 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroscopic Vehicle Trajectory Datasets from UAV-collected Video for Heterogeneous, Area-Based Urban Traffic
Dec 10, 2025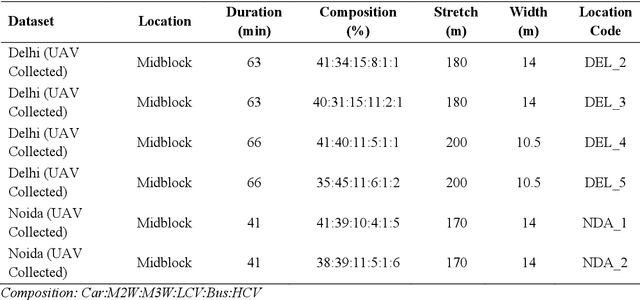
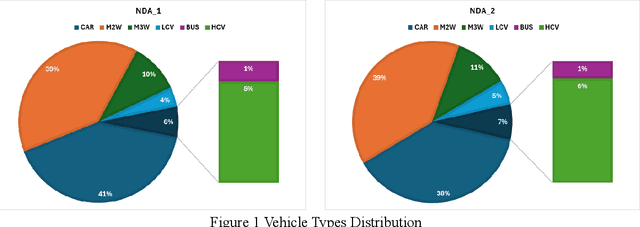
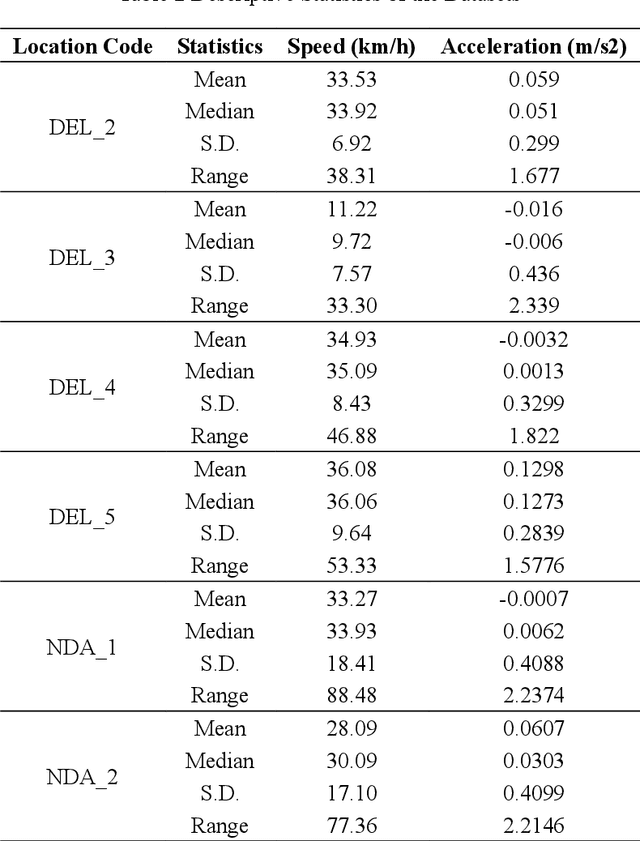
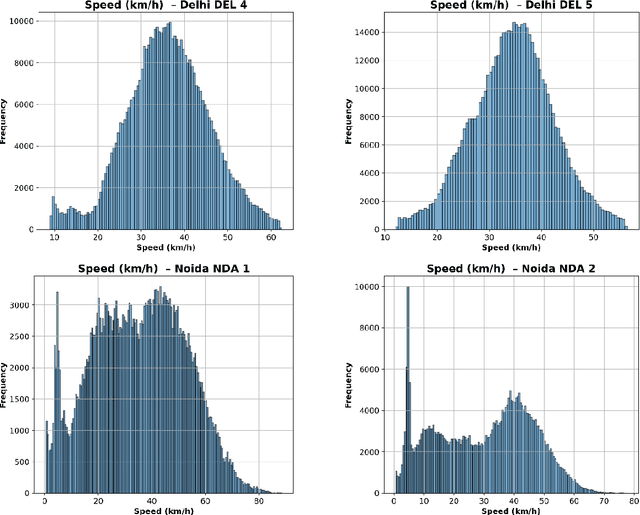
This paper offers openly available microscopic vehicle trajectory (MVT) datasets collected using unmanned aerial vehicles (UAVs) in heterogeneous, area-based urban traffic conditions. Traditional roadside video collection often fails in dense mixed traffic due to occlusion, limited viewing angles, and irregular vehicle movements. UAV-based recording provides a top-down perspective that reduces these issues and captures rich spatial and temporal dynamics. The datasets described here were extracted using the Data from Sky (DFS) platform and validated against manual counts, space mean speeds, and probe trajectories in earlier work. Each dataset contains time-stamped vehicle positions, speeds, longitudinal and lateral accelerations, and vehicle classifications at a resolution of 30 frames per second. Data were collected at six mid-block locations in the national capital region of India, covering diverse traffic compositions and density levels. Exploratory analyses highlight key behavioural patterns, including lane-keeping preferences, speed distributions, and lateral manoeuvres typical of heterogeneous and area-based traffic settings. These datasets are intended as a resource for the global research community to support simulation modelling, safety assessment, and behavioural studies under area-based traffic conditions. By making these empirical datasets openly available, this work offers researchers a unique opportunity to develop, test, and validate models that more accurately represent complex urban traffic environments.
QuanTaxo: A Quantum Approach to Self-Supervised Taxonomy Expansion
Jan 23, 2025



A taxonomy is a hierarchical graph containing knowledge to provide valuable insights for various web applications. Online retail organizations like Microsoft and Amazon utilize taxonomies to improve product recommendations and optimize advertisement by enhancing query interpretation. However, the manual construction of taxonomies requires significant human effort. As web content continues to expand at an unprecedented pace, existing taxonomies risk becoming outdated, struggling to incorporate new and emerging information effectively. As a consequence, there is a growing need for dynamic taxonomy expansion to keep them relevant and up-to-date. Existing taxonomy expansion methods often rely on classical word embeddings to represent entities. However, these embeddings fall short in capturing hierarchical polysemy, where an entity's meaning can vary based on its position in the hierarchy and its surrounding context. To address this challenge, we introduce QuanTaxo, an innovative quantum-inspired framework for taxonomy expansion. QuanTaxo encodes entity representations in quantum space, effectively modeling hierarchical polysemy by leveraging the principles of Hilbert space to capture interference effects between entities, yielding richer and more nuanced representations. Comprehensive experiments on four real-world benchmark datasets show that QuanTaxo significantly outperforms classical embedding models, achieving substantial improvements of 18.45% in accuracy, 20.5% in Mean Reciprocal Rank, and 17.87% in Wu & Palmer metrics across eight classical embedding-based baselines. We further highlight the superiority of QuanTaxo through extensive ablation and case studies.
Can LLMs replace Neil deGrasse Tyson? Evaluating the Reliability of LLMs as Science Communicators
Sep 21, 2024Large Language Models (LLMs) and AI assistants driven by these models are experiencing exponential growth in usage among both expert and amateur users. In this work, we focus on evaluating the reliability of current LLMs as science communicators. Unlike existing benchmarks, our approach emphasizes assessing these models on scientific questionanswering tasks that require a nuanced understanding and awareness of answerability. We introduce a novel dataset, SCiPS-QA, comprising 742 Yes/No queries embedded in complex scientific concepts, along with a benchmarking suite that evaluates LLMs for correctness and consistency across various criteria. We benchmark three proprietary LLMs from the OpenAI GPT family and 13 open-access LLMs from the Meta Llama-2, Llama-3, and Mistral families. While most open-access models significantly underperform compared to GPT-4 Turbo, our experiments identify Llama-3-70B as a strong competitor, often surpassing GPT-4 Turbo in various evaluation aspects. We also find that even the GPT models exhibit a general incompetence in reliably verifying LLM responses. Moreover, we observe an alarming trend where human evaluators are deceived by incorrect responses from GPT-4 Turbo.
Scrutinizing Data from Sky: An Examination of Its Veracity in Area Based Traffic Contexts
Apr 26, 2024



Traffic data collection has been an overwhelming task for researchers as well as authorities over the years. With the advancement in technology and introduction of various tools for processing and extracting traffic data the task has been made significantly convenient. Data from Sky (DFS) is one such tool, based on image processing and artificial intelligence (AI), that provides output for macroscopic as well as microscopic variables of the traffic streams. The company claims to provide 98 to 100 percent accuracy on the data exported using DFS tool. The tool is widely used in developed countries where the traffic is homogenous and has lane-based movements. In this study, authors have checked the veracity of DFS tool in heterogenous and area-based traffic movement that is prevailing in most developing countries. The validation is done using various methods using Classified Volume Count (CVC), Space Mean Speeds (SMS) of individual vehicle classes and microscopic trajectory of probe vehicle to verify DFS claim. The error for CVCs for each vehicle class present in the traffic stream is estimated. Mean Absolute Percentage Error (MAPE) values are calculated for average speeds of each vehicle class between manually and DFS extracted space mean speeds (SMSs), and the microscopic trajectories are validated using a GPS based tracker put on probe vehicles. The results are fairly accurate in the case of data taken from a bird eye view with least errors. The other configurations of data collection have some significant errors, that are majorly caused by the varied traffic composition, the view of camera angle, and the direction of traffic.
FL Games: A Federated Learning Framework for Distribution Shifts
Oct 31, 2022



Federated learning aims to train predictive models for data that is distributed across clients, under the orchestration of a server. However, participating clients typically each hold data from a different distribution, which can yield to catastrophic generalization on data from a different client, which represents a new domain. In this work, we argue that in order to generalize better across non-i.i.d. clients, it is imperative to only learn correlations that are stable and invariant across domains. We propose FL GAMES, a game-theoretic framework for federated learning that learns causal features that are invariant across clients. While training to achieve the Nash equilibrium, the traditional best response strategy suffers from high-frequency oscillations. We demonstrate that FL GAMES effectively resolves this challenge and exhibits smooth performance curves. Further, FL GAMES scales well in the number of clients, requires significantly fewer communication rounds, and is agnostic to device heterogeneity. Through empirical evaluation, we demonstrate that FL GAMES achieves high out-of-distribution performance on various benchmarks.
Multi-label classification for biomedical literature: an overview of the BioCreative VII LitCovid Track for COVID-19 literature topic annotations
Apr 20, 2022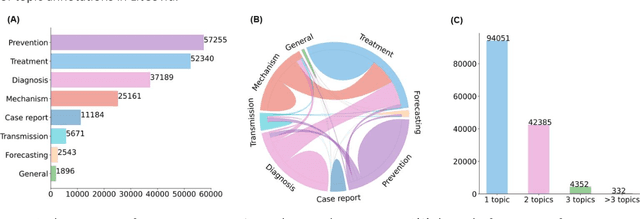
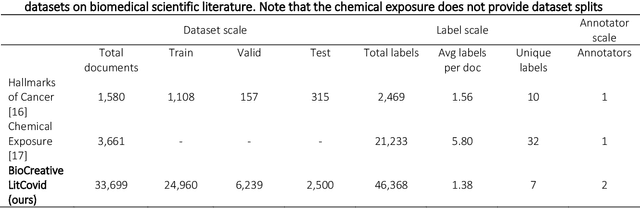
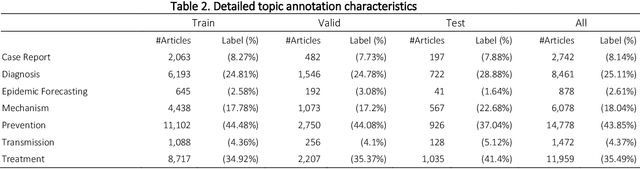
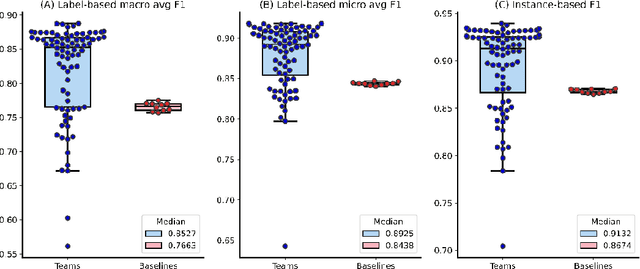
The COVID-19 pandemic has been severely impacting global society since December 2019. Massive research has been undertaken to understand the characteristics of the virus and design vaccines and drugs. The related findings have been reported in biomedical literature at a rate of about 10,000 articles on COVID-19 per month. Such rapid growth significantly challenges manual curation and interpretation. For instance, LitCovid is a literature database of COVID-19-related articles in PubMed, which has accumulated more than 200,000 articles with millions of accesses each month by users worldwide. One primary curation task is to assign up to eight topics (e.g., Diagnosis and Treatment) to the articles in LitCovid. Despite the continuing advances in biomedical text mining methods, few have been dedicated to topic annotations in COVID-19 literature. To close the gap, we organized the BioCreative LitCovid track to call for a community effort to tackle automated topic annotation for COVID-19 literature. The BioCreative LitCovid dataset, consisting of over 30,000 articles with manually reviewed topics, was created for training and testing. It is one of the largest multilabel classification datasets in biomedical scientific literature. 19 teams worldwide participated and made 80 submissions in total. Most teams used hybrid systems based on transformers. The highest performing submissions achieved 0.8875, 0.9181, and 0.9394 for macro F1-score, micro F1-score, and instance-based F1-score, respectively. The level of participation and results demonstrate a successful track and help close the gap between dataset curation and method development. The dataset is publicly available via https://ftp.ncbi.nlm.nih.gov/pub/lu/LitCovid/biocreative/ for benchmarking and further development.
Interpretation of Black Box NLP Models: A Survey
Mar 31, 2022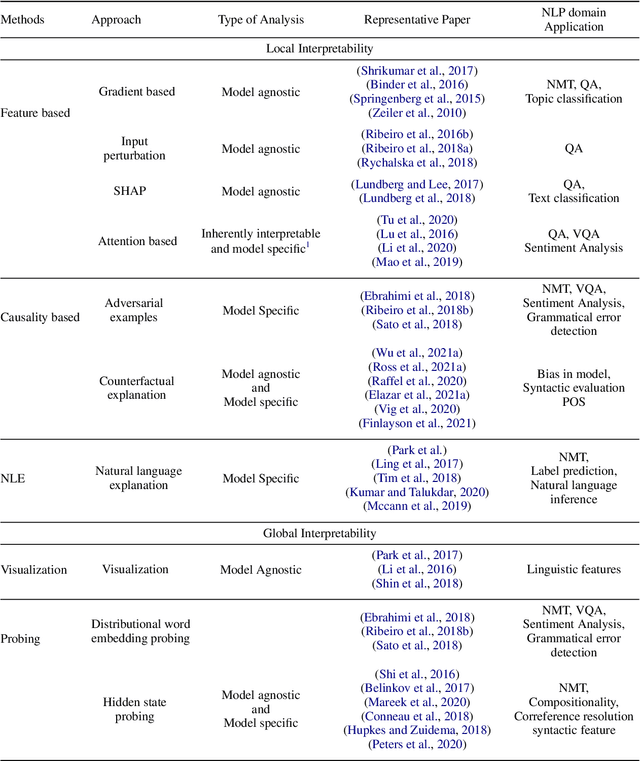
An increasing number of machine learning models have been deployed in domains with high stakes such as finance and healthcare. Despite their superior performances, many models are black boxes in nature which are hard to explain. There are growing efforts for researchers to develop methods to interpret these black-box models. Post hoc explanations based on perturbations, such as LIME, are widely used approaches to interpret a machine learning model after it has been built. This class of methods has been shown to exhibit large instability, posing serious challenges to the effectiveness of the method itself and harming user trust. In this paper, we propose S-LIME, which utilizes a hypothesis testing framework based on central limit theorem for determining the number of perturbation points needed to guarantee stability of the resulting explanation. Experiments on both simulated and real world data sets are provided to demonstrate the effectiveness of our method.
Temporal Random Indexing of Context Vectors Applied to Event Detection
Sep 30, 2020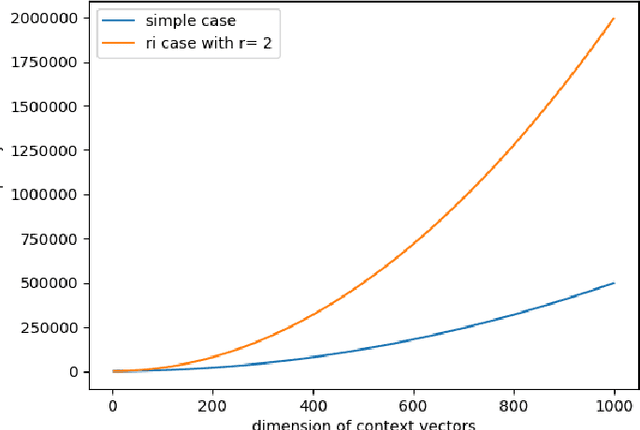

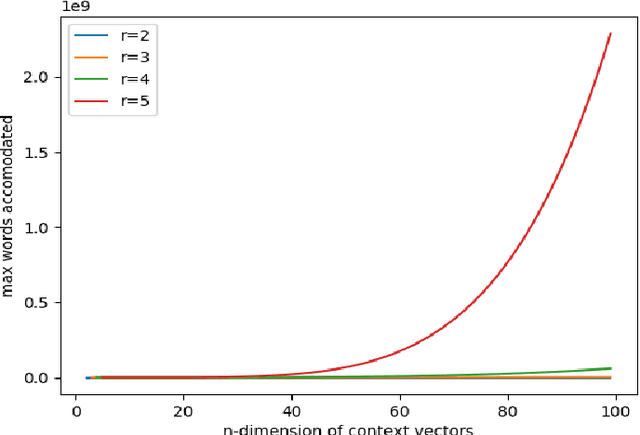

In this paper we explore new representations for encoding language data. The general method of one-hot encoding grows linearly with the size of the word corpus in space-complexity. We address this by using Random Indexing(RI) of context vectors with non-zero entries. We propose a novel RI representation where we exploit the effect imposing a probability distribution on the number of randomized entries which leads to a class of RI representations. We also propose an algorithm that is log linear in the size of word corpus to track the semantic relationship of the query word to other words for suggesting the events that are relevant to the word in question. Finally we run simulations on the novel RI representations using the proposed algorithms for tweets relevant to the word "iPhone" and present results. The RI representation is shown to be faster and space efficient as compared to BoW embeddings.
An improved Bayesian TRIE based model for SMS text normalization
Aug 04, 2020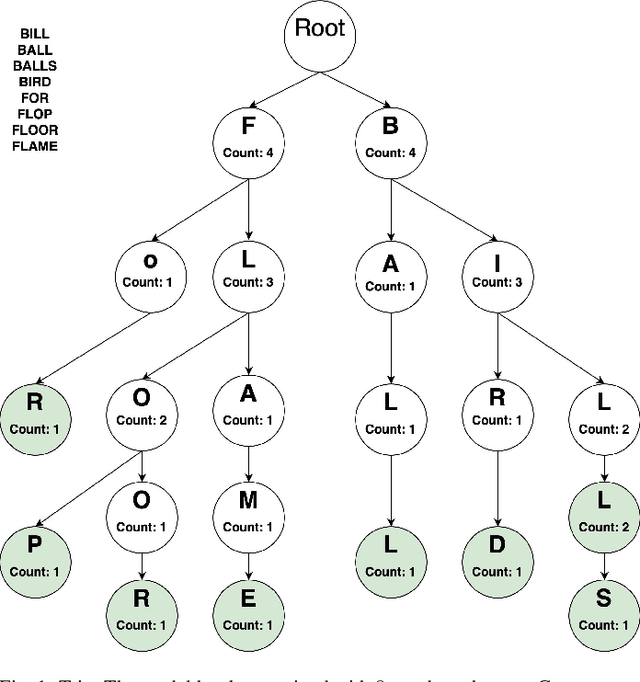
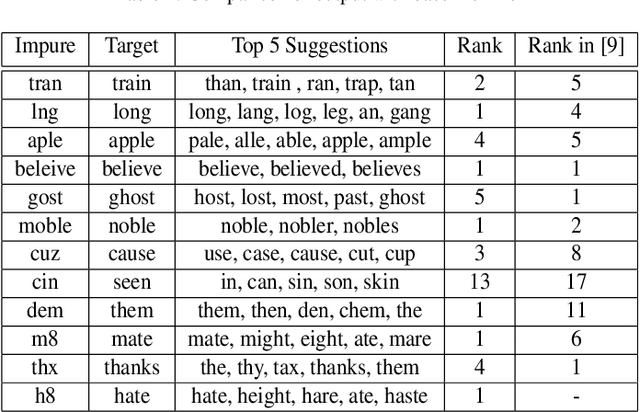
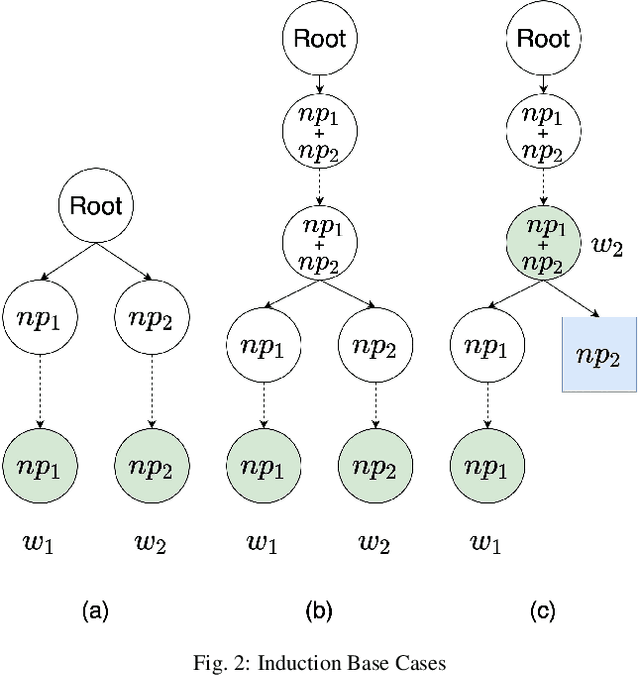
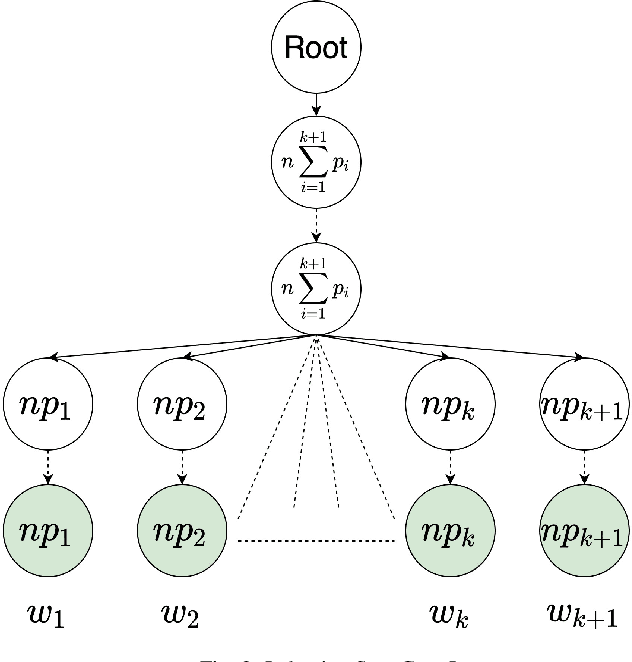
Normalization of SMS text, commonly known as texting language, is being pursued for more than a decade. A probabilistic approach based on the Trie data structure was proposed in literature which was found to be better performing than HMM based approaches proposed earlier in predicting the correct alternative for an out-of-lexicon word. However, success of the Trie based approach depends largely on how correctly the underlying probabilities of word occurrences are estimated. In this work we propose a structural modification to the existing Trie-based model along with a novel training algorithm and probability generation scheme. We prove two theorems on statistical properties of the proposed Trie and use them to claim that is an unbiased and consistent estimator of the occurrence probabilities of the words. We further fuse our model into the paradigm of noisy channel based error correction and provide a heuristic to go beyond a Damerau Levenshtein distance of one. We also run simulations to support our claims and show superiority of the proposed scheme over previous works.
Rough Set based Aggregate Rank Measure & its Application to Supervised Multi Document Summarization
Feb 09, 2020

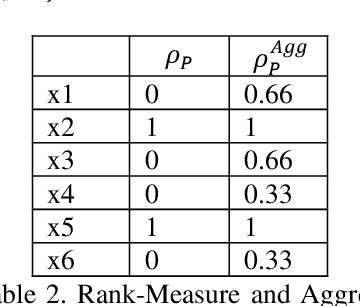
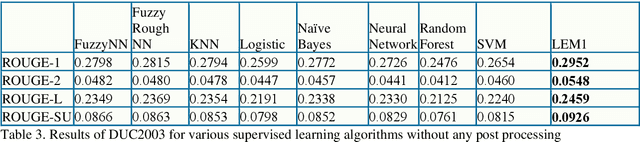
Most problems in Machine Learning cater to classification and the objects of universe are classified to a relevant class. Ranking of classified objects of universe per decision class is a challenging problem. We in this paper propose a novel Rough Set based membership called Rank Measure to solve to this problem. It shall be utilized for ranking the elements to a particular class. It differs from Pawlak Rough Set based membership function which gives an equivalent characterization of the Rough Set based approximations. It becomes paramount to look beyond the traditional approach of computing memberships while handling inconsistent, erroneous and missing data that is typically present in real world problems. This led us to propose the aggregate Rank Measure. The contribution of the paper is three fold. Firstly, it proposes a Rough Set based measure to be utilized for numerical characterization of within class ranking of objects. Secondly, it proposes and establish the properties of Rank Measure and aggregate Rank Measure based membership. Thirdly, we apply the concept of membership and aggregate ranking to the problem of supervised Multi Document Summarization wherein first the important class of sentences are determined using various supervised learning techniques and are post processed using the proposed ranking measure. The results proved to have significant improvement in accuracy.