 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Sequence Tagging Into A Seq2Seq Task
Mar 16, 2022

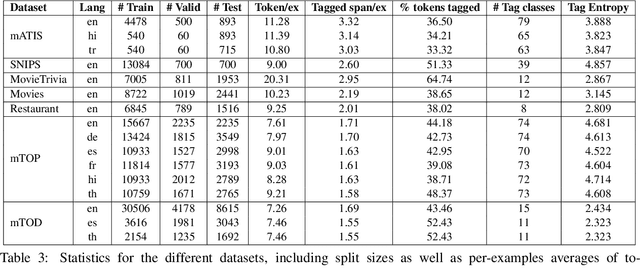
Pretrained, large, generative language models (LMs) have had great success in a wide range of sequence tagging and structured prediction tasks. Casting a sequence tagging task as a Seq2Seq one requires deciding the formats of the input and output sequences. However, we lack a principled understanding of the trade-offs associated with these formats (such as the effect on model accuracy, sequence length, multilingual generalization, hallucination). In this paper, we rigorously study different formats one could use for casting input text sentences and their output labels into the input and target (i.e., output) of a Seq2Seq model. Along the way, we introduce a new format, which we show to not only be simpler but also more effective. Additionally the new format demonstrates significant gains in the multilingual settings -- both zero-shot transfer learning and joint training. Lastly, we find that the new format is more robust and almost completely devoid of hallucination -- an issue we find common in existing formats. With well over a 1000 experiments studying 14 different formats, over 7 diverse public benchmarks -- including 3 multilingual datasets spanning 7 languages -- we believe our findings provide a strong empirical basis in understanding how we should tackle sequence tagging tasks.
Choose Your QA Model Wisely: A Systematic Study of Generative and Extractive Readers for Question Answering
Mar 14, 2022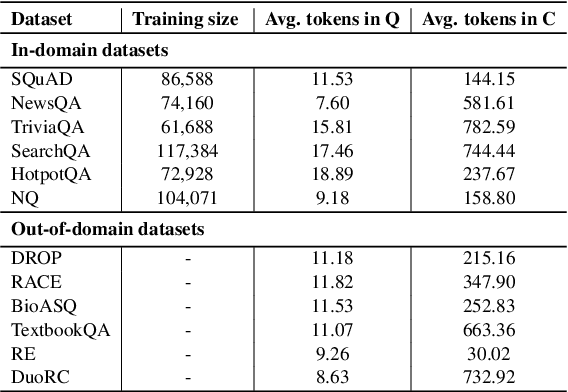
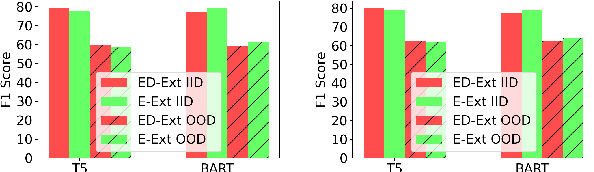

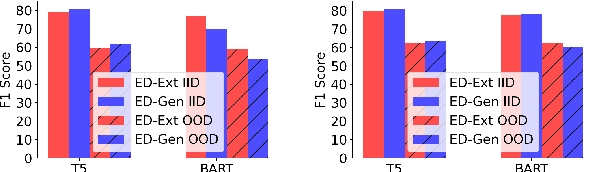
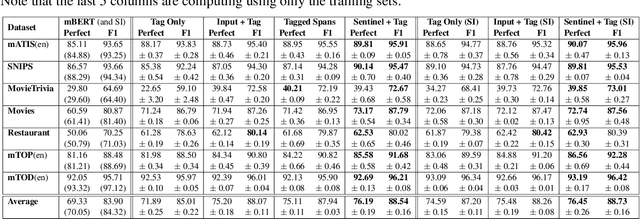
While both extractive and generative readers have been successfully applied to the Question Answering (QA) task, little attention has been paid toward the systematic comparison of them. Characterizing the strengths and weaknesses of the two readers is crucial not only for making a more informed reader selection in practice but also for developing a deeper understanding to foster further research on improving readers in a principled manner. Motivated by this goal, we make the first attempt to systematically study the comparison of extractive and generative readers for question answering. To be aligned with the state-of-the-art, we explore nine transformer-based large pre-trained language models (PrLMs) as backbone architectures. Furthermore, we organize our findings under two main categories: (1) keeping the architecture invariant, and (2) varying the underlying PrLMs. Among several interesting findings, it is important to highlight that (1) the generative readers perform better in long context QA, (2) the extractive readers perform better in short context while also showing better out-of-domain generalization, and (3) the encoder of encoder-decoder PrLMs (e.g., T5) turns out to be a strong extractive reader and outperforms the standard choice of encoder-only PrLMs (e.g., RoBERTa). We also study the effect of multi-task learning on the two types of readers varying the underlying PrLMs and perform qualitative and quantitative diagnosis to provide further insights into future directions in modeling better readers.
Dense Hierarchical Retrieval for Open-Domain Question Answering
Oct 28, 2021
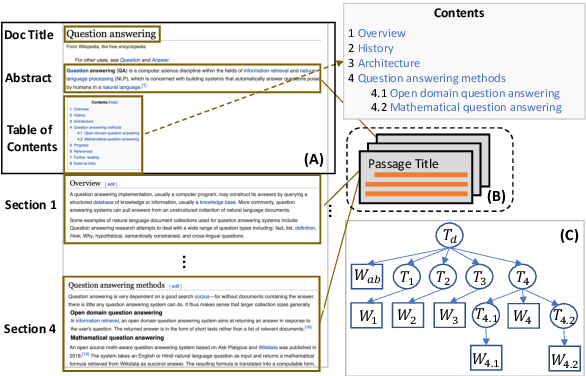
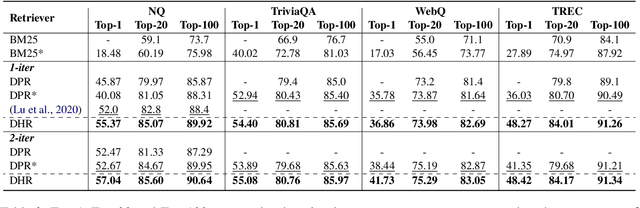
Dense neural text retrieval has achieved promising results on open-domain Question Answering (QA), where latent representations of questions and passages are exploited for maximum inner product search in the retrieval process. However, current dense retrievers require splitting documents into short passages that usually contain local, partial, and sometimes biased context, and highly depend on the splitting process. As a consequence, it may yield inaccurate and misleading hidden representations, thus deteriorating the final retrieval result. In this work, we propose Dense Hierarchical Retrieval (DHR), a hierarchical framework that can generate accurate dense representations of passages by utilizing both macroscopic semantics in the document and microscopic semantics specific to each passage. Specifically, a document-level retriever first identifies relevant documents, among which relevant passages are then retrieved by a passage-level retriever. The ranking of the retrieved passages will be further calibrated by examining the document-level relevance. In addition, hierarchical title structure and two negative sampling strategies (i.e., In-Doc and In-Sec negatives) are investigated. We apply DHR to large-scale open-domain QA datasets. DHR significantly outperforms the original dense passage retriever and helps an end-to-end QA system outperform the strong baselines on multiple open-domain QA benchmarks.
Field Extraction from Forms with Unlabeled Data
Oct 08, 2021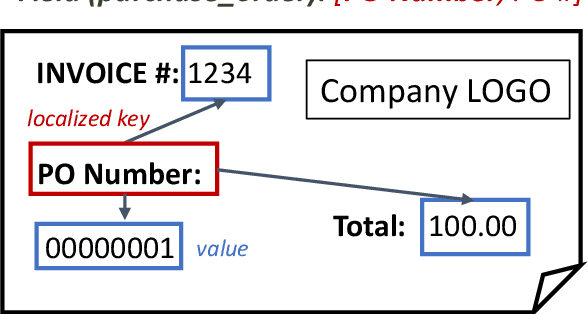
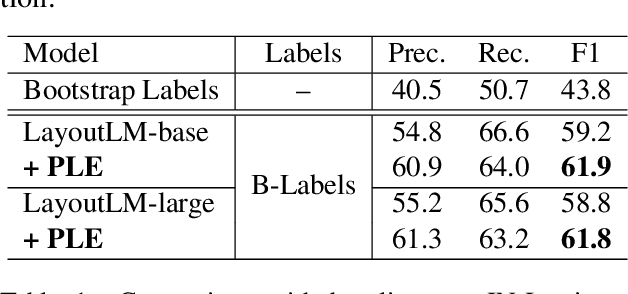
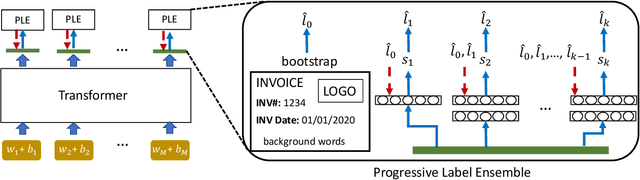
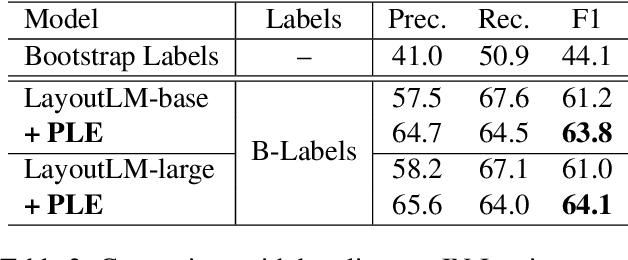
We propose a novel framework to conduct field extraction from forms with unlabeled data. To bootstrap the training process, we develop a rule-based method for mining noisy pseudo-labels from unlabeled forms. Using the supervisory signal from the pseudo-labels, we extract a discriminative token representation from a transformer-based model by modeling the interaction between text in the form. To prevent the model from overfitting to label noise, we introduce a refinement module based on a progressive pseudo-label ensemble. Experimental results demonstrate the effectiveness of our framework.
RnG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering
Sep 17, 2021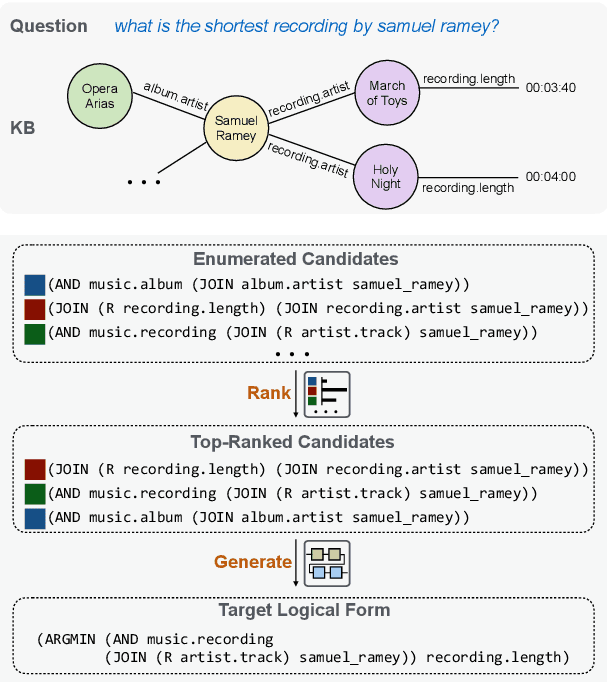
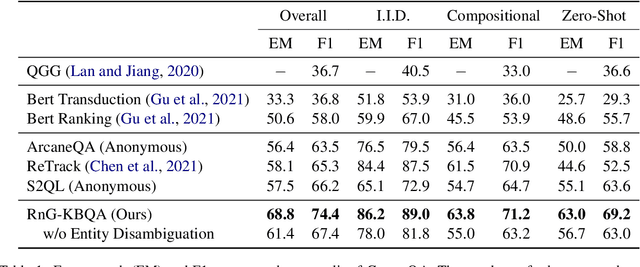
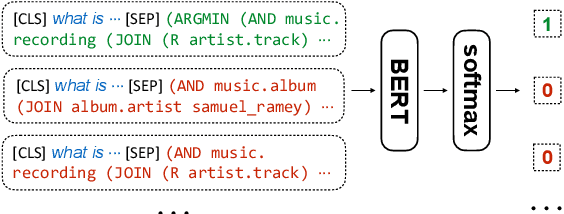
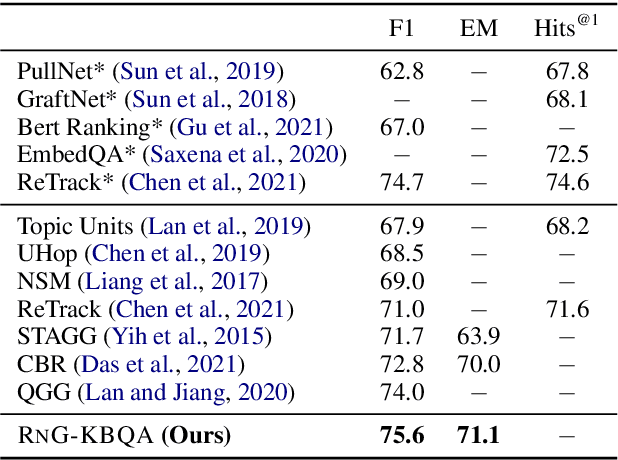
Existing KBQA approaches, despite achieving strong performance on i.i.d. test data, often struggle in generalizing to questions involving unseen KB schema items. Prior ranking-based approaches have shown some success in generalization, but suffer from the coverage issue. We present RnG-KBQA, a Rank-and-Generate approach for KBQA, which remedies the coverage issue with a generation model while preserving a strong generalization capability. Our approach first uses a contrastive ranker to rank a set of candidate logical forms obtained by searching over the knowledge graph. It then introduces a tailored generation model conditioned on the question and the top-ranked candidates to compose the final logical form. We achieve new state-of-the-art results on GrailQA and WebQSP datasets. In particular, our method surpasses the prior state-of-the-art by a large margin on the GrailQA leaderboard. In addition, RnG-KBQA outperforms all prior approaches on the popular WebQSP benchmark, even including the ones that use the oracle entity linking. The experimental results demonstrate the effectiveness of the interplay between ranking and generation, which leads to the superior performance of our proposed approach across all settings with especially strong improvements in zero-shot generalization.
Are Pretrained Transformers Robust in Intent Classification? A Missing Ingredient in Evaluation of Out-of-Scope Intent Detection
Jun 08, 2021
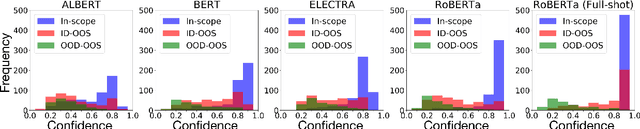
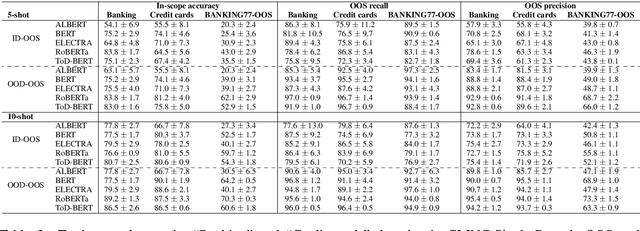
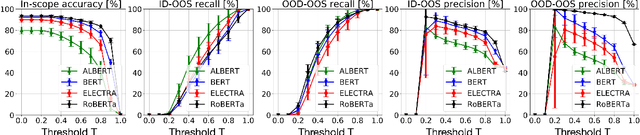
Pretrained Transformer-based models were reported to be robust in intent classification. In this work, we first point out the importance of in-domain out-of-scope detection in few-shot intent recognition tasks and then illustrate the vulnerability of pretrained Transformer-based models against samples that are in-domain but out-of-scope (ID-OOS). We empirically show that pretrained models do not perform well on both ID-OOS examples and general out-of-scope examples, especially on fine-grained few-shot intent detection tasks. To figure out how the models mistakenly classify ID-OOS intents as in-scope intents, we further conduct analysis on confidence scores and the overlapping keywords and provide several prospective directions for future work. We release the relevant resources to facilitate future research.
Focused Attention Improves Document-Grounded Generation
Apr 26, 2021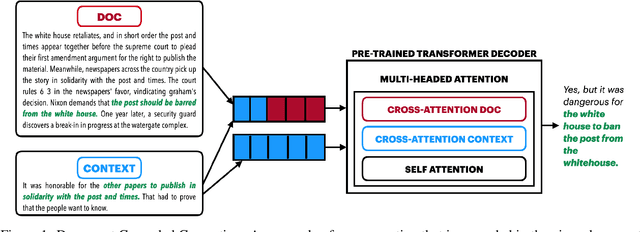
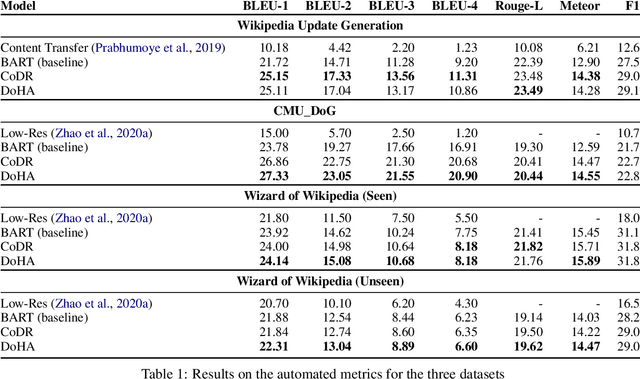
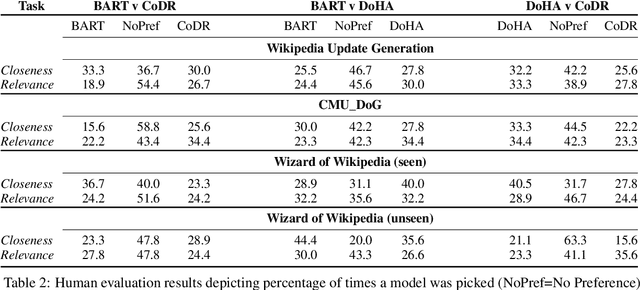
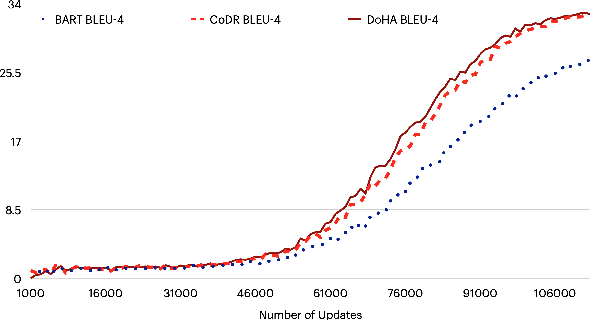
Document grounded generation is the task of using the information provided in a document to improve text generation. This work focuses on two different document grounded generation tasks: Wikipedia Update Generation task and Dialogue response generation. Our work introduces two novel adaptations of large scale pre-trained encoder-decoder models focusing on building context driven representation of the document and enabling specific attention to the information in the document. Additionally, we provide a stronger BART baseline for these tasks. Our proposed techniques outperform existing methods on both automated (at least 48% increase in BLEU-4 points) and human evaluation for closeness to reference and relevance to the document. Furthermore, we perform comprehensive manual inspection of the generated output and categorize errors to provide insights into future directions in modeling these tasks.
Causal-aware Safe Policy Improvement for Task-oriented dialogue
Mar 10, 2021
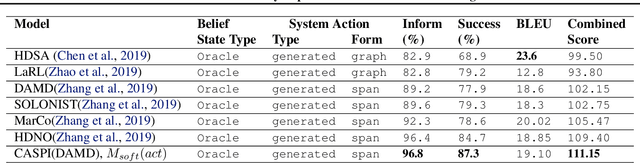
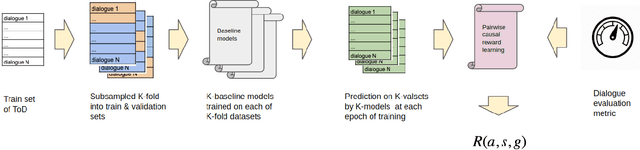
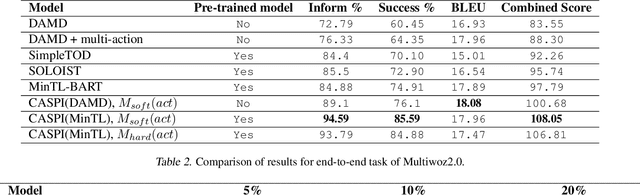
The recent success of reinforcement learning's (RL) in solving complex tasks is most often attributed to its capacity to explore and exploit an environment where it has been trained. Sample efficiency is usually not an issue since cheap simulators are available to sample data on-policy. On the other hand, task oriented dialogues are usually learnt from offline data collected using human demonstrations. Collecting diverse demonstrations and annotating them is expensive. Unfortunately, use of RL methods trained on off-policy data are prone to issues of bias and generalization, which are further exacerbated by stochasticity in human response and non-markovian belief state of a dialogue management system. To this end, we propose a batch RL framework for task oriented dialogue policy learning: causal aware safe policy improvement (CASPI). This method gives guarantees on dialogue policy's performance and also learns to shape rewards according to intentions behind human responses, rather than just mimicking demonstration data; this couple with batch-RL helps overall with sample efficiency of the framework. We demonstrate the effectiveness of this framework on a dialogue-context-to-text Generation and end-to-end dialogue task of the Multiwoz2.0 dataset. The proposed method outperforms the current state of the art on these metrics, in both case. In the end-to-end case, our method trained only on 10\% of the data was able to out perform current state in three out of four evaluation metrics.
Neural Text Generation with Artificial Negative Examples
Dec 28, 2020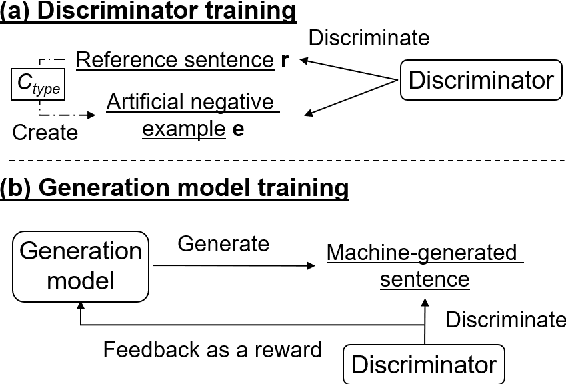

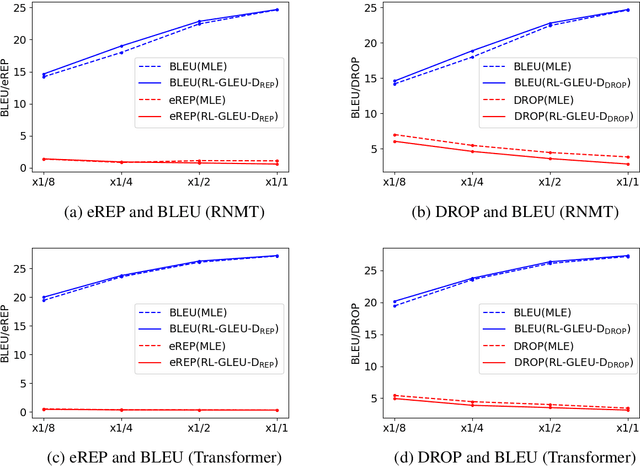
Neural text generation models conditioning on given input (e.g. machine translation and image captioning) are usually trained by maximum likelihood estimation of target text. However, the trained models suffer from various types of errors at inference time. In this paper, we propose to suppress an arbitrary type of errors by training the text generation model in a reinforcement learning framework, where we use a trainable reward function that is capable of discriminating between references and sentences containing the targeted type of errors. We create such negative examples by artificially injecting the targeted errors to the references. In experiments, we focus on two error types, repeated and dropped tokens in model-generated text. The experimental results show that our method can suppress the generation errors and achieve significant improvements on two machine translation and two image captioning tasks.
Discriminative Nearest Neighbor Few-Shot Intent Detection by Transferring Natural Language Inference
Oct 25, 2020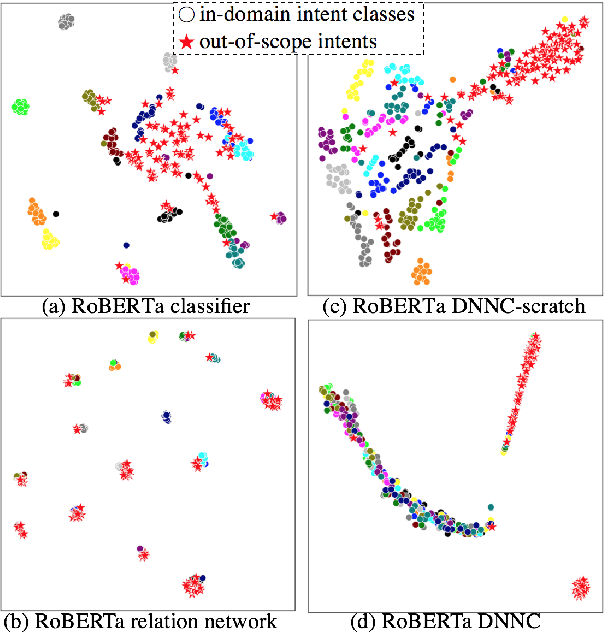

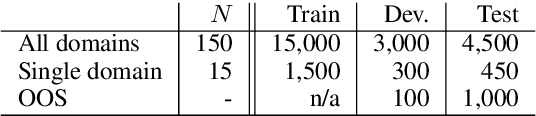
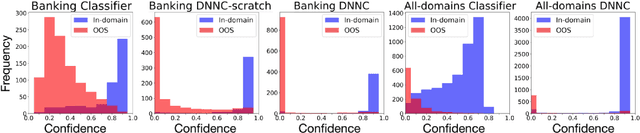
Intent detection is one of the core components of goal-oriented dialog systems, and detecting out-of-scope (OOS) intents is also a practically important skill. Few-shot learning is attracting much attention to mitigate data scarcity, but OOS detection becomes even more challenging. In this paper, we present a simple yet effective approach, discriminative nearest neighbor classification with deep self-attention. Unlike softmax classifiers, we leverage BERT-style pairwise encoding to train a binary classifier that estimates the best matched training example for a user input. We propose to boost the discriminative ability by transferring a natural language inference (NLI) model. Our extensive experiments on a large-scale multi-domain intent detection task show that our method achieves more stable and accurate in-domain and OOS detection accuracy than RoBERTa-based classifiers and embedding-based nearest neighbor approaches. More notably, the NLI transfer enables our 10-shot model to perform competitively with 50-shot or even full-shot classifiers, while we can keep the inference time constant by leveraging a faster embedding retrieval model.