 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASSANDRA: Programmatic and Probabilistic Learning and Inference for Stochastic World Modeling
Jan 26, 2026Building world models is essential for planning in real-world domains such as businesses. Since such domains have rich semantics, we can leverage world knowledge to effectively model complex action effects and causal relationships from limited data. In this work, we propose CASSANDRA, a neurosymbolic world modeling approach that leverages an LLM as a knowledge prior to construct lightweight transition models for planning. CASSANDRA integrates two components: (1) LLM-synthesized code to model deterministic features, and (2) LLM-guided structure learning of a probabilistic graphical model to capture causal relationships among stochastic variables. We evaluate CASSANDRA in (i) a small-scale coffee-shop simulator and (ii) a complex theme park business simulator, where we demonstrate significant improvements in transition prediction and planning over baselines.
Aligning LLMs by Predicting Preferences from User Writing Samples
May 27, 2025Accommodating human preferences is essential for creating aligned LLM agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs acting as writing agents to infer a description of user preferences. Agent alignment then comes from conditioning on the inferred preference description. However, existing methods often produce generic preference descriptions that fail to capture the unique and individualized nature of human preferences. This paper introduces PROSE, a method designed to enhance the precision of preference descriptions inferred from user writing samples. PROSE incorporates two key elements: (1) iterative refinement of inferred preferences, and (2) verification of inferred preferences across multiple user writing samples. We evaluate PROSE with several LLMs (i.e., Qwen2.5 7B and 72B Instruct, GPT-mini, and GPT-4o) on a summarization and an email writing task. We find that PROSE more accurately infers nuanced human preferences, improving the quality of the writing agent's generations over CIPHER (a state-of-the-art method for inferring preferences) by 33\%. Lastly, we demonstrate that ICL and PROSE are complementary methods, and combining them provides up to a 9\% improvement over ICL alone.
Implicitly Aligning Humans and Autonomous Agents through Shared Task Abstractions
May 07, 2025In collaborative tasks, autonomous agents fall short of humans in their capability to quickly adapt to new and unfamiliar teammates. We posit that a limiting factor for zero-shot coordination is the lack of shared task abstractions, a mechanism humans rely on to implicitly align with teammates. To address this gap, we introduce HA$^2$: Hierarchical Ad Hoc Agents, a framework leveraging hierarchical reinforcement learning to mimic the structured approach humans use in collaboration. We evaluate HA$^2$ in the Overcooked environment, demonstrating statistically significant improvement over existing baselines when paired with both unseen agents and humans, providing better resilience to environmental shifts, and outperforming all state-of-the-art methods.
The World of an Octopus: How Reporting Bias Influences a Language Model's Perception of Color
Oct 15, 2021
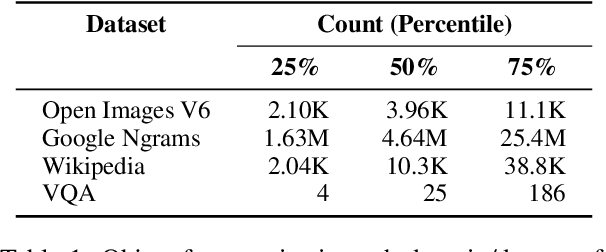
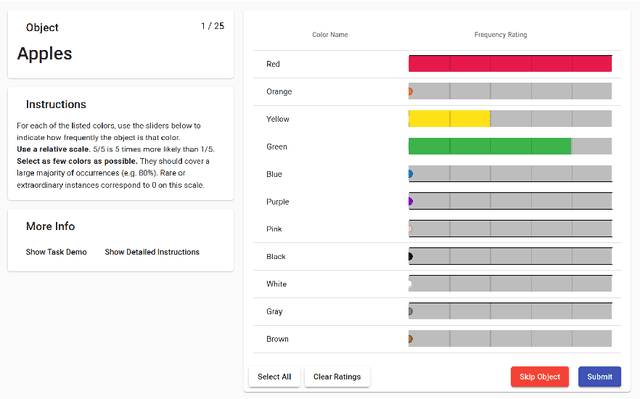
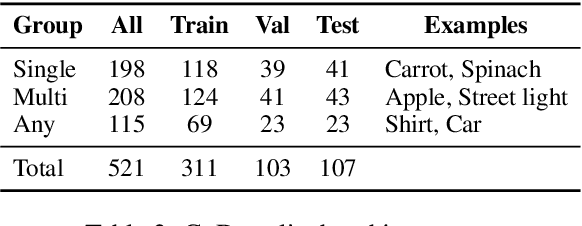
Recent work has raised concerns about the inherent limitations of text-only pretraining. In this paper, we first demonstrate that reporting bias, the tendency of people to not state the obvious, is one of the causes of this limitation, and then investigate to what extent multimodal training can mitigate this issue. To accomplish this, we 1) generate the Color Dataset (CoDa), a dataset of human-perceived color distributions for 521 common objects; 2) use CoDa to analyze and compare the color distribution found in text, the distribution captured by language models, and a human's perception of color; and 3) investigate the performance differences between text-only and multimodal models on CoDa. Our results show that the distribution of colors that a language model recovers correlates more strongly with the inaccurate distribution found in text than with the ground-truth, supporting the claim that reporting bias negatively impacts and inherently limits text-only training. We then demonstrate that multimodal models can leverage their visual training to mitigate these effects, providing a promising avenue for future research.
PROST: Physical Reasoning of Objects through Space and Time
Jun 07, 2021We present a new probing dataset named PROST: Physical Reasoning about Objects Through Space and Time. This dataset contains 18,736 multiple-choice questions made from 14 manually curated templates, covering 10 physical reasoning concepts. All questions are designed to probe both causal and masked language models in a zero-shot setting. We conduct an extensive analysis which demonstrates that state-of-the-art pretrained models are inadequate at physical reasoning: they are influenced by the order in which answer options are presented to them, they struggle when the superlative in a question is inverted (e.g., most <-> least), and increasing the amount of pretraining data and parameters only yields minimal improvements. These results provide support for the hypothesis that current pretrained models' ability to reason about physical interactions is inherently limited by a lack of real world experience. By highlighting these limitations, we hope to motivate the development of models with a human-like understanding of the physical world.