 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Large-scale Subsurface Simulations with a Hybrid Graph Network Simulator
Jun 15, 2022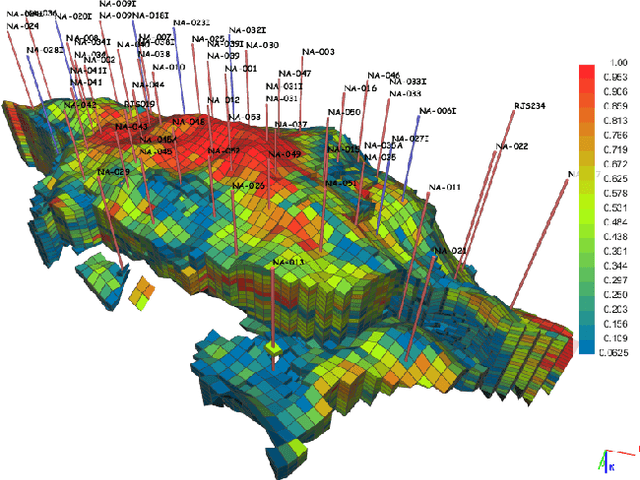
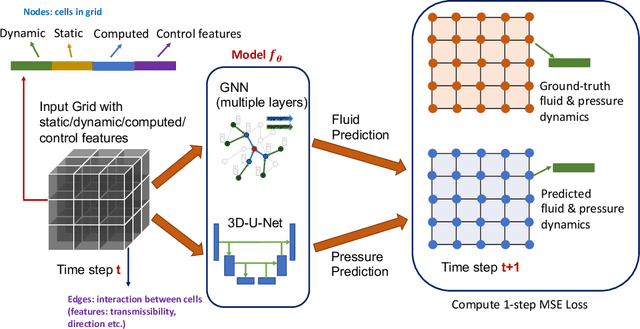
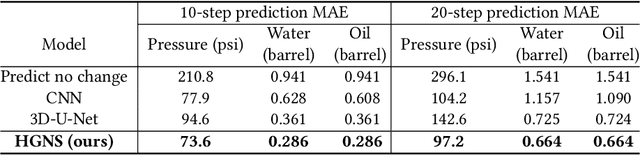
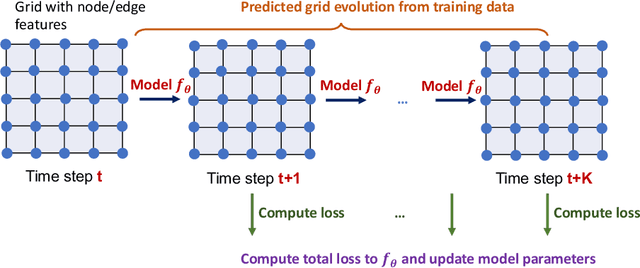
Subsurface simulations use computational models to predict the flow of fluids (e.g., oil, water, gas) through porous media. These simulations are pivotal in industrial applications such as petroleum production, where fast and accurate models are needed for high-stake decision making, for example, for well placement optimization and field development planning. Classical finite difference numerical simulators require massive computational resources to model large-scale real-world reservoirs. Alternatively, streamline simulators and data-driven surrogate models are computationally more efficient by relying on approximate physics models, however they are insufficient to model complex reservoir dynamics at scale. Here we introduce Hybrid Graph Network Simulator (HGNS), which is a data-driven surrogate model for learning reservoir simulations of 3D subsurface fluid flows. To model complex reservoir dynamics at both local and global scale, HGNS consists of a subsurface graph neural network (SGNN) to model the evolution of fluid flows, and a 3D-U-Net to model the evolution of pressure. HGNS is able to scale to grids with millions of cells per time step, two orders of magnitude higher than previous surrogate models, and can accurately predict the fluid flow for tens of time steps (years into the future). Using an industry-standard subsurface flow dataset (SPE-10) with 1.1 million cells, we demonstrate that HGNS is able to reduce the inference time up to 18 times compared to standard subsurface simulators, and that it outperforms other learning-based models by reducing long-term prediction errors by up to 21%.
Learning Backward Compatible Embeddings
Jun 07, 2022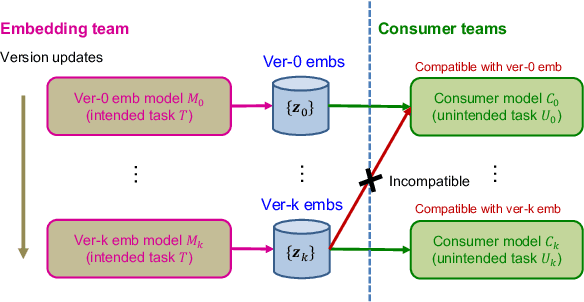
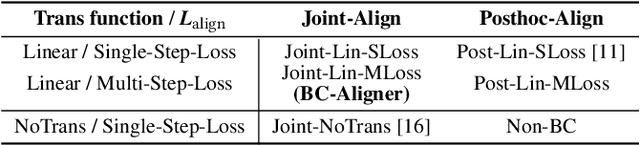
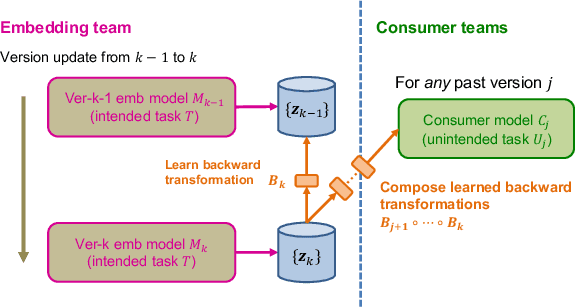

Embeddings, low-dimensional vector representation of objects, are fundamental in building modern machine learning systems. In industrial settings, there is usually an embedding team that trains an embedding model to solve intended tasks (e.g., product recommendation). The produced embeddings are then widely consumed by consumer teams to solve their unintended tasks (e.g., fraud detection). However, as the embedding model gets updated and retrained to improve performance on the intended task, the newly-generated embeddings are no longer compatible with the existing consumer models. This means that historical versions of the embeddings can never be retired or all consumer teams have to retrain their models to make them compatible with the latest version of the embeddings, both of which are extremely costly in practice. Here we study the problem of embedding version updates and their backward compatibility. We formalize the problem where the goal is for the embedding team to keep updating the embedding version, while the consumer teams do not have to retrain their models. We develop a solution based on learning backward compatible embeddings, which allows the embedding model version to be updated frequently, while also allowing the latest version of the embedding to be quickly transformed into any backward compatible historical version of it, so that consumer teams do not have to retrain their models. Under our framework, we explore six methods and systematically evaluate them on a real-world recommender system application. We show that the best method, which we call BC-Aligner, maintains backward compatibility with existing unintended tasks even after multiple model version updates. Simultaneously, BC-Aligner achieves the intended task performance similar to the embedding model that is solely optimized for the intended task.
Open-World Semi-Supervised Learning
Feb 06, 2021
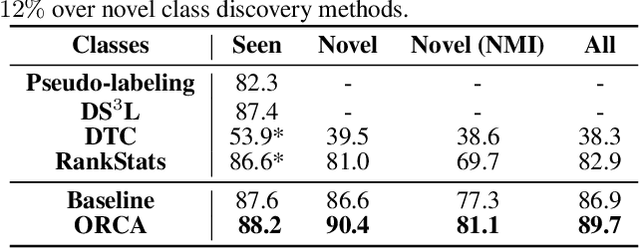
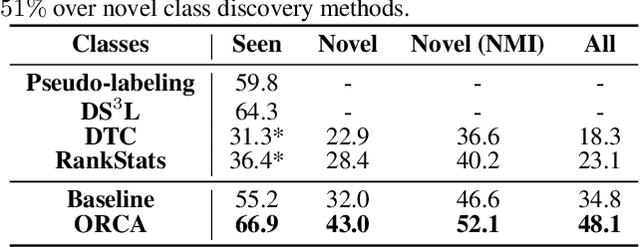
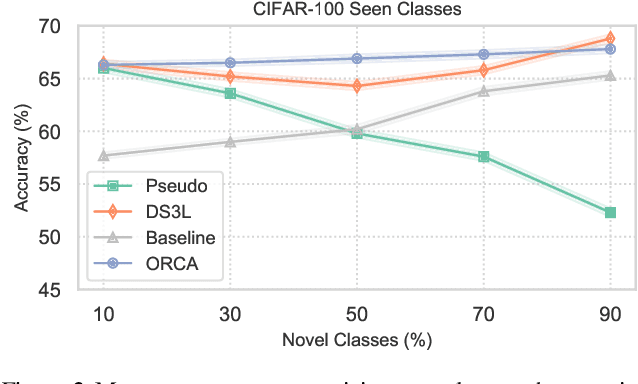
Supervised and semi-supervised learning methods have been traditionally designed for the closed-world setting based on the assumption that unlabeled test data contains only classes previously encountered in the labeled training data. However, the real world is inherently open and dynamic, and thus novel, previously unseen classes may appear in the test data or during the model deployment. Here, we introduce a new open-world semi-supervised learning setting in which the model is required to recognize previously seen classes, as well as to discover novel classes never seen in the labeled dataset. To tackle the problem, we propose ORCA, an approach that learns to simultaneously classify and cluster the data. ORCA classifies examples from the unlabeled dataset to previously seen classes, or forms a novel class by grouping similar examples together. The key idea in ORCA is in introducing uncertainty based adaptive margin that effectively circumvents the bias caused by the imbalance of variance between seen and novel classes/clusters. We demonstrate that ORCA accurately discovers novel classes and assigns samples to previously seen classes on benchmark image classification datasets, including CIFAR and ImageNet. Remarkably, despite solving the harder task ORCA outperforms semi-supervised methods on seen classes, as well as novel class discovery methods on novel classes, achieving 7% and 151% improvements on seen and novel classes in the ImageNet dataset.
Coresets for Robust Training of Neural Networks against Noisy Labels
Nov 15, 2020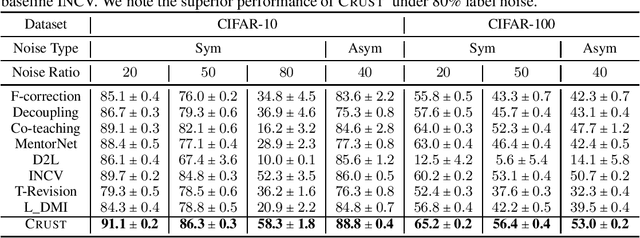
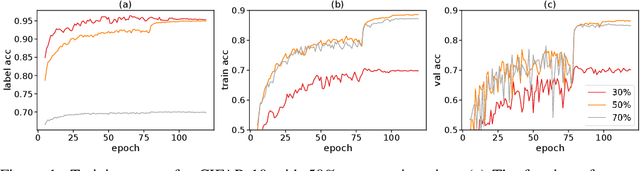


Modern neural networks have the capacity to overfit noisy labels frequently found in real-world datasets. Although great progress has been made, existing techniques are limited in providing theoretical guarantees for the performance of the neural networks trained with noisy labels. Here we propose a novel approach with strong theoretical guarantees for robust training of deep networks trained with noisy labels. The key idea behind our method is to select weighted subsets (coresets) of clean data points that provide an approximately low-rank Jacobian matrix. We then prove that gradient descent applied to the subsets do not overfit the noisy labels. Our extensive experiments corroborate our theory and demonstrate that deep networks trained on our subsets achieve a significantly superior performance compared to state-of-the art, e.g., 6% increase in accuracy on CIFAR-10 with 80% noisy labels, and 7% increase in accuracy on mini Webvision.
Concept Learners for Generalizable Few-Shot Learning
Jul 14, 2020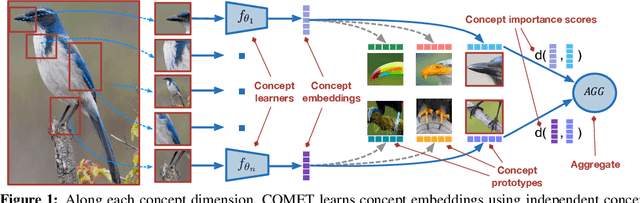
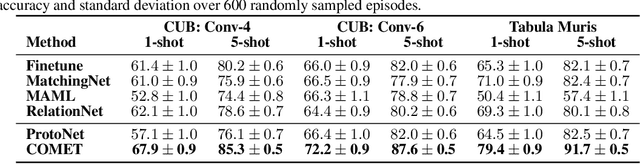

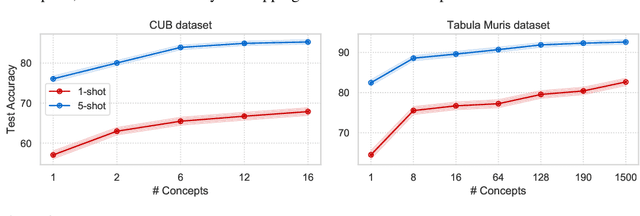
Developing algorithms that are able to generalize to a novel task given only a few labeled examples represents a fundamental challenge in closing the gap between machine- and human-level performance. The core of human cognition lies in the structured, reusable concepts that help us to rapidly adapt to new tasks and provide reasoning behind our decisions. However, existing meta-learning methods learn complex representations across prior labeled tasks without imposing any structure on the learned representations. Here we propose COMET, a meta-learning method that improves generalization ability by learning to learn along human-interpretable concept dimensions. Instead of learning a joint unstructured metric space, COMET learns mappings of high-level concepts into semi-structured metric spaces, and effectively combines the outputs of independent concept learners. We evaluate our model on few-shot tasks from diverse domains, including a benchmark image classification dataset and a novel single-cell dataset from a biological domain developed in our work. COMET significantly outperforms strong meta-learning baselines, achieving $9$-$12\%$ average improvement on the most challenging $1$-shot learning tasks, while unlike existing methods also providing interpretations behind the model's predictions.
Heteroskedastic and Imbalanced Deep Learning with Adaptive Regularization
Jun 29, 2020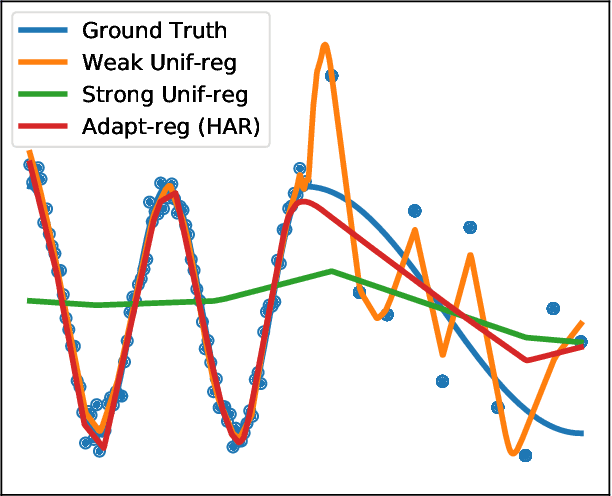
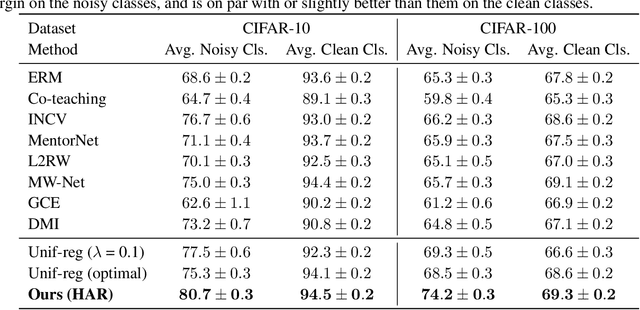
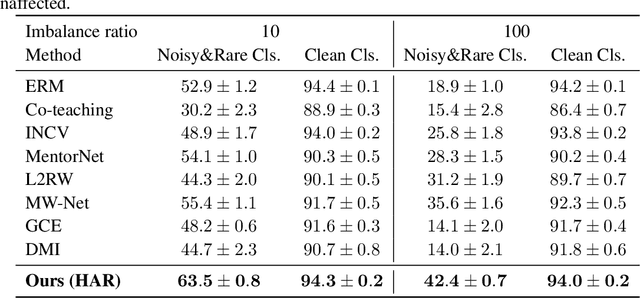
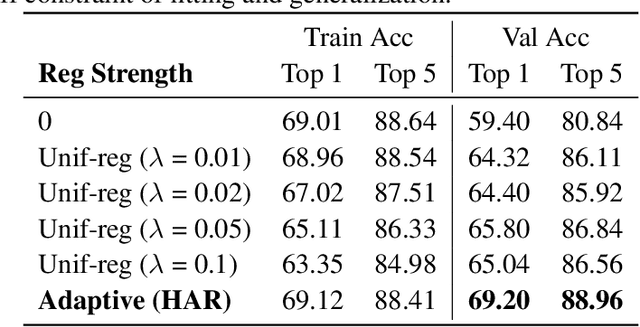
Real-world large-scale datasets are heteroskedastic and imbalanced -- labels have varying levels of uncertainty and label distributions are long-tailed. Heteroskedasticity and imbalance challenge deep learning algorithms due to the difficulty of distinguishing among mislabeled, ambiguous, and rare examples. Addressing heteroskedasticity and imbalance simultaneously is under-explored. We propose a data-dependent regularization technique for heteroskedastic datasets that regularizes different regions of the input space differently. Inspired by the theoretical derivation of the optimal regularization strength in a one-dimensional nonparametric classification setting, our approach adaptively regularizes the data points in higher-uncertainty, lower-density regions more heavily. We test our method on several benchmark tasks, including a real-world heteroskedastic and imbalanced dataset, WebVision. Our experiments corroborate our theory and demonstrate a significant improvement over other methods in noise-robust deep learning.
Learning Temporal Action Proposals With Fewer Labels
Oct 03, 2019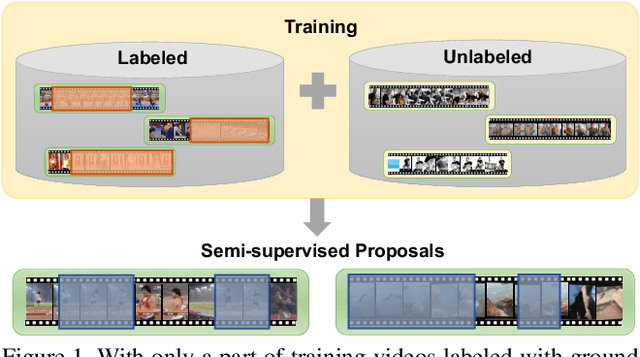
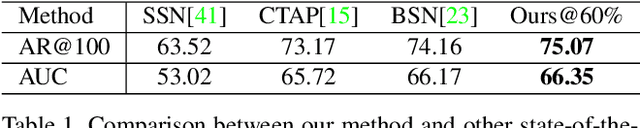
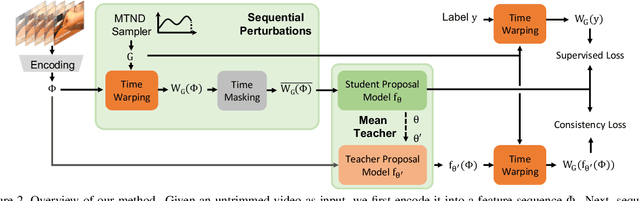
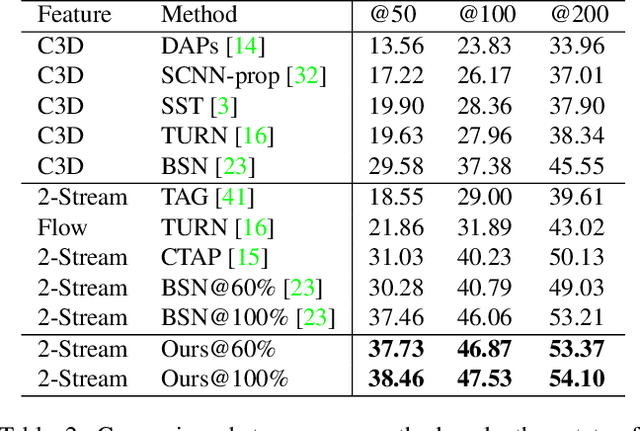
Temporal action proposals are a common module in action detection pipelines today. Most current methods for training action proposal modules rely on fully supervised approaches that require large amounts of annotated temporal action intervals in long video sequences. The large cost and effort in annotation that this entails motivate us to study the problem of training proposal modules with less supervision. In this work, we propose a semi-supervised learning algorithm specifically designed for training temporal action proposal networks. When only a small number of labels are available, our semi-supervised method generates significantly better proposals than the fully-supervised counterpart and other strong semi-supervised baselines. We validate our method on two challenging action detection video datasets, ActivityNet v1.3 and THUMOS14. We show that our semi-supervised approach consistently matches or outperforms the fully supervised state-of-the-art approaches.
Delving Deep Into Hybrid Annotations for 3D Human Recovery in the Wild
Aug 20, 2019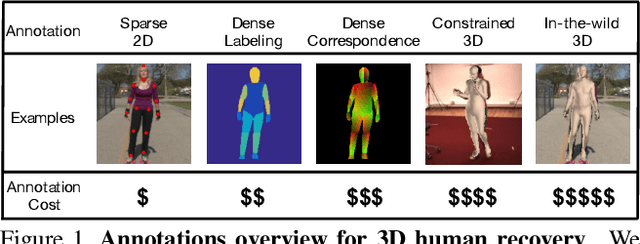
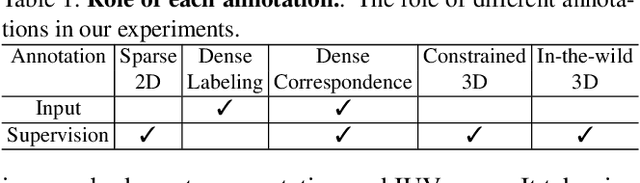
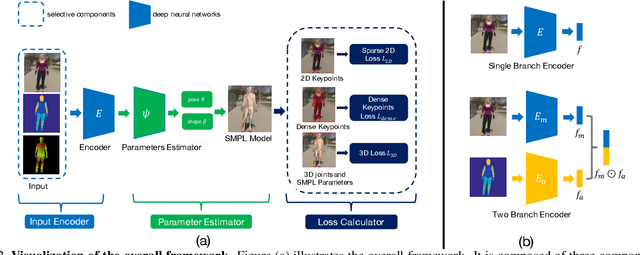
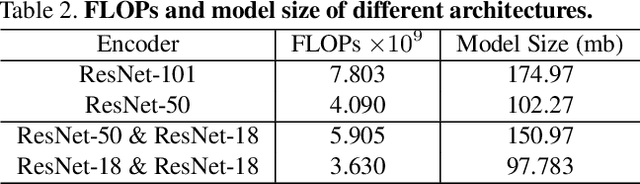
Though much progress has been achieved in single-image 3D human recovery, estimating 3D model for in-the-wild images remains a formidable challenge. The reason lies in the fact that obtaining high-quality 3D annotations for in-the-wild images is an extremely hard task that consumes enormous amount of resources and manpower. To tackle this problem, previous methods adopt a hybrid training strategy that exploits multiple heterogeneous types of annotations including 3D and 2D while leaving the efficacy of each annotation not thoroughly investigated. In this work, we aim to perform a comprehensive study on cost and effectiveness trade-off between different annotations. Specifically, we focus on the challenging task of in-the-wild 3D human recovery from single images when paired 3D annotations are not fully available. Through extensive experiments, we obtain several observations: 1) 3D annotations are efficient, whereas traditional 2D annotations such as 2D keypoints and body part segmentation are less competent in guiding 3D human recovery. 2) Dense Correspondence such as DensePose is effective. When there are no paired in-the-wild 3D annotations available, the model exploiting dense correspondence can achieve 92% of the performance compared to a model trained with paired 3D data. We show that incorporating dense correspondence into in-the-wild 3D human recovery is promising and competitive due to its high efficiency and relatively low annotating cost. Our model trained with dense correspondence can serve as a strong reference for future research.
Few-Shot Video Classification via Temporal Alignment
Jun 27, 2019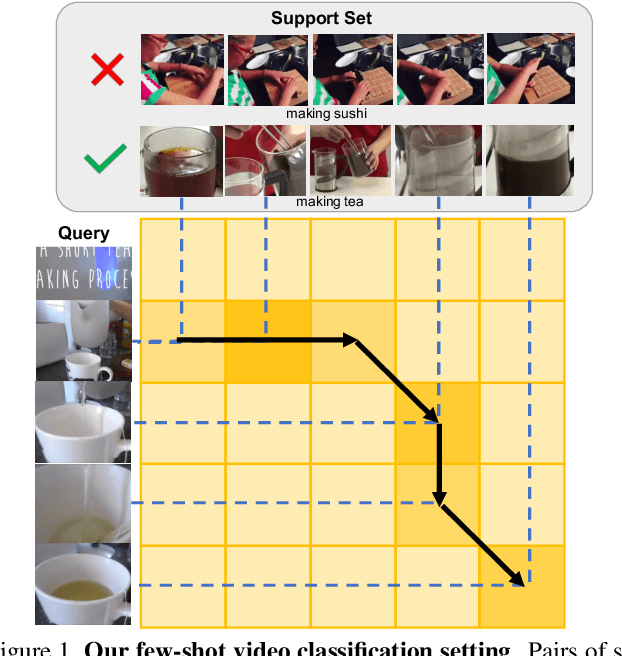
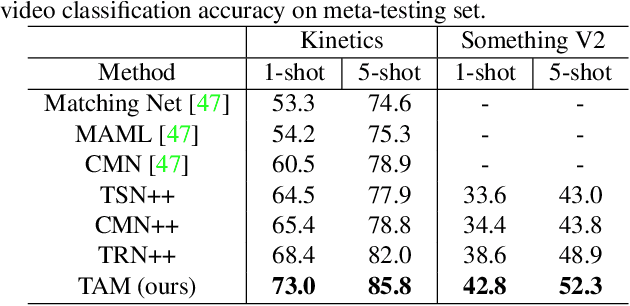
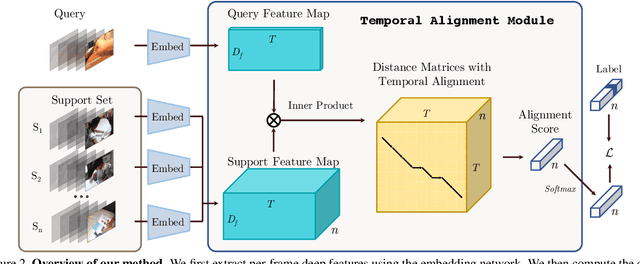
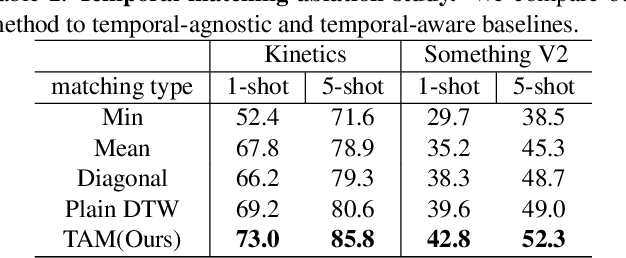
There is a growing interest in learning a model which could recognize novel classes with only a few labeled examples. In this paper, we propose Temporal Alignment Module (TAM), a novel few-shot learning framework that can learn to classify a previous unseen video. While most previous works neglect long-term temporal ordering information, our proposed model explicitly leverages the temporal ordering information in video data through temporal alignment. This leads to strong data-efficiency for few-shot learning. In concrete, TAM calculates the distance value of query video with respect to novel class proxies by averaging the per frame distances along its alignment path. We introduce continuous relaxation to TAM so the model can be learned in an end-to-end fashion to directly optimize the few-shot learning objective. We evaluate TAM on two challenging real-world datasets, Kinetics and Something-Something-V2, and show that our model leads to significant improvement of few-shot video classification over a wide range of competitive baselines.
Learning Imbalanced Datasets with Label-Distribution-Aware Margin Loss
Jun 18, 2019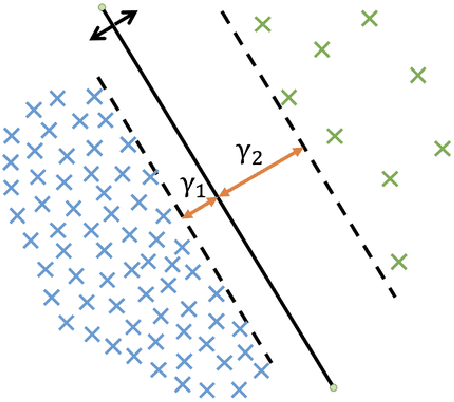
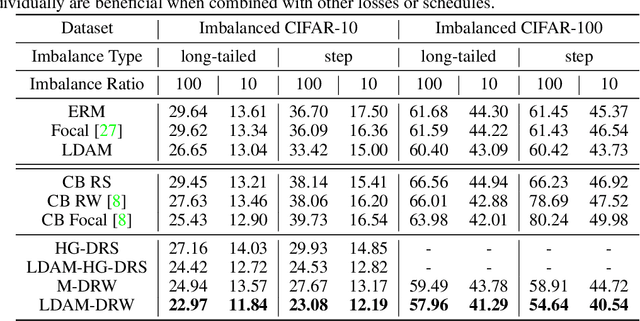
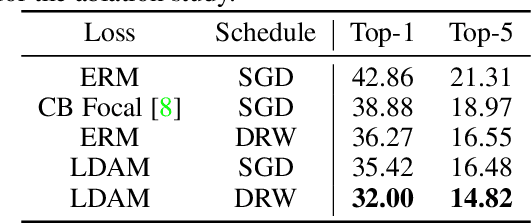
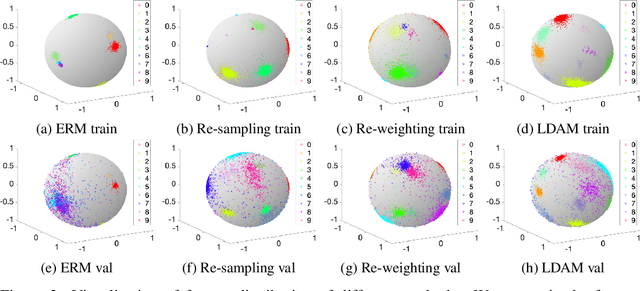
Deep learning algorithms can fare poorly when the training dataset suffers from heavy class-imbalance but the testing criterion requires good generalization on less frequent classes. We design two novel methods to improve performance in such scenarios. First, we propose a theoretically-principled label-distribution-aware margin (LDAM) loss motivated by minimizing a margin-based generalization bound. This loss replaces the standard cross-entropy objective during training and can be applied with prior strategies for training with class-imbalance such as re-weighting or re-sampling. Second, we propose a simple, yet effective, training schedule that defers re-weighting until after the initial stage, allowing the model to learn an initial representation while avoiding some of the complications associated with re-weighting or re-sampling. We test our methods on several benchmark vision tasks including the real-world imbalanced dataset iNaturalist 2018. Our experiments show that either of these methods alone can already improve over existing techniques and their combination achieves even better performance gains.