 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Data Augmentation in Model Compression: An Empirical and Comprehensive Study
May 22, 2023The excellent performance of deep neural networks is usually accompanied by a large number of parameters and computations, which have limited their usage on the resource-limited edge devices. To address this issue, abundant methods such as pruning, quantization and knowledge distillation have been proposed to compress neural networks and achieved significant breakthroughs. However, most of these compression methods focus on the architecture or the training method of neural networks but ignore the influence from data augmentation. In this paper, we revisit the usage of data augmentation in model compression and give a comprehensive study on the relation between model sizes and their optimal data augmentation policy. To sum up, we mainly have the following three observations: (A) Models in different sizes prefer data augmentation with different magnitudes. Hence, in iterative pruning, data augmentation with varying magnitudes leads to better performance than data augmentation with a consistent magnitude. (B) Data augmentation with a high magnitude may significantly improve the performance of large models but harm the performance of small models. Fortunately, small models can still benefit from strong data augmentations by firstly learning them with "additional parameters" and then discard these "additional parameters" during inference. (C) The prediction of a pre-trained large model can be utilized to measure the difficulty of data augmentation. Thus it can be utilized as a criterion to design better data augmentation policies. We hope this paper may promote more research on the usage of data augmentation in model compression.
CORSD: Class-Oriented Relational Self Distillation
Apr 28, 2023



Knowledge distillation conducts an effective model compression method while holding some limitations:(1) the feature based distillation methods only focus on distilling the feature map but are lack of transferring the relation of data examples; (2) the relational distillation methods are either limited to the handcrafted functions for relation extraction, such as L2 norm, or weak in inter- and intra- class relation modeling. Besides, the feature divergence of heterogeneous teacher-student architectures may lead to inaccurate relational knowledge transferring. In this work, we propose a novel training framework named Class-Oriented Relational Self Distillation (CORSD) to address the limitations. The trainable relation networks are designed to extract relation of structured data input, and they enable the whole model to better classify samples by transferring the relational knowledge from the deepest layer of the model to shallow layers. Besides, auxiliary classifiers are proposed to make relation networks capture class-oriented relation that benefits classification task. Experiments demonstrate that CORSD achieves remarkable improvements. Compared to baseline, 3.8%, 1.5% and 4.5% averaged accuracy boost can be observed on CIFAR100, ImageNet and CUB-200-2011, respectively.
CLIP-FO3D: Learning Free Open-world 3D Scene Representations from 2D Dense CLIP
Mar 16, 2023



Training a 3D scene understanding model requires complicated human annotations, which are laborious to collect and result in a model only encoding close-set object semantics. In contrast, vision-language pre-training models (e.g., CLIP) have shown remarkable open-world reasoning properties. To this end, we propose directly transferring CLIP's feature space to 3D scene understanding model without any form of supervision. We first modify CLIP's input and forwarding process so that it can be adapted to extract dense pixel features for 3D scene contents. We then project multi-view image features to the point cloud and train a 3D scene understanding model with feature distillation. Without any annotations or additional training, our model achieves promising annotation-free semantic segmentation results on open-vocabulary semantics and long-tailed concepts. Besides, serving as a cross-modal pre-training framework, our method can be used to improve data efficiency during fine-tuning. Our model outperforms previous SOTA methods in various zero-shot and data-efficient learning benchmarks. Most importantly, our model successfully inherits CLIP's rich-structured knowledge, allowing 3D scene understanding models to recognize not only object concepts but also open-world semantics.
Hebbian and Gradient-based Plasticity Enables Robust Memory and Rapid Learning in RNNs
Feb 07, 2023



Rapidly learning from ongoing experiences and remembering past events with a flexible memory system are two core capacities of biological intelligence. While the underlying neural mechanisms are not fully understood, various evidence supports that synaptic plasticity plays a critical role in memory formation and fast learning. Inspired by these results, we equip Recurrent Neural Networks (RNNs) with plasticity rules to enable them to adapt their parameters according to ongoing experiences. In addition to the traditional local Hebbian plasticity, we propose a global, gradient-based plasticity rule, which allows the model to evolve towards its self-determined target. Our models show promising results on sequential and associative memory tasks, illustrating their ability to robustly form and retain memories. In the meantime, these models can cope with many challenging few-shot learning problems. Comparing different plasticity rules under the same framework shows that Hebbian plasticity is well-suited for several memory and associative learning tasks; however, it is outperformed by gradient-based plasticity on few-shot regression tasks which require the model to infer the underlying mapping. Code is available at https://github.com/yuvenduan/PlasticRNNs.
Contrast with Reconstruct: Contrastive 3D Representation Learning Guided by Generative Pretraining
Feb 05, 2023



Mainstream 3D representation learning approaches are built upon contrastive or generative modeling pretext tasks, where great improvements in performance on various downstream tasks have been achieved. However, by investigating the methods of these two paradigms, we find that (i) contrastive models are data-hungry that suffer from a representation over-fitting issue; (ii) generative models have a data filling issue that shows inferior data scaling capacity compared to contrastive models. This motivates us to learn 3D representations by sharing the merits of both paradigms, which is non-trivial due to the pattern difference between the two paradigms. In this paper, we propose contrast with reconstruct (ReCon) that unifies these two paradigms. ReCon is trained to learn from both generative modeling teachers and cross-modal contrastive teachers through ensemble distillation, where the generative student guides the contrastive student. An encoder-decoder style ReCon-block is proposed that transfers knowledge through cross attention with stop-gradient, which avoids pretraining over-fitting and pattern difference issues. ReCon achieves a new state-of-the-art in 3D representation learning, e.g., 91.26% accuracy on ScanObjectNN. Codes will be released at https://github.com/qizekun/ReCon.
Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning?
Dec 16, 2022The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages. This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring. In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT). The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance. The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding. Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN. Codes will be released at https://github.com/RunpeiDong/ACT.
Language-Assisted 3D Feature Learning for Semantic Scene Understanding
Dec 11, 2022



Learning descriptive 3D features is crucial for understanding 3D scenes with diverse objects and complex structures. However, it is usually unknown whether important geometric attributes and scene context obtain enough emphasis in an end-to-end trained 3D scene understanding network. To guide 3D feature learning toward important geometric attributes and scene context, we explore the help of textual scene descriptions. Given some free-form descriptions paired with 3D scenes, we extract the knowledge regarding the object relationships and object attributes. We then inject the knowledge to 3D feature learning through three classification-based auxiliary tasks. This language-assisted training can be combined with modern object detection and instance segmentation methods to promote 3D semantic scene understanding, especially in a label-deficient regime. Moreover, the 3D feature learned with language assistance is better aligned with the language features, which can benefit various 3D-language multimodal tasks. Experiments on several benchmarks of 3D-only and 3D-language tasks demonstrate the effectiveness of our language-assisted 3D feature learning. Code is available at https://github.com/Asterisci/Language-Assisted-3D.
Structured Knowledge Distillation Towards Efficient and Compact Multi-View 3D Detection
Nov 21, 2022Detecting 3D objects from multi-view images is a fundamental problem in 3D computer vision. Recently, significant breakthrough has been made in multi-view 3D detection tasks. However, the unprecedented detection performance of these vision BEV (bird's-eye-view) detection models is accompanied with enormous parameters and computation, which make them unaffordable on edge devices. To address this problem, in this paper, we propose a structured knowledge distillation framework, aiming to improve the efficiency of modern vision-only BEV detection models. The proposed framework mainly includes: (a) spatial-temporal distillation which distills teacher knowledge of information fusion from different timestamps and views, (b) BEV response distillation which distills teacher response to different pillars, and (c) weight-inheriting which solves the problem of inconsistent inputs between students and teacher in modern transformer architectures. Experimental results show that our method leads to an average improvement of 2.16 mAP and 2.27 NDS on the nuScenes benchmark, outperforming multiple baselines by a large margin.
LW-ISP: A Lightweight Model with ISP and Deep Learning
Oct 08, 2022

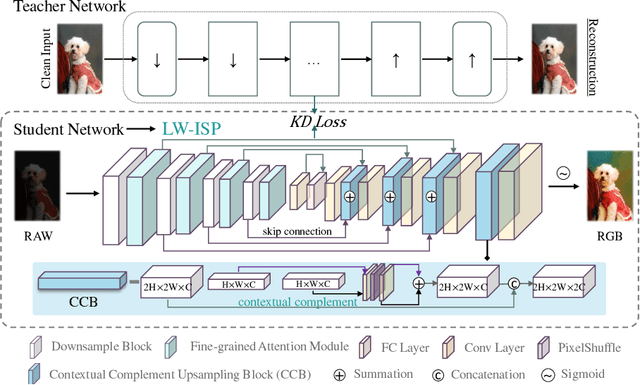

The deep learning (DL)-based methods of low-level tasks have many advantages over the traditional camera in terms of hardware prospects, error accumulation and imaging effects. Recently, the application of deep learning to replace the image signal processing (ISP) pipeline has appeared one after another; however, there is still a long way to go towards real landing. In this paper, we show the possibility of learning-based method to achieve real-time high-performance processing in the ISP pipeline. We propose LW-ISP, a novel architecture designed to implicitly learn the image mapping from RAW data to RGB image. Based on U-Net architecture, we propose the fine-grained attention module and a plug-and-play upsampling block suitable for low-level tasks. In particular, we design a heterogeneous distillation algorithm to distill the implicit features and reconstruction information of the clean image, so as to guide the learning of the student model. Our experiments demonstrate that LW-ISP has achieved a 0.38 dB improvement in PSNR compared to the previous best method, while the model parameters and calculation have been reduced by 23 times and 81 times. The inference efficiency has been accelerated by at least 15 times. Without bells and whistles, LW-ISP has achieved quite competitive results in ISP subtasks including image denoising and enhancement.
Contrastive Deep Supervision
Jul 12, 2022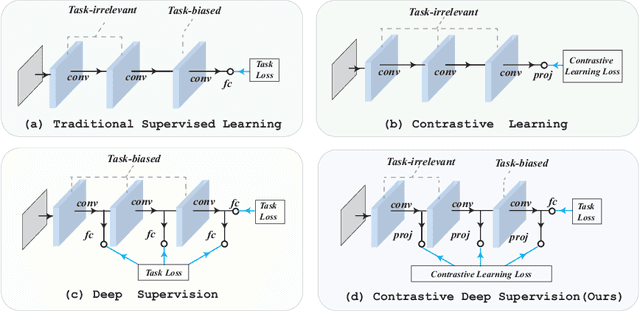
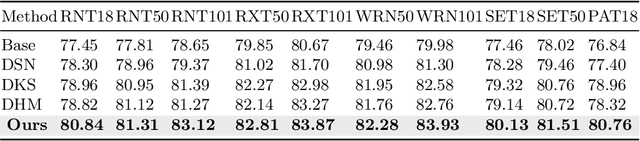
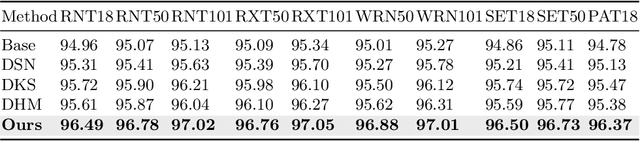
The success of deep learning is usually accompanied by the growth in neural network depth. However, the traditional training method only supervises the neural network at its last layer and propagates the supervision layer-by-layer, which leads to hardship in optimizing the intermediate layers. Recently, deep supervision has been proposed to add auxiliary classifiers to the intermediate layers of deep neural networks. By optimizing these auxiliary classifiers with the supervised task loss, the supervision can be applied to the shallow layers directly. However, deep supervision conflicts with the well-known observation that the shallow layers learn low-level features instead of task-biased high-level semantic features. To address this issue, this paper proposes a novel training framework named Contrastive Deep Supervision, which supervises the intermediate layers with augmentation-based contrastive learning. Experimental results on nine popular datasets with eleven models demonstrate its effects on general image classification, fine-grained image classification and object detection in supervised learning, semi-supervised learning and knowledge distillation. Codes have been released in Github.