 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFourier Representations for Black-Box Optimization over Categorical Variables
Feb 08, 2022
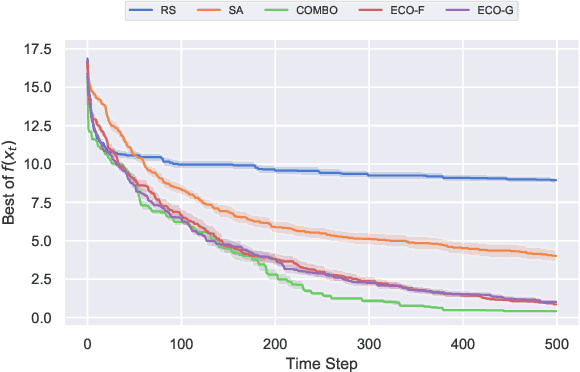
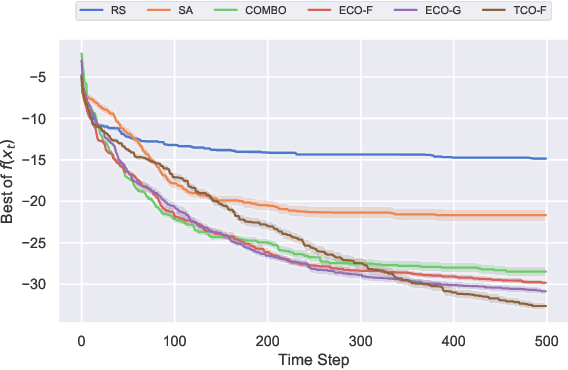
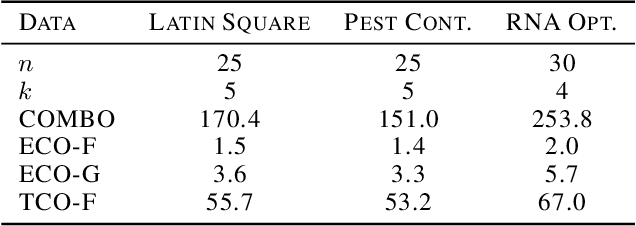
Optimization of real-world black-box functions defined over purely categorical variables is an active area of research. In particular, optimization and design of biological sequences with specific functional or structural properties have a profound impact in medicine, materials science, and biotechnology. Standalone search algorithms, such as simulated annealing (SA) and Monte Carlo tree search (MCTS), are typically used for such optimization problems. In order to improve the performance and sample efficiency of such algorithms, we propose to use existing methods in conjunction with a surrogate model for the black-box evaluations over purely categorical variables. To this end, we present two different representations, a group-theoretic Fourier expansion and an abridged one-hot encoded Boolean Fourier expansion. To learn such representations, we consider two different settings to update our surrogate model. First, we utilize an adversarial online regression setting where Fourier characters of each representation are considered as experts and their respective coefficients are updated via an exponential weight update rule each time the black box is evaluated. Second, we consider a Bayesian setting where queries are selected via Thompson sampling and the posterior is updated via a sparse Bayesian regression model (over our proposed representation) with a regularized horseshoe prior. Numerical experiments over synthetic benchmarks as well as real-world RNA sequence optimization and design problems demonstrate the representational power of the proposed methods, which achieve competitive or superior performance compared to state-of-the-art counterparts, while improving the computation cost and/or sample efficiency, substantially.
Auto-Transfer: Learning to Route Transferrable Representations
Feb 04, 2022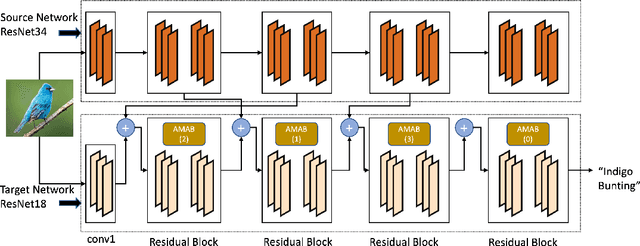
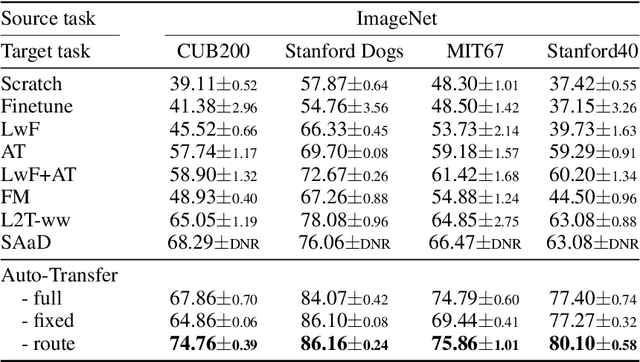
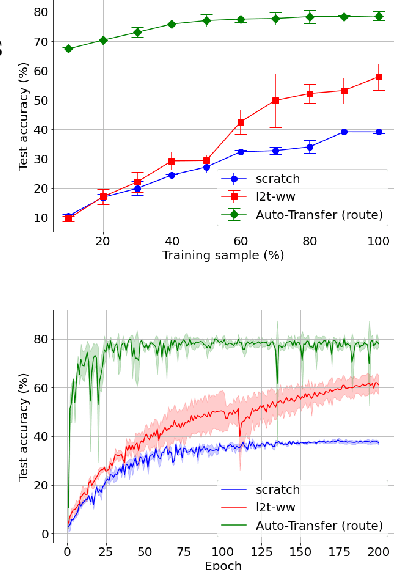

Knowledge transfer between heterogeneous source and target networks and tasks has received a lot of attention in recent times as large amounts of quality labelled data can be difficult to obtain in many applications. Existing approaches typically constrain the target deep neural network (DNN) feature representations to be close to the source DNNs feature representations, which can be limiting. We, in this paper, propose a novel adversarial multi-armed bandit approach which automatically learns to route source representations to appropriate target representations following which they are combined in meaningful ways to produce accurate target models. We see upwards of 5% accuracy improvements compared with the state-of-the-art knowledge transfer methods on four benchmark (target) image datasets CUB200, Stanford Dogs, MIT67, and Stanford40 where the source dataset is ImageNet. We qualitatively analyze the goodness of our transfer scheme by showing individual examples of the important features our target network focuses on in different layers compared with the (closest) competitors. We also observe that our improvement over other methods is higher for smaller target datasets making it an effective tool for small data applications that may benefit from transfer learning.
Scalable Intervention Target Estimation in Linear Models
Nov 15, 2021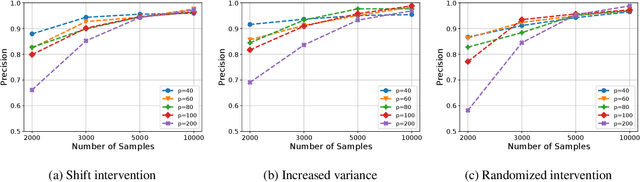
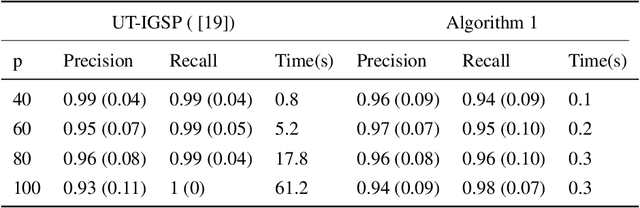
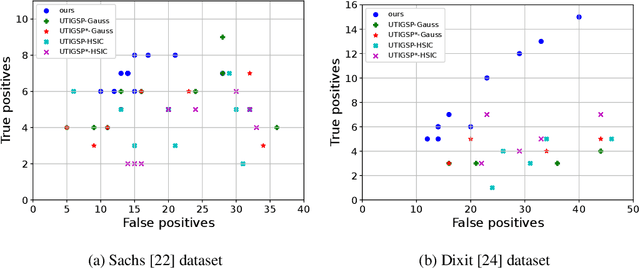
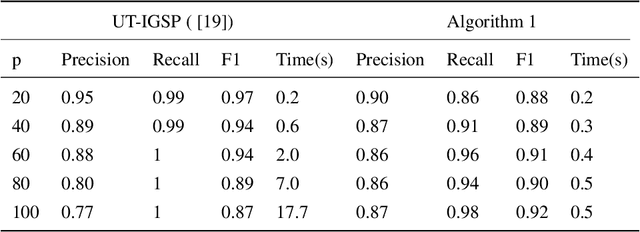
This paper considers the problem of estimating the unknown intervention targets in a causal directed acyclic graph from observational and interventional data. The focus is on soft interventions in linear structural equation models (SEMs). Current approaches to causal structure learning either work with known intervention targets or use hypothesis testing to discover the unknown intervention targets even for linear SEMs. This severely limits their scalability and sample complexity. This paper proposes a scalable and efficient algorithm that consistently identifies all intervention targets. The pivotal idea is to estimate the intervention sites from the difference between the precision matrices associated with the observational and interventional datasets. It involves repeatedly estimating such sites in different subsets of variables. The proposed algorithm can be used to also update a given observational Markov equivalence class into the interventional Markov equivalence class. Consistency, Markov equivalency, and sample complexity are established analytically. Finally, simulation results on both real and synthetic data demonstrate the gains of the proposed approach for scalable causal structure recovery. Implementation of the algorithm and the code to reproduce the simulation results are available at \url{https://github.com/bvarici/intervention-estimation}.
AI Explainability 360: Impact and Design
Sep 24, 2021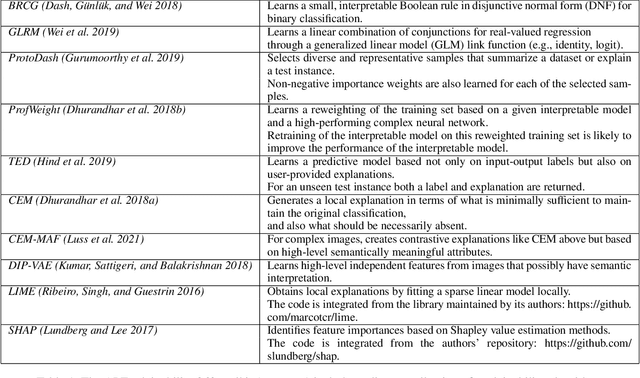
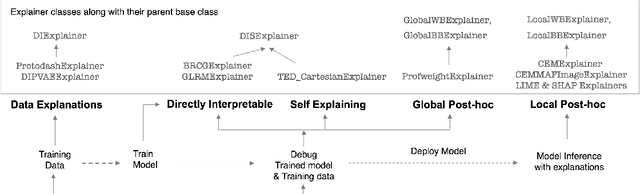

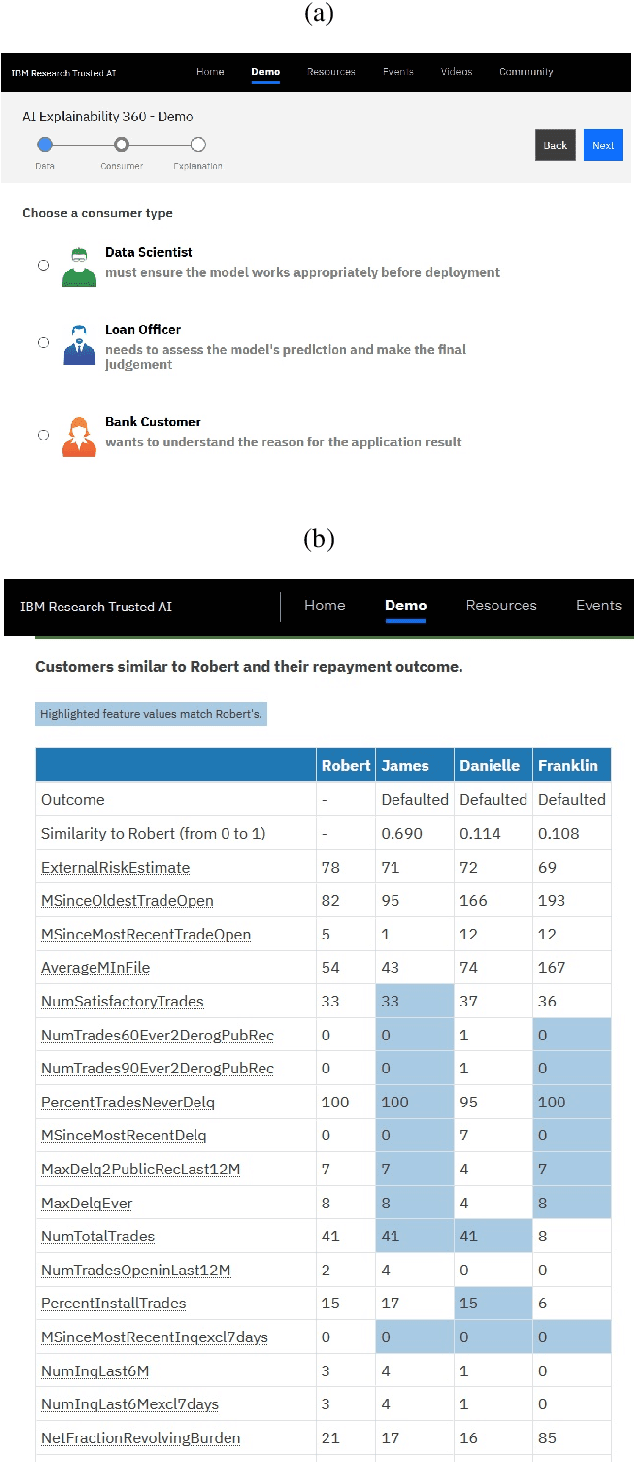
As artificial intelligence and machine learning algorithms become increasingly prevalent in society, multiple stakeholders are calling for these algorithms to provide explanations. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, have different explanation needs. To address these needs, in 2019, we created AI Explainability 360 (Arya et al. 2020), an open source software toolkit featuring ten diverse and state-of-the-art explainability methods and two evaluation metrics. This paper examines the impact of the toolkit with several case studies, statistics, and community feedback. The different ways in which users have experienced AI Explainability 360 have resulted in multiple types of impact and improvements in multiple metrics, highlighted by the adoption of the toolkit by the independent LF AI & Data Foundation. The paper also describes the flexible design of the toolkit, examples of its use, and the significant educational material and documentation available to its users.
Episodic Bandits with Stochastic Experts
Jul 07, 2021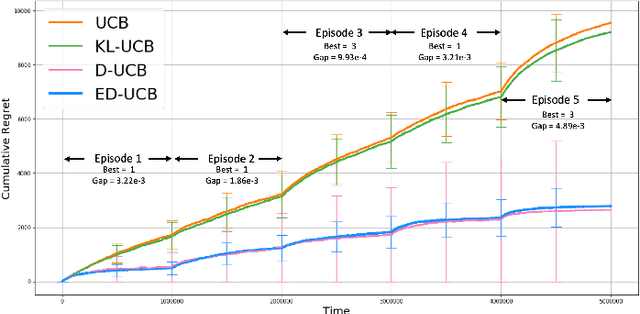
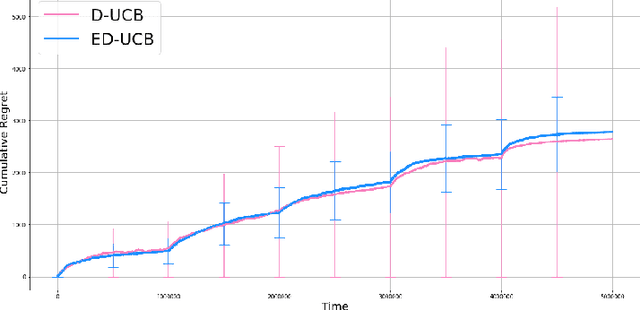
We study a version of the contextual bandit problem where an agent is given soft control of a node in a graph-structured environment through a set of stochastic expert policies. The agent interacts with the environment over episodes, with each episode having different context distributions; this results in the `best expert' changing across episodes. Our goal is to develop an agent that tracks the best expert over episodes. We introduce the Empirical Divergence-based UCB (ED-UCB) algorithm in this setting where the agent does not have any knowledge of the expert policies or changes in context distributions. With mild assumptions, we show that bootstrapping from $\tilde{O}(N\log(NT^2\sqrt{E}))$ samples results in a regret of $\tilde{O}(E(N+1) + \frac{N\sqrt{E}}{T^2})$. If the expert policies are known to the agent a priori, then we can improve the regret to $\tilde{O}(EN)$ without requiring any bootstrapping. Our analysis also tightens pre-existing logarithmic regret bounds to a problem-dependent constant in the non-episodic setting when expert policies are known. We finally empirically validate our findings through simulations.
Finite-Sample Analysis of Off-Policy TD-Learning via Generalized Bellman Operators
Jun 24, 2021In temporal difference (TD) learning, off-policy sampling is known to be more practical than on-policy sampling, and by decoupling learning from data collection, it enables data reuse. It is known that policy evaluation (including multi-step off-policy importance sampling) has the interpretation of solving a generalized Bellman equation. In this paper, we derive finite-sample bounds for any general off-policy TD-like stochastic approximation algorithm that solves for the fixed-point of this generalized Bellman operator. Our key step is to show that the generalized Bellman operator is simultaneously a contraction mapping with respect to a weighted $\ell_p$-norm for each $p$ in $[1,\infty)$, with a common contraction factor. Off-policy TD-learning is known to suffer from high variance due to the product of importance sampling ratios. A number of algorithms (e.g. $Q^\pi(\lambda)$, Tree-Backup$(\lambda)$, Retrace$(\lambda)$, and $Q$-trace) have been proposed in the literature to address this issue. Our results immediately imply finite-sample bounds of these algorithms. In particular, we provide first-known finite-sample guarantees for $Q^\pi(\lambda)$, Tree-Backup$(\lambda)$, and Retrace$(\lambda)$, and improve the best known bounds of $Q$-trace in [19]. Moreover, we show the bias-variance trade-offs in each of these algorithms.
Finding Valid Adjustments under Non-ignorability with Minimal DAG Knowledge
Jun 22, 2021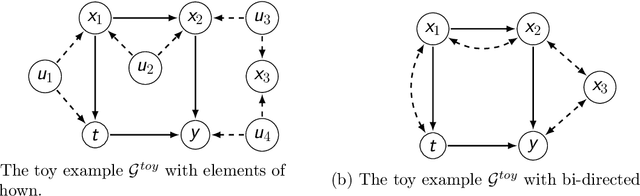
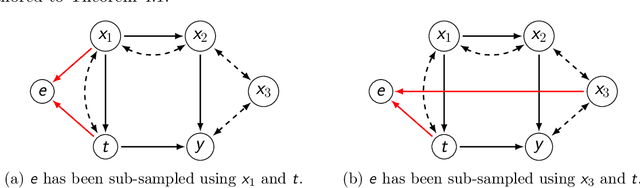
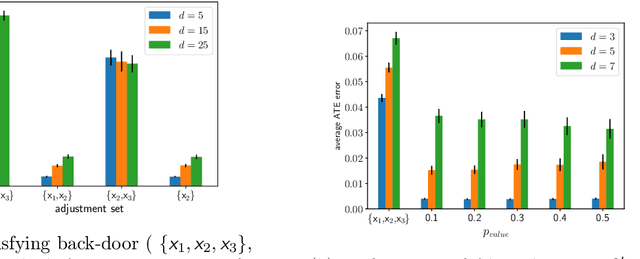
Treatment effect estimation from observational data is a fundamental problem in causal inference. There are two very different schools of thought that have tackled this problem. On the one hand, the Pearlian framework commonly assumes structural knowledge (provided by an expert) in the form of Directed Acyclic Graphs (DAGs) and provides graphical criteria such as the back-door criterion to identify the valid adjustment sets. On the other hand, the potential outcomes (PO) framework commonly assumes that all the observed features satisfy ignorability (i.e., no hidden confounding), which in general is untestable. In this work, we take steps to bridge these two frameworks. We show that even if we know only one parent of the treatment variable (provided by an expert), then quite remarkably it suffices to test a broad class of (but not all) back-door criteria. Importantly, we also cover the non-trivial case where the entire set of observed features is not ignorable (generalizing the PO framework) without requiring all the parents of the treatment variable to be observed. Our key technical idea involves a more general result -- Given a synthetic sub-sampling (or environment) variable that is a function of the parent variable, we show that an invariance test involving this sub-sampling variable is equivalent to testing a broad class of back-door criteria. We demonstrate our approach on synthetic data as well as real causal effect estimation benchmarks.
Treatment Effect Estimation using Invariant Risk Minimization
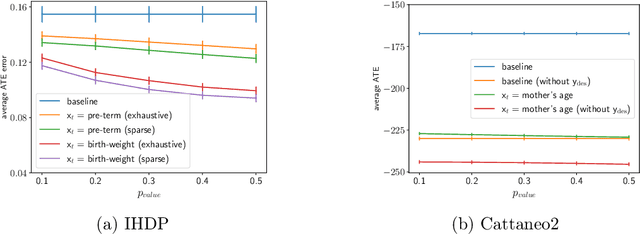
Mar 13, 2021
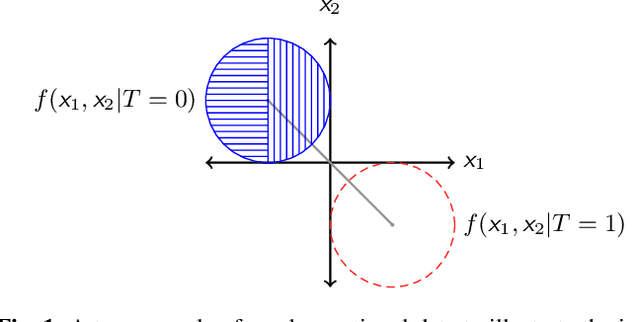
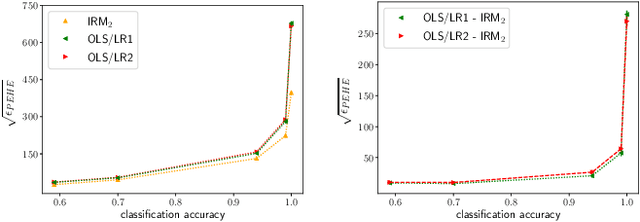
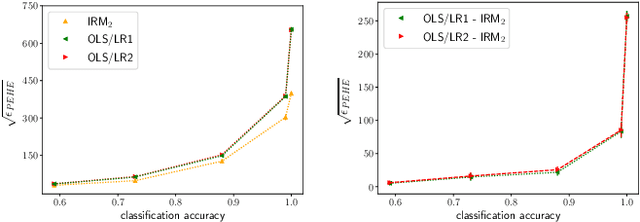
Inferring causal individual treatment effect (ITE) from observational data is a challenging problem whose difficulty is exacerbated by the presence of treatment assignment bias. In this work, we propose a new way to estimate the ITE using the domain generalization framework of invariant risk minimization (IRM). IRM uses data from multiple domains, learns predictors that do not exploit spurious domain-dependent factors, and generalizes better to unseen domains. We propose an IRM-based ITE estimator aimed at tackling treatment assignment bias when there is little support overlap between the control group and the treatment group. We accomplish this by creating diversity: given a single dataset, we split the data into multiple domains artificially. These diverse domains are then exploited by IRM to more effectively generalize regression-based models to data regions that lack support overlap. We show gains over classical regression approaches to ITE estimation in settings when support mismatch is more pronounced.
Efficient Encrypted Inference on Ensembles of Decision Trees
Mar 05, 2021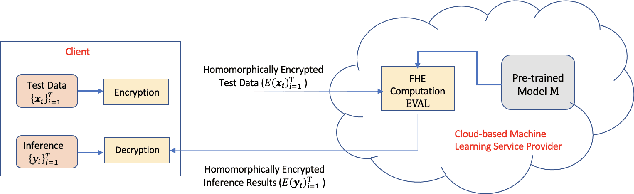

Data privacy concerns often prevent the use of cloud-based machine learning services for sensitive personal data. While homomorphic encryption (HE) offers a potential solution by enabling computations on encrypted data, the challenge is to obtain accurate machine learning models that work within the multiplicative depth constraints of a leveled HE scheme. Existing approaches for encrypted inference either make ad-hoc simplifications to a pre-trained model (e.g., replace hard comparisons in a decision tree with soft comparators) at the cost of accuracy or directly train a new depth-constrained model using the original training set. In this work, we propose a framework to transfer knowledge extracted by complex decision tree ensembles to shallow neural networks (referred to as DTNets) that are highly conducive to encrypted inference. Our approach minimizes the accuracy loss by searching for the best DTNet architecture that operates within the given depth constraints and training this DTNet using only synthetic data sampled from the training data distribution. Extensive experiments on real-world datasets demonstrate that these characteristics are critical in ensuring that DTNet accuracy approaches that of the original tree ensemble. Our system is highly scalable and can perform efficient inference on batched encrypted (134 bits of security) data with amortized time in milliseconds. This is approximately three orders of magnitude faster than the standard approach of applying soft comparison at the internal nodes of the ensemble trees.
A Lyapunov Theory for Finite-Sample Guarantees of Asynchronous Q-Learning and TD-Learning Variants
Feb 02, 2021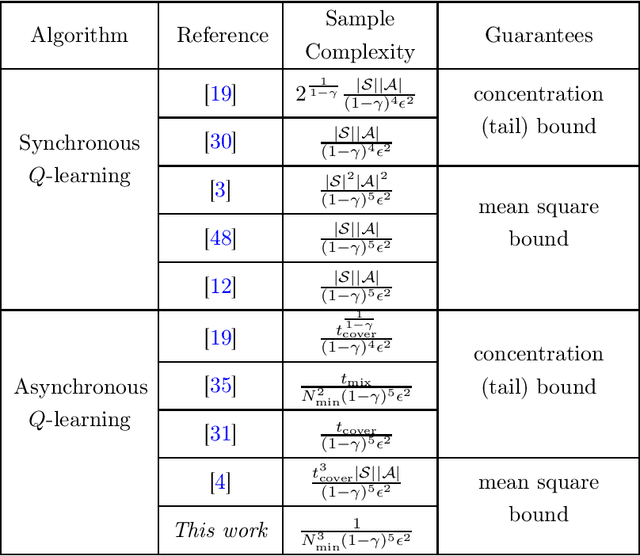
This paper develops an unified framework to study finite-sample convergence guarantees of a large class of value-based asynchronous Reinforcement Learning (RL) algorithms. We do this by first reformulating the RL algorithms as Markovian Stochastic Approximation (SA) algorithms to solve fixed-point equations. We then develop a Lyapunov analysis and derive mean-square error bounds on the convergence of the Markovian SA. Based on this central result, we establish finite-sample mean-square convergence bounds for asynchronous RL algorithms such as $Q$-learning, $n$-step TD, TD$(\lambda)$, and off-policy TD algorithms including V-trace. As a by-product, by analyzing the performance bounds of the TD$(\lambda)$ (and $n$-step TD) algorithm for general $\lambda$ (and $n$), we demonstrate a bias-variance trade-off, i.e., efficiency of bootstrapping in RL. This was first posed as an open problem in [37].