 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld of Workflows: a Benchmark for Bringing World Models to Enterprise Systems
Jan 29, 2026Frontier large language models (LLMs) excel as autonomous agents in many domains, yet they remain untested in complex enterprise systems where hidden workflows create cascading effects across interconnected databases. Existing enterprise benchmarks evaluate surface-level agentic task completion similar to general consumer benchmarks, ignoring true challenges in enterprises, such as limited observability, large database state, and hidden workflows with cascading side effects. We introduce World of Workflows (WoW), a realistic ServiceNow-based environment incorporating 4,000+ business rules and 55 active workflows embedded in the system, alongside WoW-bench, a benchmark of 234 tasks evaluating constrained agentic task completion and enterprise dynamics modeling capabilities. We reveal two major takeaways: (1) Frontier LLMs suffer from dynamics blindness, consistently failing to predict the invisible, cascading side effects of their actions, which leads to silent constraint violations, and (2) reliability in opaque systems requires grounded world modeling, where agents must mentally simulate hidden state transitions to bridge the observability gap when high-fidelity feedback is unavailable. For reliable and useful enterprise agents, WoW motivates a new paradigm to explicitly learn system dynamics. We release our GitHub for setting up and evaluating WoW.
SFBD-OMNI: Bridge models for lossy measurement restoration with limited clean samples
Dec 18, 2025In many real-world scenarios, obtaining fully observed samples is prohibitively expensive or even infeasible, while partial and noisy observations are comparatively easy to collect. In this work, we study distribution restoration with abundant noisy samples, assuming the corruption process is available as a black-box generator. We show that this task can be framed as a one-sided entropic optimal transport problem and solved via an EM-like algorithm. We further provide a test criterion to determine whether the true underlying distribution is recoverable under per-sample information loss, and show that in otherwise unrecoverable cases, a small number of clean samples can render the distribution largely recoverable. Building on these insights, we introduce SFBD-OMNI, a bridge model-based framework that maps corrupted sample distributions to the ground-truth distribution. Our method generalizes Stochastic Forward-Backward Deconvolution (SFBD; Lu et al., 2025) to handle arbitrary measurement models beyond Gaussian corruption. Experiments across benchmark datasets and diverse measurement settings demonstrate significant improvements in both qualitative and quantitative performance.
SCOPE: Language Models as One-Time Teacher for Hierarchical Planning in Text Environments
Dec 10, 2025Long-term planning in complex, text-based environments presents significant challenges due to open-ended action spaces, ambiguous observations, and sparse feedback. Recent research suggests that large language models (LLMs) encode rich semantic knowledge about the world, which can be valuable for guiding agents in high-level reasoning and planning across both embodied and purely textual settings. However, existing approaches often depend heavily on querying LLMs during training and inference, making them computationally expensive and difficult to deploy efficiently. In addition, these methods typically employ a pretrained, unaltered LLM whose parameters remain fixed throughout training, providing no opportunity for adaptation to the target task. To address these limitations, we introduce SCOPE (Subgoal-COnditioned Pretraining for Efficient planning), a one-shot hierarchical planner that leverages LLM-generated subgoals only at initialization to pretrain a lightweight student model. Unlike prior approaches that distill LLM knowledge by repeatedly prompting the model to adaptively generate subgoals during training, our method derives subgoals directly from example trajectories. This design removes the need for repeated LLM queries, significantly improving efficiency, though at the cost of reduced explainability and potentially suboptimal subgoals. Despite their suboptimality, our results on the TextCraft environment show that LLM-generated subgoals can still serve as a strong starting point for hierarchical goal decomposition in text-based planning tasks. Compared to the LLM-based hierarchical agent ADaPT (Prasad et al., 2024), which achieves a 0.52 success rate, our method reaches 0.56 and reduces inference time from 164.4 seconds to just 3.0 seconds.
Stochastic Forward-Backward Deconvolution: Training Diffusion Models with Finite Noisy Datasets
Feb 08, 2025



Recent diffusion-based generative models achieve remarkable results by training on massive datasets, yet this practice raises concerns about memorization and copyright infringement. A proposed remedy is to train exclusively on noisy data with potential copyright issues, ensuring the model never observes original content. However, through the lens of deconvolution theory, we show that although it is theoretically feasible to learn the data distribution from noisy samples, the practical challenge of collecting sufficient samples makes successful learning nearly unattainable. To overcome this limitation, we propose to pretrain the model with a small fraction of clean data to guide the deconvolution process. Combined with our Stochastic Forward--Backward Deconvolution (SFBD) method, we attain an FID of $6.31$ on CIFAR-10 with just $4\%$ clean images (and $3.58$ with $10\%$). Theoretically, we prove that SFBD guides the model to learn the true data distribution. The result also highlights the importance of pretraining on limited but clean data or the alternative from similar datasets. Empirical studies further support these findings and offer additional insights.
Structure Preserving Diffusion Models
Feb 29, 2024Diffusion models have become the leading distribution-learning method in recent years. Herein, we introduce structure-preserving diffusion processes, a family of diffusion processes for learning distributions that possess additional structure, such as group symmetries, by developing theoretical conditions under which the diffusion transition steps preserve said symmetry. While also enabling equivariant data sampling trajectories, we exemplify these results by developing a collection of different symmetry equivariant diffusion models capable of learning distributions that are inherently symmetric. Empirical studies, over both synthetic and real-world datasets, are used to validate the developed models adhere to the proposed theory and are capable of achieving improved performance over existing methods in terms of sample equality. We also show how the proposed models can be used to achieve theoretically guaranteed equivariant image noise reduction without prior knowledge of the image orientation.
On the Dynamics of Training Attention Models
Nov 19, 2020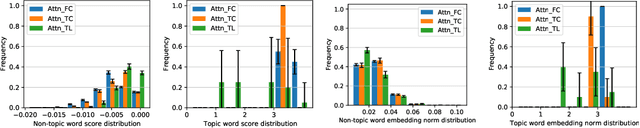
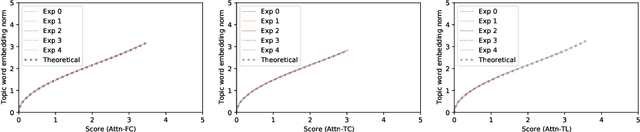

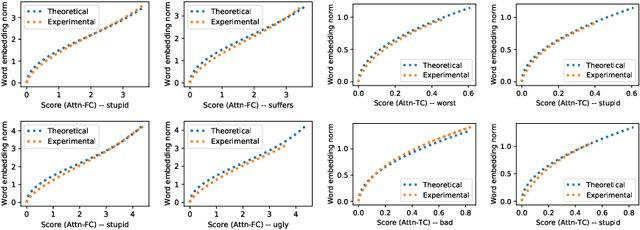
The attention mechanism has been widely used in deep neural networks as a model component. By now, it has become a critical building block in many state-of-the-art natural language models. Despite its great success established empirically, the working mechanism of attention has not been investigated at a sufficient theoretical depth to date. In this paper, we set up a simple text classification task and study the dynamics of training a simple attention-based classification model using gradient descent. In this setting, we show that, for the discriminative words that the model should attend to, a persisting identity exists relating its embedding and the inner product of its key and the query. This allows us to prove that training must converge to attending to the discriminative words when the attention output is classified by a linear classifier. Experiments are performed, which validates our theoretical analysis and provides further insights.
A Deep Neural Network for Audio Classification with a Classifier Attention Mechanism
Jun 14, 2020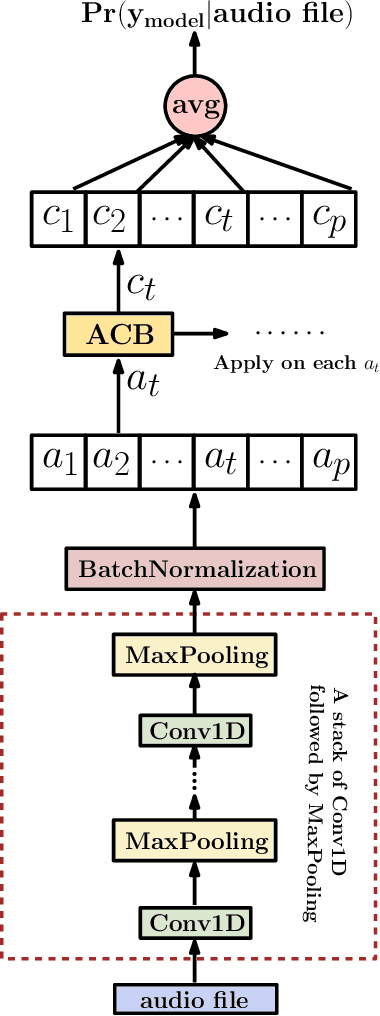
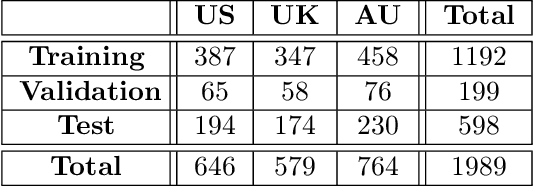
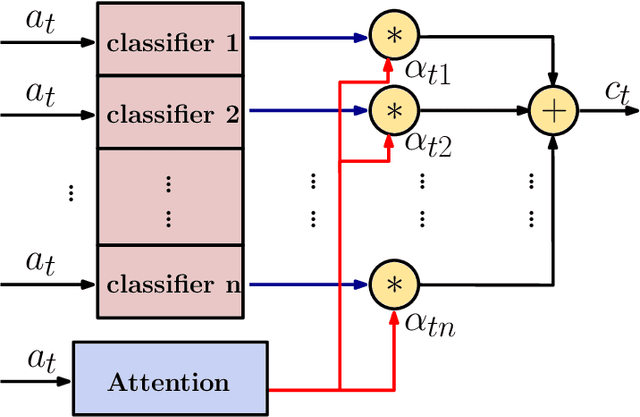
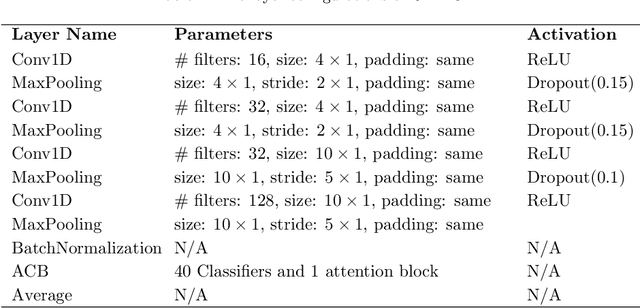
Audio classification is considered as a challenging problem in pattern recognition. Recently, many algorithms have been proposed using deep neural networks. In this paper, we introduce a new attention-based neural network architecture called Classifier-Attention-Based Convolutional Neural Network (CAB-CNN). The algorithm uses a newly designed architecture consisting of a list of simple classifiers and an attention mechanism as a classifier selector. This design significantly reduces the number of parameters required by the classifiers and thus their complexities. In this way, it becomes easier to train the classifiers and achieve a high and steady performance. Our claims are corroborated by the experimental results. Compared to the state-of-the-art algorithms, our algorithm achieves more than 10% improvements on all selected test scores.