 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic keypoint-based pose estimation from single RGB frames
Apr 12, 2022


This paper presents an approach to estimating the continuous 6-DoF pose of an object from a single RGB image. The approach combines semantic keypoints predicted by a convolutional network (convnet) with a deformable shape model. Unlike prior investigators, we are agnostic to whether the object is textured or textureless, as the convnet learns the optimal representation from the available training-image data. Furthermore, the approach can be applied to instance- and class-based pose recovery. Additionally, we accompany our main pipeline with a technique for semi-automatic data generation from unlabeled videos. This procedure allows us to train the learnable components of our method with minimal manual intervention in the labeling process. Empirically, we show that our approach can accurately recover the 6-DoF object pose for both instance- and class-based scenarios even against a cluttered background. We apply our approach both to several, existing, large-scale datasets - including PASCAL3D+, LineMOD-Occluded, YCB-Video, and TUD-Light - and, using our labeling pipeline, to a new dataset with novel object classes that we introduce here. Extensive empirical evaluations show that our approach is able to provide pose estimation results comparable to the state of the art.
* https://sites.google.com/view/rcta-object-keypoints-dataset/home. arXiv admin note: substantial text overlap with arXiv:1703.04670
Cross-modal Map Learning for Vision and Language Navigation
Mar 21, 2022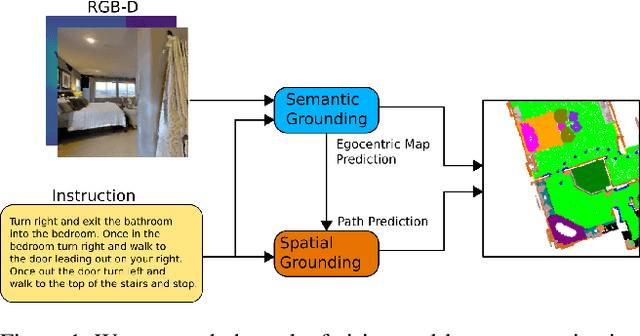
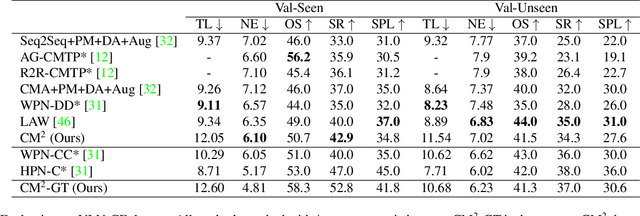
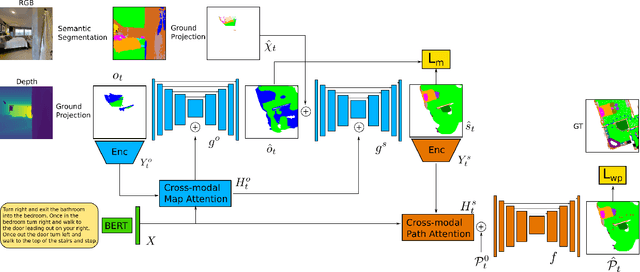
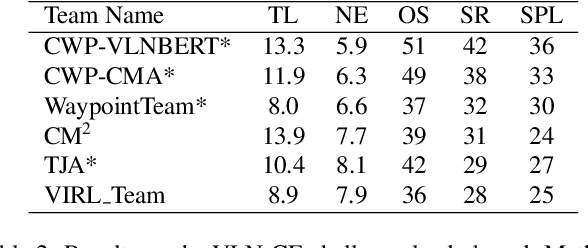
We consider the problem of Vision-and-Language Navigation (VLN). The majority of current methods for VLN are trained end-to-end using either unstructured memory such as LSTM, or using cross-modal attention over the egocentric observations of the agent. In contrast to other works, our key insight is that the association between language and vision is stronger when it occurs in explicit spatial representations. In this work, we propose a cross-modal map learning model for vision-and-language navigation that first learns to predict the top-down semantics on an egocentric map for both observed and unobserved regions, and then predicts a path towards the goal as a set of waypoints. In both cases, the prediction is informed by the language through cross-modal attention mechanisms. We experimentally test the basic hypothesis that language-driven navigation can be solved given a map, and then show competitive results on the full VLN-CE benchmark.
Uncertainty-driven Planner for Exploration and Navigation
Feb 24, 2022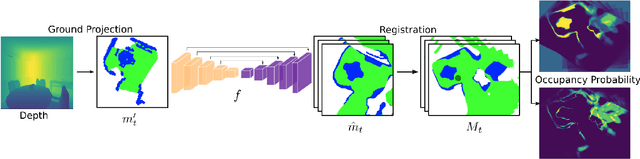
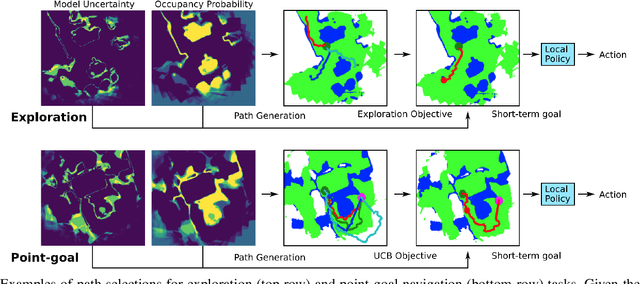

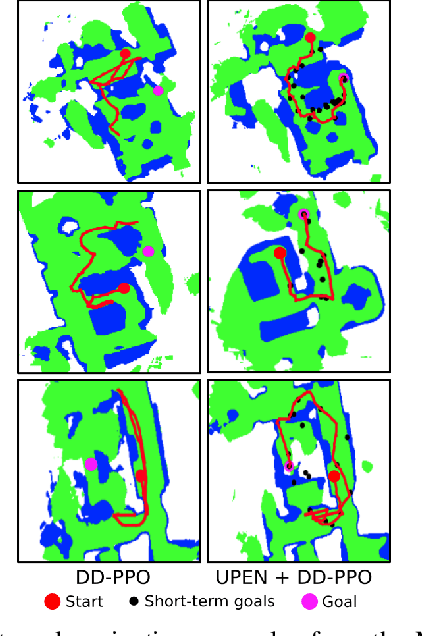
We consider the problems of exploration and point-goal navigation in previously unseen environments, where the spatial complexity of indoor scenes and partial observability constitute these tasks challenging. We argue that learning occupancy priors over indoor maps provides significant advantages towards addressing these problems. To this end, we present a novel planning framework that first learns to generate occupancy maps beyond the field-of-view of the agent, and second leverages the model uncertainty over the generated areas to formulate path selection policies for each task of interest. For point-goal navigation the policy chooses paths with an upper confidence bound policy for efficient and traversable paths, while for exploration the policy maximizes model uncertainty over candidate paths. We perform experiments in the visually realistic environments of Matterport3D using the Habitat simulator and demonstrate: 1) Improved results on exploration and map quality metrics over competitive methods, and 2) The effectiveness of our planning module when paired with the state-of-the-art DD-PPO method for the point-goal navigation task.
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Sep 27, 2021
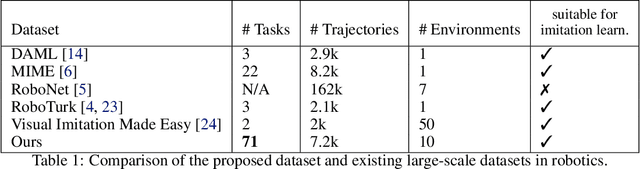

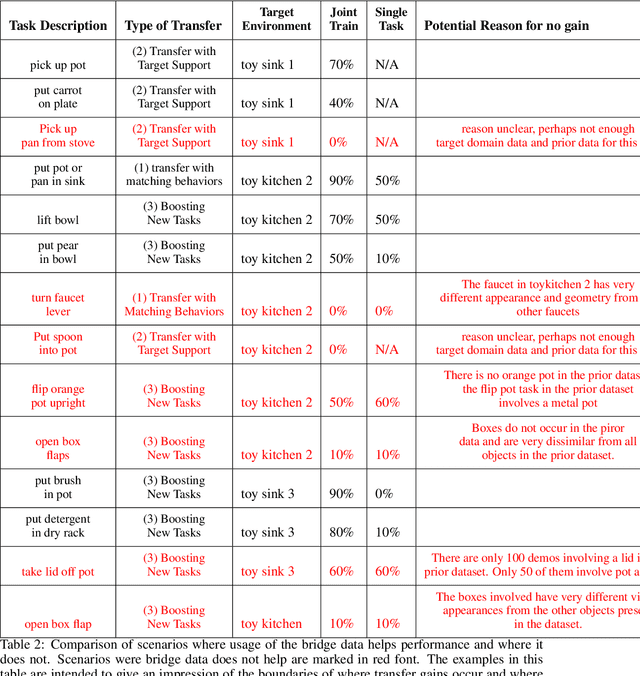
Robot learning holds the promise of learning policies that generalize broadly. However, such generalization requires sufficiently diverse datasets of the task of interest, which can be prohibitively expensive to collect. In other fields, such as computer vision, it is common to utilize shared, reusable datasets, such as ImageNet, to overcome this challenge, but this has proven difficult in robotics. In this paper, we ask: what would it take to enable practical data reuse in robotics for end-to-end skill learning? We hypothesize that the key is to use datasets with multiple tasks and multiple domains, such that a new user that wants to train their robot to perform a new task in a new domain can include this dataset in their training process and benefit from cross-task and cross-domain generalization. To evaluate this hypothesis, we collect a large multi-domain and multi-task dataset, with 7,200 demonstrations constituting 71 tasks across 10 environments, and empirically study how this data can improve the learning of new tasks in new environments. We find that jointly training with the proposed dataset and 50 demonstrations of a never-before-seen task in a new domain on average leads to a 2x improvement in success rate compared to using target domain data alone. We also find that data for only a few tasks in a new domain can bridge the domain gap and make it possible for a robot to perform a variety of prior tasks that were only seen in other domains. These results suggest that reusing diverse multi-task and multi-domain datasets, including our open-source dataset, may pave the way for broader robot generalization, eliminating the need to re-collect data for each new robot learning project.
Learning to Map for Active Semantic Goal Navigation
Jun 29, 2021
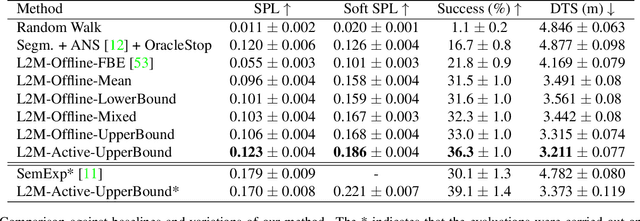
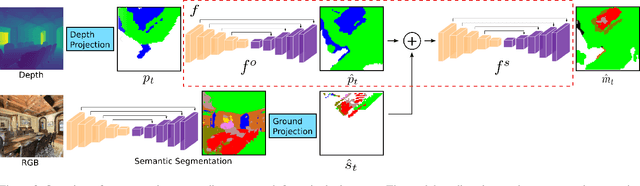

We consider the problem of object goal navigation in unseen environments. In our view, solving this problem requires learning of contextual semantic priors, a challenging endeavour given the spatial and semantic variability of indoor environments. Current methods learn to implicitly encode these priors through goal-oriented navigation policy functions operating on spatial representations that are limited to the agent's observable areas. In this work, we propose a novel framework that actively learns to generate semantic maps outside the field of view of the agent and leverages the uncertainty over the semantic classes in the unobserved areas to decide on long term goals. We demonstrate that through this spatial prediction strategy, we are able to learn semantic priors in scenes that can be leveraged in unknown environments. Additionally, we show how different objectives can be defined by balancing exploration with exploitation during searching for semantic targets. Our method is validated in the visually realistic environments offered by the Matterport3D dataset and show state of the art results on the object goal navigation task.
Object-centric Video Prediction without Annotation
May 06, 2021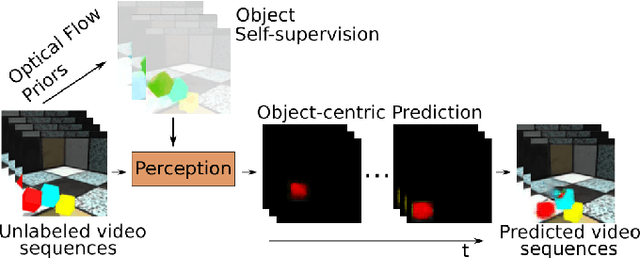
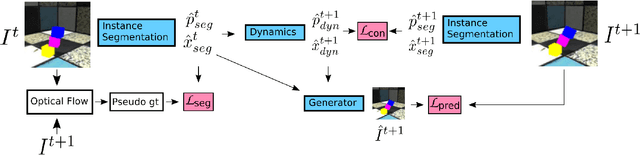

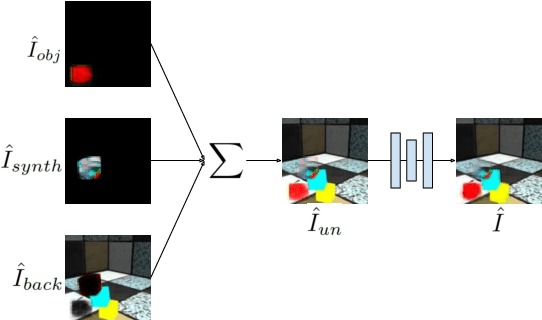
In order to interact with the world, agents must be able to predict the results of the world's dynamics. A natural approach to learn about these dynamics is through video prediction, as cameras are ubiquitous and powerful sensors. Direct pixel-to-pixel video prediction is difficult, does not take advantage of known priors, and does not provide an easy interface to utilize the learned dynamics. Object-centric video prediction offers a solution to these problems by taking advantage of the simple prior that the world is made of objects and by providing a more natural interface for control. However, existing object-centric video prediction pipelines require dense object annotations in training video sequences. In this work, we present Object-centric Prediction without Annotation (OPA), an object-centric video prediction method that takes advantage of priors from powerful computer vision models. We validate our method on a dataset comprised of video sequences of stacked objects falling, and demonstrate how to adapt a perception model in an environment through end-to-end video prediction training.
Deformable Linear Object Prediction Using Locally Linear Latent Dynamics
Mar 26, 2021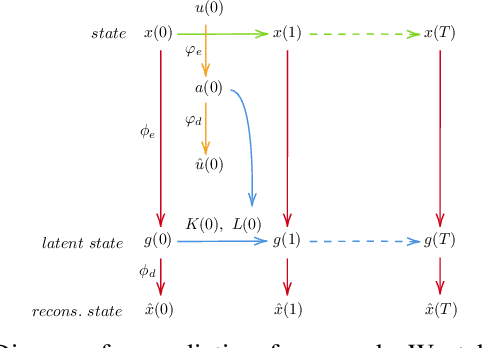
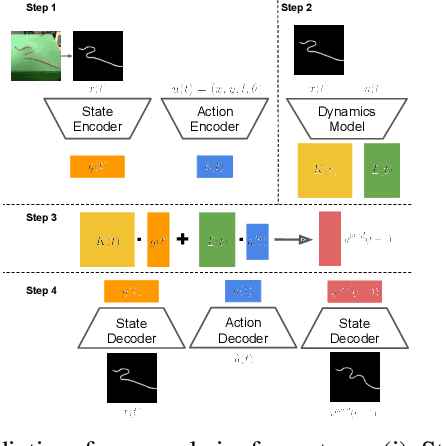


We propose a framework for deformable linear object prediction. Prediction of deformable objects (e.g., rope) is challenging due to their non-linear dynamics and infinite-dimensional configuration spaces. By mapping the dynamics from a non-linear space to a linear space, we can use the good properties of linear dynamics for easier learning and more efficient prediction. We learn a locally linear, action-conditioned dynamics model that can be used to predict future latent states. Then, we decode the predicted latent state into the predicted state. We also apply a sampling-based optimization algorithm to select the optimal control action. We empirically demonstrate that our approach can predict the rope state accurately up to ten steps into the future and that our algorithm can find the optimal action given an initial state and a goal state.
Reinforcement Learning with Videos: Combining Offline Observations with Interaction
Nov 12, 2020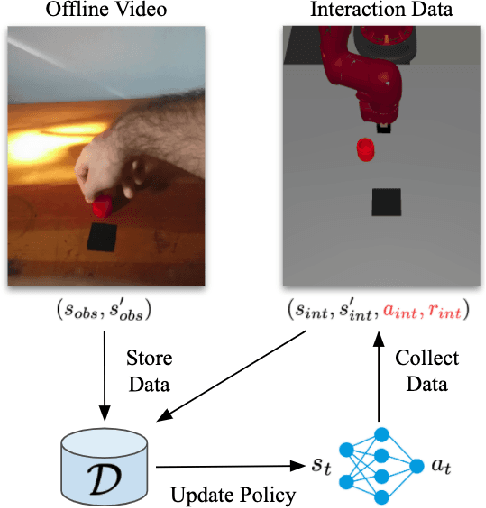

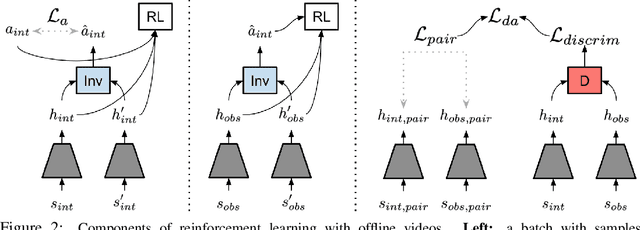
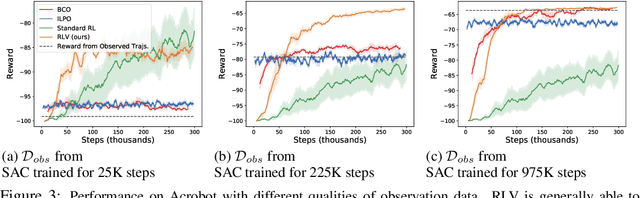
Reinforcement learning is a powerful framework for robots to acquire skills from experience, but often requires a substantial amount of online data collection. As a result, it is difficult to collect sufficiently diverse experiences that are needed for robots to generalize broadly. Videos of humans, on the other hand, are a readily available source of broad and interesting experiences. In this paper, we consider the question: can we perform reinforcement learning directly on experience collected by humans? This problem is particularly difficult, as such videos are not annotated with actions and exhibit substantial visual domain shift relative to the robot's embodiment. To address these challenges, we propose a framework for reinforcement learning with videos (RLV). RLV learns a policy and value function using experience collected by humans in combination with data collected by robots. In our experiments, we find that RLV is able to leverage such videos to learn challenging vision-based skills with less than half as many samples as RL methods that learn from scratch.
Action for Better Prediction
Mar 13, 2020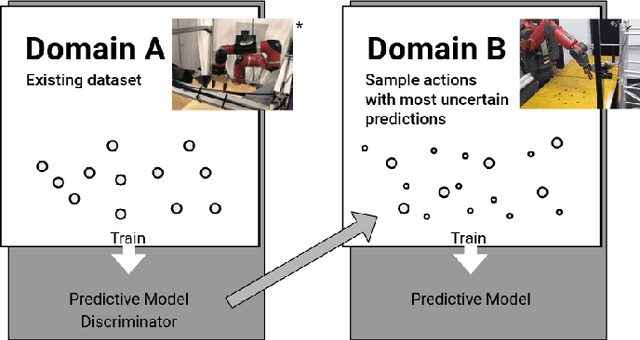


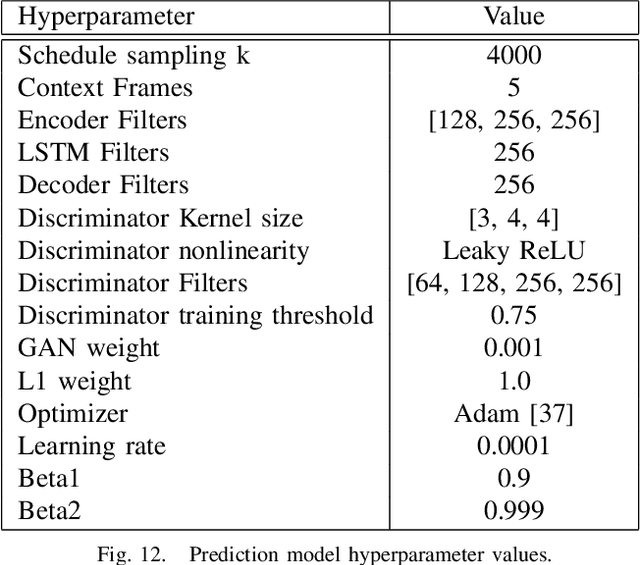
Good prediction is necessary for autonomous robotics to make informed decisions in dynamic environments. Improvements can be made to the performance of a given data-driven prediction model by using better sampling strategies when collecting training data. Active learning approaches to optimal sampling have been combined with the mathematically general approaches to incentivizing exploration presented in the curiosity literature via model-based formulations of curiosity. We present an adversarial curiosity method which maximizes a score given by a discriminator network. This score gives a measure of prediction certainty enabling our approach to sample sequences of observations and actions which result in outcomes considered the least realistic by the discriminator. We demonstrate the ability of our active sampling method to achieve higher prediction performance and higher sample efficiency in a domain transfer problem for robotic manipulation tasks. We also present a validation dataset of action-conditioned video of robotic manipulation tasks on which we test the prediction performance of our trained models.
Reactive Navigation in Partially Familiar Planar Environments Using Semantic Perceptual Feedback
Feb 20, 2020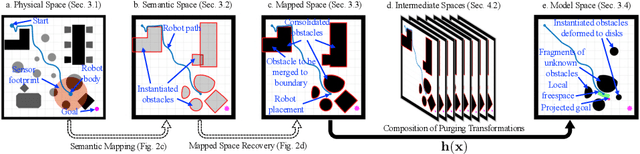

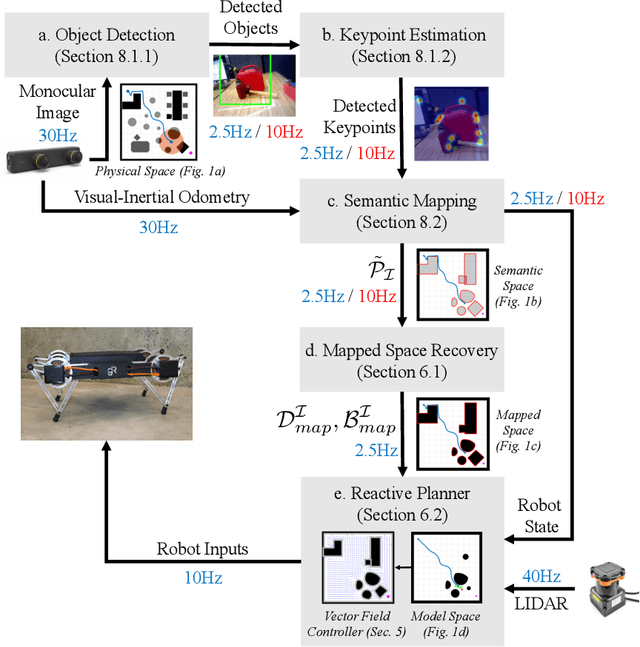

This paper solves the planar navigation problem by recourse to an online reactive scheme that exploits recent advances in SLAM and visual object recognition to recast prior geometric knowledge in terms of an offline catalogue of familiar objects. The resulting vector field planner guarantees convergence to an arbitrarily specified goal, avoiding collisions along the way with fixed but arbitrarily placed instances from the catalogue as well as completely unknown fixed obstacles so long as they are strongly convex and well separated. We illustrate the generic robustness properties of such deterministic reactive planners as well as the relatively modest computational cost of this algorithm by supplementing an extensive numerical study with physical implementation on both a wheeled and legged platform in different settings.