 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Fairness-Accuracy tradeoff with few Test Samples under Covariate Shift
Oct 11, 2023Covariate shift in the test data can significantly downgrade both the accuracy and the fairness performance of the model. Ensuring fairness across different sensitive groups in such settings is of paramount importance due to societal implications like criminal justice. We operate under the unsupervised regime where only a small set of unlabeled test samples along with a labeled training set is available. Towards this problem, we make three contributions. First is a novel composite weighted entropy based objective for prediction accuracy which is optimized along with a representation matching loss for fairness. We experimentally verify that optimizing with our loss formulation outperforms a number of state-of-the-art baselines in the pareto sense with respect to the fairness-accuracy tradeoff on several standard datasets. Our second contribution is a new setting we term Asymmetric Covariate Shift that, to the best of our knowledge, has not been studied before. Asymmetric covariate shift occurs when distribution of covariates of one group shifts significantly compared to the other groups and this happens when a dominant group is over-represented. While this setting is extremely challenging for current baselines, We show that our proposed method significantly outperforms them. Our third contribution is theoretical, where we show that our weighted entropy term along with prediction loss on the training set approximates test loss under covariate shift. Empirically and through formal sample complexity bounds, we show that this approximation to the unseen test loss does not depend on importance sampling variance which affects many other baselines.
Identifiability Guarantees for Causal Disentanglement from Soft Interventions
Jul 13, 2023



Causal disentanglement aims to uncover a representation of data using latent variables that are interrelated through a causal model. Such a representation is identifiable if the latent model that explains the data is unique. In this paper, we focus on the scenario where unpaired observational and interventional data are available, with each intervention changing the mechanism of a latent variable. When the causal variables are fully observed, statistically consistent algorithms have been developed to identify the causal model under faithfulness assumptions. We here show that identifiability can still be achieved with unobserved causal variables, given a generalized notion of faithfulness. Our results guarantee that we can recover the latent causal model up to an equivalence class and predict the effect of unseen combinations of interventions, in the limit of infinite data. We implement our causal disentanglement framework by developing an autoencoding variational Bayes algorithm and apply it to the problem of predicting combinatorial perturbation effects in genomics.
Front-door Adjustment Beyond Markov Equivalence with Limited Graph Knowledge
Jun 19, 2023Causal effect estimation from data typically requires assumptions about the cause-effect relations either explicitly in the form of a causal graph structure within the Pearlian framework, or implicitly in terms of (conditional) independence statements between counterfactual variables within the potential outcomes framework. When the treatment variable and the outcome variable are confounded, front-door adjustment is an important special case where, given the graph, causal effect of the treatment on the target can be estimated using post-treatment variables. However, the exact formula for front-door adjustment depends on the structure of the graph, which is difficult to learn in practice. In this work, we provide testable conditional independence statements to compute the causal effect using front-door-like adjustment without knowing the graph under limited structural side information. We show that our method is applicable in scenarios where knowing the Markov equivalence class is not sufficient for causal effect estimation. We demonstrate the effectiveness of our method on a class of random graphs as well as real causal fairness benchmarks.
Optimal Best-Arm Identification in Bandits with Access to Offline Data
Jun 15, 2023



Learning paradigms based purely on offline data as well as those based solely on sequential online learning have been well-studied in the literature. In this paper, we consider combining offline data with online learning, an area less studied but of obvious practical importance. We consider the stochastic $K$-armed bandit problem, where our goal is to identify the arm with the highest mean in the presence of relevant offline data, with confidence $1-\delta$. We conduct a lower bound analysis on policies that provide such $1-\delta$ probabilistic correctness guarantees. We develop algorithms that match the lower bound on sample complexity when $\delta$ is small. Our algorithms are computationally efficient with an average per-sample acquisition cost of $\tilde{O}(K)$, and rely on a careful characterization of the optimality conditions of the lower bound problem.
InfoNCE Loss Provably Learns Cluster-Preserving Representations
Feb 15, 2023

The goal of contrasting learning is to learn a representation that preserves underlying clusters by keeping samples with similar content, e.g. the ``dogness'' of a dog, close to each other in the space generated by the representation. A common and successful approach for tackling this unsupervised learning problem is minimizing the InfoNCE loss associated with the training samples, where each sample is associated with their augmentations (positive samples such as rotation, crop) and a batch of negative samples (unrelated samples). To the best of our knowledge, it was unanswered if the representation learned by minimizing the InfoNCE loss preserves the underlying data clusters, as it only promotes learning a representation that is faithful to augmentations, i.e., an image and its augmentations have the same representation. Our main result is to show that the representation learned by InfoNCE with a finite number of negative samples is also consistent with respect to clusters in the data, under the condition that the augmentation sets within clusters may be non-overlapping but are close and intertwined, relative to the complexity of the learning function class.
Score-based Causal Representation Learning with Interventions
Jan 19, 2023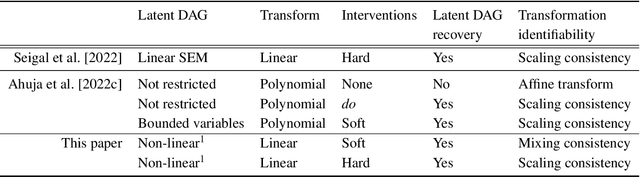
This paper studies causal representation learning problem when the latent causal variables are observed indirectly through an unknown linear transformation. The objectives are: (i) recovering the unknown linear transformation (up to scaling and ordering), and (ii) determining the directed acyclic graph (DAG) underlying the latent variables. Since identifiable representation learning is impossible based on only observational data, this paper uses both observational and interventional data. The interventional data is generated under distinct single-node randomized hard and soft interventions. These interventions are assumed to cover all nodes in the latent space. It is established that the latent DAG structure can be recovered under soft randomized interventions via the following two steps. First, a set of transformation candidates is formed by including all inverting transformations corresponding to which the \emph{score} function of the transformed variables has the minimal number of coordinates that change between an interventional and the observational environment summed over all pairs. Subsequently, this set is distilled using a simple constraint to recover the latent DAG structure. For the special case of hard randomized interventions, with an additional hypothesis testing step, one can also uniquely recover the linear transformation, up to scaling and a valid causal ordering. These results generalize the recent results that either assume deterministic hard interventions or linear causal relationships in the latent space.
Optimal Algorithms for Latent Bandits with Cluster Structure
Jan 17, 2023We consider the problem of latent bandits with cluster structure where there are multiple users, each with an associated multi-armed bandit problem. These users are grouped into \emph{latent} clusters such that the mean reward vectors of users within the same cluster are identical. At each round, a user, selected uniformly at random, pulls an arm and observes a corresponding noisy reward. The goal of the users is to maximize their cumulative rewards. This problem is central to practical recommendation systems and has received wide attention of late \cite{gentile2014online, maillard2014latent}. Now, if each user acts independently, then they would have to explore each arm independently and a regret of $\Omega(\sqrt{\mathsf{MNT}})$ is unavoidable, where $\mathsf{M}, \mathsf{N}$ are the number of arms and users, respectively. Instead, we propose LATTICE (Latent bAndiTs via maTrIx ComplEtion) which allows exploitation of the latent cluster structure to provide the minimax optimal regret of $\widetilde{O}(\sqrt{(\mathsf{M}+\mathsf{N})\mathsf{T}})$, when the number of clusters is $\widetilde{O}(1)$. This is the first algorithm to guarantee such a strong regret bound. LATTICE is based on a careful exploitation of arm information within a cluster while simultaneously clustering users. Furthermore, it is computationally efficient and requires only $O(\log{\mathsf{T}})$ calls to an offline matrix completion oracle across all $\mathsf{T}$ rounds.
Causal Bandits for Linear Structural Equation Models
Aug 26, 2022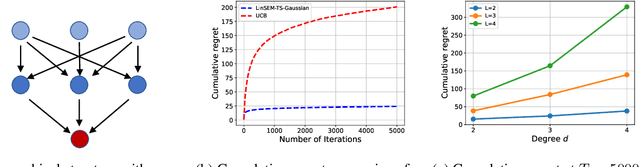
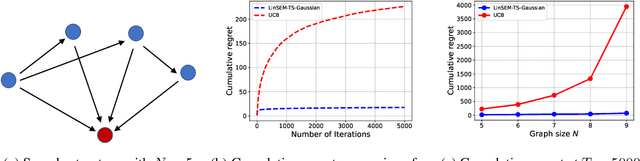
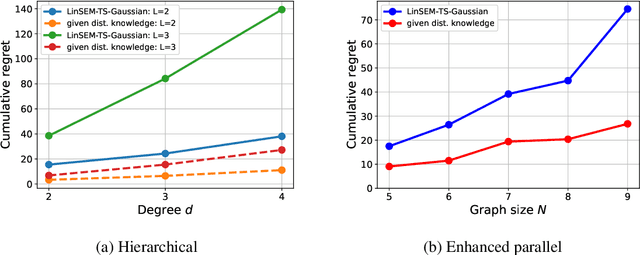
This paper studies the problem of designing an optimal sequence of interventions in a causal graphical model to minimize the cumulative regret with respect to the best intervention in hindsight. This is, naturally, posed as a causal bandit problem. The focus is on causal bandits for linear structural equation models (SEMs) and soft interventions. It is assumed that the graph's structure is known, and it has $N$ nodes. Two linear mechanisms, one soft intervention and one observational, are assumed for each node, giving rise to $2^N$ possible interventions. The existing causal bandit algorithms assume that at least the interventional distributions of the reward node's parents are fully specified. However, there are $2^N$ such distributions (one corresponding to each intervention), acquiring which becomes prohibitive even in moderate-sized graphs. This paper dispenses with the assumption of knowing these distributions. Two algorithms are proposed for the frequentist (UCB-based) and Bayesian (Thompson Sampling-based) settings. The key idea of these algorithms is to avoid directly estimating the $2^N$ reward distributions and instead estimate the parameters that fully specify the SEMs (linear in $N$) and use them to compute the rewards. In both algorithms, under boundedness assumptions on noise and the parameter space, the cumulative regrets scale as $\tilde{\cal O} ((2d)^L L \sqrt{T})$, where $d$ is the graph's maximum degree, and $L$ is the length of its longest causal path.
Causal Graphs Underlying Generative Models: Path to Learning with Limited Data
Jul 14, 2022

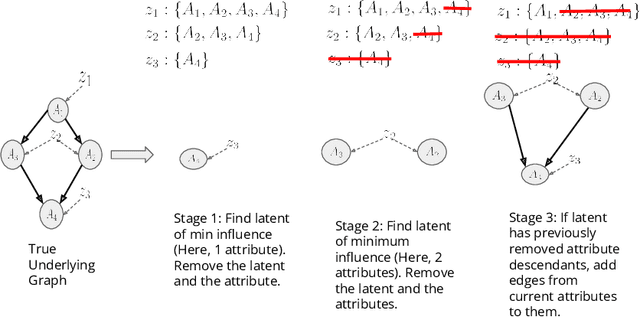

Training generative models that capture rich semantics of the data and interpreting the latent representations encoded by such models are very important problems in unsupervised learning. In this work, we provide a simple algorithm that relies on perturbation experiments on latent codes of a pre-trained generative autoencoder to uncover a causal graph that is implied by the generative model. We leverage pre-trained attribute classifiers and perform perturbation experiments to check for influence of a given latent variable on a subset of attributes. Given this, we show that one can fit an effective causal graph that models a structural equation model between latent codes taken as exogenous variables and attributes taken as observed variables. One interesting aspect is that a single latent variable controls multiple overlapping subsets of attributes unlike conventional approach that tries to impose full independence. Using a pre-trained RNN-based generative autoencoder trained on a dataset of peptide sequences, we demonstrate that the learnt causal graph from our algorithm between various attributes and latent codes can be used to predict a specific property for sequences which are unseen. We compare prediction models trained on either all available attributes or only the ones in the Markov blanket and empirically show that in both the unsupervised and supervised regimes, typically, using the predictor that relies on Markov blanket attributes generalizes better for out-of-distribution sequences.
PAC Generalization via Invariant Representations
May 31, 2022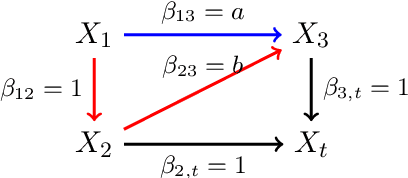
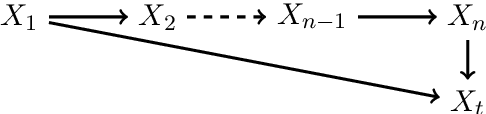
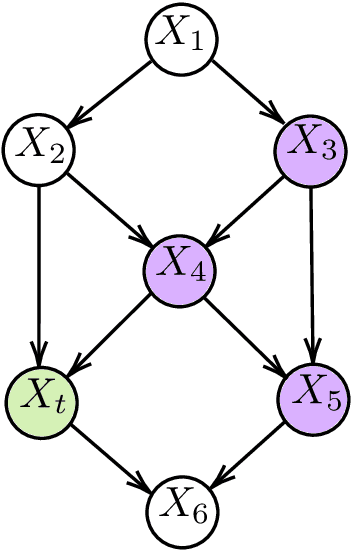
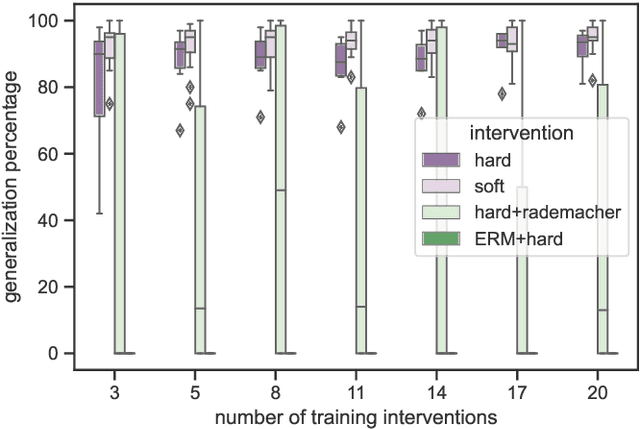
One method for obtaining generalizable solutions to machine learning tasks when presented with diverse training environments is to find invariant representations of the data. These are representations of the covariates such that the best model on top of the representation is invariant across training environments. In the context of linear Structural Equation Models (SEMs), invariant representations might allow us to learn models with out-of-distribution guarantees, i.e., models that are robust to interventions in the SEM. To address the invariant representation problem in a finite sample setting, we consider the notion of $\epsilon$-approximate invariance. We study the following question: If a representation is approximately invariant with respect to a given number of training interventions, will it continue to be approximately invariant on a larger collection of unseen SEMs? This larger collection of SEMs is generated through a parameterized family of interventions. Inspired by PAC learning, we obtain finite-sample out-of-distribution generalization guarantees for approximate invariance that holds probabilistically over a family of linear SEMs without faithfulness assumptions. Our results show bounds that do not scale in ambient dimension when intervention sites are restricted to lie in a constant size subset of in-degree bounded nodes. We also show how to extend our results to a linear indirect observation model that incorporates latent variables.