 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecycling diverse models for out-of-distribution generalization
Dec 20, 2022



Foundation models are redefining how AI systems are built. Practitioners now follow a standard procedure to build their machine learning solutions: download a copy of a foundation model, and fine-tune it using some in-house data about the target task of interest. Consequently, the Internet is swarmed by a handful of foundation models fine-tuned on many diverse tasks. Yet, these individual fine-tunings often lack strong generalization and exist in isolation without benefiting from each other. In our opinion, this is a missed opportunity, as these specialized models contain diverse features. Based on this insight, we propose model recycling, a simple strategy that leverages multiple fine-tunings of the same foundation model on diverse auxiliary tasks, and repurposes them as rich and diverse initializations for the target task. Specifically, model recycling fine-tunes in parallel each specialized model on the target task, and then averages the weights of all target fine-tunings into a final model. Empirically, we show that model recycling maximizes model diversity by benefiting from diverse auxiliary tasks, and achieves a new state of the art on the reference DomainBed benchmark for out-of-distribution generalization. Looking forward, model recycling is a contribution to the emerging paradigm of updatable machine learning where, akin to open-source software development, the community collaborates to incrementally and reliably update machine learning models.
Empirical Study on Optimizer Selection for Out-of-Distribution Generalization
Nov 18, 2022



Modern deep learning systems are fragile and do not generalize well under distribution shifts. While much promising work has been accomplished to address these concerns, a systematic study of the role of optimizers and their out-of-distribution generalization performance has not been undertaken. In this study, we examine the performance of popular first-order optimizers for different classes of distributional shift under empirical risk minimization and invariant risk minimization. We address the problem settings for image and text classification using DomainBed, WILDS, and Backgrounds Challenge as out-of-distribution datasets for the exhaustive study. We search over a wide range of hyperparameters and examine the classification accuracy (in-distribution and out-of-distribution) for over 20,000 models. We arrive at the following findings: i) contrary to conventional wisdom, adaptive optimizers (e.g., Adam) perform worse than non-adaptive optimizers (e.g., SGD, momentum-based SGD), ii) in-distribution performance and out-of-distribution performance exhibit three types of behavior depending on the dataset - linear returns, increasing returns, and diminishing returns. We believe these findings can help practitioners choose the right optimizer and know what behavior to expect.
FL Games: A Federated Learning Framework for Distribution Shifts
Oct 31, 2022



Federated learning aims to train predictive models for data that is distributed across clients, under the orchestration of a server. However, participating clients typically each hold data from a different distribution, which can yield to catastrophic generalization on data from a different client, which represents a new domain. In this work, we argue that in order to generalize better across non-i.i.d. clients, it is imperative to only learn correlations that are stable and invariant across domains. We propose FL GAMES, a game-theoretic framework for federated learning that learns causal features that are invariant across clients. While training to achieve the Nash equilibrium, the traditional best response strategy suffers from high-frequency oscillations. We demonstrate that FL GAMES effectively resolves this challenge and exhibits smooth performance curves. Further, FL GAMES scales well in the number of clients, requires significantly fewer communication rounds, and is agnostic to device heterogeneity. Through empirical evaluation, we demonstrate that FL GAMES achieves high out-of-distribution performance on various benchmarks.
Interventional Causal Representation Learning
Oct 09, 2022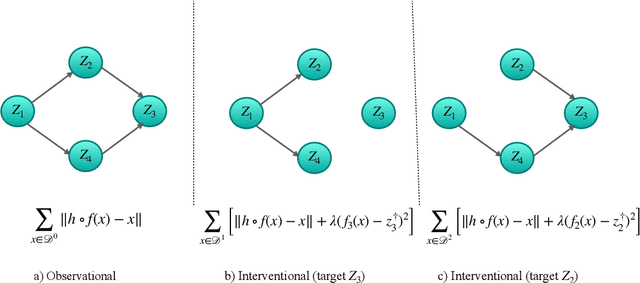
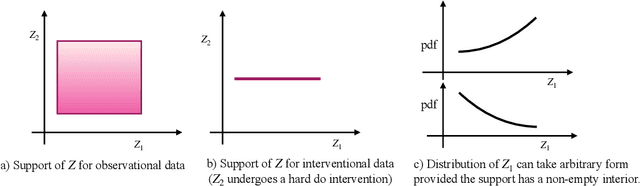
The theory of identifiable representation learning aims to build general-purpose methods that extract high-level latent (causal) factors from low-level sensory data. Most existing works focus on identifiable representation learning with observational data, relying on distributional assumptions on latent (causal) factors. However, in practice, we often also have access to interventional data for representation learning. How can we leverage interventional data to help identify high-level latents? To this end, we explore the role of interventional data for identifiable representation learning in this work. We study the identifiability of latent causal factors with and without interventional data, under minimal distributional assumptions on the latents. We prove that, if the true latent variables map to the observed high-dimensional data via a polynomial function, then representation learning via minimizing the standard reconstruction loss of autoencoders identifies the true latents up to affine transformation. If we further have access to interventional data generated by hard $do$ interventions on some of the latents, then we can identify these intervened latents up to permutation, shift and scaling.
Weakly Supervised Representation Learning with Sparse Perturbations
Jun 02, 2022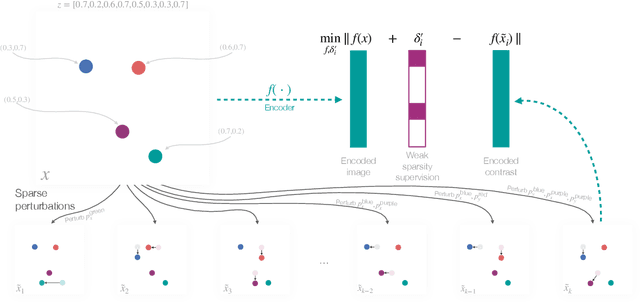
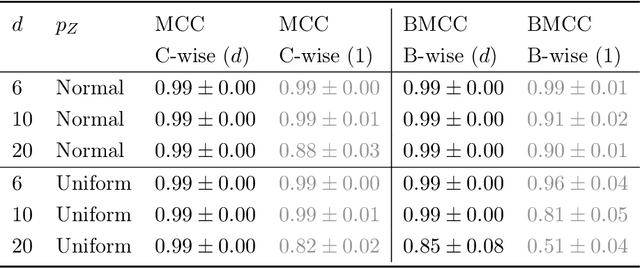
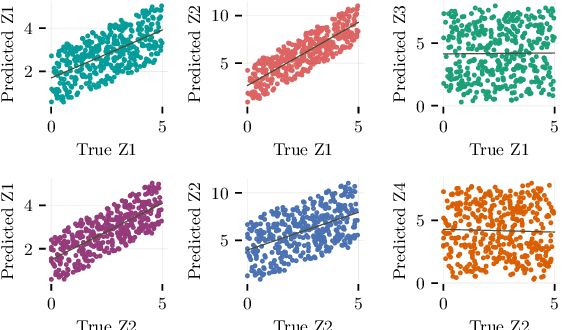
The theory of representation learning aims to build methods that provably invert the data generating process with minimal domain knowledge or any source of supervision. Most prior approaches require strong distributional assumptions on the latent variables and weak supervision (auxiliary information such as timestamps) to provide provable identification guarantees. In this work, we show that if one has weak supervision from observations generated by sparse perturbations of the latent variables--e.g. images in a reinforcement learning environment where actions move individual sprites--identification is achievable under unknown continuous latent distributions. We show that if the perturbations are applied only on mutually exclusive blocks of latents, we identify the latents up to those blocks. We also show that if these perturbation blocks overlap, we identify latents up to the smallest blocks shared across perturbations. Consequently, if there are blocks that intersect in one latent variable only, then such latents are identified up to permutation and scaling. We propose a natural estimation procedure based on this theory and illustrate it on low-dimensional synthetic and image-based experiments.
Towards efficient representation identification in supervised learning
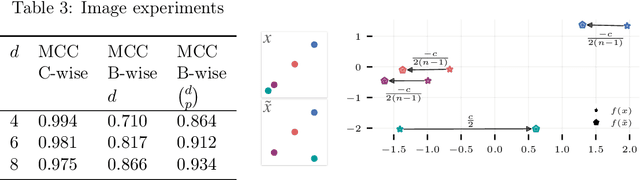
Apr 10, 2022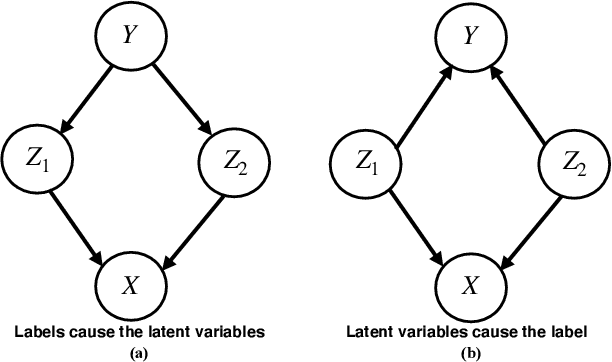
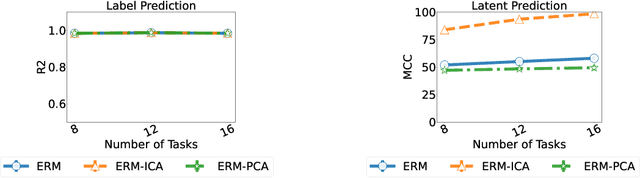
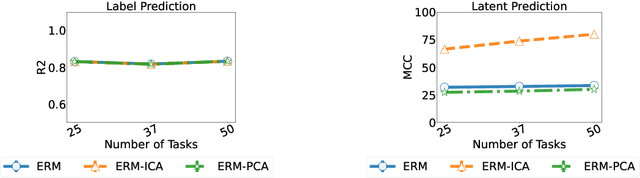
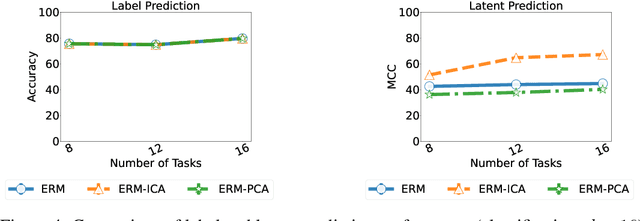
Humans have a remarkable ability to disentangle complex sensory inputs (e.g., image, text) into simple factors of variation (e.g., shape, color) without much supervision. This ability has inspired many works that attempt to solve the following question: how do we invert the data generation process to extract those factors with minimal or no supervision? Several works in the literature on non-linear independent component analysis have established this negative result; without some knowledge of the data generation process or appropriate inductive biases, it is impossible to perform this inversion. In recent years, a lot of progress has been made on disentanglement under structural assumptions, e.g., when we have access to auxiliary information that makes the factors of variation conditionally independent. However, existing work requires a lot of auxiliary information, e.g., in supervised classification, it prescribes that the number of label classes should be at least equal to the total dimension of all factors of variation. In this work, we depart from these assumptions and ask: a) How can we get disentanglement when the auxiliary information does not provide conditional independence over the factors of variation? b) Can we reduce the amount of auxiliary information required for disentanglement? For a class of models where auxiliary information does not ensure conditional independence, we show theoretically and experimentally that disentanglement (to a large extent) is possible even when the auxiliary information dimension is much less than the dimension of the true latent representation.
WOODS: Benchmarks for Out-of-Distribution Generalization in Time Series Tasks
Mar 18, 2022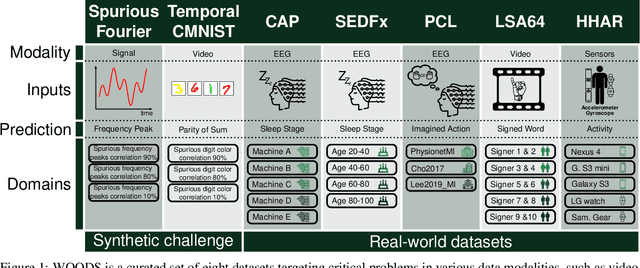
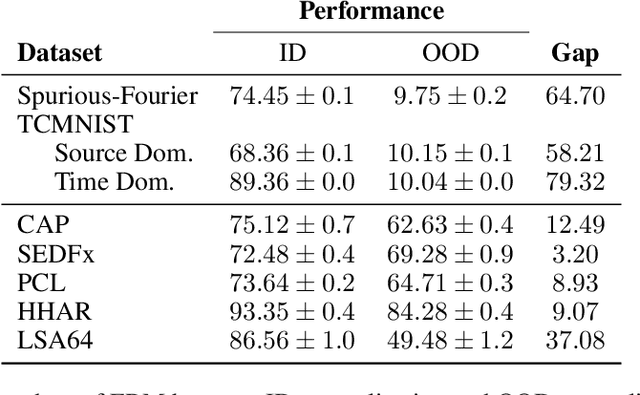
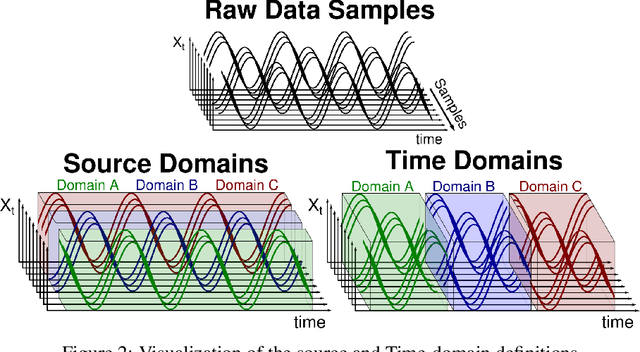

Machine learning models often fail to generalize well under distributional shifts. Understanding and overcoming these failures have led to a research field of Out-of-Distribution (OOD) generalization. Despite being extensively studied for static computer vision tasks, OOD generalization has been underexplored for time series tasks. To shine light on this gap, we present WOODS: eight challenging open-source time series benchmarks covering a diverse range of data modalities, such as videos, brain recordings, and sensor signals. We revise the existing OOD generalization algorithms for time series tasks and evaluate them using our systematic framework. Our experiments show a large room for improvement for empirical risk minimization and OOD generalization algorithms on our datasets, thus underscoring the new challenges posed by time series tasks. Code and documentation are available at https://woods-benchmarks.github.io .
Locally Invariant Explanations: Towards Stable and Unidirectional Explanations through Local Invariant Learning
Jan 28, 2022Locally interpretable model agnostic explanations (LIME) method is one of the most popular methods used to explain black-box models at a per example level. Although many variants have been proposed, few provide a simple way to produce high fidelity explanations that are also stable and intuitive. In this work, we provide a novel perspective by proposing a model agnostic local explanation method inspired by the invariant risk minimization (IRM) principle -- originally proposed for (global) out-of-distribution generalization -- to provide such high fidelity explanations that are also stable and unidirectional across nearby examples. Our method is based on a game theoretic formulation where we theoretically show that our approach has a strong tendency to eliminate features where the gradient of the black-box function abruptly changes sign in the locality of the example we want to explain, while in other cases it is more careful and will choose a more conservative (feature) attribution, a behavior which can be highly desirable for recourse. Empirically, we show on tabular, image and text data that the quality of our explanations with neighborhoods formed using random perturbations are much better than LIME and in some cases even comparable to other methods that use realistic neighbors sampled from the data manifold. This is desirable given that learning a manifold to either create realistic neighbors or to project explanations is typically expensive or may even be impossible. Moreover, our algorithm is simple and efficient to train, and can ascertain stable input features for local decisions of a black-box without access to side information such as a (partial) causal graph as has been seen in some recent works.
Properties from Mechanisms: An Equivariance Perspective on Identifiable Representation Learning
Oct 29, 2021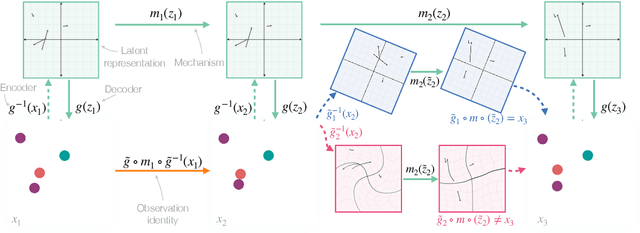

A key goal of unsupervised representation learning is "inverting" a data generating process to recover its latent properties. Existing work that provably achieves this goal relies on strong assumptions on relationships between the latent variables (e.g., independence conditional on auxiliary information). In this paper, we take a very different perspective on the problem and ask, "Can we instead identify latent properties by leveraging knowledge of the mechanisms that govern their evolution?" We provide a complete characterization of the sources of non-identifiability as we vary knowledge about a set of possible mechanisms. In particular, we prove that if we know the exact mechanisms under which the latent properties evolve, then identification can be achieved up to any equivariances that are shared by the underlying mechanisms. We generalize this characterization to settings where we only know some hypothesis class over possible mechanisms, as well as settings where the mechanisms are stochastic. We demonstrate the power of this mechanism-based perspective by showing that we can leverage our results to generalize existing identifiable representation learning results. These results suggest that by exploiting inductive biases on mechanisms, it is possible to design a range of new identifiable representation learning approaches.
Finding Valid Adjustments under Non-ignorability with Minimal DAG Knowledge
Jun 22, 2021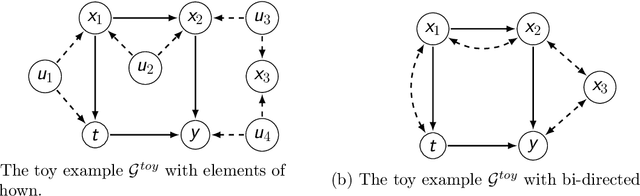
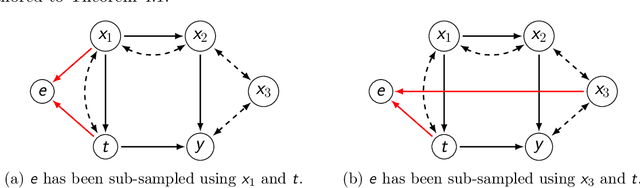
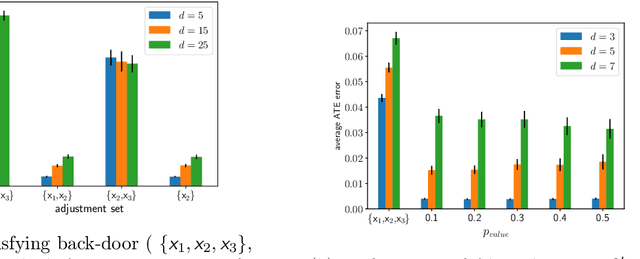
Treatment effect estimation from observational data is a fundamental problem in causal inference. There are two very different schools of thought that have tackled this problem. On the one hand, the Pearlian framework commonly assumes structural knowledge (provided by an expert) in the form of Directed Acyclic Graphs (DAGs) and provides graphical criteria such as the back-door criterion to identify the valid adjustment sets. On the other hand, the potential outcomes (PO) framework commonly assumes that all the observed features satisfy ignorability (i.e., no hidden confounding), which in general is untestable. In this work, we take steps to bridge these two frameworks. We show that even if we know only one parent of the treatment variable (provided by an expert), then quite remarkably it suffices to test a broad class of (but not all) back-door criteria. Importantly, we also cover the non-trivial case where the entire set of observed features is not ignorable (generalizing the PO framework) without requiring all the parents of the treatment variable to be observed. Our key technical idea involves a more general result -- Given a synthetic sub-sampling (or environment) variable that is a function of the parent variable, we show that an invariance test involving this sub-sampling variable is equivalent to testing a broad class of back-door criteria. We demonstrate our approach on synthetic data as well as real causal effect estimation benchmarks.