 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Privacy-Preserving Entity Resolution with Fully Homomorphic Encryption
Jan 26, 2026The canonical challenge of entity resolution within high-compliance sectors, where secure identity reconciliation is frequently confounded by significant data heterogeneity, including syntactic variations in personal identifiers, is a longstanding and complex problem. To this end, we introduce a novel multimodal framework operating with the voluminous data sets typical of government and financial institutions. Specifically, our methodology is designed to address the tripartite challenge of data volume, matching fidelity, and privacy. Consequently, the underlying plaintext of personally identifiable information remains computationally inaccessible throughout the matching lifecycle, empowering institutions to rigorously satisfy stringent regulatory mandates with cryptographic assurances of client confidentiality while achieving a demonstrably low equal error rate and maintaining computational tractability at scale.
Forget Less by Learning Together through Concept Consolidation
Jan 05, 2026Custom Diffusion Models (CDMs) have gained significant attention due to their remarkable ability to personalize generative processes. However, existing CDMs suffer from catastrophic forgetting when continuously learning new concepts. Most prior works attempt to mitigate this issue under the sequential learning setting with a fixed order of concept inflow and neglect inter-concept interactions. In this paper, we propose a novel framework - Forget Less by Learning Together (FL2T) - that enables concurrent and order-agnostic concept learning while addressing catastrophic forgetting. Specifically, we introduce a set-invariant inter-concept learning module where proxies guide feature selection across concepts, facilitating improved knowledge retention and transfer. By leveraging inter-concept guidance, our approach preserves old concepts while efficiently incorporating new ones. Extensive experiments, across three datasets, demonstrates that our method significantly improves concept retention and mitigates catastrophic forgetting, highlighting the effectiveness of inter-concept catalytic behavior in incremental concept learning of ten tasks with at least 2% gain on average CLIP Image Alignment scores.
Aligning Characteristic Descriptors with Images for Human-Expert-like Explainability
Nov 06, 2024



In mission-critical domains such as law enforcement and medical diagnosis, the ability to explain and interpret the outputs of deep learning models is crucial for ensuring user trust and supporting informed decision-making. Despite advancements in explainability, existing methods often fall short in providing explanations that mirror the depth and clarity of those given by human experts. Such expert-level explanations are essential for the dependable application of deep learning models in law enforcement and medical contexts. Additionally, we recognize that most explanations in real-world scenarios are communicated primarily through natural language. Addressing these needs, we propose a novel approach that utilizes characteristic descriptors to explain model decisions by identifying their presence in images, thereby generating expert-like explanations. Our method incorporates a concept bottleneck layer within the model architecture, which calculates the similarity between image and descriptor encodings to deliver inherent and faithful explanations. Through experiments in face recognition and chest X-ray diagnosis, we demonstrate that our approach offers a significant contrast over existing techniques, which are often limited to the use of saliency maps. We believe our approach represents a significant step toward making deep learning systems more accountable, transparent, and trustworthy in the critical domains of face recognition and medical diagnosis.
Enhancing Authorship Attribution through Embedding Fusion: A Novel Approach with Masked and Encoder-Decoder Language Models
Nov 01, 2024



The increasing prevalence of AI-generated content alongside human-written text underscores the need for reliable discrimination methods. To address this challenge, we propose a novel framework with textual embeddings from Pre-trained Language Models (PLMs) to distinguish AI-generated and human-authored text. Our approach utilizes Embedding Fusion to integrate semantic information from multiple Language Models, harnessing their complementary strengths to enhance performance. Through extensive evaluation across publicly available diverse datasets, our proposed approach demonstrates strong performance, achieving classification accuracy greater than 96% and a Matthews Correlation Coefficient (MCC) greater than 0.93. This evaluation is conducted on a balanced dataset of texts generated from five well-known Large Language Models (LLMs), highlighting the effectiveness and robustness of our novel methodology.
Towards Building Secure UAV Navigation with FHE-aware Knowledge Distillation
Nov 01, 2024



In safeguarding mission-critical systems, such as Unmanned Aerial Vehicles (UAVs), preserving the privacy of path trajectories during navigation is paramount. While the combination of Reinforcement Learning (RL) and Fully Homomorphic Encryption (FHE) holds promise, the computational overhead of FHE presents a significant challenge. This paper proposes an innovative approach that leverages Knowledge Distillation to enhance the practicality of secure UAV navigation. By integrating RL and FHE, our framework addresses vulnerabilities to adversarial attacks while enabling real-time processing of encrypted UAV camera feeds, ensuring data security. To mitigate FHE's latency, Knowledge Distillation is employed to compress the network, resulting in an impressive 18x speedup without compromising performance, as evidenced by an R-squared score of 0.9499 compared to the original model's score of 0.9631. Our methodology underscores the feasibility of processing encrypted data for UAV navigation tasks, emphasizing security alongside performance efficiency and timely processing. These findings pave the way for deploying autonomous UAVs in sensitive environments, bolstering their resilience against potential security threats.
Confidential and Protected Disease Classifier using Fully Homomorphic Encryption
May 05, 2024



With the rapid surge in the prevalence of Large Language Models (LLMs), individuals are increasingly turning to conversational AI for initial insights across various domains, including health-related inquiries such as disease diagnosis. Many users seek potential causes on platforms like ChatGPT or Bard before consulting a medical professional for their ailment. These platforms offer valuable benefits by streamlining the diagnosis process, alleviating the significant workload of healthcare practitioners, and saving users both time and money by avoiding unnecessary doctor visits. However, Despite the convenience of such platforms, sharing personal medical data online poses risks, including the presence of malicious platforms or potential eavesdropping by attackers. To address privacy concerns, we propose a novel framework combining FHE and Deep Learning for a secure and private diagnosis system. Operating on a question-and-answer-based model akin to an interaction with a medical practitioner, this end-to-end secure system employs Fully Homomorphic Encryption (FHE) to handle encrypted input data. Given FHE's computational constraints, we adapt deep neural networks and activation functions to the encryted domain. Further, we also propose a faster algorithm to compute summation of ciphertext elements. Through rigorous experiments, we demonstrate the efficacy of our approach. The proposed framework achieves strict security and privacy with minimal loss in performance.
Enhancing Privacy and Security of Autonomous UAV Navigation
Apr 26, 2024



Autonomous Unmanned Aerial Vehicles (UAVs) have become essential tools in defense, law enforcement, disaster response, and product delivery. These autonomous navigation systems require a wireless communication network, and of late are deep learning based. In critical scenarios such as border protection or disaster response, ensuring the secure navigation of autonomous UAVs is paramount. But, these autonomous UAVs are susceptible to adversarial attacks through the communication network or the deep learning models - eavesdropping / man-in-the-middle / membership inference / reconstruction. To address this susceptibility, we propose an innovative approach that combines Reinforcement Learning (RL) and Fully Homomorphic Encryption (FHE) for secure autonomous UAV navigation. This end-to-end secure framework is designed for real-time video feeds captured by UAV cameras and utilizes FHE to perform inference on encrypted input images. While FHE allows computations on encrypted data, certain computational operators are yet to be implemented. Convolutional neural networks, fully connected neural networks, activation functions and OpenAI Gym Library are meticulously adapted to the FHE domain to enable encrypted data processing. We demonstrate the efficacy of our proposed approach through extensive experimentation. Our proposed approach ensures security and privacy in autonomous UAV navigation with negligible loss in performance.
Enhancing Privacy in Face Analytics Using Fully Homomorphic Encryption
Apr 24, 2024



Modern face recognition systems utilize deep neural networks to extract salient features from a face. These features denote embeddings in latent space and are often stored as templates in a face recognition system. These embeddings are susceptible to data leakage and, in some cases, can even be used to reconstruct the original face image. To prevent compromising identities, template protection schemes are commonly employed. However, these schemes may still not prevent the leakage of soft biometric information such as age, gender and race. To alleviate this issue, we propose a novel technique that combines Fully Homomorphic Encryption (FHE) with an existing template protection scheme known as PolyProtect. We show that the embeddings can be compressed and encrypted using FHE and transformed into a secure PolyProtect template using polynomial transformation, for additional protection. We demonstrate the efficacy of the proposed approach through extensive experiments on multiple datasets. Our proposed approach ensures irreversibility and unlinkability, effectively preventing the leakage of soft biometric attributes from face embeddings without compromising recognition accuracy.
RidgeBase: A Cross-Sensor Multi-Finger Contactless Fingerprint Dataset
Jul 09, 2023



Contactless fingerprint matching using smartphone cameras can alleviate major challenges of traditional fingerprint systems including hygienic acquisition, portability and presentation attacks. However, development of practical and robust contactless fingerprint matching techniques is constrained by the limited availability of large scale real-world datasets. To motivate further advances in contactless fingerprint matching across sensors, we introduce the RidgeBase benchmark dataset. RidgeBase consists of more than 15,000 contactless and contact-based fingerprint image pairs acquired from 88 individuals under different background and lighting conditions using two smartphone cameras and one flatbed contact sensor. Unlike existing datasets, RidgeBase is designed to promote research under different matching scenarios that include Single Finger Matching and Multi-Finger Matching for both contactless- to-contactless (CL2CL) and contact-to-contactless (C2CL) verification and identification. Furthermore, due to the high intra-sample variance in contactless fingerprints belonging to the same finger, we propose a set-based matching protocol inspired by the advances in facial recognition datasets. This protocol is specifically designed for pragmatic contactless fingerprint matching that can account for variances in focus, polarity and finger-angles. We report qualitative and quantitative baseline results for different protocols using a COTS fingerprint matcher (Verifinger) and a Deep CNN based approach on the RidgeBase dataset. The dataset can be downloaded here: https://www.buffalo.edu/cubs/research/datasets/ridgebase-benchmark-dataset.html
* Paper accepted at IJCB 2022
HEFT: Homomorphically Encrypted Fusion of Biometric Templates
Aug 15, 2022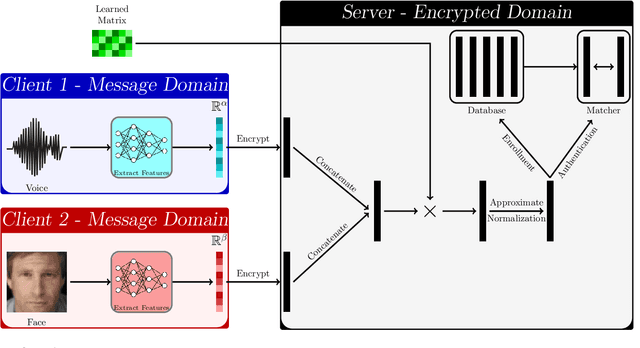

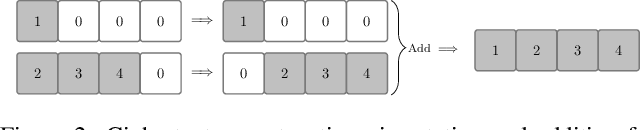
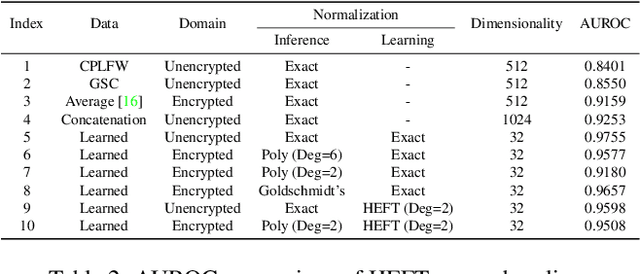
This paper proposes a non-interactive end-to-end solution for secure fusion and matching of biometric templates using fully homomorphic encryption (FHE). Given a pair of encrypted feature vectors, we perform the following ciphertext operations, i) feature concatenation, ii) fusion and dimensionality reduction through a learned linear projection, iii) scale normalization to unit $\ell_2$-norm, and iv) match score computation. Our method, dubbed HEFT (Homomorphically Encrypted Fusion of biometric Templates), is custom-designed to overcome the unique constraint imposed by FHE, namely the lack of support for non-arithmetic operations. From an inference perspective, we systematically explore different data packing schemes for computationally efficient linear projection and introduce a polynomial approximation for scale normalization. From a training perspective, we introduce an FHE-aware algorithm for learning the linear projection matrix to mitigate errors induced by approximate normalization. Experimental evaluation for template fusion and matching of face and voice biometrics shows that HEFT (i) improves biometric verification performance by 11.07% and 9.58% AUROC compared to the respective unibiometric representations while compressing the feature vectors by a factor of 16 (512D to 32D), and (ii) fuses a pair of encrypted feature vectors and computes its match score against a gallery of size 1024 in 884 ms. Code and data are available at https://github.com/human-analysis/encrypted-biometric-fusion