 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Double IRS aided Secure Communication for MIMO-OFDM Systems
Jan 27, 2026Cooperative double intelligent reflecting surface (double-IRS) has emerged as a promising approach for enhancing physical layer security (PLS) in MIMO systems. However, existing studies are limited to narrowband scenarios and fail to address wideband MIMO-OFDM. In this regime, frequency-flat IRS phases and cascaded IRS links cause severe coupling, rendering narrowband designs inapplicable. To overcome this challenge, we introduce cooperative double-IRS-assisted wideband MIMO-OFDM and propose an efficient manifold-based solution. By regarding the power and constant modulus constraints as Riemannian manifolds, we reformulate the non-convex secrecy sum rate maximization as an unconstrained optimization on a product manifold. Building on this formulation, we further develop a product Riemannian gradient descent (PRGD) algorithm with guaranteed stationary convergence. Simulation results demonstrate that the proposed scheme effectively resolves the OFDM coupling issue and achieves significant secrecy rate gains, outperforming single-IRS and distributed multi-IRS benchmarks by 32.0% and 22.3%, respectively.
Joint Analog Beamforming and Antenna Position Design for Secure Communication systems With Movable Antennas
Nov 19, 2025Movable antennas (MA) are a novel technology that allows for the flexible adjustment of antenna positions within a specified region, thereby enhancing the performance of wireless communication systems. In this paper, we explore the use of MA to improve physical layer security in an analog beamforming (AB) communication system. Our goal is to maximize the secrecy rate by jointly optimizing the transmit AB and MA position, subject to constant modulus (CM) constraints on the AB and position constraints for the MA. The resulting problem is non-convex, and we propose a penalty product manifold (PPM) method to solve it efficiently. Specifically, we convert the inequality constraints related to MA position into a penalty function using smoothing techniques, thereby reformulating the problem as an unconstrained optimization on the product manifold space (PMS). We then derive a parallel conjugate gradient descent (PCGD) algorithm to update both the AB and MA position on the PMS. This method is efficient, providing an analytical solution at each step and ensuring convergence to a KKT point. Simulation results show that the MA system achieves a higher secrecy rate than systems with fixed-position antennas.
Movable IRS-Aided ISAC Systems: Joint Beamforming and Position Optimization
Sep 05, 2025Driven by intelligent reflecting surface (IRS) and movable antenna (MA) technologies, movable IRS (MIRS) has been proposed to improve the adaptability and performance of conventional IRS, enabling flexible adjustment of the IRS reflecting element positions. This paper investigates MIRS-aided integrated sensing and communication (ISAC) systems. The objective is to minimize the power required for satisfying the quality-of-service (QoS) of sensing and communication by jointly optimizing the MIRS element positions, IRS reflection coefficients, transmit beamforming, and receive filters. To balance the performance-cost trade-off, we proposed two MIRS schemes: element-wise control and array-wise control, where the positions of individual reflecting elements and arrays consisting of multiple elements are controllable, respectively. To address the joint beamforming and position optimization, a product Riemannian manifold optimization (PRMO) method is proposed, where the variables are updated over a constructed product Riemannian manifold space (PRMS) in parallel via penalty-based transformation and Riemannian Broyden-Fletcher-Goldfarb-Shanno (RBFGS) algorithm. Simulation results demonstrate that the proposed MIRS outperforms conventional IRS in power minimization with both element-wise control and array-wise control. Specifically, with different system parameters, the minimum power is achieved by the MIRS with the element-wise control scheme, while suboptimal solution and higher computational efficiency are achieved by the MIRS with array-wise control scheme.
RankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025



In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
Joint Beamforming and Antenna Position Design for IRS-Aided Multi-User Movable Antenna Systems
Oct 01, 2024



Intelligent reflecting surface (IRS) and movable antenna (MA) technologies have been proposed to enhance wireless communications by creating favorable channel conditions. This paper investigates the joint beamforming and antenna position design for an MA-enabled IRS (MA-IRS)-aided multi-user multiple-input single-output (MU-MISO) communication system, where the MA-IRS is deployed to aid the communication between the MA-enabled base station (BS) and user equipment (UE). In contrast to conventional fixed position antenna (FPA)-enabled IRS (FPA-IRS), the MA-IRS enhances the wireless channel by controlling the positions of the reflecting elements. To verify the system's effectiveness and optimize its performance, we formulate a sum-rate maximization problem with a minimum rate threshold constraint for the MU-MISO communication. To tackle the non-convex problem, a product Riemannian manifold optimization (PRMO) method is proposed for the joint design of the beamforming and MA positions. Specifically, a product Riemannian manifold space (PRMS) is constructed and the corresponding Riemannian gradient is derived for updating the variables, and the Riemannian exact penalty (REP) method and a Riemannian Broyden-Fletcher-Goldfarb-Shanno (RBFGS) algorithm is derived to obtain a feasible solution over the PRMS. Simulation results demonstrate that compared with the conventional FPA-IRS-aided MU-MISO communication, the reflecting elements of the MA-IRS can move to the positions with higher channel gain, thus enhancing the system performance. Furthermore, it is shown that integrating MA with IRS leads to higher performance gains compared to integrating MA with BS.
APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Jun 20, 2024Large Language Models (LLMs) have significantly enhanced Information Retrieval (IR) across various modules, such as reranking. Despite impressive performance, current zero-shot relevance ranking with LLMs heavily relies on human prompt engineering. Existing automatic prompt engineering algorithms primarily focus on language modeling and classification tasks, leaving the domain of IR, particularly reranking, underexplored. Directly applying current prompt engineering algorithms to relevance ranking is challenging due to the integration of query and long passage pairs in the input, where the ranking complexity surpasses classification tasks. To reduce human effort and unlock the potential of prompt optimization in reranking, we introduce a novel automatic prompt engineering algorithm named APEER. APEER iteratively generates refined prompts through feedback and preference optimization. Extensive experiments with four LLMs and ten datasets demonstrate the substantial performance improvement of APEER over existing state-of-the-art (SoTA) manual prompts. Furthermore, we find that the prompts generated by APEER exhibit better transferability across diverse tasks and LLMs. Code is available at https://github.com/jincan333/APEER.
FOSS: A Self-Learned Doctor for Query Optimizer
Dec 11, 2023



Various works have utilized deep reinforcement learning (DRL) to address the query optimization problem in database system. They either learn to construct plans from scratch in a bottom-up manner or guide the plan generation behavior of traditional optimizer using hints. While these methods have achieved some success, they face challenges in either low training efficiency or limited plan search space. To address these challenges, we introduce FOSS, a novel DRL-based framework for query optimization. FOSS initiates optimization from the original plan generated by a traditional optimizer and incrementally refines suboptimal nodes of the plan through a sequence of actions. Additionally, we devise an asymmetric advantage model to evaluate the advantage between two plans. We integrate it with a traditional optimizer to form a simulated environment. Leveraging this simulated environment, FOSS can bootstrap itself to rapidly generate a large amount of high-quality simulated experiences. FOSS then learns and improves its optimization capability from these simulated experiences. We evaluate the performance of FOSS on Join Order Benchmark, TPC-DS, and Stack Overflow. The experimental results demonstrate that FOSS outperforms the state-of-the-art methods in terms of latency performance and optimization time. Compared to PostgreSQL, FOSS achieves savings ranging from 15% to 83% in total latency across different benchmarks.
Doppler velocity-based algorithm for Clustering and Velocity Estimation of moving objects
Dec 24, 2021
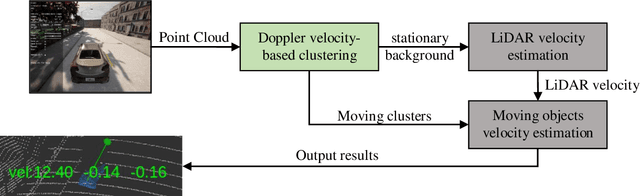
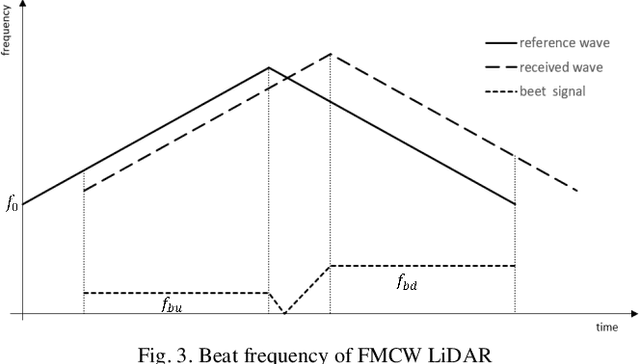

We propose a Doppler velocity-based cluster and velocity estimation algorithm based on the characteristics of FMCW LiDAR which achieves highly accurate, single-scan, and real-time motion state detection and velocity estimation. We prove the continuity of the Doppler velocity on the same object. Based on this principle, we achieve the distinction between moving objects and stationary background via region growing clustering algorithm. The obtained stationary background will be used to estimate the velocity of the FMCW LiDAR by the least-squares method. Then we estimate the velocity of the moving objects using the estimated LiDAR velocity and the Doppler velocity of moving objects obtained by clustering. To ensure real-time processing, we set the appropriate least-squares parameters. Meanwhile, to verify the effectiveness of the algorithm, we create the FMCW LiDAR model on the autonomous driving simulation platform CARLA for spawning data. The results show that our algorithm can process at least a 4.5million points and estimate the velocity of 150 moving objects per second under the arithmetic power of the Ryzen 3600x CPU, with a motion state detection accuracy of over 99% and estimated velocity accuracy of 0.1 m/s.
Extreme Multi-label Learning for Semantic Matching in Product Search
Jun 23, 2021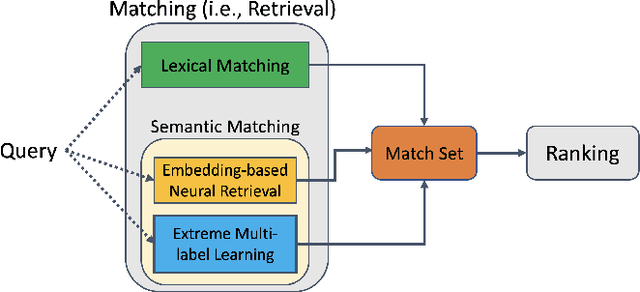

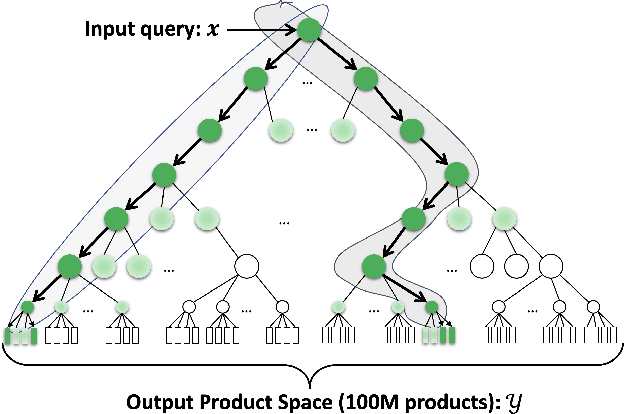
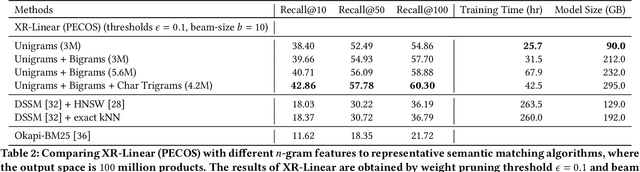
We consider the problem of semantic matching in product search: given a customer query, retrieve all semantically related products from a huge catalog of size 100 million, or more. Because of large catalog spaces and real-time latency constraints, semantic matching algorithms not only desire high recall but also need to have low latency. Conventional lexical matching approaches (e.g., Okapi-BM25) exploit inverted indices to achieve fast inference time, but fail to capture behavioral signals between queries and products. In contrast, embedding-based models learn semantic representations from customer behavior data, but the performance is often limited by shallow neural encoders due to latency constraints. Semantic product search can be viewed as an eXtreme Multi-label Classification (XMC) problem, where customer queries are input instances and products are output labels. In this paper, we aim to improve semantic product search by using tree-based XMC models where inference time complexity is logarithmic in the number of products. We consider hierarchical linear models with n-gram features for fast real-time inference. Quantitatively, our method maintains a low latency of 1.25 milliseconds per query and achieves a 65% improvement of Recall@100 (60.9% v.s. 36.8%) over a competing embedding-based DSSM model. Our model is robust to weight pruning with varying thresholds, which can flexibly meet different system requirements for online deployments. Qualitatively, our method can retrieve products that are complementary to existing product search system and add diversity to the match set.
BoolNet: Minimizing The Energy Consumption of Binary Neural Networks
Jun 13, 2021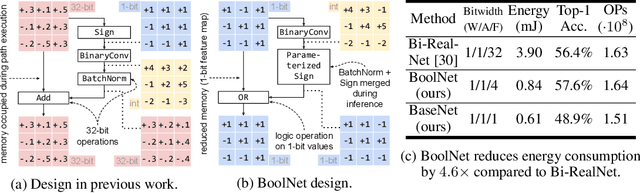
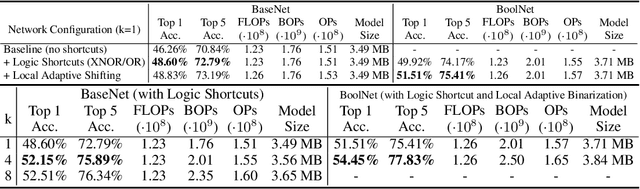
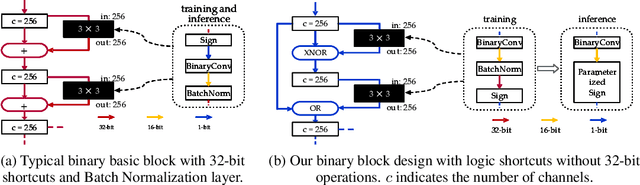
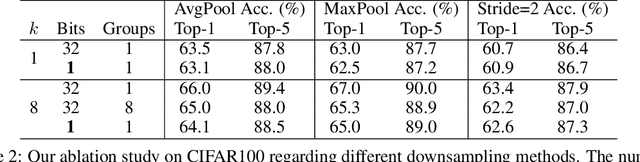
Recent works on Binary Neural Networks (BNNs) have made promising progress in narrowing the accuracy gap of BNNs to their 32-bit counterparts. However, the accuracy gains are often based on specialized model designs using additional 32-bit components. Furthermore, almost all previous BNNs use 32-bit for feature maps and the shortcuts enclosing the corresponding binary convolution blocks, which helps to effectively maintain the accuracy, but is not friendly to hardware accelerators with limited memory, energy, and computing resources. Thus, we raise the following question: How can accuracy and energy consumption be balanced in a BNN network design? We extensively study this fundamental problem in this work and propose a novel BNN architecture without most commonly used 32-bit components: \textit{BoolNet}. Experimental results on ImageNet demonstrate that BoolNet can achieve 4.6x energy reduction coupled with 1.2\% higher accuracy than the commonly used BNN architecture Bi-RealNet. Code and trained models are available at: https://github.com/hpi-xnor/BoolNet.