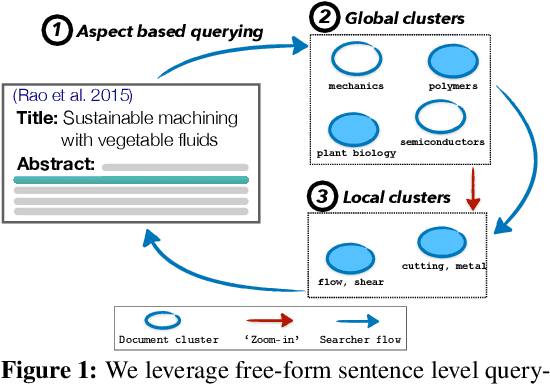
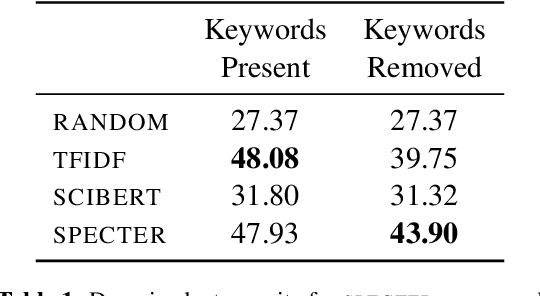

Exposure to ideas in domains outside a scientist's own may benefit her in reformulating existing research problems in novel ways and discovering new application domains for existing solution ideas. While improved performance in scholarly search engines can help scientists efficiently identify relevant advances in domains they may already be familiar with, it may fall short of helping them explore diverse ideas \textit{outside} such domains. In this paper we explore the design of systems aimed at augmenting the end-user ability in cross-domain exploration with flexible query specification. To this end, we develop an exploratory search system in which end-users can select a portion of text core to their interest from a paper abstract and retrieve papers that have a high similarity to the user-selected core aspect but differ in terms of domains. Furthermore, end-users can `zoom in' to specific domain clusters to retrieve more papers from them and understand nuanced differences within the clusters. Our case studies with scientists uncover opportunities and design implications for systems aimed at facilitating cross-domain exploration and inspiration.
CEM-GD: Cross-Entropy Method with Gradient Descent Planner for Model-Based Reinforcement Learning
Dec 14, 2021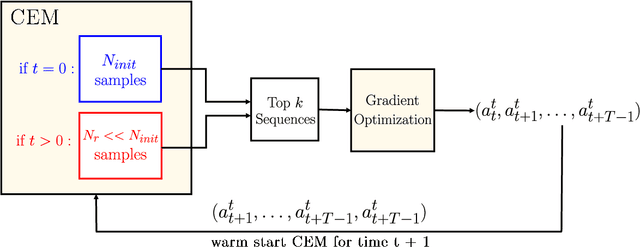
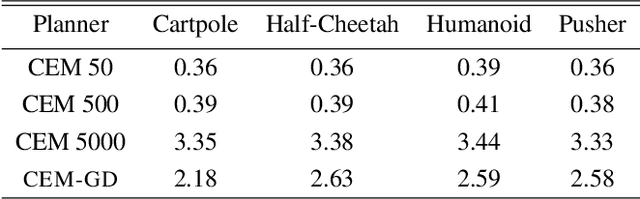
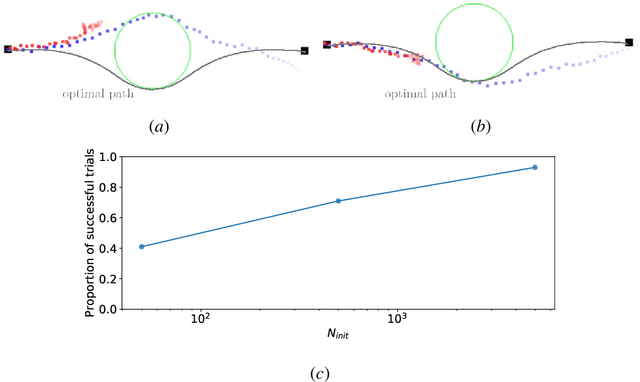
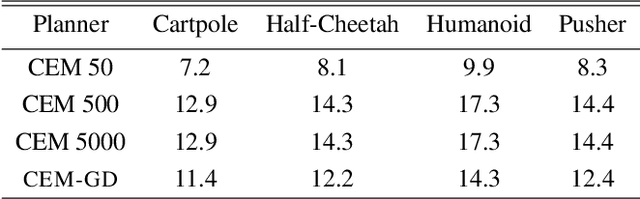
Current state-of-the-art model-based reinforcement learning algorithms use trajectory sampling methods, such as the Cross-Entropy Method (CEM), for planning in continuous control settings. These zeroth-order optimizers require sampling a large number of trajectory rollouts to select an optimal action, which scales poorly for large prediction horizons or high dimensional action spaces. First-order methods that use the gradients of the rewards with respect to the actions as an update can mitigate this issue, but suffer from local optima due to the non-convex optimization landscape. To overcome these issues and achieve the best of both worlds, we propose a novel planner, Cross-Entropy Method with Gradient Descent (CEM-GD), that combines first-order methods with CEM. At the beginning of execution, CEM-GD uses CEM to sample a significant amount of trajectory rollouts to explore the optimization landscape and avoid poor local minima. It then uses the top trajectories as initialization for gradient descent and applies gradient updates to each of these trajectories to find the optimal action sequence. At each subsequent time step, however, CEM-GD samples much fewer trajectories from CEM before applying gradient updates. We show that as the dimensionality of the planning problem increases, CEM-GD maintains desirable performance with a constant small number of samples by using the gradient information, while avoiding local optima using initially well-sampled trajectories. Furthermore, CEM-GD achieves better performance than CEM on a variety of continuous control benchmarks in MuJoCo with 100x fewer samples per time step, resulting in around 25% less computation time and 10% less memory usage. The implementation of CEM-GD is available at $\href{https://github.com/KevinHuang8/CEM-GD}{\text{https://github.com/KevinHuang8/CEM-GD}}$.
Towards Cross-Cultural Analysis using Music Information Dynamics
Nov 24, 2021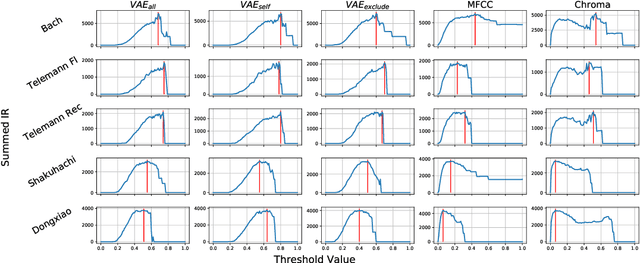
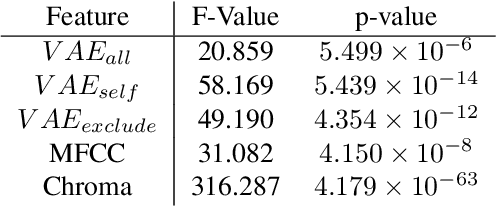
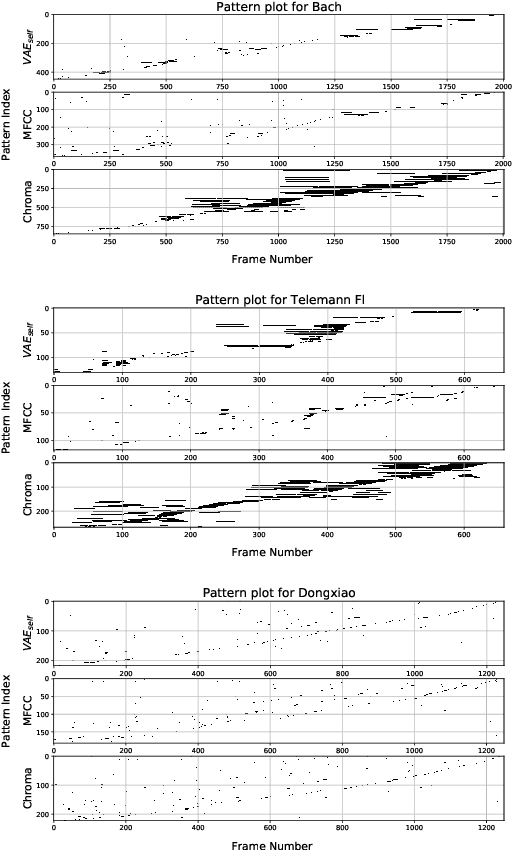
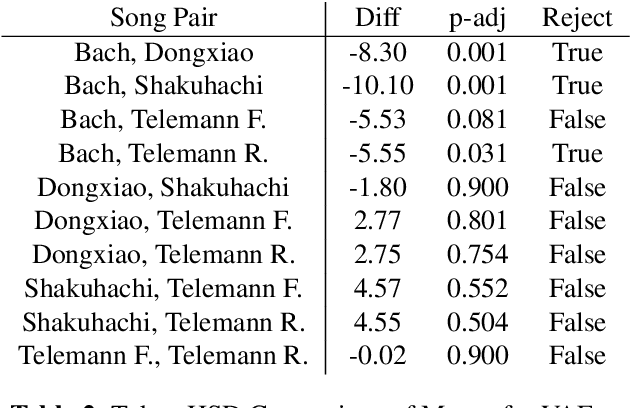
A music piece is both comprehended hierarchically, from sonic events to melodies, and sequentially, in the form of repetition and variation. Music from different cultures establish different aesthetics by having different style conventions on these two aspects. We propose a framework that could be used to quantitatively compare music from different cultures by looking at these two aspects. The framework is based on an Music Information Dynamics model, a Variable Markov Oracle (VMO), and is extended with a variational representation learning of audio. A variational autoencoder (VAE) is trained to map audio fragments into a latent representation. The latent representation is fed into a VMO. The VMO then learns a clustering of the latent representation via a threshold that maximizes the information rate of the quantized latent representation sequence. This threshold effectively controls the sensibility of the predictive step to acoustic changes, which determines the framework's ability to track repetitions on longer time scales. This approach allows characterization of the overall information contents of a musical signal at each level of acoustic sensibility. Our findings under this framework show that sensibility to subtle acoustic changes is higher for East-Asian musical traditions, while the Western works exhibit longer motivic structures at higher thresholds of differences in the latent space. This suggests that a profile of information contents, analyzed as a function of the level of acoustic detail can serve as a possible cultural characteristic.
Multiple regression techniques for modeling dates of first performances of Shakespeare-era plays
Apr 14, 2021
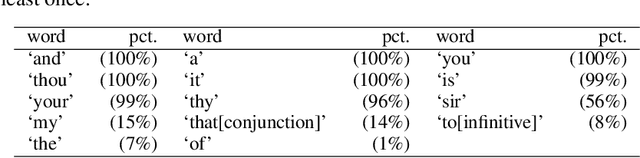
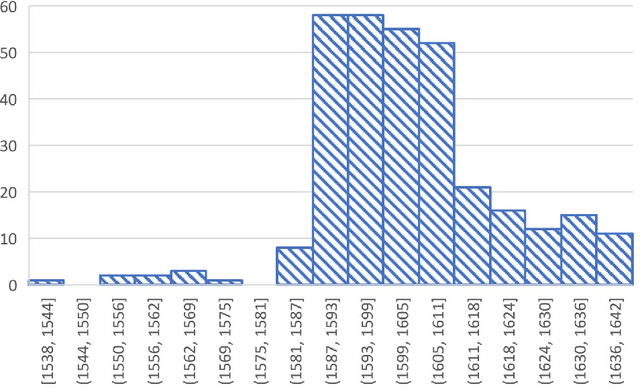
The date of the first performance of a play of Shakespeare's time must usually be guessed with reference to multiple indirect external sources, or to some aspect of the content or style of the play. Identifying these dates is important to literary history and to accounts of developing authorial styles, such as Shakespeare's. In this study, we took a set of Shakespeare-era plays (181 plays from the period 1585--1610), added the best-guess dates for them from a standard reference work as metadata, and calculated a set of probabilities of individual words in these samples. We applied 11 regression methods to predict the dates of the plays at an 80/20 training/test split. We withdrew one play at a time, used the best-guess date metadata with the probabilities and weightings to infer its date, and thus built a model of date-probabilities interaction. We introduced a memetic algorithm-based Continued Fraction Regression (CFR) which delivered models using a small number of variables, leading to an interpretable model and reduced dimensionality. An in-depth analysis of the most commonly occurring 20 words in the CFR models in 100 independent runs helps explain the trends in linguistic and stylistic terms. The analysis with the subset of words revealed an interesting correlation of signature words with the Shakespeare-era play's genre.
Accelerating Road Sign Ground Truth Construction with Knowledge Graph and Machine Learning
Dec 04, 2020
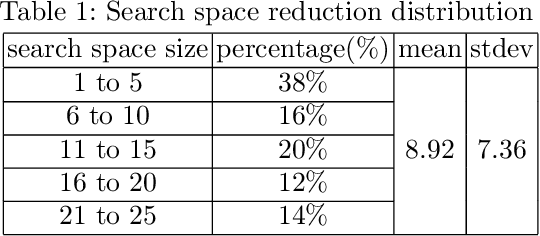


Having a comprehensive, high-quality dataset of road sign annotation is critical to the success of AI-based Road Sign Recognition (RSR) systems. In practice, annotators often face difficulties in learning road sign systems of different countries; hence, the tasks are often time-consuming and produce poor results. We propose a novel approach using knowledge graphs and a machine learning algorithm - variational prototyping-encoder (VPE) - to assist human annotators in classifying road signs effectively. Annotators can query the Road Sign Knowledge Graph using visual attributes and receive closest matching candidates suggested by the VPE model. The VPE model uses the candidates from the knowledge graph and a real sign image patch as inputs. We show that our knowledge graph approach can reduce sign search space by 98.9%. Furthermore, with VPE, our system can propose the correct single candidate for 75% of signs in the tested datasets, eliminating the human search effort entirely in those cases.
* 12 pages, 5 figures
Learning to extrapolate using continued fractions: Predicting the critical temperature of superconductor materials
Nov 27, 2020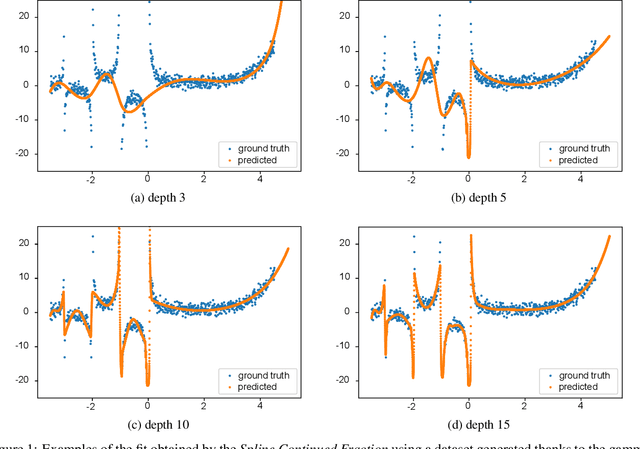
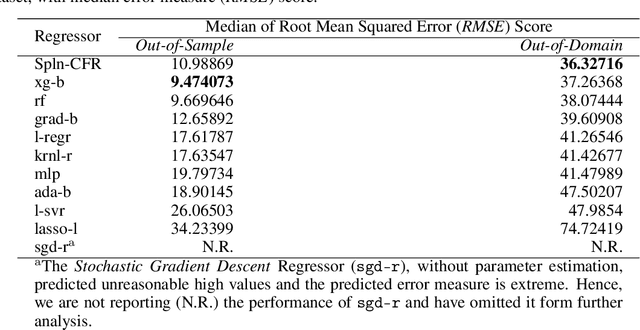
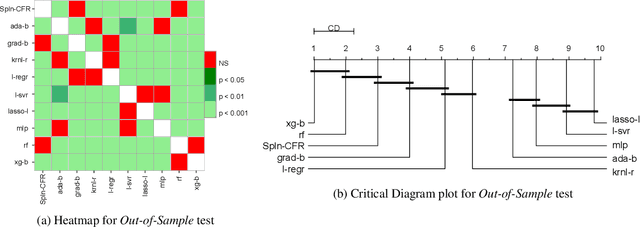
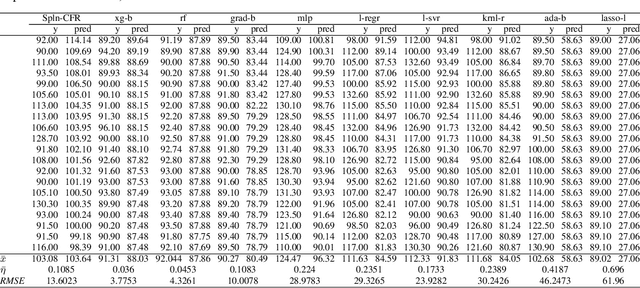
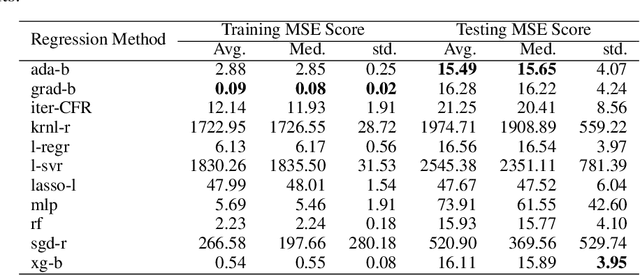
In Artificial Intelligence we often seek to identify an unknown target function of many variables $y=f(\mathbf{x})$ giving a limited set of instances $S=\{(\mathbf{x^{(i)}},y^{(i)})\}$ with $\mathbf{x^{(i)}} \in D$ where $D$ is a domain of interest. We refer to $S$ as the training set and the final quest is to identify the mathematical model that approximates this target function for new $\mathbf{x}$; with the set $T=\{ \mathbf{x^{(j)}} \} \subset D$ with $T \neq S$ (i.e. thus testing the model generalisation). However, for some applications, the main interest is approximating well the unknown function on a larger domain $D'$ that contains $D$. In cases involving the design of new structures, for instance, we may be interested in maximizing $f$; thus, the model derived from $S$ alone should also generalize well in $D'$ for samples with values of $y$ larger than the largest observed in $S$. In that sense, the AI system would provide important information that could guide the design process, e.g., using the learned model as a surrogate function to design new lab experiments. We introduce a method for multivariate regression based on iterative fitting of a continued fraction by incorporating additive spline models. We compared it with established methods such as AdaBoost, Kernel Ridge, Linear Regression, Lasso Lars, Linear Support Vector Regression, Multi-Layer Perceptrons, Random Forests, Stochastic Gradient Descent and XGBoost. We tested the performance on the important problem of predicting the critical temperature of superconductors based on physical-chemical characteristics.
Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling
Oct 23, 2020
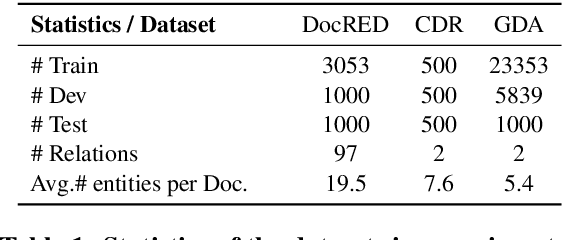
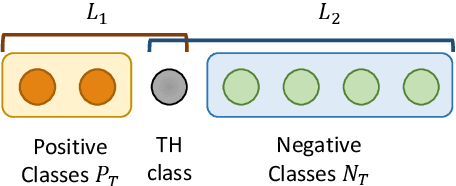
Document-level relation extraction (RE) poses new challenges compared to its sentence-level RE counterpart. One document commonly contains multiple entity pairs, and one entity pair occurs multiple times in the document associated with multiple possible relations. In this paper, we propose two novel techniques, adaptive thresholding and localized context pooling, to solve the multilabel and multi-entity problems. The adaptive thresholding replaces the global threshold for multi-label classification in the prior work by a learnable entities-dependent threshold. The localized context pooling directly transfers attention from pre-trained language models to locate relevant context that is useful to decide the relation. We experiment on three document-level RE benchmark datasets: DocRED, a recently released large-scale RE dataset, and two datasets CDR and GDA in the biomedical domain. Our ATLOP (Adaptive Thresholding and Localized cOntext Pooling) model achieves an F1 score of 63.4; and also significantly outperforms existing models on both CDR and GDA.
Entity and Evidence Guided Relation Extraction for DocRED
Aug 27, 2020

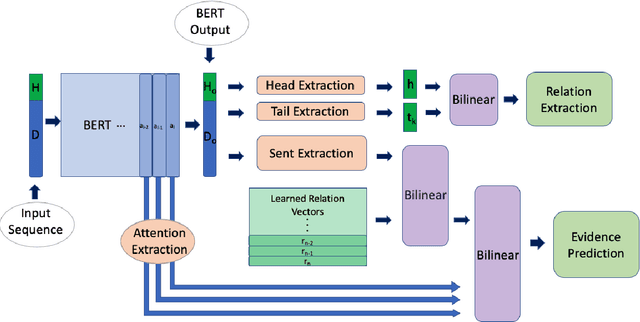
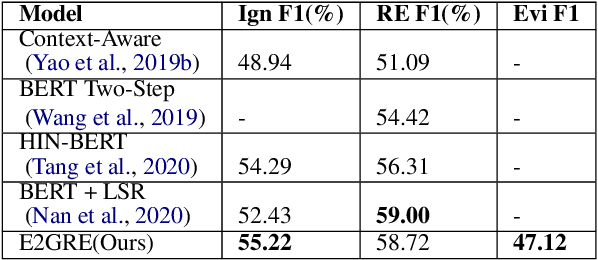
Document-level relation extraction is a challenging task which requires reasoning over multiple sentences in order to predict relations in a document. In this paper, we pro-pose a joint training frameworkE2GRE(Entity and Evidence Guided Relation Extraction)for this task. First, we introduce entity-guided sequences as inputs to a pre-trained language model (e.g. BERT, RoBERTa). These entity-guided sequences help a pre-trained language model (LM) to focus on areas of the document related to the entity. Secondly, we guide the fine-tuning of the pre-trained language model by using its internal attention probabilities as additional features for evidence prediction.Our new approach encourages the pre-trained language model to focus on the entities and supporting/evidence sentences. We evaluate our E2GRE approach on DocRED, a recently released large-scale dataset for relation extraction. Our approach is able to achieve state-of-the-art results on the public leaderboard across all metrics, showing that our E2GRE is both effective and synergistic on relation extraction and evidence prediction.
Select, Answer and Explain: Interpretable Multi-hop Reading Comprehension over Multiple Documents
Nov 22, 2019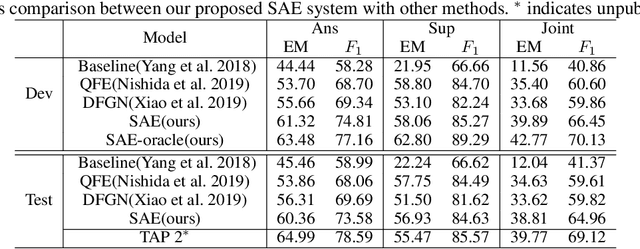
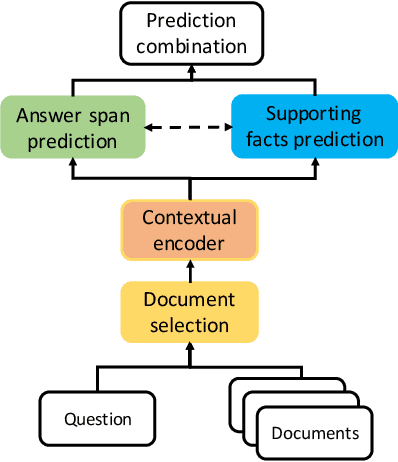
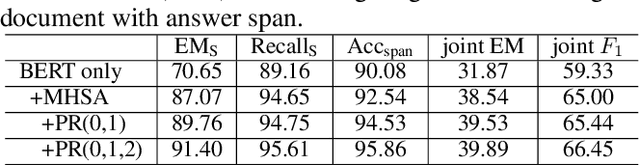
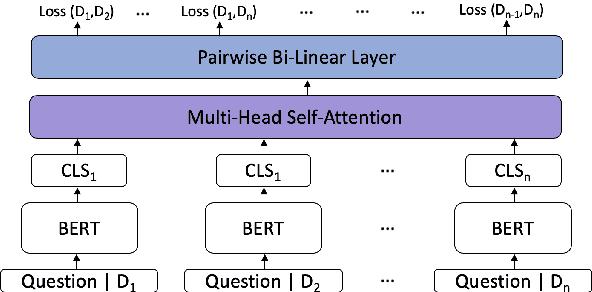
Interpretable multi-hop reading comprehension (RC) over multiple documents is a challenging problem because it demands reasoning over multiple information sources and explaining the answer prediction by providing supporting evidences. In this paper, we propose an effective and interpretable Select, Answer and Explain (SAE) system to solve the multi-document RC problem. Our system first filters out answer-unrelated documents and thus reduce the amount of distraction information. This is achieved by a document classifier trained with a novel pairwise learning-to-rank loss. The selected answer-related documents are then input to a model to jointly predict the answer and supporting sentences. The model is optimized with a multi-task learning objective on both token level for answer prediction and sentence level for supporting sentences prediction, together with an attention-based interaction between these two tasks. Evaluated on HotpotQA, a challenging multi-hop RC data set, the proposed SAE system achieves top competitive performance in distractor setting compared to other existing systems on the leaderboard.
Selective Attention Based Graph Convolutional Networks for Aspect-Level Sentiment Classification
Oct 24, 2019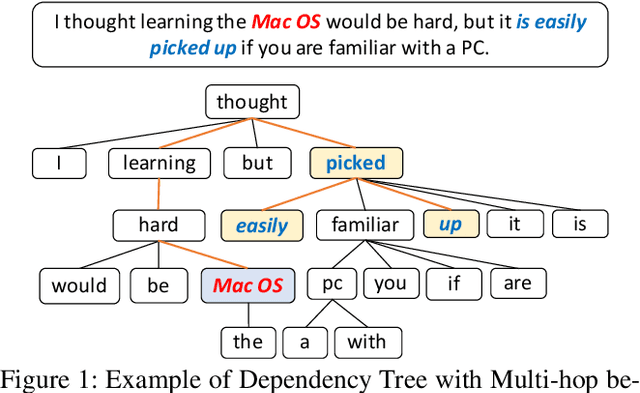
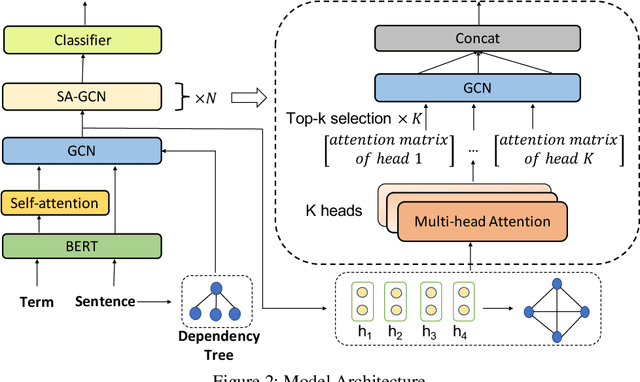
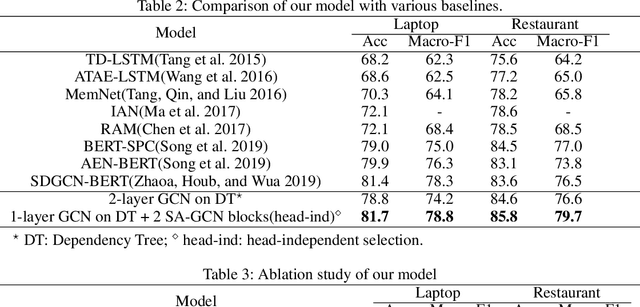
Aspect-level sentiment classification aims to identify the sentiment polarity towards a specific aspect term in a sentence. Most current approaches mainly consider the semantic information by utilizing attention mechanisms to capture the interactions between the context and the aspect term. In this paper, we propose to employ graph convolutional networks (GCNs) on the dependency tree to learn syntax-aware representations of aspect terms. GCNs often show the best performance with two layers, and deeper GCNs do not bring additional gain due to over-smoothing problem. However, in some cases, important context words cannot be reached within two hops on the dependency tree. Therefore we design a selective attention based GCN block (SA-GCN) to find the most important context words, and directly aggregate these information into the aspect-term representation. We conduct experiments on the SemEval 2014 Task 4 datasets. Our experimental results show that our model outperforms the current state-of-the-art.